Tim Alibaba Tongyi Qianwen merilis seri model sumber terbuka Qwen2. Seri ini mencakup 5 ukuran model pra-pelatihan dan penyempurnaan instruksi. Jumlah parameter dan kinerja telah ditingkatkan secara signifikan dibandingkan dengan Qwen1.5 generasi sebelumnya. Seri Qwen2 juga membuat terobosan besar dalam kemampuan multi-bahasa, mendukung 27 bahasa selain Inggris dan Cina. Dalam hal pemahaman bahasa alami, pengkodean, kemampuan matematika, dll., model besar (parameter 70B+) berkinerja baik, terutama model Qwen2-72B, yang melampaui generasi sebelumnya dalam hal kinerja dan jumlah parameter. Peluncuran ini menandai pencapaian baru dalam teknologi kecerdasan buatan, memberikan kemungkinan yang lebih luas untuk penerapan dan komersialisasi AI global.
Pagi ini, tim Alibaba Tongyi Qianwen merilis model open source seri Qwen2. Rangkaian model ini mencakup 5 ukuran model terlatih dan model yang telah disesuaikan dengan instruksi: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, dan Qwen2-72B. Informasi penting menunjukkan bahwa jumlah parameter dan kinerja model ini telah meningkat secara signifikan dibandingkan dengan Qwen1.5 generasi sebelumnya.
Untuk kemampuan model multi-bahasa, seri Qwen2 telah menginvestasikan banyak upaya dalam meningkatkan kuantitas dan kualitas kumpulan data, mencakup 27 bahasa lain kecuali Inggris dan Cina. Setelah pengujian komparatif, model besar (parameter 70B +) memiliki kinerja yang baik dalam pemahaman bahasa alami, pengkodean, kemampuan matematika, dll. Model Qwen2-72B melampaui generasi sebelumnya dalam hal kinerja dan jumlah parameter.
Model Qwen2 tidak hanya menunjukkan kemampuan yang kuat dalam evaluasi model bahasa dasar, tetapi juga mencapai hasil yang mengesankan dalam evaluasi model penyetelan instruksi. Kemampuan multi-bahasanya bekerja dengan baik dalam pengujian benchmark seperti M-MMLU dan MGSM, menunjukkan potensi kuat dari model penyetelan instruksi Qwen2.
Model seri Qwen2 yang dirilis kali ini menandai puncak baru teknologi kecerdasan buatan, memberikan kemungkinan yang lebih luas untuk penerapan dan komersialisasi AI global. Di masa depan, Qwen2 akan semakin memperluas skala model dan kemampuan multi-modal untuk mempercepat pengembangan bidang AI open source.
Informasi modelSeri Qwen2 mencakup 5 ukuran model dasar dan model yang disesuaikan dengan perintah, termasuk Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, dan Qwen2-72B. Kami menjelaskan informasi penting untuk setiap model dalam tabel di bawah ini:
Model Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Parameter 049 juta 154 juta 707B57.41B72.71B# Parameter non-Emb 035 juta 131B598 juta 5632 juta 7021B Jaminan kualitas benar-benar benar benar ikatan yang tertanam benar benar salah salah salah salah konteks panjangnya 32 ribu 32 ribu 128 ribu 64 ribu 128 ribuSecara khusus, di Qwen1.5, hanya Qwen1.5-32B dan Qwen1.5-110B yang menggunakan Group Query Attention (GQA). Kali ini, kami menerapkan GQA untuk semua ukuran model sehingga mereka dapat menikmati manfaat kecepatan yang lebih tinggi dan penggunaan memori yang lebih kecil dalam inferensi model. Untuk model kecil, kami lebih suka menerapkan penyematan pengikatan karena penyematan renggang yang besar menyumbang sebagian besar dari total parameter model.
