LLM4Decompile
1.0.0
![]()
結果 | ?モデル | クイックスタート | HumanEval-逆コンパイル | ?引用 | 紙 | コラボ |
リバース エンジニアリング: 大規模な言語モデルを使用したバイナリ コードの逆コンパイル
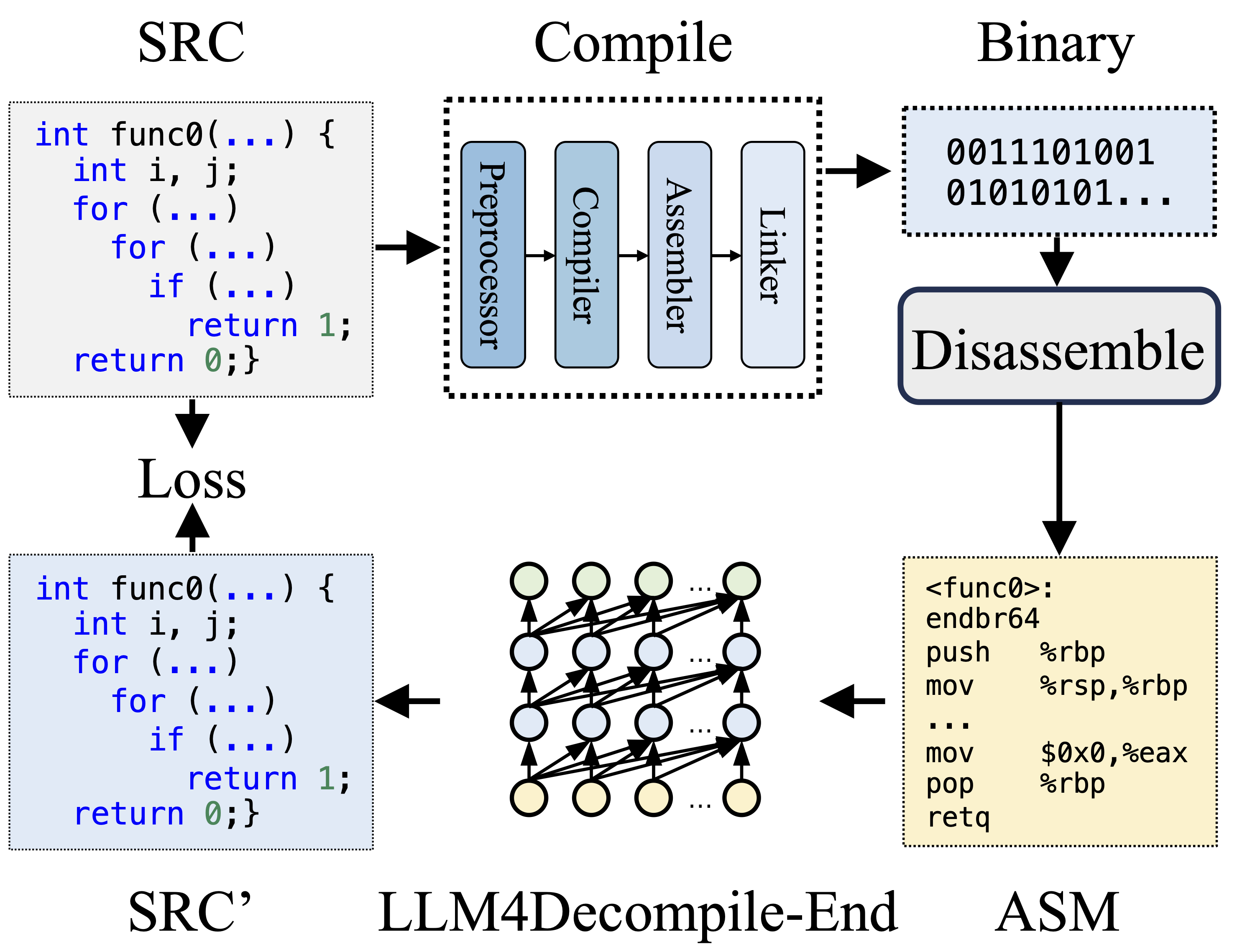
コンパイル中に、プリプロセッサはソース コード (SRC) を処理してコメントを削除し、マクロまたはインクルードを展開します。クリーンアップされたコードはコンパイラに転送され、コンパイラによってアセンブリ コード (ASM) に変換されます。この ASM は、アセンブラーによってバイナリ コード (0 と 1) に変換されます。リンカは、関数呼び出しをリンクして実行可能ファイルを作成することでプロセスを終了します。一方、逆コンパイルでは、バイナリ コードをソース ファイルに変換して戻します。 LLM はテキストでトレーニングされているため、バイナリ データを直接処理する能力がありません。したがって、バイナリは最初にObjdumpによってアセンブリ言語 (ASM) に逆アセンブルされる必要があります。バイナリ ASM と逆アセンブルされた ASM は同等であり、相互変換できるため、これらを同じ意味で参照することに注意してください。最後に、トレーニングをガイドするために、逆コンパイルされたコードとソース コード間の損失が計算されます。逆コンパイルされたコード (SRC') の品質を評価するために、テスト アサーション (再実行可能性) を通じてその機能がテストされます。
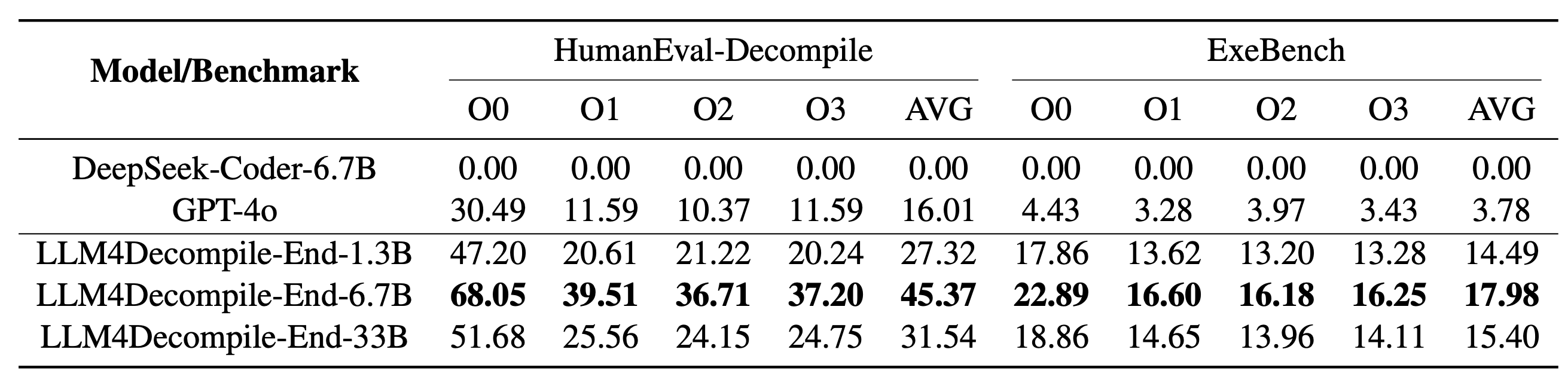
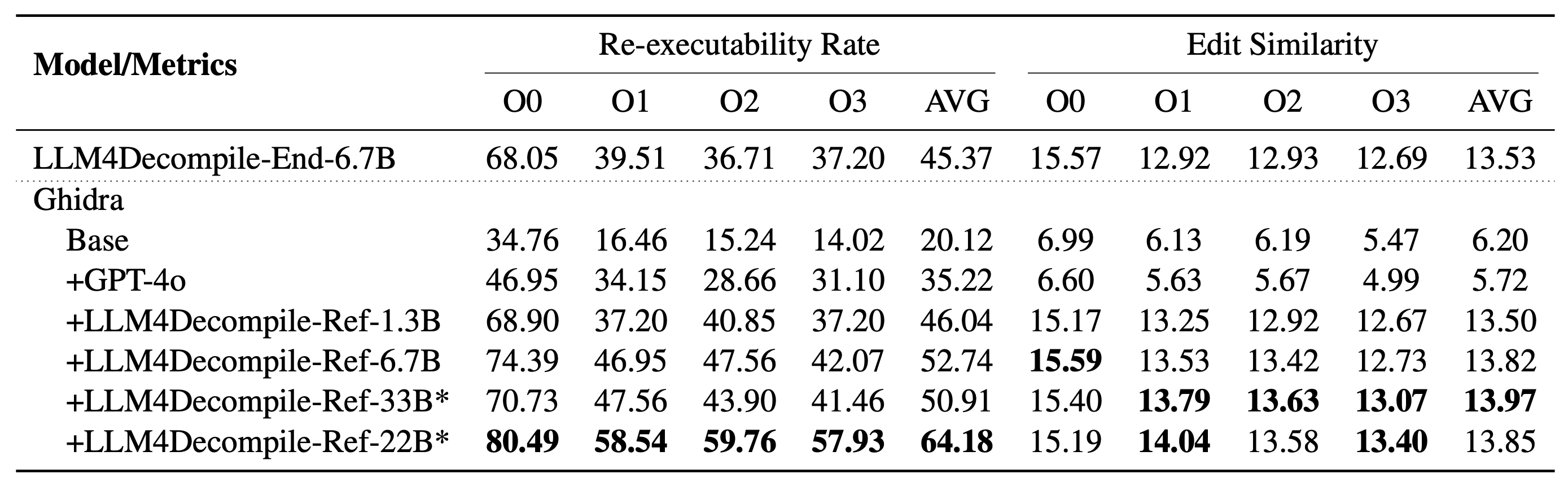
