Lovelace
velace's first appearance in these alleys.
Lovelace のドキュメントを読んでください。
Lovelace は、Python の GPT4FREE ライブラリを使用して ChatGPT と自由に対話できる Web アプリケーションです。このソフトウェアは JavaScript で書かれており、サーバー側では NodeJS + Express + SocketIO、フロントエンドでは Vite + ReactJS を使用します。
バックエンドにより、さまざまなクライアントが ChatGPT と通信できるようになります。 Lovelace の目的が、自分自身の目的のために使用することである場合、ネットワークにバックエンド サーバーをマウントすることのみが可能で、アプリケーションの反対側、つまりクライアントは無視できます。バックエンドでは API を介した対話が可能です。または、SocketIO クライアントを使用して WebSocket による接続を使用することもできます。
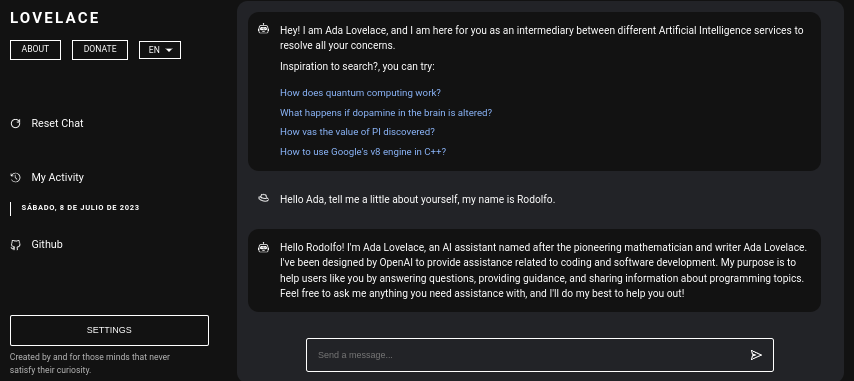
目次:
Lovelace をコンピュータまたはサーバーにインストールするのは比較的簡単で、そのプロセスで大きな複雑な問題は発生しません。ただし、リポジトリのクローン作成を開始する前に、少なくともNodeJS v18.0.0とPython v3.10があることを確認してください。
必要な NodeJS バージョンがシステムにインストールされていない場合は、バージョン マネージャーNVM (Node Version Manager)を使用できることを考慮してください。
# Installing NVM on your system...
export NVM_DIR= " $HOME /.nvm " && (
git clone https://github.com/nvm-sh/nvm.git " $NVM_DIR "
cd " $NVM_DIR "
git checkout ` git describe --abbrev=0 --tags --match " v[0-9]* " $( git rev-list --tags --max-count=1 ) `
) && . " $NVM_DIR /nvm.sh "
# Once NVM has been installed, we proceed to install the specified NodeJS version (> 18.0.0)
nvm install 18.0.0システムにPython v3.10がインストールされていない場合は、次のことを検討してください。
# (DEBIAN)
sudo add-apt-repository ppa:deadsnakes/ppa && sudo apt update && sudo apt install python3.10
# (MacOS)
brew install [email protected]同様に、ネットワーク内にバックエンド サーバーをマウントできるようにするために必要なモジュールをインストールするときに pip が使用されるため、システムに pip をインストールすることを検討してください。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.pyさて、前述の依存関係がシステムにインストールされていると仮定して、次のステップに進むことができます...
バックエンド サーバーを Lovelace フロントエンドとしてインストールして構成する前に、アプリケーションのソース コードが配置されている Github リポジトリのクローンを作成する必要があります。
この記事を読んでいるこの時点では、Python バージョン 3.10 以降と NodeJS バージョン 18.0.0 がすでにインストールされていることを前提としています。前回の説明では、インストールに進む前に、それぞれのインストール手順について説明しました。
# Cloning the Github repository that contains the source code (I stole it from a cyber).
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace
# Accessing the "Client" folder, which stores the source code of the
# Vite + ReactjS (Frontend) application, and then installing its required modules from NPM.
cd Server && npm install --force && pip install -r Requirements.txt
# Like the previous line, we access the "Server" folder that houses the source code
# for the Lovelace Backend, then we install the NPM packages required to mount on the network.
cd ../Client && npm install --force すべてを 1 行で実行したい場合もあります...