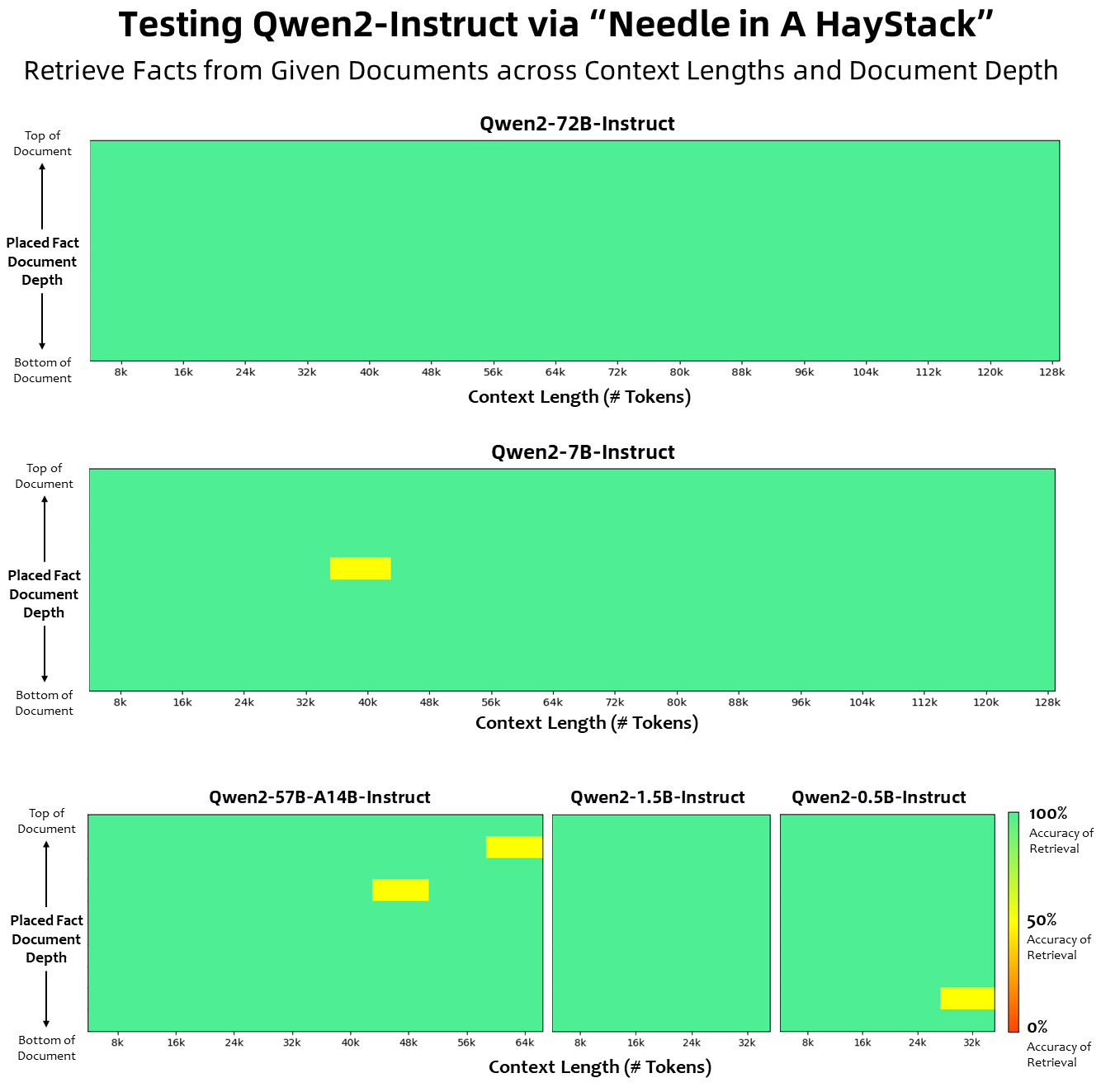
Dalam hal panjang konteks, semua model bahasa dasar telah dilatih sebelumnya pada data panjang konteks sebanyak 32 ribu token, dan kami mengamati kemampuan ekstrapolasi yang memuaskan hingga 128 ribu dalam evaluasi PPL. Namun, untuk model yang disesuaikan dengan instruksi, kami tidak puas hanya dengan evaluasi PPL; kami memerlukan model tersebut agar dapat memahami konteks panjang dengan benar dan menyelesaikan tugas. Dalam tabel, kami mencantumkan kemampuan panjang konteks model penyetelan instruksi, sebagaimana dinilai melalui evaluasi pada tugas Needlein a Haystack. Perlu dicatat bahwa ketika ditingkatkan dengan YARN, model Qwen2-7B-Instruct dan Qwen2-72B-Instruct menunjukkan kemampuan yang mengesankan dan dapat menangani panjang konteks hingga 128 ribu token.
Kami telah melakukan upaya signifikan untuk meningkatkan kuantitas dan kualitas kumpulan data pra-pelatihan dan penyesuaian instruksi yang mencakup berbagai bahasa selain Inggris dan Mandarin untuk meningkatkan kemampuan multibahasanya. Meskipun model bahasa besar memiliki kemampuan bawaan untuk menggeneralisasi ke bahasa lain, kami secara eksplisit menekankan penyertaan 27 bahasa lain dalam pelatihan kami:
Bahasa Daerah Eropa Barat Jerman, Perancis, Spanyol, Portugis, Italia, Belanda Eropa Timur dan Tengah Rusia, Ceko, Polandia Arab Timur Tengah, Persia, Ibrani, Turki Asia Timur Jepang, Korea Asia Tenggara Vietnam, Thai, Indonesia, Melayu, Lao, Burma, Cebuano, Khmer, Tagalog Hindi Asia Selatan, Bengali, UrduSelain itu, kami berupaya keras untuk memecahkan masalah transcoding yang sering muncul dalam penilaian multibahasa. Oleh karena itu, kemampuan model kami untuk menangani fenomena ini meningkat secara signifikan. Evaluasi yang menggunakan isyarat yang biasanya menimbulkan alih kode lintas bahasa mengkonfirmasi adanya pengurangan signifikan dalam masalah terkait.
PertunjukanHasil uji komparatif menunjukkan bahwa performa model skala besar (parameter 70B+) telah meningkat secara signifikan dibandingkan dengan Qwen1.5. Tes ini berpusat pada model skala besar Qwen2-72B. Dalam hal model bahasa dasar, kami membandingkan kinerja Qwen2-72B dan model terbuka terbaik saat ini dalam hal pemahaman bahasa alami, perolehan pengetahuan, kemampuan pemrograman, kemampuan matematika, kemampuan multi-bahasa, dan kemampuan lainnya. Berkat kumpulan data yang dipilih dengan cermat dan metode pelatihan yang dioptimalkan, Qwen2-72B mengungguli model terkemuka seperti Llama-3-70B, dan bahkan mengungguli Qwen1.5- generasi sebelumnya dengan jumlah parameter yang lebih kecil 110B.