当社の LLM4Decompile には、13 億から 330 億のパラメーターのサイズを持つモデルが含まれており、これらのモデルを Hugging Face で利用できるようにしました。
| モデル | チェックポイント | サイズ | 再実行可能性 | 注記 |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? HFリンク | 1.3B | 27.3% | 注3 |
| llm4decompile-6.7b-v1.5 | ? HFリンク | 6.7B | 45.4% | 注3 |
| llm4decompile-1.3b-v2 | ? HFリンク | 1.3B | 46.0% | 注4 |
| llm4decompile-6.7b-v2 | ? HFリンク | 6.7B | 52.7% | 注4 |
| llm4decompile-9b-v2 | ? HFリンク | 9B | 64.9% | 注4 |
| llm4decompile-22b-v2 | ? HFリンク | 22B | 63.6% | 注4 |
注 3: V1.5 シリーズは、より大きなデータセット (15B トークン) と最大トークン サイズ 4,096 でトレーニングされ、以前のモデルと比較して顕著なパフォーマンス (100% 以上の向上) が得られます。
注 4: V2 シリーズはGhidraに基づいて構築されており、Ghidra から逆コンパイルされた疑似コードを改良するために 20 億のトークンでトレーニングされています。詳細については、gidra フォルダーを確認してください。
セットアップ:以下のスクリプトを使用して、必要な環境をインストールしてください。
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
弊社モデルの使用例をご紹介します(V1.5用に改訂。以前のモデルについてはHFの対応機種ページをご確認ください)。注: 「func0」を逆コンパイルする関数名に置き換えます。
前処理: C コードをバイナリにコンパイルし、バイナリをアセンブリ命令に逆アセンブルします。
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )組み立て説明書は次の形式にする必要があります。
<FUNCTION_NAME>:nオペレーションnオペレーションn
一般的な組み立て手順は次のようになります。
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
逆コンパイル: LLM4Decompile を使用してアセンブリ命令を C に変換します。
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' )データは、JSON リスト形式を使用してllm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.jsonに保存されます。 164*4 (O0、O1、O2、O3) のサンプルがあり、それぞれに 5 つのキーがあります。
task_id : 問題の ID を示します。type : 最適化ステージ。[O0、O1、O2、O3] のいずれかです。c_func : HumanEval 問題の C ソリューション。c_test : C テスト アサーション。input_asm_prompt : プロンプト付きのアセンブリ命令。前処理の例と同様に派生できます。評価スクリプトを確認してください。
このコード リポジトリは、MIT および DeepSeek ライセンスに基づいてライセンスされています。
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


