bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | モデル会社 | モデルタイプ | 機種名 | サポートするかどうか | 説明する |
|---|---|---|---|---|
| OpenAI | チャット | gpt-3.5、gpt-4 | √ | すべての gpt3.5 および gpt4 モデルをサポート |
| テキスト補完 | テキスト-ダヴィンチ-003 | √ | テキスト生成クラスモデル | |
| 埋め込み | テキスト埋め込み-ada-002 | √ | ベクトル化されたモデル | |
| Baidu-Wen Xin Yiyan | チャット | アーニーボット、アーニーボットターボ | √ | Baidu 商用チャット モデル |
| 埋め込み | 埋め込み_v1 | √ | Baidu 商用ベクトル化モデル | |
| ホストモデル | さまざまなオープンソース モデル | √ | Baidu がホストするさまざまなオープン ソース モデルについては、Baidu のサードパーティ モデル アクセス プロトコルを使用して自分で設定してください。詳細については、以下のモデル アクセス セクションを参照してください。 | |
| Alibaba Cloud-Tongyi Qianwen | チャット | qwen-v1、qwen-plus-v1、qwen-7b-chat-v1 | √ | Alibaba Cloud の商用およびオープンソースのチャット モデル |
| 埋め込み | テキスト埋め込みv1 | √ | Alibaba Cloud 商用ベクトル化モデル | |
| ホストモデル | さまざまなオープンソース モデル | √ | Alibaba Cloud がホストする他のタイプのオープンソース モデルについては、Alibaba Cloud サードパーティ モデル アクセス プロトコルを使用して自分で設定してください。詳細については、以下のモデル アクセス セクションを参照してください。 | |
| ミニマックス | チャット | abab5、abab5.5 | √ | MiniMax コマーシャル チャット モデル |
| チャットプロ | abab5.5 | √ | MiniMax 商用チャット モデルは、カスタマイズされた Chatcompletion プロ モードを使用し、複数人および複数ボットの会話シナリオ、サンプル会話、戻り形式の制限、関数呼び出し、プラグイン、およびその他の機能をサポートします。 | |
| 埋め込み | エンボ-01 | √ | MiniMax商用ベクトルモデル | |
| 知恵AI-ChatGLM | チャット | ChatGLM-Pro、Std、Lite、characterglm | √ | Zhipu AIマルチバージョン商用大型モデル |
| 埋め込み | テキストの埋め込み | √ | Zhipu AI コマーシャル テキスト ベクトル モデル | |
| iFlytek-Spark | チャット | SparkDesk V1.5、V2.0 | √ | iFlytek Spark Cognitive 大型モデル |
| 埋め込み | 埋め込み | √ | iFlytek Spark テキスト ベクトル モデル | |
| SenseTime-RiRiXin | チャット | nova-ptc-xl-v1、nova-ptc-xs-v1 | √ | SenseNova SenseTime 日替わり新作大型モデル |
| バイチュアン インテリジェンス | チャット | バイチュアン-53b-v1.0.0 | √ | 百川53B大型モデル |