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace && cd Server && npm install --force && pip install -r Requirements.txt && cd ../Client && npm install --force && cd ..サーバーを実行するために必要なモジュールをインストールするときは、 GPT4FREEライブラリを使用できるようにするために必要なパッケージをインストールするためにpip install -r Requirements.txtコマンドが実行されることに注意してください。パイソンから。 pipがインストールされていない場合、または Python パッケージがインストールされていない場合は、バックエンド サーバーとクライアントがネットワーク上にマウントされていても、何もすることができません。 WebSocket 経由、またはバックエンドから NodeJS python-shellライブラリを使用する API 経由で、応答を返す役割を担う対応する Python ファイルに対して通信が行われます。必要な要件を満たしていない場合は、エラーがスローされます。
Github リポジトリのクローンを作成したら、フロントエンド アプリケーションとバックエンド アプリケーションの両方の構成とネットワーク マウントに進むことができます。ただし、リポジトリのクローンを作成することによって生成されたフォルダーを含む各サブフォルダーの保存場所についてもう少し詳しく見てみましょう。
| フォルダ | 説明 |
|---|---|
| クライアント | 「Client」フォルダーには、Vite + React アプリケーション、つまり Lovelace フロントエンドのソース コードが保存されます。ここに Web サイトをネットワークにマウントして、バックエンドと通信し、AI との質の高い会話を確立できます。 |
| ドキュメント | 「Documentation」フォルダーには、ソフトウェア ドキュメントのソース コードが格納されています: https://lovelace-docs.codewithrodi.com/。 |
| サーバ | 「Server」フォルダーには、Lovelace バックエンドのソース コードが格納されています。このバックエンドは、Express を使用して NodeJS の下に構築され、WebSocket で応答を送信するための API と SocketIO を提供します。 |
また、フォルダーとは別に、いくつかのファイルが表示されます。同様に、以下の説明とともに表示されます。
| ファイル | 説明 |
|---|---|
| .クロシニョア | これは「cloc」ソフトウェアによって使用され、ソフトウェア コードの行を数え、テクノロジや使用されているプログラミング言語が持つ可能性のあるコメントごとに行を分離することができます。 「clocignore」ファイル内には、ソフトウェアがカウントするときに無視する必要があるファイルとディレクトリのパスが含まれています。 |
| ライセンス | クライアントとサーバーのソース コードが適用される Lovelace ライセンスが含まれています。このソフトウェアは MIT ライセンスに基づいてライセンスされています。 |
リポジトリのクローンを作成し、必要なサーバーおよびクライアント NPM モジュールをインストールしたら、ソフトウェアの使用を開始するようにバックエンドをセットアップします。
サーバーから始めましょう。ここで魔法が起こります。API リクエストまたは WebSocket を使用して AI と通信できます。次に、ネットワーク内にサーバーをマウントできるようにするための一連のコマンドが表示されます。
# Accessing the <Server> folder that houses the repository you cloned earlier
cd Server/
# Running the server...
npm run startすべてを正しく実行した場合、サーバーはシステム上ですでに実行されているはずです。 http://0.0.0.0:8000/api/v1/にアクセスすると確認できます!
スクリプト ( npm run <script_name> ) | 説明 |
|---|---|
| 始める | サーバーの通常の実行が開始されます。サーバーを運用環境にマウントする場合は、このオプションを検討してください。 |
| 開発者 | 「nodemon」パッケージを使用して、開発モードでサーバーの実行を開始します。 |
環境変数は動的な文字値であり、認証情報や設定などに関連する情報を保存できることを知っておく必要があります。その後、サーバーのソース コード内にある「.env」ファイルが表示されます。利用可能な変数の操作について説明します。
# Specifies the execution mode of the server, considers the value of <NODE_ENV>
# can be <development> and <production>.
NODE_ENV = production
# Address of the server where the client application is running.
CLIENT_HOST = https://lovelace.codewithrodi.com/
# Port where the server will
# start executing over the network.
SERVER_PORT = 8000
# Hostname where the server will be launched in
# complement with the previously established
# port on the network.
SERVER_HOST = 0.0.0.0
# If you have an SSL certificate, you must
# specify the certificate and then the key.
SSL_CERT =
SSL_KEY =
# Others...
CORS_ORIGIN = *
BODY_MAX_SIZE = 100kbこの時点でネットワーク上にバックエンド サーバーがセットアップされていると仮定すると、クライアントのサーバーのセットアップを続けることができます。これにより、Web サイトを通じて AI との対話を開始できるようになります。次に設定します...
