CoPilot
v0.9.0
2024 年 8 月 21 日: CoPilot は v0.9 (v0.9.0) で利用可能になりました。詳細については、リリースノートを参照してください。注: TigerGraph Cloud では、CoPilot v0.5 のみが利用可能です。
2024 年 4 月 30 日: CoPilot はベータ版 (v0.5.0) で利用可能になりました。まったく新しい機能が CoPilot に追加されました。独自のドキュメント上でグラフ拡張 AI を備えたチャットボットを作成できるようになりました。 CoPilot は、ソース資料からナレッジ グラフを構築し、ナレッジ グラフ RAG (検索拡張生成) を適用して、自然言語の質問に対する文脈の関連性と回答の精度を向上させます。より多くの価値を提供できるよう改善を続けるために、皆様からのフィードバックをお待ちしております。 CoPilot で遊んだ後、この短いアンケートにご記入いただけると助かります。ご関心とご支援をいただきありがとうございます!
2024 年 3 月 18 日: CoPilot はアルファ版 (v0.0.1) で利用可能になりました。 Large Language Model (LLM) を使用して質問を関数呼び出しに変換し、TigerGraph のグラフ上で実行します。より多くの価値を提供できるよう改善を続けるために、皆様からのフィードバックをお待ちしております。お試し中の方は、こちらのサインアップ フォームに記入していただければ、追跡できるようになるので助かります (スパムではないことをお約束します)。フィードバックを提供したいだけの場合は、お気軽にこの短いアンケートにご記入ください。ご関心とご支援をいただきありがとうございます!
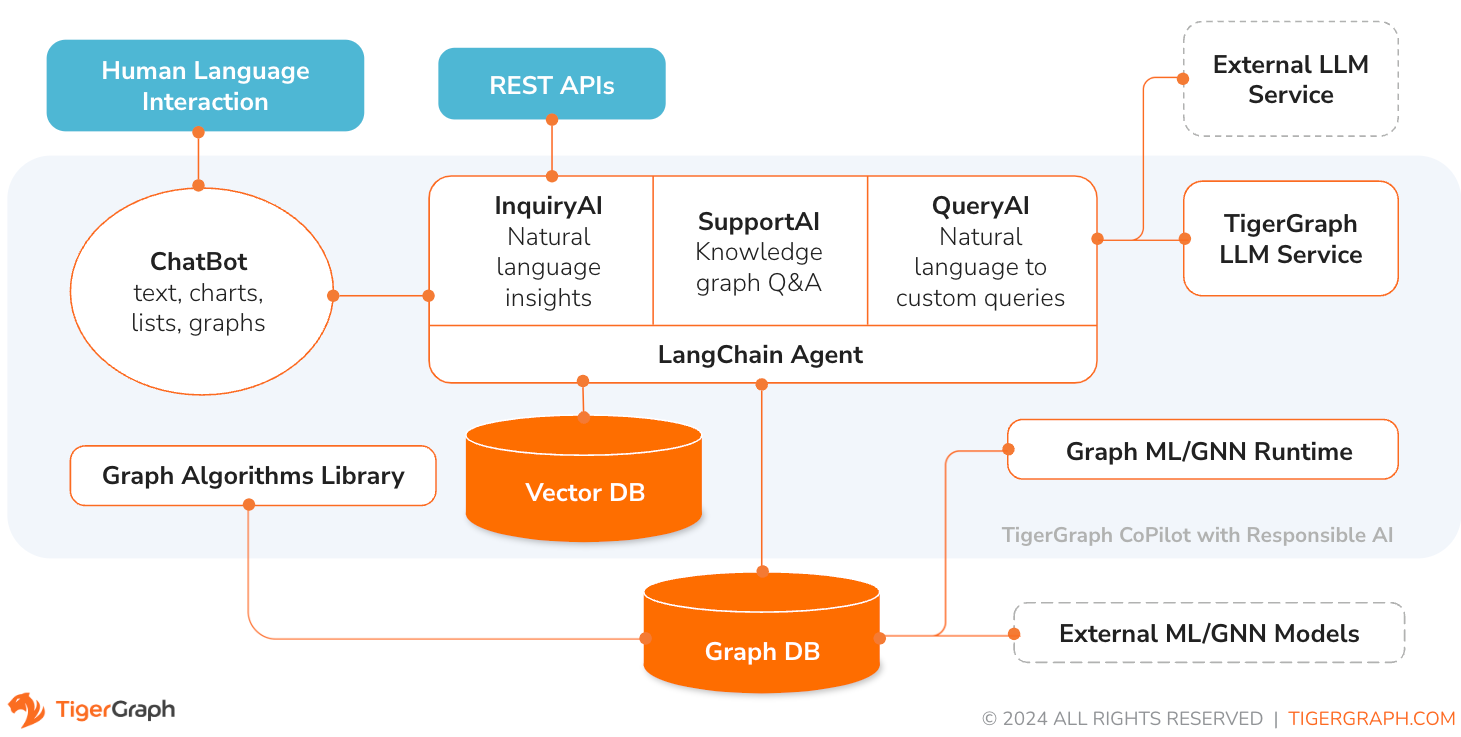
TigerGraph CoPilot は、グラフ データベースと生成 AI の力を組み合わせてデータから最大限の価値を引き出し、分析、開発、管理タスクなどのさまざまなビジネス機能全体の生産性を向上させるように細心の注意を払って設計された AI アシスタントです。これは、次の 3 つのコア コンポーネント サービスを備えた 1 つの AI アシスタントです。
TigerGraph Cloud 上のチャット インターフェイス、組み込みのチャット インターフェイスおよび API を通じて CoPilot と対話できます。現時点では、CoPilot を使用するには独自の LLM サービス (OpenAI、Azure、GCP、AWS Bedrock、Ollama、Hugging Face、Groq など) が必要ですが、将来のリリースでは TigerGraph の LLM を使用できるようになります。
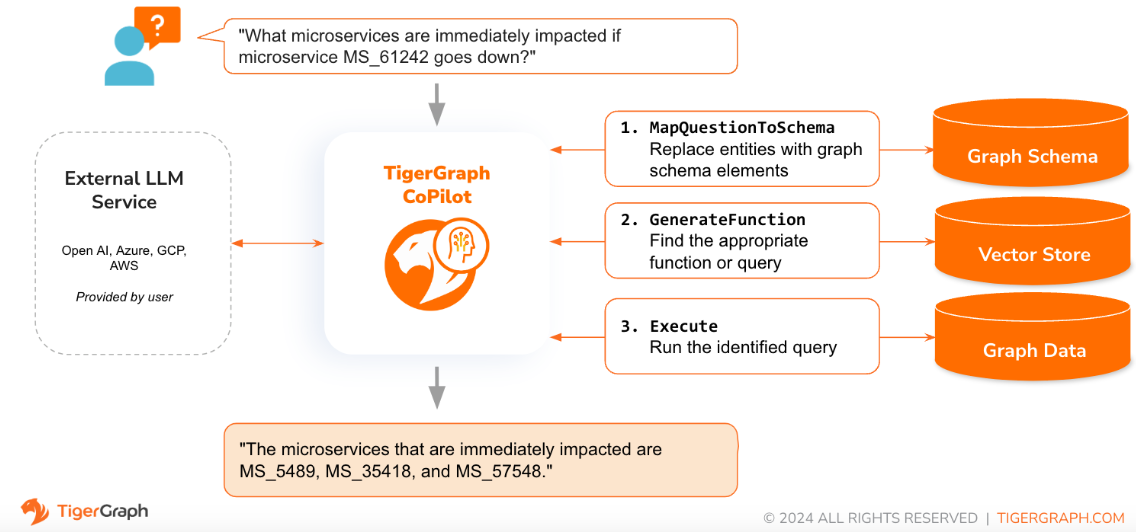
質問が自然言語で提起されると、CoPilot (RecruitAI) は、TigerGraph データベースとユーザーが選択した LLM の両方との新しい 3 フェーズ インタラクションを採用し、正確で適切な応答を取得します。
最初のフェーズでは、質問をデータベース内で利用可能な特定のデータと照合します。 CoPilot は LLM を使用して質問とグラフのスキーマを比較し、質問内のエンティティをグラフ要素に置き換えます。たとえば、「BareMetalNode」という頂点タイプがあり、ユーザーが「サーバーはいくつありますか?」と尋ねた場合、その質問は「BareMetalNode 頂点は何個ありますか?」と変換されます。第 2 フェーズでは、CoPilot は LLM を使用して、変換された質問を厳選されたデータベース クエリおよび関数のセットと比較し、最も一致するものを選択します。 3 番目のフェーズでは、CoPilot が特定されたクエリを実行し、アクションの背後にある理由とともに結果を自然言語で返します。
事前承認されたクエリを使用すると、複数の利点が得られます。何よりもまず、各クエリの意味と動作が検証されているため、幻覚の可能性が軽減されます。第 2 に、システムには、質問に答えるために必要な実行リソースを予測できる可能性があります。
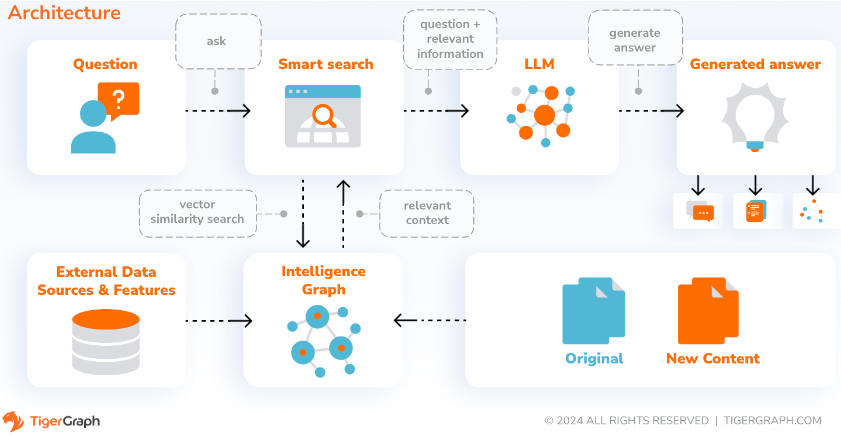