| テンセント・フンユアン | チャット | テンセント・フンユアン | √ | テンセント・フンユアンの大型モデル |
| 自己展開型オープンソース モデル | チャット、補完、埋め込み | さまざまなオープンソース モデル | √ | FastChat やその他のデプロイメントによってデプロイされたオープン ソース モデルを使用して、提供される Web API インターフェイスは OpenAI 互換の RESTful API に従い、詳細については、以下のモデル アクセスの章を参照してください。 |
知らせ:
AIGC のモデル LLM とプロンプト ワード プロンプトの 2 つのテクノロジーは非常に新しく、理論、チュートリアル、ツール、エンジニアリングなどの側面が非常に不足しており、使用されているテクノロジー スタックは現在の主流の開発者の経験とほとんど重複しません。 :
| 分類 | 現在の主流の開発 | 即時プロジェクト | モデルの開発、モデルの微調整 |
|---|---|---|---|
| 開発言語 | Java、.Net、JavaScript、ABAPなど | 自然言語、Python | パイソン |
| 開発ツール | とても大人っぽくて | なし | 成熟した |
| 開発の閾値 | 低くて成熟した | 背は低いが非常に未熟 | 非常に高い |
| 開発技術 | 明確で安定した | 始めるのは簡単ですが、安定した出力を達成するのは非常に困難です | 複雑で多様な |
| よく使われるテクニック | オブジェクト指向、データベース、ビッグデータ | プロンプトチューニング、インコンテキスト学習、埋め込み | トランス、RLHF、ファインチューニング、LoRA |
| オープンソースのサポート | 豊かで成熟した | 下位レベルでは非常に混乱する | 裕福だが未熟 |
| 開発費 | 低い | より高い | 非常に高い |
| 開発者 | リッチ | 極めて希少 | 非常に希少です |
| 連携モデルの開発 | プロダクトマネージャーから渡されたドキュメントに従って開発 | 要件から納品まですべての業務を 1 人または最小限のチームで処理できます | 理論的研究の方向性に従って開発 |
現在、ほぼすべてのテクノロジー企業、インターネット企業、ビッグデータ企業はすべてこの方向に進んでいますが、より伝統的な企業は依然として混乱状態にあります。従来の企業がそれを必要としていないのではなく、1) 技術的な人材の予備力がないため、何をすればよいのかわからない、2) ハードウェアの予備力がない、そしてそれができない、ということです。 3) ビジネスのデジタル化の度合いが低く、AIGC の変革とアップグレードのサイクルが長く、成果が遅い。
現在、国内外には商用モデルやオープンソースモデルが非常に多く存在しており、それらは非常に急速に開発されていますが、その結果、新しいモデルに直面すると、モデルの API とデータオブジェクトが異なります。新しいバージョン) を使用するには、開発ドキュメントを読み、独自のアプリケーション コードを変更して適応させる必要があります。アプリケーション開発者は誰でも多くのモデルをテストし、苦労したことがあるはずです。
実際、モデルの機能は異なりますが、機能を提供するためのモードは一般的に同じです。そのため、多くの開発者にとって、多数のモデル API に適応し、統一された呼び出しモードを提供できるフレームワークを用意することが緊急のニーズとなっています。
まず第一に、bida は langchain を置き換えることを目的としたものではありませんが、そのターゲットの位置付けと開発コンセプトも大きく異なります。