クライアント アプリケーションは、Vite を開発ツールとして使用し、ReactJS で構築されます。いくつかのターミナル コマンドを使用するだけで、アプリケーションをすぐにセットアップしてネットワーク上に展開できます。私たちの指示に従い、ReactJS と Vite の力を利用することで、シームレスで効率的なセットアップ プロセスを体験できるでしょう。
Web アプリケーションを正しく使用するには、サーバーがネットワーク上ですでに実行されている必要があることを確認してください。
# Accessing the existing <Client> folder within the cloned repository
cd Client/
# Assuming you have already installed the necessary npm packages <npm install --force>
# we will proceed to start the server in development mode
npm run devハッキングを楽しんでください!... サーバーはhttp://0.0.0.0:5173/で実行されているはずです。
前回の説明と同じ方法で、クライアント アプリケーションの ".env" ファイル内にある環境変数のリストが、その説明とともに次に表示されます。
# Address where the backend server was mounted, you must
# be sure to specify in the address if you have ridden
# the server under HTTPS, changing <http> to <https> ;)
VITE_SERVER = http://0.0.0.0:8000
# The server has a suffix to be able to access its respective API
# in this case we use v1
VITE_API_SUFFIX = /api/v1
# Others...
VITE_DONATE_LINK = https://ko-fi.com/codewithrodi
VITE_GPT4FREE_LINK = https://github.com/xtekky/gpt4free
VITE_SOFTWARE_REPOSITORY_LINK = https://github.com/codewithrodi/Lovelaceネットワーク上で Vite サーバーを起動するときに使用されるネットワーク アドレスまたはポートを変更する場合は、 vite.config.jsファイルの変更を検討できます。このファイルには、Vite サーバーの構成設定が含まれています。 vite.config.jsファイルの内容は次のとおりです。
export default defineConfig ( {
plugins : [ react ( ) ] ,
server : {
// If you want to change the network address where the server will be mounted
// you must change <0.0.0.0> to the desired one.
host : '0.0.0.0' ,
// Following the same line above, you must modify the port <5173>
// for which you want to ride on the network.
port : 5173
} ,
define : {
global : { }
}
} ) ;これらの設定の変更は、サーバーのアクセシビリティに影響を与える可能性があるため、慎重に行う必要があることに注意してください。必ず適切なネットワーク アドレスと、まだ使用されていないポートを選択してください。
Vite は、その効率性の高い環境のため、JavaScript で書かれた Web アプリケーションを開発するための一般的な選択肢です。新しいモジュールをロードするときや、開発プロセス中にソースコードをコンパイルするときの起動時間を大幅に短縮するなど、大きな利点があります。 Vite を活用することで、開発者は生産性の向上と開発サイクルの短縮を体験できます。速度とパフォーマンスが最適化されているため、Web 開発プロジェクトにとって価値のあるツールになります。
Web アプリケーションには、プラットフォームにアクセスする Web ブラウザーの言語を検出する機能があります。これは、要求された言語で利用可能なコンテンツの翻訳があるかどうかを後で検出できるようにするためです。翻訳が存在しない場合は、翻訳は返却されます。デフォルトでは英語に対応します。
新しい翻訳を追加するには、 Client/src/Locale/にアクセスできます。この最後のLocale/フォルダーには、 {LANGUAGE_IN_ISO_369}.json形式の一連の JSON が格納されています。新しい翻訳を追加する場合は、形式に従い、値が作成中の目的の言語に更新されるそれぞれのキーをコピーするだけです。
現在、Web アプリケーション内には次の翻訳が存在します: French - Arabic - Chinese - German - English - Spanish - Italian - Portuguese - Russian - Turkish 。
個人のニーズや目的に合わせて Lovelace を利用することを目的としている場合は、ReactJS で実装されたクライアント アプリケーションを無視してかまいません。代わりに、エンチャントが実際に行われる場所であるサーバーに注意をそらしてください。
API または WebSocket を使用してバックエンドと通信する場合、 Model or Roleとして送信されるデータは大文字と小文字が区別されないことに注意してください。つまり、 Modelの値がgPT-3.5-TUrbOであるかどうかは問題ではありません。バックエンドからフォーマットされるため、 Prompt明らかに重要ではありませんが、 Providerに割り当てられる値は、後の読書で、AI との対話を確立するときに使用できる利用可能なプロバイダーを取得する方法を学びます。同様に、それぞれのモデルが何であるかを知ることができます。また、lovelace バックエンドのパブリック インスタンスの同じパス/api/v1/chat/providers/にアクセスして、情報を表示することもできます。
ネイティブ Fetch 関数を介して API を使用する例を次に示します。
const Data = {
// Select the model you want to use for the request.
