xTuring
0.1.8


xTuring 、Mistral、LLaMA、GPT-J などのオープンソース LLM の高速、効率的かつシンプルな微調整を提供します。 xTuring は、独自のデータやアプリケーションに合わせて LLM を微調整するための使いやすいインターフェイスを提供することで、LLM の構築、変更、制御を簡単にします。プロセス全体はコンピューター内またはプライベート クラウド内で実行できるため、データのプライバシーとセキュリティが確保されます。
xTuring使用すると、次のことが可能になります。
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))ここでデータフォルダーを見つけることができます。
xTuringライブラリの最新の機能強化を発表できることを嬉しく思います。
LLaMA 2統合- LLaMA 2モデルをさまざまな構成で使用および微調整できます:既製、 INT8 精度の既製、 LoRA 微調整、 INT8 精度の LoRA 微調整、およびLoRA 微調整GenericModelラッパーを使用してINT4 精度で調整したり、 xturing.modelsのLlama2クラスを使用してモデルをテストして微調整したりできます。 from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation - 任意のデータセットでCausal Language Modelを評価できるようになりました。現在サポートされているメトリクスはperplexityです。 # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4精度- GenericLoraKbitModelを使用して、 INT4 Precisionの LLM を使用し、微調整できるようになりました。 # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )そのアプリケーションを理解するには、Llama LoRA INT4 の動作例を調べることをお勧めします。