| 分類 | ラングチェーン | ビダ |
|---|---|---|
| ターゲットグループ | AIGC の方向に全力で開発に取り組む人々 | AIGC とアプリケーション開発を緊急に組み合わせる必要がある開発者 |
| モデルのサポート | ローカルまたはリモート展開のさまざまなモデルをサポート | 現在、Web API を提供するモデル呼び出しのみがサポートされています。ほとんどの商用モデルは、FastChat などのフレームワークを使用してデプロイされた後に Web API を提供することもできます。 |
| フレーム構造 | 多くの機能と非常に複雑な構造を提供するため、2023 年 8 月の時点で、コア コードには 1,700 以上のファイルと 150,000 行以上のコードがあり、学習の敷居が高くなります。 | 10 を超えるコア コードと約 2,000 行のコードがあり、コードの学習と変更は比較的簡単です。 |
| 機能サポート | AIGCの方向に沿って、さまざまなモデル、テクノロジー、アプリケーション分野を完全にカバーします | 現在、ChatCompletions、Completions、Embedding、Function Callなどの機能をサポートしており、近い将来、音声や画像などのマルチモーダル機能もリリースされる予定です。 |
| プロンプト | プロンプト テンプレートが提供されていますが、独自の関数で使用されるプロンプトがコードに埋め込まれているため、デバッグや変更が困難になります。 | 現在、プロンプトを使用するための組み込み関数は提供されていません。将来使用する場合は、ユーザーの調整を容易にするために構成ベースのロード後モードが使用されます。 |
| 会話と記憶 | 複数のメモリ管理方法をサポートおよび提供する | サポート、サポート 会話の永続性 (duckdb に保存)、メモリは限定的なアーカイブ セッション機能を提供し、その他の機能は拡張フレームワークによって拡張可能 |
| 機能とプラグイン | 豊富な拡張機能をサポートおよび提供しますが、使用効果は大規模モデル自体の機能に依存します | OpenAI の Function Call 仕様を使用した大規模モデルとの互換性 |
| エージェントとチェーン | 豊富な拡張機能をサポートおよび提供しますが、使用効果は大規模モデル自体の機能に依存します | サポートされていないため、別のプロジェクトを立ち上げて実装する予定です。または、現在のフレームワークに基づいて独自に拡張および開発することもできます。 |
| その他の機能 | ドキュメントの分割 (分割後の埋め込み、chatpdf および他の同様の機能の実装に使用) など、他の多くの機能をサポートします。 | 現時点ではその他の機能はありません。追加する場合は、互換性のある新しいプロジェクトを開くことで実装されます。現時点では、他の製品が提供する機能を組み合わせて実装できます。 |
| 業務効率化 | 多くの開発者は、API を直接呼び出すよりも遅いと報告していますが、その理由は不明です。 | 呼び出しプロセスをカプセル化し、呼び出しインターフェースを統合するだけであり、パフォーマンスは API を直接呼び出す場合と変わりません。 |
業界をリードするオープンソース プロジェクトとして、langchain は大規模モデルと AGI の推進に多大な貢献をしてきましたが、同時に開発時にそのモデルやアイデアの多くも活用しました。ビダ。しかし、langchain は大規模で包括的なツールになることを目指しているため、必然的に多くの欠点が生じます。Max Woolf - 中国語、Hacker News - 中国語などの記事にも同様の意見があります。