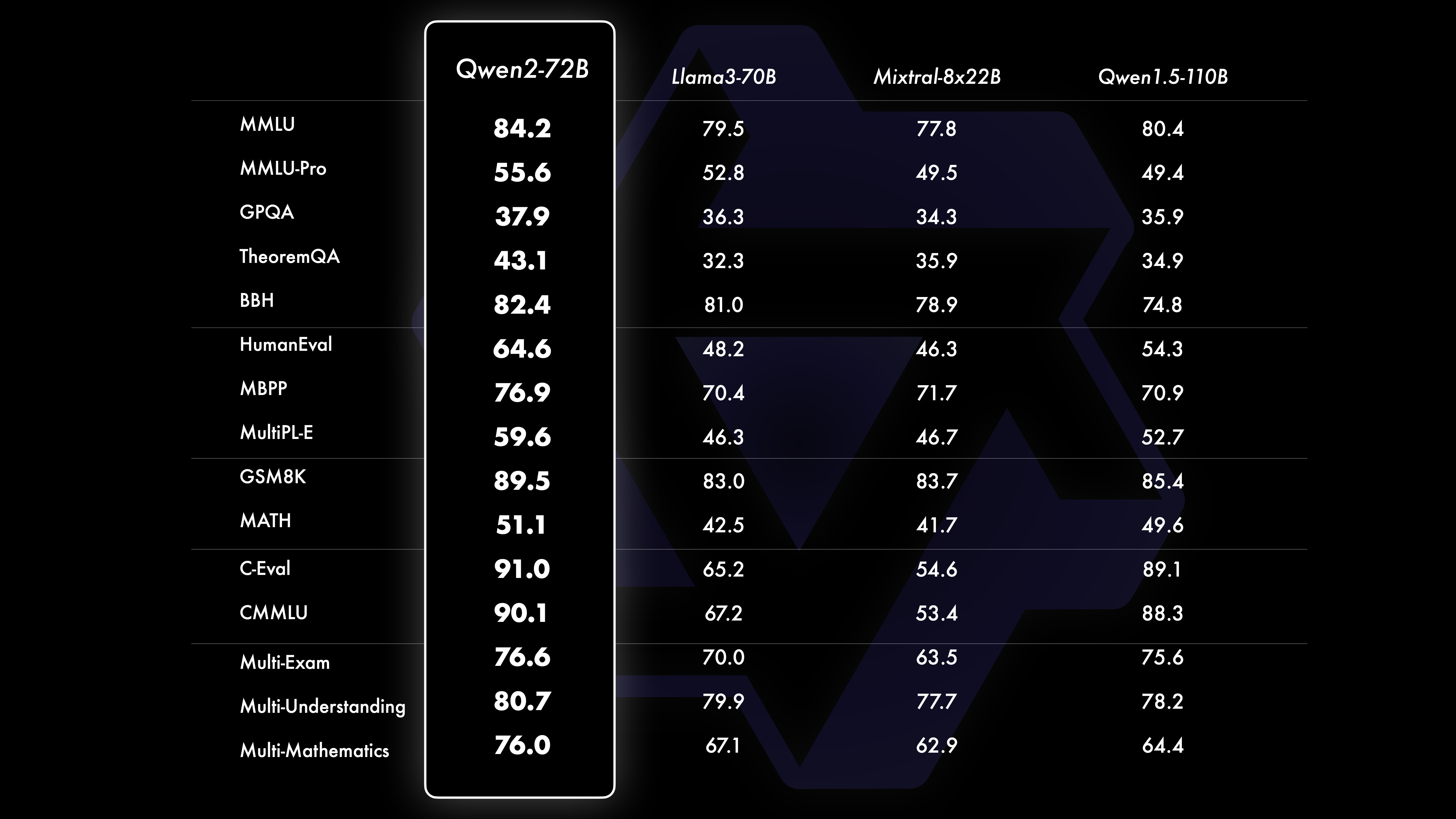
Setelah pra-pelatihan skala besar yang ekstensif, kami melakukan pasca-pelatihan untuk lebih meningkatkan kecerdasan Qwen dan membuatnya lebih dekat dengan manusia. Proses ini semakin meningkatkan kemampuan model di berbagai bidang seperti pengkodean, matematika, penalaran, mengikuti instruksi, dan pemahaman multi-bahasa. Selain itu, hal ini menyelaraskan keluaran model dengan nilai-nilai kemanusiaan, memastikan bahwa model tersebut berguna, jujur, dan tidak berbahaya. Fase pasca-pelatihan kami dirancang dengan prinsip pelatihan terukur dan anotasi manusia yang minimal. Secara khusus, kami mempelajari cara memperoleh data presentasi dan data preferensi yang berkualitas tinggi, andal, beragam, dan kreatif melalui berbagai strategi penyelarasan otomatis, seperti pengambilan sampel penolakan untuk matematika, umpan balik eksekusi untuk pengkodean dan mengikuti instruksi, dan terjemahan balik untuk penulisan kreatif. ., pengawasan permainan peran yang terukur, dan banyak lagi. Sedangkan untuk pelatihan, kami menggunakan kombinasi penyesuaian yang diawasi, pelatihan model penghargaan, dan pelatihan DPO online. Kami juga menggunakan pengoptimal penggabungan online baru untuk meminimalkan pajak penyelarasan. Upaya gabungan ini sangat meningkatkan kemampuan dan kecerdasan model kami, seperti yang ditunjukkan pada tabel di bawah.
