open_llama
1.0.0
TL;DR : 私たちは、Meta AI の LLaMA を許可的にライセンスされたオープンソースの複製である OpenLLaMA のパブリック プレビューをリリースします。さまざまなデータ混合でトレーニングされた一連の 3B、7B、および 13B モデルをリリースします。私たちのモデルの重みは、既存の実装における LLaMA の代替として機能します。
このリポジトリでは、Meta AI の LLaMA 大規模言語モデルの、寛容なライセンスを取得したオープンソースの複製を紹介します。 1T トークンでトレーニングされた一連の 3B、7B、および 13B モデルをリリースします。事前トレーニングされた OpenLLaMA モデルの PyTorch および JAX の重み、評価結果、および元の LLaMA モデルとの比較を提供します。 v2 モデルは、異なるデータ混合物でトレーニングされた古い v1 モデルよりも優れています。
OpenLLaMA 3Bv3 モデルをリリースします。これは、7Bv2 モデルと同じデータセット混合で 1T トークン用にトレーニングされた 3B モデルです。
私たちは OpenLLaMA 7Bv2 モデルをリリースできることをうれしく思います。このモデルは、Falcon の洗練された Web データセット、スターコーダー データセット、および RedPajama の wikipedia、arxiv、書籍およびスタック交換の混合物でトレーニングされています。
OpenLLaMA 13B の最終 1T トークン バージョンをリリースできることを嬉しく思います。評価結果を更新しました。 OpenLLaMA モデルの現在のバージョンでは、T5 トークナイザーと同様に、トークナイザーはトークン化の前に複数の空のスペースを 1 つにマージするようにトレーニングされています。このため、コードには多くの空のスペースが含まれるため、トークナイザーはコード生成タスク (HumanEval など) では機能しません。コード関連のタスクには、v2 モデルを使用してください。
OpenLLaMA 3B および 7B の最終 1T トークン バージョンをリリースできることを嬉しく思います。評価結果を更新しました。また、Stability AI と連携してトレーニングされた 13B モデルの 600B トークンのプレビューをリリースできることをうれしく思います。
OpenLLaMA 7B モデル用の 700B トークン チェックポイントと 3B モデル用の 600B トークン チェックポイントをリリースできることを嬉しく思います。評価結果も更新しました。完全な 1T トークン トレーニングの実行は今週末に終了する予定です。
コミュニティからフィードバックを受けた後、以前のチェックポイント リリースのトークナイザーが正しく構成されておらず、新しい行が保持されていないことが判明しました。この問題を解決するために、トークナイザーを再トレーニングし、モデルのトレーニングを再開しました。また、この新しいトークナイザーではトレーニング損失が少ないことも確認されています。
ウェイトは 2 つの形式でリリースされます。1 つは EasyLM フレームワークで使用される EasyLM 形式、もう 1 つは Hugging Face トランスフォーマー ライブラリで使用される PyTorch 形式です。私たちのトレーニング フレームワーク EasyLM とチェックポイントの重みはどちらも、Apache 2.0 ライセンスに基づいて許可されています。
プレビュー チェックポイントは、Hugging Face Hub から直接ロードできます。自動変換された高速トークナイザーが時々誤ったトークン化を行うことが確認されているため、現時点では Hugging Face 高速トークナイザーの使用を避けることをお勧めします。これは、 LlamaTokenizerクラスを直接使用するか、 AutoTokenizerクラスのuse_fast=Falseオプションを渡すことによって実現できます。使用方法については、次の例を参照してください。
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))より高度な使用法については、トランスフォーマー LLaMA のドキュメントに従ってください。