SupportAI を使用すると、CoPilot はユーザー自身のドキュメントまたはテキスト データを基にグラフ拡張 AI を備えたチャットボットを作成します。ソース資料からナレッジ グラフを構築し、独自のナレッジ グラフ ベースの RAG (検索拡張生成) を適用して、自然言語の質問に対する文脈の関連性と回答の精度を向上させます。
また、CoPilot は概念を特定してオントロジーを構築し、セマンティクスと推論をナレッジ グラフに追加するか、ユーザーが独自の概念オントロジーを提供することもできます。次に、この包括的なナレッジ グラフを使用して、CoPilot は従来のベクトル検索とグラフ トラバーサルを組み合わせたハイブリッド検索を実行して、ユーザーの知識に関する質問に答えるためのより関連性の高い情報とより豊富なコンテキストを収集します。
データをナレッジ グラフとして整理することで、チャットボットは正確で事実に基づいた情報に迅速かつ効率的にアクセスできるようになり、トレーニング中に学習したパターン (不正確または古い場合がある) から応答を生成することへの依存が軽減されます。
QueryAI は、TigerGraph CoPilot の 3 番目のコンポーネントです。これは、英語の記述から GSQL でグラフ クエリを生成するのに役立つ開発者ツールとして使用するように設計されています。スキーマ、データ マッピング、さらにはダッシュボードの生成にも使用できます。これにより、開発者は GSQL クエリをより迅速かつ正確に作成できるようになり、GSQL を初めて使用する開発者にとって特に役立ちます。現在、実験的な openCypher 生成が利用可能です。
CoPilot は、TigerGraph Cloud 上のワークスペースへのアドオン サービスとして利用できます。デフォルトでは無効になっています。 TigerGraph CoPilot をマーケットプレイスのオプションとして有効にするには、[email protected] にお問い合わせください。
TigerGraph CoPilot は、GitHub 上のオープンソース プロジェクトであり、独自のインフラストラクチャにデプロイできます。
CoPilot のソース コードを拡張する必要がない場合、最も簡単な方法は、リポジトリ内の docker compose ファイルを使用してその docker イメージをデプロイすることです。このルートを選択するには、次の前提条件が必要です。
ステップ 1: docker-compose ファイルを取得する
git clone https://github.com/tigergraph/CoPilot Docker Compose ファイルには、Milvus データベースを含む CoPilot のすべての依存関係が含まれています。特定のサービスが必要ない場合は、Compose ファイルを編集して削除するか、Compose ファイルの実行時にスケールを 0 に設定します (詳細は後述)。さらに、CoPilot の展開時には、Swagger API ドキュメント ページが付属します。これを無効にしたい場合は、Compose ファイルで CoPilot サービスのPRODUCTION環境変数を true に設定します。
ステップ 2: 構成をセットアップする
次に、Docker Compose ファイルと同じディレクトリに、次の構成ファイルを作成して入力します。
ステップ 3 (オプション): ロギングを構成する
touch configs/log_config.json 。構成の詳細については、こちらをご覧ください。
ステップ 4: すべてのサービスを開始する
ここで、 docker compose up -dを実行して、すべてのサービスが開始されるのを待ちます。付属の Milvus DB を使用したくない場合は、そのスケールを 0 に設定して起動しないようにできます: docker compose up -d --scale milvus-standalone=0 --scale etcd=0 --scale minio=0 。
ステップ 5: UDF をインストールする
この手順は、TigerGraph データベース バージョン 4.x では必要ありません。 TigerGraph 3.x の場合、CoPilot が動作するには、いくつかのユーザー定義関数 (UDF) をインストールする必要があります。
