coverup
ved performance using tool function

アマースト大学プラズマ研究所のフアン・アルトマイヤー・ピッツォルノ氏とエメリー・バーガー氏による。
CoverUp は、より多くのコードを確実にテストする (つまり、コード カバレッジを増やす) テストを自動的に生成します。 CoverUp は、テスト スイートをまだ持っていない場合、テスト スイートを最初から作成することもできます。新しいテストはコードに基づいているため、回帰テストに役立ちます。
CoverUp は、pytest テスト フレームワークと密接に連携するように設計されています。テストを生成するには、まず、SlipCover を使用してスイートのカバレッジを測定します。次に、さらにテストが必要なコード部分 (つまり、未発見のコード) を選択します。次に、CoverUp は LLM と対話し、テストを要求し、結果をチェックしてテストが実行されてカバレッジが拡大されていることを確認し (再び SlipCover を使用)、必要に応じて調整を再度要求します。最後に、CoverUp はオプションで、新しいテストが適切に統合されているかどうかをチェックし、見つかった問題の解決を試みます。
技術的な詳細と完全な評価については、arXiv の論文「CoverUp: Coverage-Guided LLM-Based Test Generation (PDF)」を参照してください。
CoverUp は PyPI から入手できるので、次のように簡単にインストールできます。
$ python3 -m pip install coverupCoverUp は、OpenAI、Anthropic、または AWS Bedrock モデルで使用できます。アクセスの詳細をシェル環境変数として定義する必要があります: OPENAI_API_KEY 、 ANTHROPIC_API_KEYまたはAWS_ACCESS_KEY_ID / AWS_SECRET_ACCESS_KEY / AWS_REGION_NAME 。
たとえば、OpenAI の場合、アカウントを作成し、残高がプラスであることを確認してから API キーを作成し、その「秘密キー」 (通常はsk-で始まる文字列) をOPENAI_API_KEYという名前の環境変数に保存します。
$ export OPENAI_API_KEY= < ...your-api-key... > モジュールの名前がmymodで、そのソースがsrcの下にあり、テストがtestsの下にある場合、CoverUp を次のように実行できます。
$ coverup --source-dir src/mymod --tests-dir tests次に、CoverUp は、 test_coverup_N.py ( Nは数字) という名前のテストをtestsディレクトリの下に作成します。
ここでは、CoverUp に人気のあるパッケージ Flask の追加テストを作成してもらいます。
$ coverup --package src/flask --tests tests
Measuring coverage... 90.9%