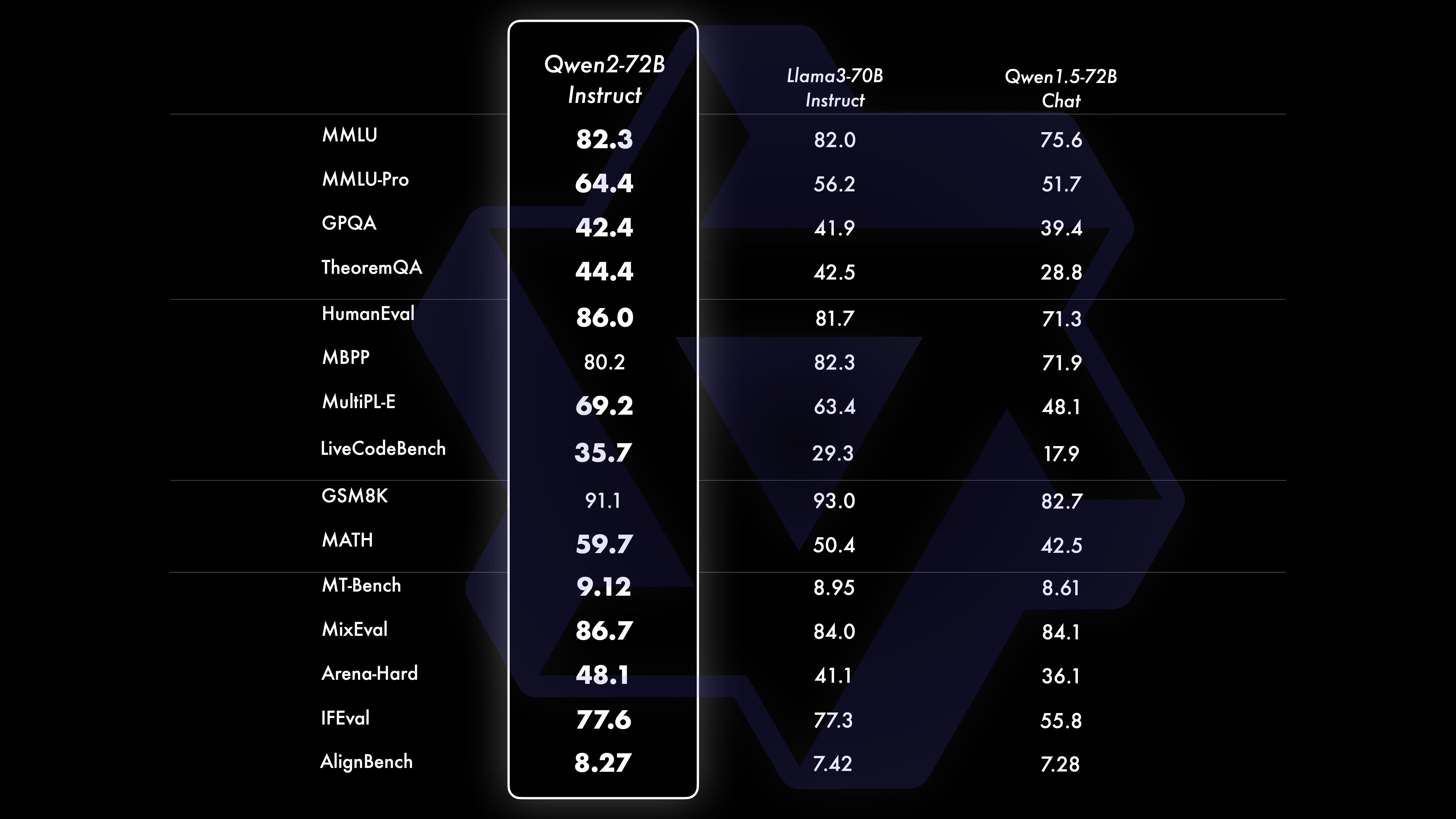
Kami melakukan evaluasi komprehensif terhadap Qwen2-72B-Instruct yang mencakup 16 benchmark di berbagai bidang. Qwen2-72B-Instruct memberikan keseimbangan antara memperoleh kemampuan yang lebih baik dan konsisten dengan nilai-nilai kemanusiaan. Secara khusus, Qwen2-72B-Instruct secara signifikan mengungguli Qwen1.5-72B-Chat di semua benchmark dan juga mencapai kinerja kompetitif dibandingkan dengan Llama-3-70B-Instruct.