sudo su - tigergraphに切り替えます。 TigerGraph がクラスター上で実行されている場合は、どのマシンでもこれを行うことができます。 gadmin config set GSQL.UDF.EnablePutTgExpr true
gadmin config set GSQL.UDF.Policy.Enable false
gadmin config apply
gadmin restart GSQL
PUT tg_ExprFunctions FROM "./tg_ExprFunctions.hpp"
PUT tg_ExprUtil FROM "./tg_ExprUtil.hpp"
gadmin config set GSQL.UDF.EnablePutTgExpr false
gadmin config set GSQL.UDF.Policy.Enable true
gadmin config apply
gadmin restart GSQL
configs/llm_config.jsonファイルで、LLM プロバイダー用に以下から JSON 構成テンプレートをコピーし、適切なフィールドに入力します。必要なプロバイダーは 1 つだけです。
OpenAI
OPENAI_API_KEYに加えて、 llm_modelおよびmodel_nameを編集して、特定の構成の詳細に一致させることができます。
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " openai " ,
"llm_model" : " gpt-4-0613 " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}GCP
https://cloud.google.com/docs/authentication/application-default-credentials#GAC にある GCP 認証情報に従い、VertexAI 認証情報を使用してサービス アカウントを作成します。次に、docker run コマンドに以下を追加します。
-v $( pwd ) /configs/SERVICE_ACCOUNT_CREDS.json:/SERVICE_ACCOUNT_CREDS.json -e GOOGLE_APPLICATION_CREDENTIALS=/SERVICE_ACCOUNT_CREDS.jsonJSON 構成は次のようになります。
{
"model_name" : " GCP-text-bison " ,
"embedding_service" : {
"embedding_model_service" : " vertexai " ,
"authentication_configuration" : {}
},
"completion_service" : {
"llm_service" : " vertexai " ,
"llm_model" : " text-bison " ,
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/gcp_vertexai_palm/ "
}
}アズール
AZURE_OPENAI_ENDPOINT 、 AZURE_OPENAI_API_KEY 、およびazure_deploymentに加えて、 llm_modelおよびmodel_name編集して、特定の構成の詳細に一致させることができます。
{
"model_name" : " GPT35Turbo " ,
"embedding_service" : {
"embedding_model_service" : " azure " ,
"azure_deployment" : " YOUR_EMBEDDING_DEPLOYMENT_HERE " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"OPENAI_API_VERSION" : " 2022-12-01 " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " azure " ,
