INTR
1.0.0
このリポジトリは、INTR: きめの細かい画像分類と分析のためのシンプルな解釈可能なトランスフォーマーの公式実装です。現在、粒度の細かいデータを解釈するためのコードとモデルが含まれています。この論文がオンラインで入手可能になった時点で、今後の ICLR 2024 議事録へのリンクを提供します。
INTR は、画像分類を解釈可能にするための Transformers の新しい使用法です。 INTR では、各クラスに画像内で自分自身を探すよう依頼する、分類への積極的なアプローチを調査します。クラス固有のクエリ (クラスごとに 1 つ) をデコーダへの入力として学習し、クロスアテンションを通じて画像内のクエリの存在を検索できるようにします。私たちは、INTR が本質的に各クラスに明確に出席することを奨励していることを示しています。したがって、クロスアテンションの重みは、モデルの予測の意味のある解釈を提供します。興味深いことに、INTR は、マルチヘッドのクロスアテンションを介して、クラスのさまざまな属性の位置を特定することを学習することができ、詳細な分類と分析に特に適しています。
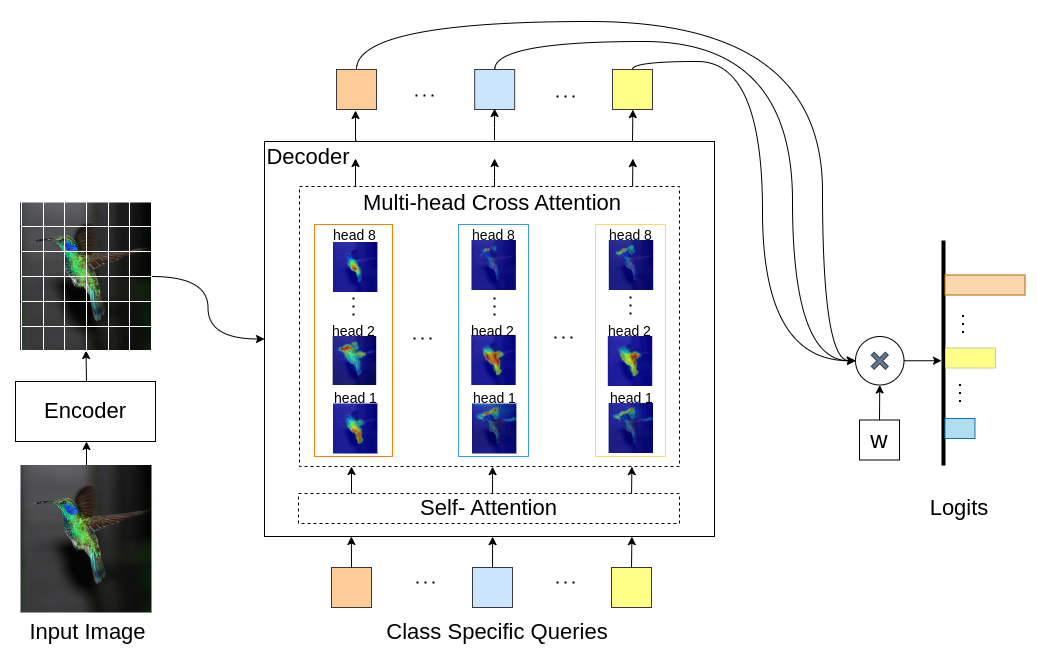
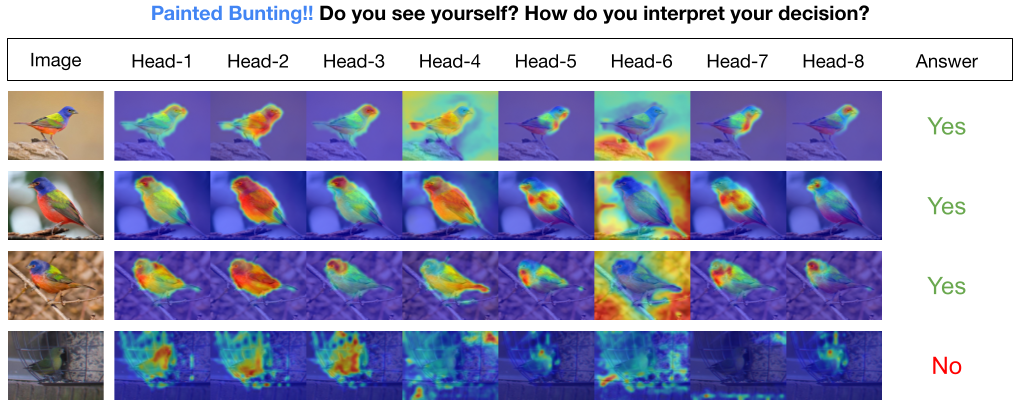
INTR モデルでは、デコーダー内の各クエリがクラスの予測を担当します。したがって、クエリはそれ自体を調べて、特徴マップからクラス固有の特徴を見つけます。まず、画像内のオブジェクトの重要な部分を確認するために、特徴マップ、つまりトランスフォーマー アーキテクチャの値マトリックスを視覚化します。モデルが値マトリックス内で注目している特定の特徴を見つけるために、モデルの注目のヒートマップを表示します。分類における外部干渉を回避するために、分類に共有重みベクトルを使用するため、注意の重みがモデルの予測を説明します。
DETR-R50 バックボーンの INTR、分類パフォーマンス、およびさまざまなデータセットの微調整されたモデル。
| データセット | ACC@1 | ACC@5 | モデル |
|---|---|---|---|
| カブ | 71.8 | 89.3 | チェックポイントのダウンロード |
| 鳥 | 97.4 | 99.2 | チェックポイントのダウンロード |
| 蝶 | 95.0 | 98.3 | チェックポイントのダウンロード |
Python環境の作成(オプション)
conda create -n intr python=3.8 -y
conda activate intrリポジトリのクローンを作成する
git clone https://github.com/dipanjyoti/INTR.git
cd INTRPythonの依存関係をインストールする