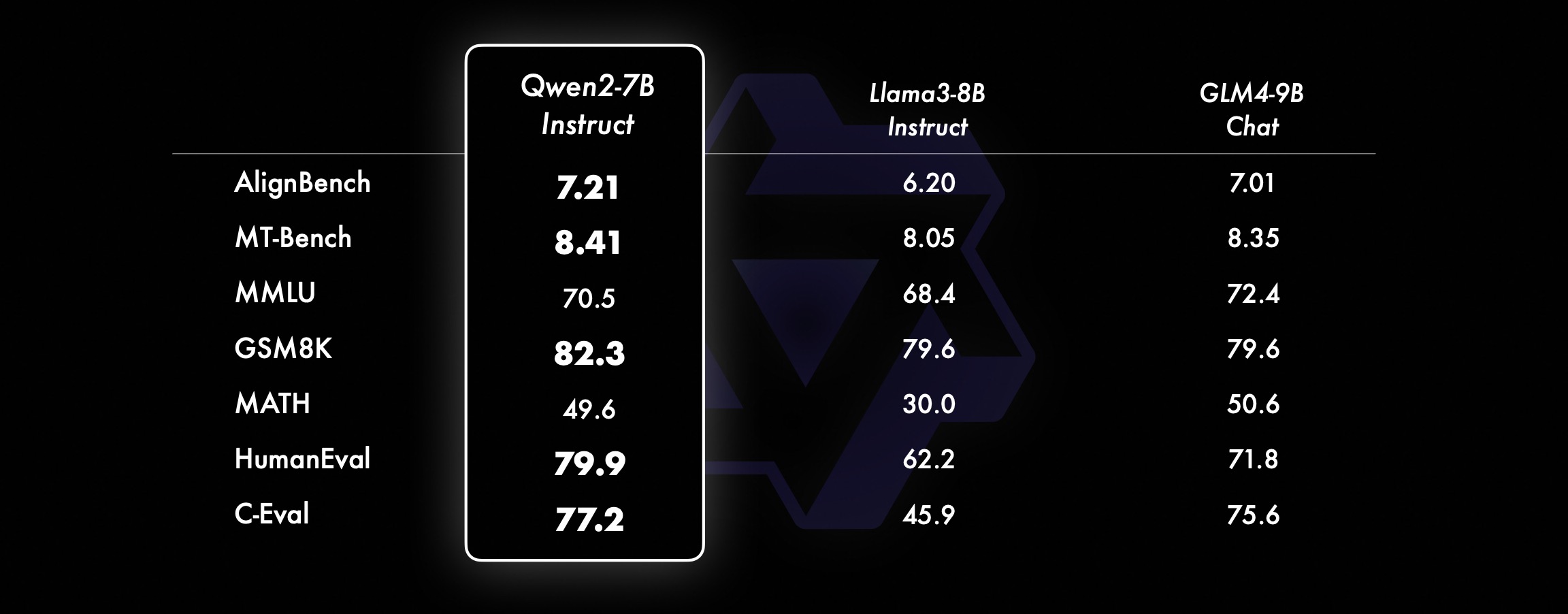
Pada model yang lebih kecil, model Qwen2 kami juga mengungguli model SOTA yang serupa dan bahkan berukuran lebih besar. Dibandingkan dengan model SOTA yang baru dirilis, Qwen2-7B-Instruct masih menunjukkan keunggulan dalam berbagai pengujian benchmark, terutama dalam pengkodean dan indikator terkait bahasa Mandarin.
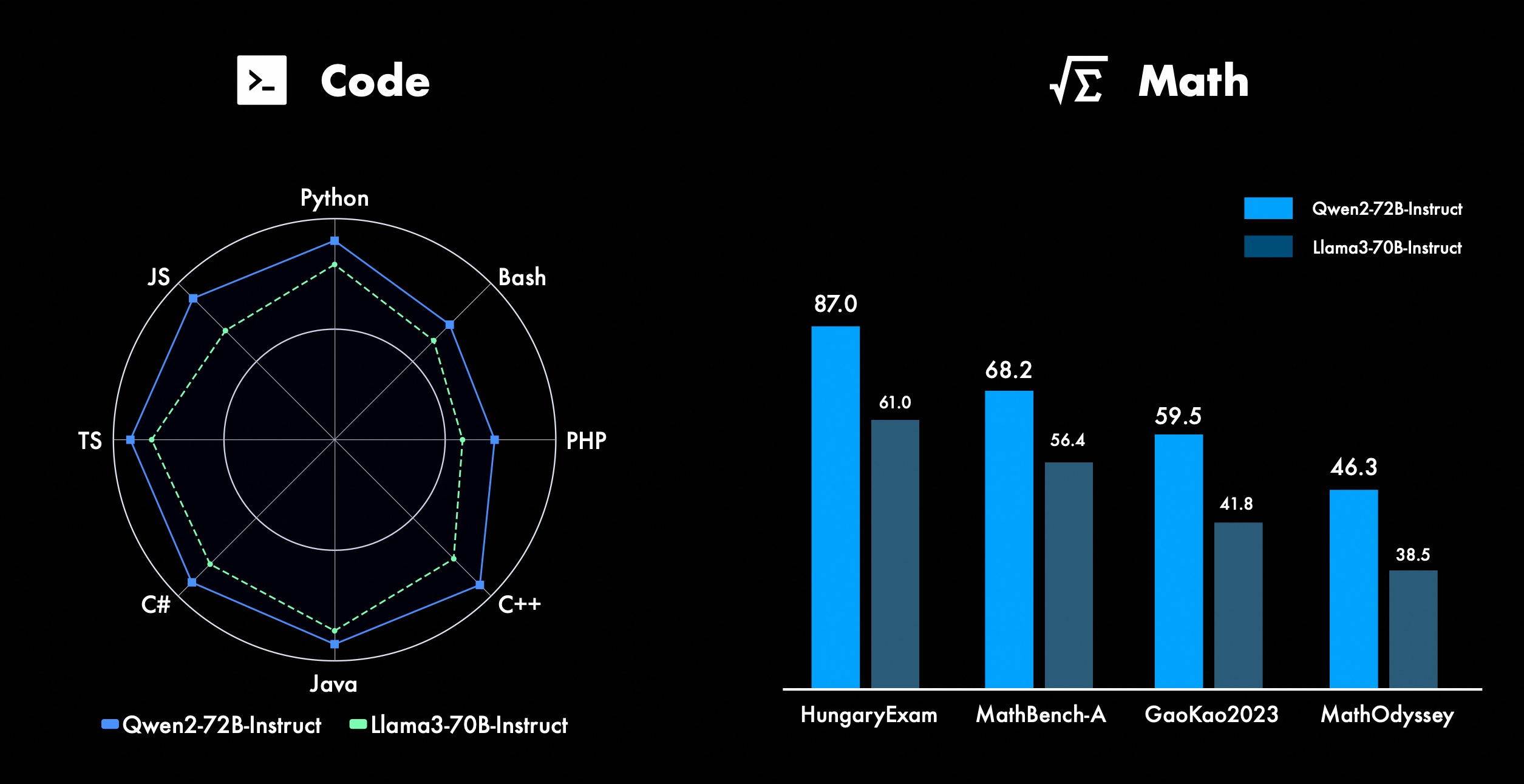
Kami terus berupaya meningkatkan fitur-fitur canggih Qwen, terutama dalam coding dan matematika. Dalam hal pengkodean, kami berhasil mengintegrasikan pengalaman pelatihan kode dan data CodeQwen1.5, sehingga Qwen2-72B-Instruct mencapai peningkatan yang signifikan dalam berbagai bahasa pemrograman. Dalam matematika, Qwen2-72B-Instruct menunjukkan peningkatan kemampuan dalam memecahkan masalah matematika dengan memanfaatkan kumpulan data yang luas dan berkualitas tinggi.