"azure_deployment" : " YOUR_COMPLETION_DEPLOYMENT_HERE " ,
"openai_api_version" : " 2023-07-01-preview " ,
"llm_model" : " gpt-35-turbo-instruct " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/azure_open_ai_gpt35_turbo_instruct/ "
}
}AWS の基盤
{
"model_name" : " Claude-3-haiku " ,
"embedding_service" : {
"embedding_model_service" : " bedrock " ,
"embedding_model" : " amazon.titan-embed-text-v1 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
}
},
"completion_service" : {
"llm_service" : " bedrock " ,
"llm_model" : " anthropic.claude-3-haiku-20240307-v1:0 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
},
"model_kwargs" : {
"temperature" : 0 ,
},
"prompt_path" : " ./app/prompts/aws_bedrock_claude3haiku/ "
}
}オラマ
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " ollama " ,
"llm_model" : " calebfahlgren/natural-functions " ,
"model_kwargs" : {
"temperature" : 0.0000001
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}ハグフェイス
専用エンドポイントを使用した Hugging Face のモデルの構成例を以下に示します。構成の詳細を指定してください:
{
"model_name" : " llama3-8b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " hermes-2-pro-llama-3-8b-lpt " ,
"endpoint_url" : " https:endpoints.huggingface.cloud " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}サーバーレス エンドポイントを使用した Hugging Face のモデルの構成例を以下に示します。構成の詳細を指定してください:
{
"model_name" : " Llama3-70b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " meta-llama/Meta-Llama-3-70B-Instruct " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/llama_70b/ "
}
}グロク
{
"model_name" : " mixtral-8x7b-32768 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " groq " ,
"llm_model" : " mixtral-8x7b-32768 " ,
"authentication_configuration" : {
"GROQ_API_KEY" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}以下をconfigs/db_config.jsonにコピーし、データベースの構成と一致するようにhostnameとgetTokenフィールドを編集します。 TigerGraph でトークン認証が有効になっている場合は、 getToken trueに設定します。タイムアウト、メモリしきい値、スレッド制限パラメータを必要に応じて設定し、質問に回答するときに消費されるデータベース リソースの量を制御します。