さらに詳しい洞察が必要な場合は、リポジトリで利用可能な GenericModel の動作例を調べることを検討してください。

$ xturing chat -m " <path-to-model-folder> "
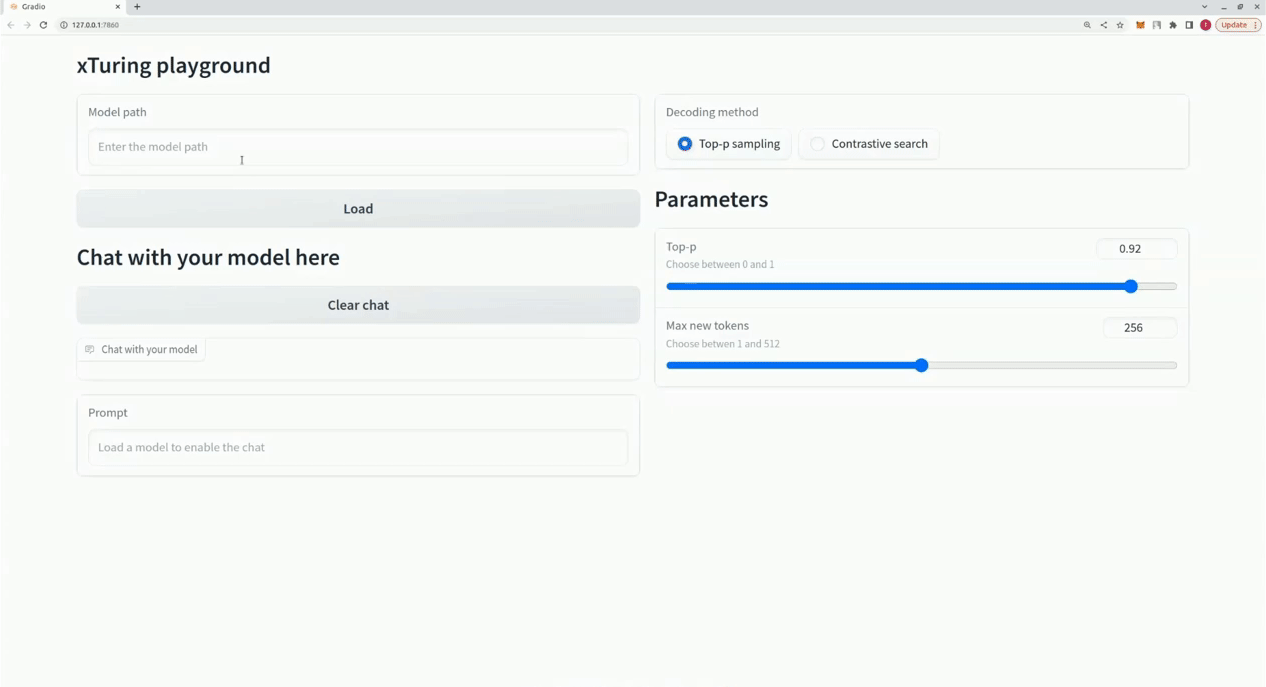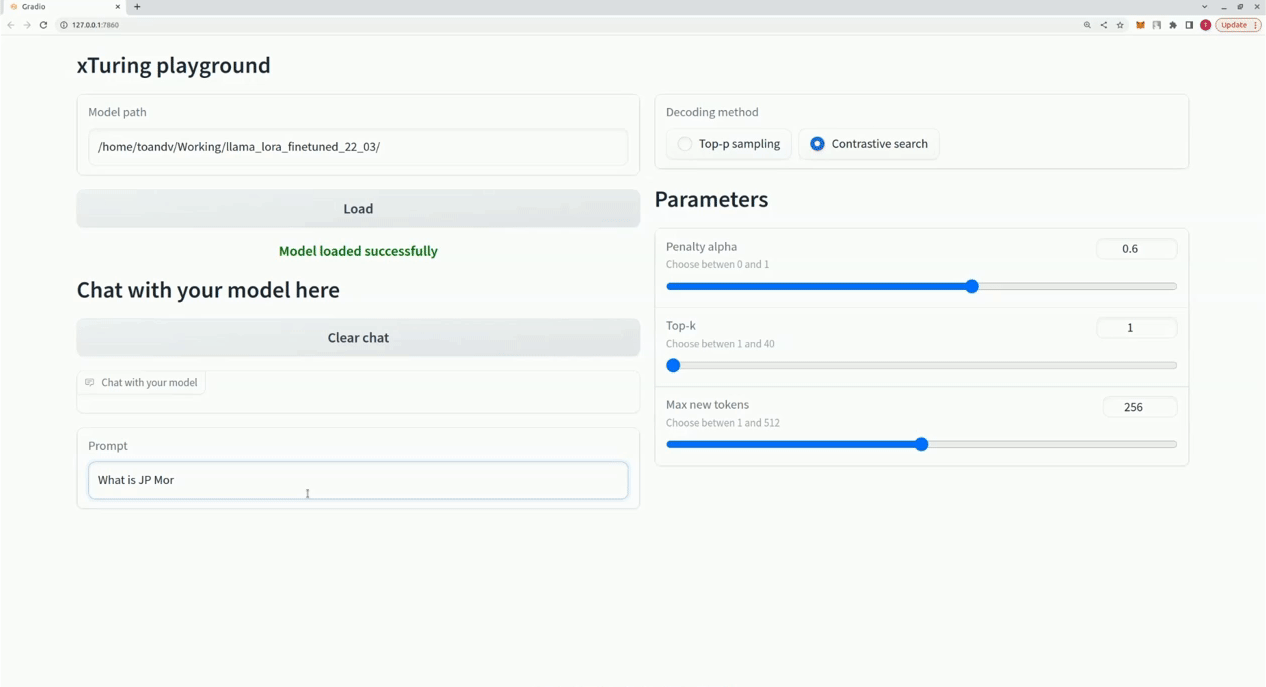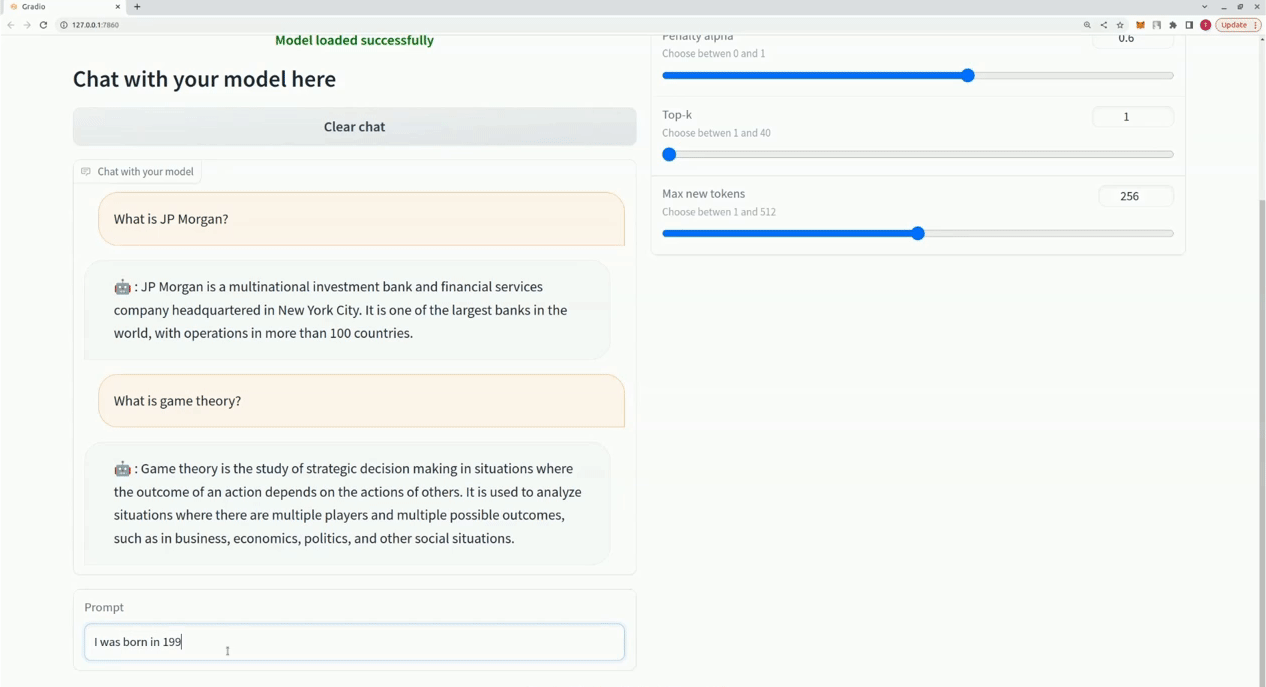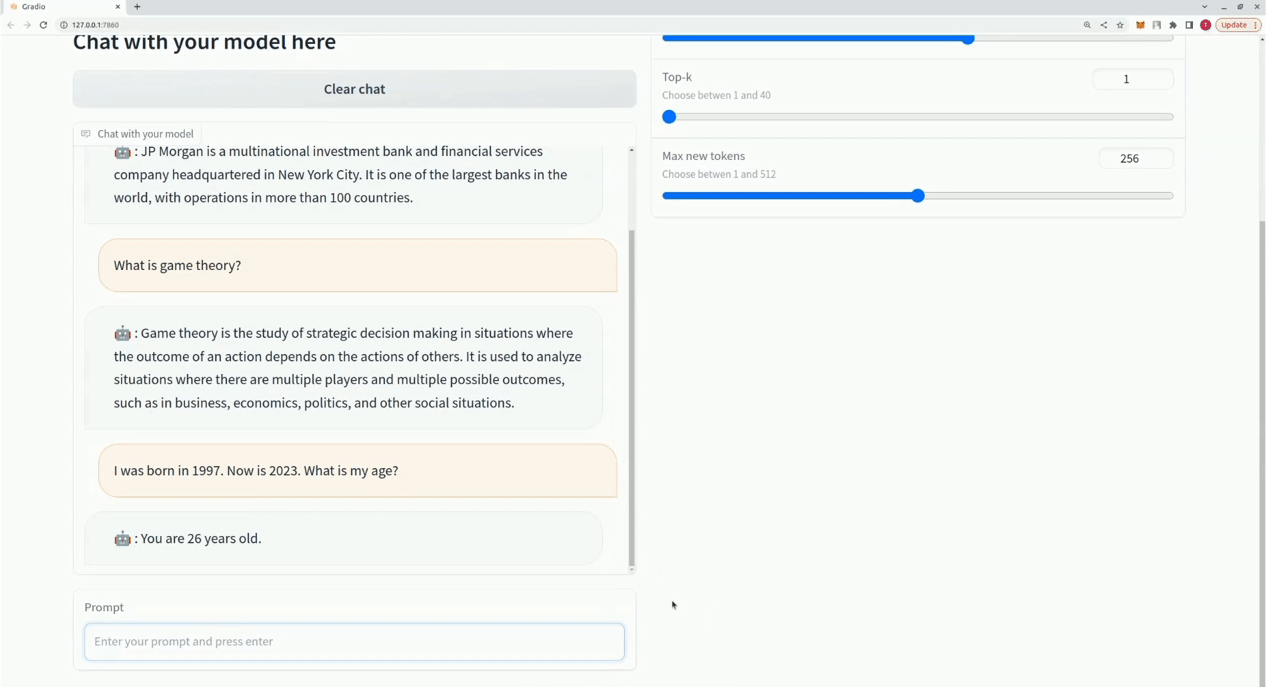
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI 以下は、LLaMA 7B モデルでのさまざまな微調整テクニックのパフォーマンスの比較です。微調整には Alpaca データセットを使用します。データセットには 52K の命令が含まれています。
ハードウェア:
4xA100 40GB GPU、335GB CPU RAM
パラメーターの微調整:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| LLaMA-7B | DeepSpeed + CPU オフロード | LoRA + ディープスピード | LoRA + DeepSpeed + CPU オフロード |
|---|---|---|---|
| GPU | 33.5GB | 23.7GB | 21.9GB |
| CPU | 190GB | 10.2GB | 14.9GB |
| 時間/エポック | 21時間 | 20分 | 20分 |
