ssebowa
1.0.0
Ssebowa は、次のような生成 AI モデルを提供するオープンソースの Python ライブラリです。
ssebowa-llm:テキスト生成のための大規模言語モデル (LLM)、ssebowa-vllm:視覚的に理解するための視覚言語モデル (VLLM)、ssebowa-imagen:画像生成およびカスタマイズされた微調整モデル、Ssebowa-vigen:ビデオ生成モデル。Ssebowa を使用すると、テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、パーソナライズされた画像の生成を簡単に行うことができ、有益な方法で質問に答えることができます。
詳しい使用方法については、Ssebowa の技術ドキュメントを参照してください。
スクリプトを実行する前に、必要なライブラリがインストールされていることを確認してください。これを行うには、次のコマンドを実行します。
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .次にセボワをインストールします
pip install ssebowacolab または jupyter ノートブックでこのコマンドを実行している場合は、これを使用してください。
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaこれで、ライブラリからモデルをインポートすることで、さまざまなモデルにアクセスできるようになります。
Ssebowa-Imagen は、 diffusion modelingとgenerative adversarial networks (GANs)の組み合わせを利用して、 text descriptionsから高品質の画像を生成するオープンソースの画像合成モデルです。また、数枚の写真を、生成可能なcustom modelに変換することもできます。 chosen subjectの素晴らしい画像。 100 billion datasetを活用し、現実世界の画像のニュアンスを正確に捉え、テキスト説明を魅力的な視覚表現に効果的に変換できます。
10-20 high-qualityソロ写真(jpg or png)を 10 ~ 20 枚用意し、特定のディレクトリに置きます。16GB or moreのGPUを搭載したマシンで実行してください。 (SDXL を微調整する場合は、24GB の VRAM が必要になります。) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()「本棚に座る猫」を生成してみましょう
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm は、Ssebowa AI によって開発されたオープンソースのビジュアルラージ言語モデル (VLLM) です。画像を理解するために使用できる強力なツールです。 Ssebowa-vllm には 110 億の視覚パラメータと 70 億の言語パラメータがあり、解像度 1120*1120 での画像理解をサポートします。
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)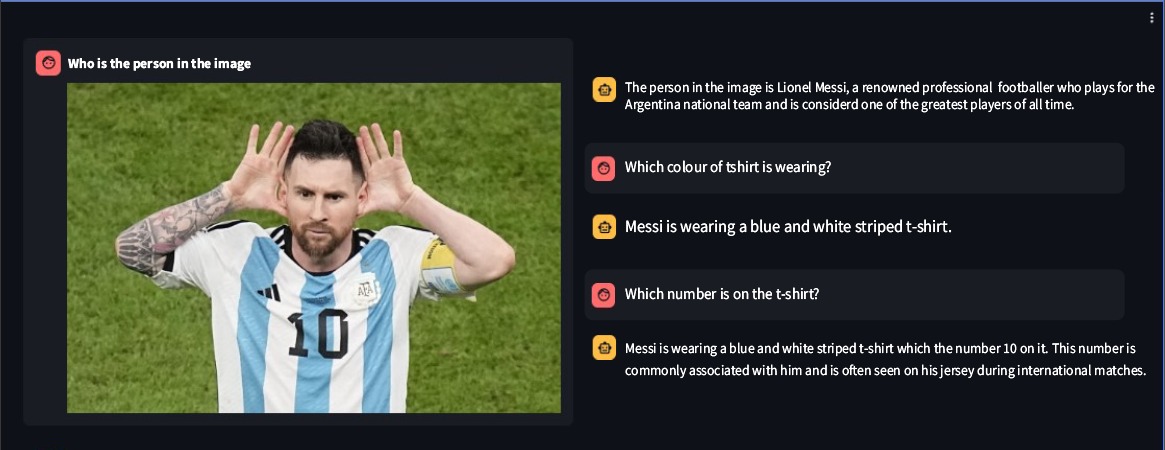
Ssebowa は寄付を受け付けています!ガイドラインは進行中です。
Ssebowa は、Apache License 2.0 に基づいてリリースされています。
ご質問やご提案がございましたら、お気軽に GitHub で問題をオープンするか、[email protected] までお問い合わせください。