「ecc」と「chat_history_api」はCoPilotの内部コンポーネントのアドレスです。Docker Composeファイルをそのまま使用する場合は変更する必要はありません。
{
"hostname" : " http://tigergraph " ,
"restppPort" : " 9000 " ,
"gsPort" : " 14240 " ,
"getToken" : false ,
"default_timeout" : 300 ,
"default_mem_threshold" : 5000 ,
"default_thread_limit" : 8 ,
"ecc" : " http://eventual-consistency-service:8001 " ,
"chat_history_api" : " http://chat-history:8002 "
}以下をconfigs/milvus_config.jsonにコピーし、Milvus 構成に一致するようにhostとportフィールドを編集します (Docker 構成を念頭に置きます)。 Milvus セットアップで必要な場合は、 usernameとpassword以下で設定することもできます。 Milvus のみがサポートされている埋め込みストアであるため、現時点では、 enabled常に「true」に設定する必要があります。
{
"host" : " milvus-standalone " ,
"port" : 19530 ,
"username" : " " ,
"password" : " " ,
"enabled" : " true " ,
"sync_interval_seconds" : 60
}以下のコードをconfigs/chat_config.jsonにコピーします。 Docker Compose ファイル内のチャット履歴サービスのポートを変更しない限り、何も変更する必要はありません。
{
"apiPort" : " 8002 " ,
"dbPath" : " chats.db " ,
"dbLogPath" : " db.log " ,
"logPath" : " requestLogs.jsonl " ,
"conversationAccessRoles": ["superuser", "globaldesigner"]
}RecruitAI で openCypher クエリの生成を有効にしたい場合は、docker compose ファイルの CoPilot サービスでUSE_CYPHER環境変数を"true"に設定できます。デフォルトでは、これは"false"に設定されています。注: openCypher クエリ生成はまだベータ版であるため、期待どおりに動作しない可能性があり、また、不正なコード生成により幻覚的な回答が発生する可能性が高くなります。非実稼働環境でのみ、注意して使用してください。
CoPilot は、技術ユーザーにも非技術ユーザーにもフレンドリーです。 CoPilot への API アクセスだけでなく、グラフィカル チャット インターフェイスもあります。機能的には、CoPilot はデータベース内の既存のクエリを呼び出して質問に回答し (RecruitAI)、ドキュメントからナレッジ グラフを構築し (SupportAI)、ドキュメントに基づいて知識の質問に回答します (SupportAI)。
CoPilot の使用方法については、公式ドキュメントを参照してください。
TigerGraph CoPilot は、簡単に拡張できるように設計されています。このサービスは、異なる LLM プロバイダー、異なるグラフ スキーマ、および異なる LangChain ツールを使用するように構成できます。このサービスは、さまざまな埋め込みサービス、さまざまな LLM 生成サービス、およびさまざまな LangChain ツールを使用するように拡張することもできます。サービスを拡張する方法の詳細については、開発者ガイドを参照してください。
