PointLLM
1.0.0
 PointLLM: 大規模言語モデルで点群を理解できるようにする
PointLLM: 大規模言語モデルで点群を理解できるようにするRunsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
香港中文大学 上海人工知能研究所 浙江大学

PointLLM はオンラインです! http://101.230.144.196 または OpenXLab/PointLLM で試してみてください。
Objaverse データセットのモデルや独自の点群について PointLLM とチャットできます。
ご意見がございましたら、お気軽にお申し付けください。 ?
| ダイアログ 1 | ダイアログ 2 | ダイアログ 3 | ダイアログ 4 |
|---|---|---|---|
 |  |  |  |
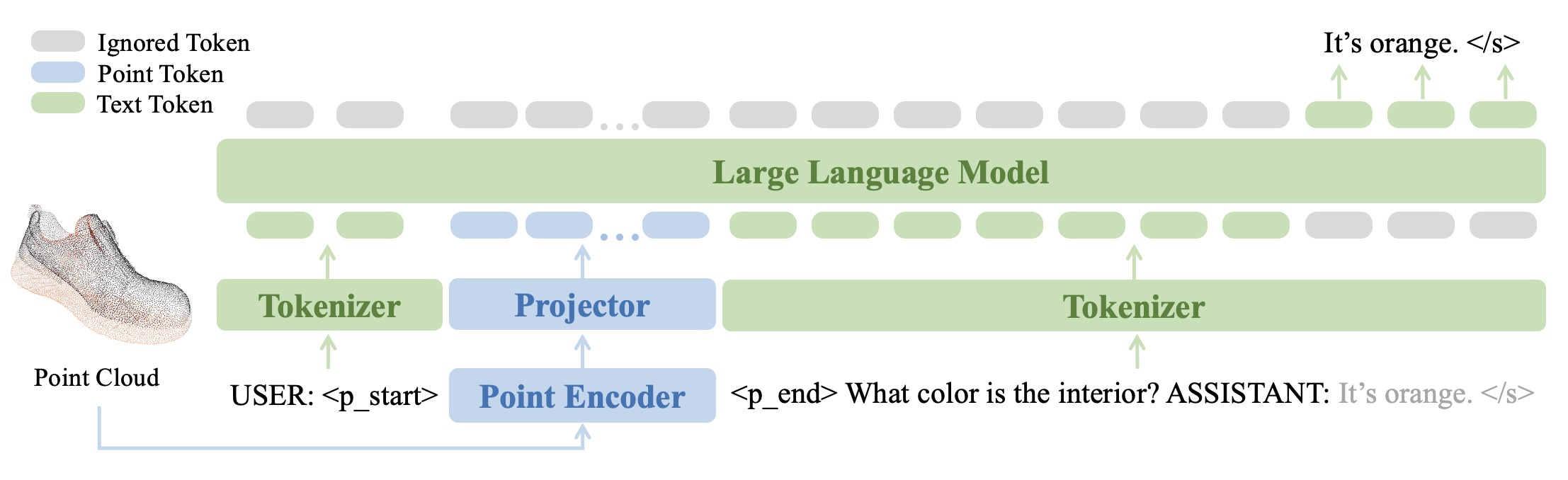
詳しい結果については論文を参照してください。
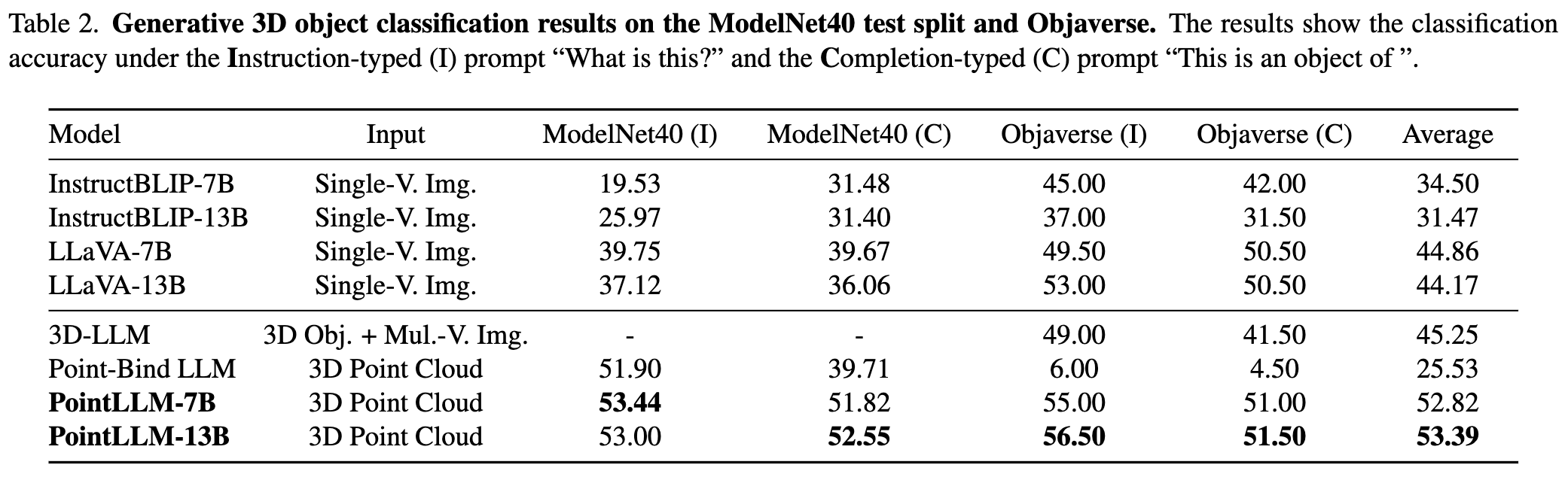
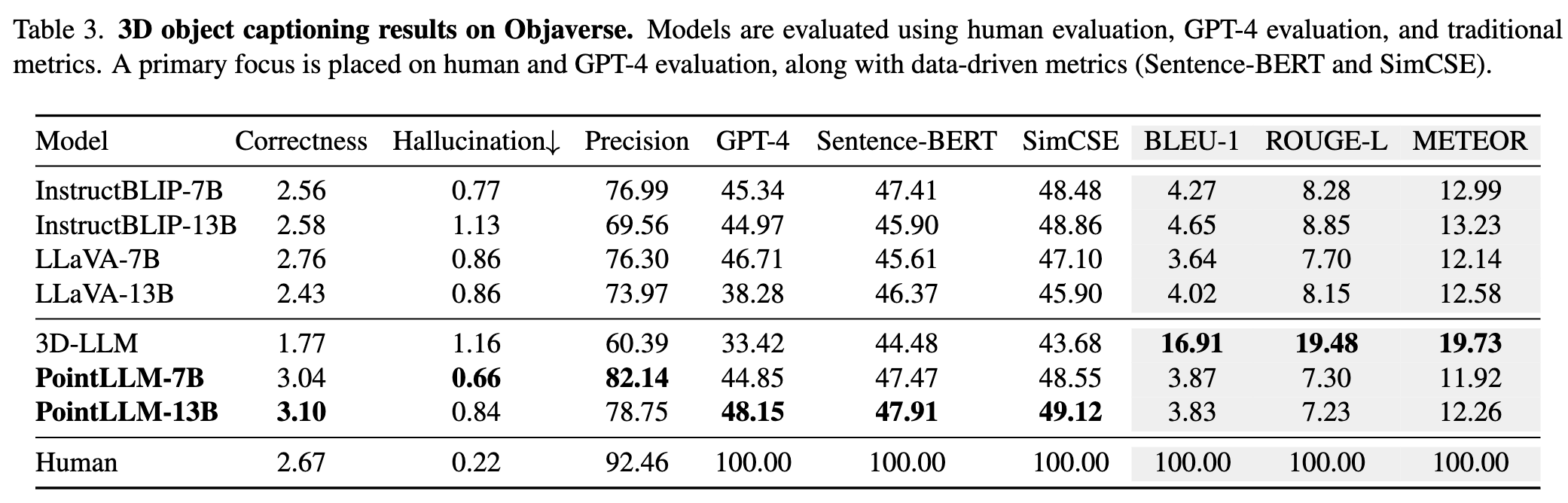
詳しい結果については論文を参照してください。

コードは次の環境でテストします。
開始するには:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn{Objaverse_ID}_8192.npyという名前の 660K 点群ファイルを含む8192_npyという名前のフォルダーが作成されます。各ファイルは次元 (8192, 6) を持つ numpy 配列で、最初の 3 次元はxyzで、最後の 3 次元は [0, 1] 範囲のrgbです。 cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLMフォルダー内にフォルダーdataを作成し、ディレクトリ内の非圧縮ファイルへのソフト リンクを作成します。 cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/dataフォルダーに、 anno_dataという名前のディレクトリを作成します。anno_dataディレクトリに置きます。ディレクトリは次のようになります。 PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.jsonは、検証セットとして予約した 3000 個のオブジェクトを削除することによって、 PointLLM_brief_description_660K.jsonからフィルター処理されていることに注意してください。論文の結果を再現したい場合は、トレーニングにPointLLM_brief_description_660K_filtered.jsonを使用する必要があります。 