// <GPT-3.5-Turbo> | <GPT-4>
Model : 'GPT-3.5-Turbo' , // Recommended Model
// Use a provider according to the model you used, consider
// that you can see the list of providers next to the models
// that have available in:
// [GET REQUEST]: http://lovelace-backend.codewithrodi.com/api/v1/chat/providers/
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
// Prompt that you will send to the model
Prompt : 'Hi Ada, Who are you?'
} ;
// Note that if you want to use your own instance replace
// <https://lovelace-backend.codewithrodi.com> for the address
// from your server, or <http://0.0.0.0:8000> in case it is
// is running locally.
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
// We will make the request with the Fetch API provided in a way
// native by JavaScript, specified in the first instance
// the endpoint where our request will be made, while as a second
// parameter we specify by means of an object the method, the header and the
// body that will have the request.
fetch ( Endpoint , {
// /api/v1/chat/completions/
method : 'POST' ,
// We are sending a JSON, we specify the format
// in the request header
headers : { 'Content-Type' : 'application/json' } ,
body : JSON . stringify ( Data )
} )
// We transform the response into JSON
. then ( ( Response ) => Response . json ( ) )
// Once the response has been transformed to the desired format, we proceed
// to display the response from the AI in the console.
. then ( ( Response ) => console . log ( Response . Data . Answer ) )
// Consider that <Response> has the following structure
// Response -> { Data: { Answer: String }, Status: String(Success | ClientError) }
. catch ( ( RequestError ) => console . error ( RequestError ) ) ;通信時に Axios を使用したい場合は、次のことを検討してください。
const Axios = require ( 'axios' ) ;
const Data = {
Model : 'GPT-3.5-Turbo' , // Recommended Model
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
Prompt : 'Hi Ada, Who are you?'
} ;
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
( async function ( ) {
const Response = ( await Axios . post ( Endpoint , Data , { headers : { 'Content-Type' : 'application/json' } } ) ) . data ;
console . log ( Response . Data . Answer ) ;
} ) ( ) ; Client/src/Services/Chat/Context.jsxファイルとClient/src/Services/Chat/Service.jsファイルを見ると、クライアントが API を介してバックエンドとどのように通信するかを確認できます。ここで魔法が起こります。
バックエンド サーバーからは、SocketIO を利用して WebSocket のサーバーが提供されるため、同じライブラリによって提供されるクライアント (NodeJS の場合はnpm i socket.io-clientなど) を使用することをお勧めします。 AIからの応答は、API経由の通信とは異なり、表示するためにAIの処理が完了するのを待つ必要がないため、「瞬時」の応答が必要な場合は、このタイプの通信を使用することをお勧めします。 。 。 WebSocket を使用すると、AI からの応答が部分的に送信され、クライアントとのインタラクションが瞬時に生成されます。
const { io } = require ( 'socket.io-client' ) ;
// Using the NodeJS 'readline' module, like this
// allow <Prompts> to be created by the user
// to our console application.
const ReadLine = require ( 'readline' ) . createInterface ( {
input : process . stdin ,
output : process . stdout
} ) ;
// We store the address where the Lovelace backend is mounted.