Prompting gpt-4o-2024-05-13 for tests to increase coverage...
(in the following, G=good, F=failed, U=useless and R=retry)
100%|███████████████████████████████████████| 92/92 [01:01<00:00, 1.50it/s, G=55, F=122, U=20, R=0, cost=~$4.19]
Measuring coverage... 94.4%
$
CoverUp は 1 分強で、Flask のテスト カバレッジを 90.9% から 94.4% に高めます。
CoverUp は、新しく生成された各テストを評価する際に、不安定なテストを検出するために何度もテストを実行します。これは--repeat-testsおよび--no-repeat-testsオプションで調整できます。 CoverUp は、新しく生成されたテストが不安定であることを検出すると、LLM に修正を求めるプロンプトを出します。
CoverUp は、単独で実行すると合格し、カバレッジが増加するテストのみをスイートに追加します。ただし、テストが状態を「汚染」し、他のテストが失敗するように状態を変更する可能性があります。デフォルトでは、CoverUp は pytest-cleanslate プラグインを使用してテストを分離し、(メモリ内の)テスト汚染を回避します。 --no-isolate-testsオプションを渡すことで無効にできます。 CoverUp は、汚染しているテスト モジュールまたは関数を見つけて無効にする ( --disable-polluting )、または単に失敗したテストを無効にする (``--disable-failing`) ように要求することもできます。
LLM によって生成されたテストを評価するには、CoverUp がテストを実行する必要があります。最高のセキュリティを確保し、システムへの損傷のリスクを最小限に抑えるために、Docker で CoverUp を実行することをお勧めします。
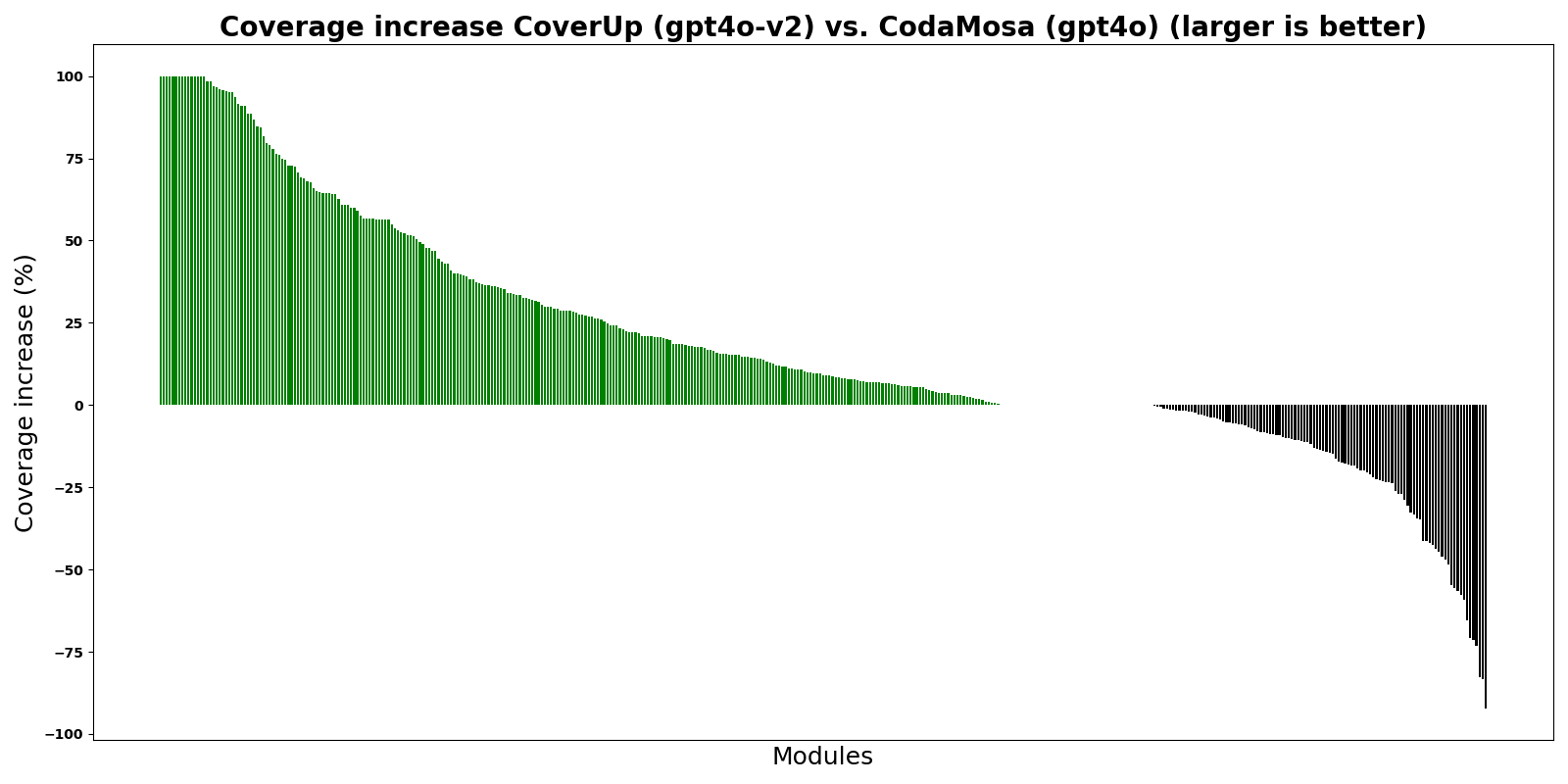
このグラフは、Pynguin テスト ジェネレーターをベースにした最先端の検索ベースのテスト ジェネレーターである CodaMosa と CoverUp を比較したものです。この実験では、CoverUp と CodaMosa の両方が「最初から」、つまり既存のテスト スイートを無視してテストを作成しました。バーは、さまざまな Python モジュールの CoverUp と CodaMosa のカバレッジ率の違いを示しています。 0 より上の緑色のバーは、CoverUp がより高いカバレッジを達成したことを示します。
グラフが示すように、CoverUp はほとんどのモジュールで CodaMosa よりも高いカバレッジを実現します。
これは CoverUp の初期リリースです。楽しんでいただければ幸いです。改善に努めているため、多少の混乱はご容赦ください。バグレポート、体験レポート、機能リクエストを歓迎します (問題を開いてください)。