サークル内でよく使われている言葉がそれをよく表しています。 「langchain は誰もが学ぶ教科書ですが、最終的には捨てるでしょう」というものです。
pip または pip3 から最新の Bida をインストールします
pip install -U bidaプロジェクト コードを Github からローカル ディレクトリにクローンします。
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txt現在のコードのルート ディレクトリ下のファイルを変更します。 「.env.template」の拡張子が「.env」環境変数ファイルになります。ファイル内の指示に従って、申請したモデルのキーを設定してください。
注: このファイルは無視リストに追加されているため、git サーバーには送信されません。
例1.初期化環境.ipynb
次のデモ コードでは、bida でサポートされているさまざまなモデルを使用します。コード内の **[model_type]** の値を、購入したモデルに応じて、対応するモデルの会社名に変更して置き換えてください。さまざまなモデルをすばやく切り替えることができます。経験のために:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )チャット モード: 現在主流の LLM インタラクション モードである ChatCompletion は、セッション管理、永続性、およびメモリ管理をサポートします。
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )上記の詳細なコードとより機能的な例については、以下の NoteBook を参照してください。
例2.1.チャットモード.ipynb
グラデーションを使用してチャットボットを構築する
Gradio は非常に人気のある自然言語処理インターフェイス フレームワークです
bida + grario は、わずか数行のコードで使用可能なアプリケーションを構築できます
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()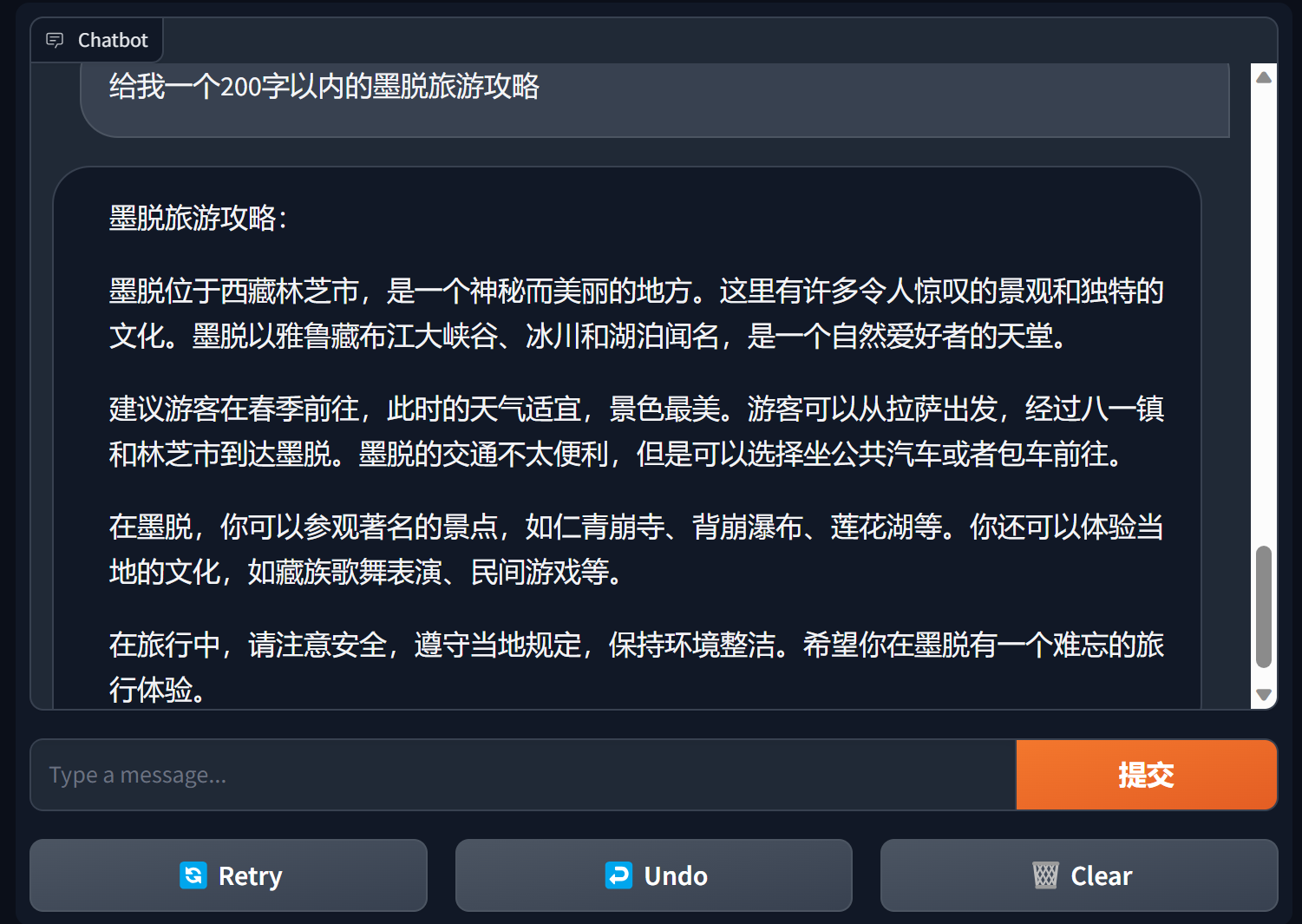
詳細については、bida+gradio のチャットボット デモを参照してください。
完了モード: 前世代の LLM インタラクション モードである Completions または TextCompletions は、シングル ラウンドの会話のみをサポートし、チャット レコードは保存されず、各通話は新しいコミュニケーションとなります。
注: 2023 年 7 月 6 日の OpenAI の記事では、このモデルは段階的に廃止されると明記されています。サポートされているモデルであっても、OpenAI に続くものと推定されており、段階的に廃止されることが予想されます。未来。 。
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )サンプル コードの詳細については、次を参照してください。
例2.2.完了モード.ipynb
プロンプトという単語 Prompt は、大規模言語モデルの最も重要な機能であり、従来のオブジェクト指向開発モデルを破壊し、 Prompt プロジェクトに変換します。 このフレームワークは、タグの置換、複数のモデルに異なるプロンプトワードの設定、モデルがインタラクションを実行する際の自動置換などの機能をサポートする「Prompt Templete」を使用して実装されています。