// In case your instance is running locally
// you can change the value of <Endpoint> to something like <http://0.0.0.0:8000>.
const Endpoint = 'http://lovelace-backend.codewithrodi.com/' ;
( async function ( ) {
const Socket = io ( Endpoint ) . connect ( ) ;
console . log ( `Connecting to the server... [ ${ Endpoint } ]` ) ;
Socket . on ( 'connect' , ( ) => {
console . log ( 'Connected, happy hacking!' ) ;
RunApplicationLoop ( ) ;
} ) ;
Socket . on ( 'disconnect' , ( ) => {
console . log ( 'nDisconnected, bye bye...!' ) ;
process . exit ( 0 ) ;
} ) ;
// We use <process.stdout.write(...)> instead of <console.log(...)> because
// in this way we print directly to the console without each time
// that a part of the response is received, a new line (n) is executed.
Socket . on ( 'Response' , ( StreamedAnswer ) => process . stdout . write ( StreamedAnswer ) ) ;
const BaseQuery = {
// We indicate the model that we want to use to communicate with the AI
// 'GPT-3.5-Turbo' - 'GPT-4'
Model : 'GPT-3.5-Turbo' ,
// Provider to use in the communication, keep in mind that not all
// providers offer ChatGPT 3.5 or ChatGPT 4. You can make a request
// [GET] to <https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/>
Provider : 'GetGpt' ,
Role : 'User' ,
} ;
const HandleClientPrompt = ( ) => new Promise ( ( Resolve , Reject ) => {
const HandleStreamedResponseEnd = ( MaybeError ) => {
if ( MaybeError ) {
return Reject ( MaybeError ) ;
}
Resolve ( ) ;
} ;
ReadLine . question ( 'Prompt > ' , ( Prompt ) => {
// We issue <Prompt> to the server, where as the second parameter
// send the Query to it, specifying the Model, Provider, Role and Prompt.
// The last parameter corresponds to the Callback that will be called
// once the transmission of the response is finished, consider that this
// callback receives a parameter, which corresponds to whether there is an error
// or not during transmission, its content is therefore the error.
Socket . emit ( 'Prompt' , { Prompt , ... BaseQuery } , HandleStreamedResponseEnd ) ;
} ) ;
} ) ;
const RunApplicationLoop = async ( ) => {
while ( true ) {
await HandleClientPrompt ( ) ;
console . log ( 'n' ) ;
}
} ;
} ) ( ) ; 提示されている言語とは別の言語で WebSocket を介して Lovelace バックエンドとの通信を確立したい場合は、次のことを検討できます。
GPT4FREE Python ライブラリがバックエンド内で使用されているという事実にもかかわらず、後者のプロバイダーは Lovelace が提供するプロバイダーとは異なることを考慮してください。 API を使用して利用可能なプロバイダーのリストを取得できます。ここで、使用を許可するモデル、サービスがホストされている Web アドレス、AI と対話するときに指定する必要がある名前などの情報を取得できます。例で見たとおりです。以前 (API、WS)。
https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/から取得する応答は次のようになります。
{
"Status" : " Success " ,
"Data" :{
"Providers" :{
// List of providers available to use on WebSocket's
"WS" :[
{
// Name to specify when making the query
"Name" : " DeepAi " ,
// Web address where the service is hosted
"Website" : " https://deepai.org " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others WebSocket's providers...
{ "Name" : " Theb " , "Website" : " https://theb.ai " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
],
// List of Providers available to be able to use through the API
"API" :[
{
// Name to specify when making the query
"Name" : " Aichat " ,
// Web address where the service is hosted
"Website" : " https://chat-gpt.org/chat " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others API providers...
{ "Name" : " ChatgptLogin " , "Website" : " https://chatgptlogin.ac " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " DeepAi " , "Website" : " https://deepai.org " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
]
}
}
}ご覧のとおり、プロバイダーのリストは 2 つの部分に分かれており、1 つは API を介して行われるクエリ用で、もう 1 つは WebSocket を使用するクエリ用です。
Lovelace バックエンド サーバーへのリクエストが関係する他の例とは異なり、プロバイダーとそれぞれの利用可能なモデルのリストを取得することは、[GET] リクエストを/api/v1 /chat/providers/に送信するだけなので非常に簡単です。ここで、応答は前に表示された JSON になります。
次の例では、NodeJS 内で Axios を使用します。これは、 npm i axiosコマンドを使用して NPM パッケージ マネージャーを使用してインストールできます。
const Axios = require ( 'axios' ) ;
( async function ( ) {
// Consider that, you can replace <https://lovelace-backend.codewithrodi.com> with
// the address where your backend server is mounted. If t