Di Qwen2, semua model penyetelan instruksi dilatih pada konteks dengan panjang 32k dan diekstrapolasi ke konteks yang lebih panjang menggunakan teknik seperti YARN atau Dual Chunk Attention.
Gambar di bawah menunjukkan hasil pengujian kami pada Needle in a Haystack. Perlu dicatat bahwa Qwen2-72B-Instruct dapat dengan sempurna menangani tugas ekstraksi informasi dalam konteks 128k. Ditambah dengan kinerja kuat yang melekat, ini dapat digunakan ketika sumber daya mencukupi .dalam hal ini, ini menjadi pilihan pertama untuk memproses tugas teks yang panjang.
Selain itu, perlu diperhatikan kemampuan mengesankan dari model lain dalam seri ini: Qwen2-7B-Instruct menangani konteks hingga 128k dengan hampir sempurna, Qwen2-57B-A14B-Instruct mengelola konteks hingga 64k, dan seri Keduanya model yang lebih kecil mendukung konteks 32k.
Selain model konteks panjang, kami menyediakan solusi proksi sumber terbuka untuk pemrosesan dokumen yang berisi hingga 1 juta tag secara efisien. Untuk detail lebih lanjut, lihat postingan blog khusus kami tentang topik ini.
Tabel di bawah menunjukkan proporsi respons berbahaya yang dihasilkan oleh model besar untuk empat kategori kueri tidak aman multibahasa (aktivitas ilegal, penipuan, pornografi, kekerasan pribadi). Data pengujian berasal dari Jailbreak dan diterjemahkan ke berbagai bahasa untuk evaluasi. Kami menemukan bahwa Llama-3 tidak menangani isyarat multibahasa secara efisien dan oleh karena itu tidak menyertakannya dalam perbandingan. Melalui uji signifikansi (P_value), kami menemukan bahwa performa keamanan model Qwen2-72B-Instruct setara dengan GPT-4, dan secara signifikan lebih baik dibandingkan model Mistral-8x22B.
Bahasa Aktivitas Ilegal Penipuan Pornografi Kekerasan Privasi GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Bahasa Mandarin0%13%0 %0%17%0%43%47%53%0%10%0%Bahasa Inggris0%7%0%0%23% 0%37%67%63%0%27%3%Piutang usaha0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%Prancis0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%point0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%rata-rata0%8%0% 3%11%2%27%39%31%3%16%2% menggunakan Qwen2 untuk pengembanganSaat ini, semua model telah dirilis di Hugging Face dan ModelScope. Anda dipersilakan untuk mengunjungi kartu model untuk melihat detail metode penggunaan dan mempelajari lebih lanjut tentang karakteristik, kinerja, dan informasi lain dari setiap model.
Sejak lama, banyak teman yang mendukung pengembangan Qwen, termasuk fine-tuning (Axolotl, Llama-Factory, Firefly, Swift, XTuner), kuantifikasi (AutoGPTQ, AutoAWQ, Neural Compressor), deployment (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), Platform API (Bersama, Kembang Api, OpenRouter), Proses Lokal (MLX, Llama.cpp, Ollama, LM Studio), Agen dan Kerangka RAG (LlamaIndex, CrewAI, OpenDevin), Evaluasi (LMSys, OpenCompass, Open LLM Leaderboard), pelatihan model (Dolphin, Openbuddy), dll. Tentang cara menggunakan Qwen2 dengan framework pihak ketiga, silakan merujuk ke dokumentasi masing-masing serta dokumentasi resmi kami.

Masih banyak tim dan individu yang berkontribusi terhadap Qwen yang belum kami sebutkan. Kami dengan tulus menghargai dukungan mereka dan berharap kolaborasi kami akan mendorong penelitian dan pengembangan komunitas AI open source.
lisensiKali ini, kami mengubah izin model ke izin lain. Qwen2-72B dan model penyetelan instruksinya masih menggunakan Lisensi Qianwen asli, sementara semua model lainnya, termasuk Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B dan Qwen2-57B-A14B, telah beralih ke Apache2.0!Kami yakin bahwa semakin terbukanya model kami kepada komunitas dapat mempercepat penerapan dan komersialisasi Qwen2 di seluruh dunia.
Apa selanjutnya untuk Qwen2?Kami sedang melatih model Qwen2 yang lebih besar untuk mengeksplorasi lebih lanjut ekstensi model serta ekstensi data terbaru kami. Selain itu, kami memperluas model bahasa Qwen2 menjadi multi-modal, yang mampu memahami informasi visual dan audio. Dalam waktu dekat, kami akan terus mengembangkan model-model baru yang bersifat open source untuk mempercepat AI open source. Pantau terus!