pip install -r requirements.txtデータは以下の形式に従ってください。
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
CUBデータセット上の INTR のパフォーマンスを評価するには、マルチ GPU (例: 4 GPU) 設定で、以下のコマンドを実行します。 INTR チェックポイントは、モデルと結果の微調整で利用できます。
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > INTR の解釈の視覚的表現を生成するには、以下のコマンドを実行します。このコマンドは、インデックス <class_number> を持つ特定のクラスの解釈を表示します。デフォルトでは、すべてのアテンションヘッドからの解釈が表示されます。また、top_q というラベルが付いた上位クエリに関連付けられた解釈に焦点を当てるには、パラメータ sim_query_heads を 1 に設定します。視覚化にはバッチ サイズ 1 を使用します。
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >推論時の単一画像の予測と視覚化:推論プロセス中の単一画像の予測と視覚化のために設計された Jupyter Notebook、demo.ipynb も提供しました。このデモは CUB データセットに焦点を当てていることに注意してください。
INTR をトレーニング用に準備するには、事前トレーニング済みモデル DETR-R50 を使用します。特定のデータセットに対してトレーニングするには、「--num_queries」をデータセット内のクラスの数に設定して変更します。 INTR アーキテクチャ内では、デコーダの各クエリにクラス固有の特徴をキャプチャするタスクが割り当てられます。これは、すべてのクエリを学習プロセスを通じて適応させることができることを意味します。したがって、モデル パラメーターの総数は、データセット内のクラスの数に比例して増加します。マルチ GPU システム (例: 4 GPU) で INTR をトレーニングするには、以下のコマンドを実行します。
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > 私たちのモデルは DEtection TRansformer (DETR) メソッドからインスピレーションを得ています。
このような素晴らしい仕事をしてくれた DETR の著者に感謝します。
私たちの研究があなたの研究に役立つと思われる場合は、BibTeX エントリを引用することを検討してください。
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