PointLLM_complex_instruction_70K.jsonは、トレーニング セットのオブジェクトが含まれています。pointllm/data/data_generation/system_prompt_gpt4_0613.txtにあります。 PointLLM_brief_description_val_200_GT.jsonここからダウンロードし、 PointLLM/data/anno_dataに置きます。また、トレーニング中にフィルタリングした 3000 個のオブジェクト ID と、それに対応する参照 GT もここで提供します。これは、3000 個すべてのオブジェクトの評価に使用できます。PointLLM/dataにmodelnet40_dataという名前のディレクトリを作成します。ここから ModelNet40 点群のテスト分割modelnet40_test_8192pts_fps.datをダウンロードし、 PointLLM/data/modelnet40_dataに置きます。PointLLMフォルダーに、 checkpointsという名前のディレクトリを作成します。checkpointsディレクトリに置きます。 cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.sh以下の内容は通常は気にする必要はありません。これらは、v1 論文 (PointLLM-v1.1) の結果を再現するためだけのものです。当社のモデルと比較したい場合、またはダウンストリーム タスクに当社のモデルを使用したい場合は、パフォーマンスが優れている PointLLM-v1.2 (v2 ペーパーを参照) を使用してください。
PointLLM v1.1 と v1.2 は、わずかに異なる事前トレーニングされたポイント エンコーダーとプロジェクターを使用します。 PointLLM v1.1 を再現する場合は、初期 LLM とポイント エンコーダーの重みのディレクトリにあるconfig.jsonファイルvim checkpoints/PointLLM_7B_v1.1_init/config.jsonなど) を編集します。
キー"point_backbone_config_name"を変更して、別のポイント エンコーダ構成を指定します。
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 scripts/train_stage1.shでポイント エンコーダのチェックポイント パスを編集します。