MengutipKami akan segera merilis laporan teknis tentang Qwen2. Selamat datang kutipan!
@article{qwen2, Lampiran Evaluasi Model Bahasa DasarEvaluasi model dasar terutama berfokus pada kinerja model seperti pemahaman bahasa alami, menjawab pertanyaan umum, pengkodean, matematika, pengetahuan ilmiah, penalaran, dan kemampuan multibahasa.
Kumpulan data yang dievaluasi meliputi:
Tugas Bahasa Inggris: MMLU (5 kali), MMLU-Pro (5 kali), GPQA (5 kali), Teorema QA (5 kali), BBH (3 kali), HellaSwag (10 kali), Winogrande (5 kali), TruthfulQA ( 0 kali), ARC-C (25 kali)
Tugas pengkodean: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Tugas Matematika: GSM8K (4 kali), MATEMATIKA (4 kali)
Tugas Tiongkok: C-Eval (5 tembakan), CMMLU (5 tembakan)
Tugas multibahasa: ujian ganda (M3Exam 5 kali, IndoMMLU 3 kali, ruMMLU 5 kali, mmMLU 5 kali), pemahaman ganda (BELEBELE 5 kali, XCOPA 5 kali, XWinograd 5 kali, XStoryCloze 0 kali, PAWS-X 5 kali) , matematika ganda (MGSM 8 kali), terjemahan ganda (Flores-1015 kali)
Set Data Kinerja Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArsitekturKementerian PendidikanDenseDenseDenseDenseDense#Parameter Aktif 21B39B70B72B110B72B#Parameter 236B140B70B72B1 10B72B Bahasa Inggris Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Edisi Profesional-49.552. 845.849.455.6Jaminan Mutu-34.336.336.335.937.9Tanya Jawab Teorema-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Shiraswag 87.888.788.086 87.6 Jendela Besar 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 Tanya Jawab yang Jujur 42.251.045.659.649.654.8 Penilaian Tenaga Kerja Pengkodean 45.746.348.246.354.364.6 Departemen Pelayanan Publik Malaysia 73 .971.770.466.970.976.9 Penilaian 55.054.154.852.957.765.4 Berbagai 44.446.746.341.852.759.6 Matematika GSM8K79. 283.783.079.585.489.5 Matematika 43.641.742.534.149.651.1 Penilaian C Bahasa Mandarin 81.754.665. 284.189.191.0 Universitas Montreal, Kanada 84.053 .467.283.588.390.1Beberapa bahasa dan banyak ujian 67 .563.570.066.475.676.6Pemahaman ganda 77.077.779.978.278.280.7Beberapa matematika 58.862.967.161.764.476.0Beberapa terjemahan 36.023.338.035.636.2 37.8Qwen2-57B-A14B Dataset Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32 BQwen2-57B-A14B Arsitektur MoE MoE Padat Padat MoE #Parameter Aktif 12B12B34B32B14B #Parameter 52B47B34B32B57B Bahasa Inggris Moleman Lu 67.471.877.174.376.5MMLU - Edisi Profesional - 41.048.344.043.0 Jaminan Kualitas - 29.2 - 30.834.3 Teorema Tanya Jawab - 23. 2 - 28.833.5 Baibei Hitam 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Tanya Jawab Jujur 46.451.153.957.457.7 Coding Manpower Assessment 29.337.246.343.35 3,0 Pelayanan Publik Malaysia - 63.965.564.271.9 Penilaian - 46.451 .950.457.2 Beragam - 39.03 9.538.549 .8 Matematika GSM8K59.962.582.776.880.7 Matematika-30.841.736.143.0 Penilaian C Cina---83.587.7 Universitas Montreal, Kanada--84.882.388.5 Berbagai bahasa dan ujian ganda-56.158.361.665.5 Pemahaman multi pihak -70.773.976.577.0Beberapa Matematika -45.049.356.162.3Beberapa Terjemahan -29.830.033.534.5Qwen2-7B Dataset Mistral -7B Jemma -7B Unta -3-8BQwen1.5 -7BQwen2-7B# Parameter 7.2B850 juta 8.0B7.7B7.6B# Parameter non-emb 7.0B780 juta 7.0B650 juta 650 juta English Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Jaminan kualitas 24.725 .725.826. 731.8 Teorema Tanya Jawab 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 .3 54.260.6Tanya Jawab Jujur 42.244 .844.051.154.2 Asesmen Tenaga Kerja Coding 29.337.233.536 .051.2 Pelayanan Publik Malaysia 51.150.653.951.665.9 Penilaian 36.439.640.340.054.2 Berganda 29.429.722.628.146.3 Matematika GSM8K52.246.456.0 62.579.9 Matematika 13.124.320.520.344.2 Cina Penilaian C Manusia 47.443.649.574.183.2 Université de Montréal , Kanada -- 50.873.183.9 Ujian Ganda Multibahasa 47.142.752.347.759.2 Pemahaman Ganda 63.358.368.667.672.0 Matematika Multivariat 26.339.136.337.357.5 Terjemahan Ganda 23.331.231 .928.431.5Qwen2 -0. Kumpulan data 5B dan Qwen2-1.5B Phi-2Gemma -2B BPS Minimum Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Parameter non-Emb 250 juta 2.0B2.4B1.3B035 juta 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Teorema Tanya Jawab----8.915.0 Penilaian Tenaga Kerja 47.622.050.020.122.031.1 Departemen Pelayanan Publik Malaysia 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Matematika 3.511.810.210.110.72 1.7 Baibi Hitam 43.435.236.924.228.437. 