現在、 PromptTemplate_Textが提供されています。文字列テキストを使用したプロンプト テンプレートの生成をサポートしています。bida は柔軟なカスタム テンプレートもサポートしており、将来的には json およびデータベースからテンプレートを読み込む機能を提供する予定です。
詳細なサンプルコードについては、次のファイルを参照してください。
例2.3.プロンプトプロンプト word.ipynb
プロンプトの言葉に含まれる重要な指示
一般に、プロンプトワードは、役割の設定、タスクの明確化、およびコンテキスト (関連情報または例) の提供の 3 つの段落構造に従うことが推奨されます。例の記述方法を参照してください。
Andrew Ng の一連のコース https://learn.deeplearning.ai/login、中国語版、通訳
openai クックブック https://github.com/openai/openai-cookbook
Microsoft Azure ドキュメント: チップ エンジニアリングの概要、チップ エンジニアリング テクノロジ
Github で最も人気のあるプロンプト エンジニアリング ガイド、中国語版
Function Callingは、2023 年 6 月 13 日に OpenAI によってリリースされた関数です。ChatGPT によってトレーニングされたデータが 2021 年以前に基づいていることは誰もが知っています。リアルタイム関連の質問を希望しても、私たちは答えることができません。と機能呼び出しにより、リアルタイムで天気予報の確認、在庫の確認、最近の映画のレコメンドなどのネットワークデータを取得することが可能になります。
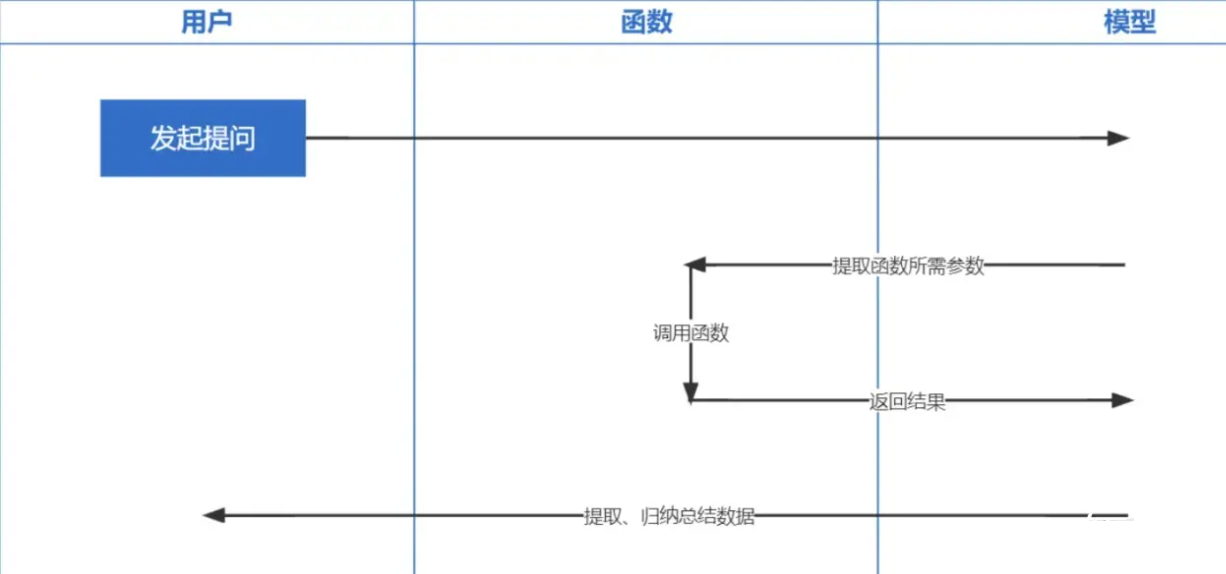
エンベディングテクノロジーは、Prompt inContext Learning を実装するための最も重要なテクノロジーであり、以前のキーワード検索と比較してさらに進歩しています。
注: 異なるモデルからのデータ埋め込みは普遍的ではないため、検索中の質問の埋め込みには同じモデルを使用する必要があります。
| 機種名 | 出力寸法 | バッチレコードの数 | 単一テキストトークンの制限 |
|---|---|---|---|
| OpenAI | 1536年 | 制限なし | 8191 |
| 百度 | 384 | 16 | 384 |
| アリ | 1536年 | 10 | 2048年 |
| ミニマックス | 1536年 | 制限なし | 4096 |
| ウィズダムスペクトルAI | 1024 | シングル | 512 |
| iFlytek スパーク | 1024 | シングル | 256 |
注: bida の埋め込みインターフェイスはバッチ処理をサポートしており、モデルのバッチ処理制限を超えると、自動的にバッチで処理され、まとめて返されます。単一のテキストの内容がトークンの制限数を超える場合、モデルのロジックに応じて、エラーを報告するものと、それを切り捨てるものがあります。
詳細な例については、examples2.6.Embeddingsembeddingmodel.ipynb を参照してください。
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
今後もより多くの機種に対応していきたいと考えておりますので、皆様の貴重なご意見をお待ちしており、より良い製品を開発者に提供していきたいと思います!