モデルは lm-eval-harness で評価できます。ただし、前述のトークナイザーの問題のため、正しい結果を得るには高速トークナイザーの使用を避ける必要があります。これは、以下の例に示すように、lm-eval-harness のこの部分にuse_fast=False渡すことで実現できます。
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)EasyLM フレームワークで重みを使用する場合は、EasyLM の LLaMA ドキュメントを参照してください。元の LLaMA モデルとは異なり、OpenLLaMA トークナイザーと重みは完全にゼロからトレーニングされるため、元の LLaMA トークナイザーと重みを取得する必要がないことに注意してください。
v1 モデルは RedPajama データセットでトレーニングされます。 v2 モデルは、Falcon の洗練された Web データセット、StarCoder データセット、および RedPajama データセットの wikipedia、arxiv、book、stackexchange 部分の混合でトレーニングされます。モデル アーキテクチャ、コンテキストの長さ、トレーニング ステップ、学習率スケジュール、オプティマイザーなど、元の LLaMA 論文とまったく同じ前処理ステップとトレーニング ハイパーパラメータに従います。私たちの設定と元の設定の唯一の違いは、使用されるデータセットです。OpenLLaMA は、元の LLaMA で使用されるデータセットではなく、オープン データセットを使用します。
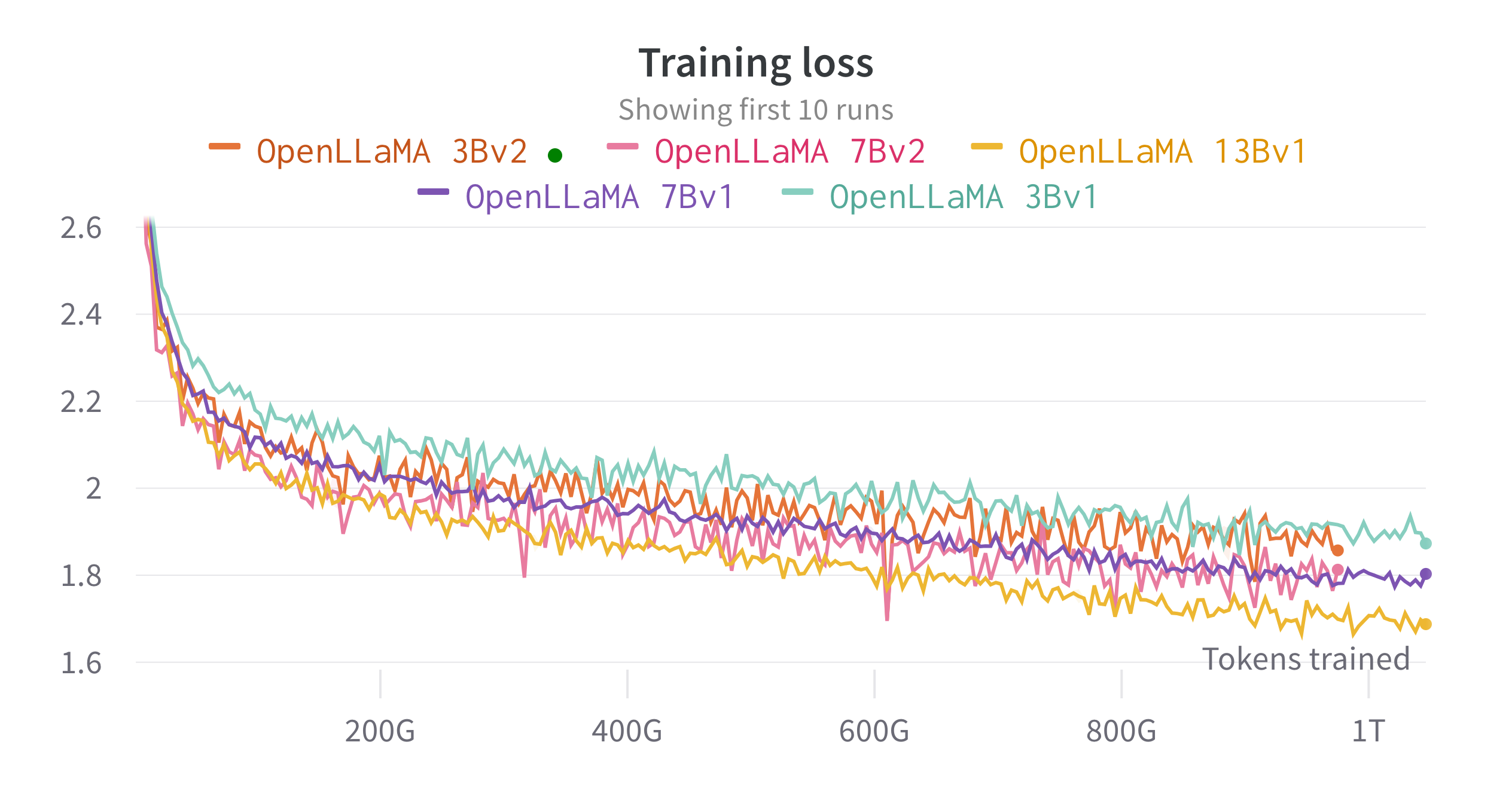
大規模な言語モデルのトレーニングと微調整のために開発した JAX ベースのトレーニング パイプラインである EasyLM を使用して、クラウド TPU-v4 でモデルをトレーニングします。通常のデータ並列処理と完全にシャード化されたデータ並列処理 (ZeRO ステージ 3 とも呼ばれる) の組み合わせを採用して、トレーニング スループットとメモリ使用量のバランスをとります。全体として、7B モデルでは TPU-v4 チップあたり 2200 トークン/秒を超えるスループットに達しています。トレーニングの損失は下の図で見ることができます。
lm-evaluation-harness を使用して、幅広いタスクで OpenLLaMA を評価しました。 LLaMA の結果は、同じ評価基準で元の LLaMA モデルを実行することによって生成されます。 LLaMA モデルの結果が元の LLaMA 論文とはわずかに異なることに注意してください。これは、異なる評価プロトコルの結果であると考えられます。同様の違いが、lm-evaluation-harness のこの問題でも報告されています。さらに、EleutherAI によって Pile データセットでトレーニングされた 6B パラメーター モデルである GPT-J の結果を紹介します。
元の LLaMA モデルは 1 兆トークンに対してトレーニングされ、GPT-J は 5,000 億トークンに対してトレーニングされました。結果を以下の表に示します。 OpenLLaMA は、ほとんどのタスクで元の LLaMA および GPT-J と同等のパフォーマンスを示し、一部のタスクではそれらを上回ります。
| タスク/メトリクス | GPT-J6B | ラマ 7B | ラマ 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLaMA 3B | OpenLLaMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/acc | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/acc | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| アークチャレンジ/acc | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| アークチャレンジ/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| アークイージー/acc | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| アークイージー/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| boolq/acc | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| ヘラスワッグ/ACC | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| ヘラスワッグ/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| オープンブックQA/ACC | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 | 0.27 | 0.30 | 0.31 |
| openbookqa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| ピカ/ACC | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| piqa/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| 記録/em | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| レコード/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| RTE/ACC | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| truefulqa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| truefulqa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| Wi-Fi/ACC | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| ウィノグランデ/ACC | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| 平均 | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
私たちのモデルはこれら 2 つのタスクで疑わしいほど高いパフォーマンスを示しているため、タスク CB と WSC をベンチマークから削除しました。トレーニング セットにベンチマーク データの汚染がある可能性があると仮説を立てます。
コミュニティからのフィードバックをお待ちしています。ご質問がある場合は、問題を開くか、お問い合わせください。
OpenLLaMA は、Berkeley AI Research の Xinyang Geng* と Hao Liu* によって開発されました。 *平等な貢献
計算リソースの一部を提供していただいた Google TPU Research Cloud プログラムに感謝いたします。コンピューティング リソースの整理にご協力いただいた TPU Research Cloud の Jonathan Caton 氏、トレーニング スループットの最適化にご協力いただいた Google Cloud チームの Rafi Witten 氏、Google JAX チームの James Bradbury 氏に特に感謝いたします。また、ディスカッションやフィードバックを提供してくれた Charlie Snell、Gautier Izacard、Eric Wallace、Lianmin Zheng、およびユーザー コミュニティにも感謝します。
OpenLLaMA 13B v1 モデルは Stability AI と協力してトレーニングされており、計算リソースを提供してくれた Stability AI に感謝します。特に、物流を調整し、エンジニアリング サポートを提供してくれた David Ha 氏と Shivanshu Purohit 氏に感謝します。
OpenLLaMA が研究や応用に役立つと思われた場合は、次の BibTeX を使用して引用してください。
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