2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Tanya Jawab Jujur 44.533.1-39.439.745.9C - Evaluasi 23.428.05 1.159.758.270.6 Universitas Montreal, Kanada 24.2 - 51.157.855.170.3 Instruksi Evaluasi Model Penyetelan Qwen2-72B - Kumpulan Data Terpandu Unta - 3-70B - Panduan Qwen1.5-72B - Obrolan Qwen2-72B - Panduan Bahasa Inggris Mohr Man Lu 82.075.682.3MMLU - Edisi Profesional 56.251. 764.4 Jaminan Kualitas 41.939.442.4 Teorema Tanya Jawab 42.528.844.4MT - Bench8.958.619.12 Arena - Keras 41.136.148.1 IFEval (Akses Ketat Cepat) 77.355.877.6 Penilaian Tenaga Kerja Pengkodean 81.771.386.0 Pelayanan Publik Malaysia 82. 371.980.2 Kelipatan 63.448.169.2 Penilaian 75.266.979.0 Tes Kode Langsung 29.317.935.7 Matematika GSM 8K93.082.7 91. 1 Matematika 50.442.559.7 Evaluasi C Cina 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMixtral-8x7B -Instruksikan-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Arsitektur Panduan Kementerian Pendidikan Padat Kementerian Pendidikan #Parameter aktif 12B34B32B14B #Parameter 47B34B32B57B Bahasa Inggris Mohr Man Lu 71.476.874.875.4MMLU - Edisi Profesional 43.352.346.452 .8 Kualitas Assurance -- 30.834.3 Soal Jawab Teorema - -30.933.1MT-Bench8.308.508.308.55 Coding Manpower Assessment 45.175.268.379.9 Public Service Malaysia 59.574.667.970.9 Beragam --50.766.4 Assessment 48.5-63.671.6 Live Tes Kode 12.3-15.225.5 Matematika GSM8K65.790.283.679.6 Matematika 30.750.142.449.1 Evaluasi C Cina--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Dataset Camel-3-8B-Guide Yi-1.5-9B -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Panduan Bahasa Inggris Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Jaminan Kualitas 34.2--27.825.3 Teorema Tanya Jawab 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 Pengkodean Kemanusiaan 62.266.571.846.379.9 Pelayanan Publik Malaysia 67.9--48.967.2 Kelipatan 48.5--27.259.1 Penilaian 60.9--44.870.3 Tes Kode Langsung 17.3-- 6.0 26. 6 Math GSM8K79.684.879.660.382.3 Math 30.047.750.623.249.6 Chinese C-Assessment 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct dan Qwen2-1.5B-Instruct Data set Q saat1.5- 0.5B-Chat Qwen2-0.5B-Panduan Qwen1.5-1.8B-Chat Qwen2-1.5B-Panduan Morman Lu35.037.943.752.4 Penilaian Tenaga Kerja 9.117.125.037.8GSM8K11.340.135.361.6C-Penilaian 37.245.255.363. 8IFEval ( prompt untuk akses ketat) perintah 14.620.016.829.0 menyesuaikan kemampuan multi-bahasa modelKami membandingkan model penyetelan instruksi Qwen2 dengan LLM terbaru lainnya pada beberapa tolok ukur terbuka lintas bahasa serta evaluasi manusia. Sebagai baseline, kami menyajikan hasil pada 2 dataset evaluasi:
M-MMLU Okapi: Penilaian pengetahuan umum multibahasa (kami menggunakan subset dari ar, de, es, fr, it, nl, ru, uk, vi, zh untuk penilaian) MGSM: untuk penilaian Jerman, Inggris, Spanyol, Prancis, Matematika dalam Bahasa Jepang, Rusia, Thailand, Cina, dan BrasilHasilnya dirata-ratakan antar bahasa untuk setiap tolok ukur dan adalah sebagai berikut:
Teladan M-MMLU (5 tembakan) MGSM (0 tembakan, CoT) LLM Kepemilikan GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 sumber terbuka LL.M perintah-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Panduan 60.057.0Qwen2-57B-A14B-Panduan 68.074.0Qwen2-72B-Panduan 78.086.6Untuk evaluasi manual, kami membandingkan Qwen2-72B-Instruct dengan GPT3.5, GPT4, dan Claude-3-Opus menggunakan set evaluasi internal, yang mencakup 10 bahasa ar, es, fr, ko, th, vi, pt, id , ja dan ru (kisaran skor dari 1 hingga 5):
Model Piutang Usaha Spanyol Perancis Corri Enam Poin ID Jiaru Rata-rata Claude-3-Pekerjaan-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93,7 24.324.09 GPT-4-Turbo- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Panduan 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923 .943.873.833.953.553.773.063.633.71GPT- 3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16Dikelompokkan berdasarkan jenis tugas, hasilnya sebagai berikut:
Model Pengetahuan Pemahaman Membuat Matematika Claude-3-Karya-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT- 4-0 6133.424.094.103. 32GPT-3.5-Turbo-11063.373.673.892.97Hasil ini menunjukkan kemampuan multibahasa yang kuat dari model penyetelan instruksi Qwen2.
Model seri Qwen2 open source Alibaba telah meningkatkan kinerja dan kemampuan multi-bahasa secara signifikan, sehingga memberikan kontribusi penting bagi komunitas AI open source. Di masa depan, Qwen2 akan terus mengembangkan dan memperluas skala model dan kemampuan multimoda, yang patut dinantikan.