テストのファミリーは、 testsディレクトリの下に含まれています。さらにテストを追加したい場合は、こちらのガイドを参照してください。このフォルダーには、テストを実行するためのドライバーであるシェル スクリプトrun_tests.shも含まれています。このスクリプトを使用する最も簡単な方法は、テストのために Docker コンテナ内で実行することです。
各サービスのテストを実行するには、サービスのディレクトリの最上位に移動し、 python -m pytestを実行します。
例(最上位から)
cd copilot
python -m pytest
cd ..まず、LLM サービス プロバイダーのすべての構成ファイルが適切に動作していることを確認します。構成は、コンテナーがアクセスできるようにマウントされます。また、データベースや Milvus などのすべての依存関係が準備されていることも確認してください。そうでない場合は、含まれている docker compose ファイルを実行して、それらのサービスを作成できます。
docker compose up -d --buildテスト結果のログ記録に重みとバイアスを使用する場合は、WandB API キーをホスト マシンの環境変数に設定する必要があります。
export WANDB_API_KEY=KEY HERE次に、 Dockerfile.testsファイルから Docker コンテナを構築し、コンテナ内でテスト スクリプトを実行できます。
docker build -f Dockerfile.tests -t copilot-tests:0.1 .
docker run -d -v $( pwd ) /configs/:/ -e GOOGLE_APPLICATION_CREDENTIALS=/GOOGLE_SERVICE_ACCOUNT_CREDS.json -e WANDB_API_KEY= $WANDB_API_KEY -it --name copilot-tests copilot-tests:0.1
docker exec copilot-tests bash -c " conda run --no-capture-output -n py39 ./run_tests.sh all all "実行されるテストを編集するには、 ./run_tests.shスクリプトに引数を渡すことができます。現在、どの LLM サービスを使用するか (デフォルトはすべて)、どのスキーマに対してテストするか (デフォルトはすべて)、ロギングに重みとバイアスを使用するかどうか (デフォルトは true) を構成できます。オプションの説明は以下にあります。
run_tests.shの最初のパラメータは、どの LLM に対してテストするかを指定します。デフォルトはallです。オプションは次のとおりです。
all - すべての LLM に対してテストを実行しますazure_gpt35 - Azure でホストされている GPT-3.5 に対してテストを実行しますopenai_gpt35 - OpenAI でホストされている GPT-3.5 に対してテストを実行しますopenai_gpt4 - OpenAI でホストされている GPT-4 でテストを実行しますgcp_textbison - GCP でホストされている text-bison でテストを実行しますrun_tests.shの 2 番目のパラメータは、どのグラフに対してテストするかを指定します。デフォルトはallです。オプションは次のとおりです。
all - 利用可能なすべてのグラフに対してテストを実行します。OGB_MAG - https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag によって提供される学術論文データセット。DigtialInfra - デジタル インフラストラクチャのデジタル ツイン データセットSynthea - 合成健康データセットテスト結果を Weights and Biases に記録する場合 (および上記で正しい資格情報を設定している場合)、 run_tests.shの最後のパラメータは自動的にデフォルトで true に設定されます。重みとバイアスのログを無効にしたい場合は、 false使用します。
TigerGraph CoPilot に貢献したい場合は、ここのドキュメントをお読みください。