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32データ型を使用してチャットボットを起動します。モデルのチェックポイントは自動的にダウンロードされます。モデル チェックポイントを手動でダウンロードし、そのパスを指定することもできます。以下に例を示します。 cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32モデルに入力される点群の次元が (N, 6) である限り、Objaverse 以外の点群を使用するコードを簡単に変更することもできます。最初の 3 次元はxyzで、最後の 3 次元はrgb ( [0, 1] の範囲)。私たちのモデルはそのような点群でトレーニングされているため、点群をサンプリングして 8192 個の点を得ることができます。
次の表は、さまざまなモデルとデータ型の GPU 要件を示しています。該当する場合は、この論文の実験で使用されているtorch.bfloat16を使用することをお勧めします。
| モデル | データ型 | GPUメモリ |
|---|---|---|
| ポイントLLM-7B | トーチ.フロート16 | 14GB |
| ポイントLLM-7B | トーチ.float32 | 28GB |
| ポイントLLM-13B | トーチ.フロート16 | 26GB |
| ポイントLLM-13B | トーチ.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluationに保存されます。 {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C使用すると、いつでも評価プロセスを中断できます。これにより、一時的な結果が保存されます。評価中にエラーが発生した場合、スクリプトは現在の状態も保存します。同じコマンドを再度実行すると、中断したところから評価を再開できます。{model_name}/evaluationに保存されます。いくつかのメトリクスは次のように説明されています。 " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_evalフラグを渡し、 --gpt_type指定することで、推論直後に評価を開始することもできます。例えば: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputコミュニティへの貢献は大歓迎です!サポートが必要な場合は、お気軽に問題を開くか、お問い合わせください。
私たちの仕事とこのコードベースが役立つと思われる場合は、このリポジトリにスターを付けることを検討してください。そして引用します:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
この作品は、クリエイティブ コモンズ 表示 - 非営利 - 継承 4.0 国際ライセンスに基づいています。
一緒に 3D 用 LLM を素晴らしいものにしましょう!