ハードウェア仕様、メモリ消費量、エポックあたりの時間に関する問題を作成して、他の GPU でのパフォーマンス結果を送信することで、これに貢献してください。
いくつかのモデルはすでに微調整されており、ベースとして使用したり、すぐに遊んだりすることができます。それらをロードする方法は次のとおりです。
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| モデル | データセット | パス |
|---|---|---|
| DistilGPT-2 LoRA | アルパカ | x/distilgpt2_lora_finetuned_alpaca |
| ラマ・ロラ | アルパカ | x/llama_lora_finetuned_alpaca |
以下は、 xTuringのBaseModelクラスを介してサポートされるすべてのモデルと、それらをロードするための対応するキーのリストです。
| モデル | 鍵 |
|---|---|
| 咲く | 咲く |
| 大脳 | 大脳 |
| ディスティルGPT-2 | 蒸留pt2 |
| ファルコン-7B | ハヤブサ |
| ギャラクティカ | ギャラクティカ |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| ラマ | ラマ |
| LlaMA2 | ラマ2 |
| OPT-1.3B | 選択する |
上記は、LLM の基本バリアントです。以下は、 LoRA 、 INT8 、 INT8 + LoRAおよびINT4 + LoRAバージョンを取得するためのテンプレートです。
| バージョン | テンプレート |
|---|---|
| LoRA | <モデルキー>_lora |
| INT8 | <モデルキー>_int8 |
| INT8 + LoRA | <モデルキー>_lora_int8 |
** モデルのINT4+LoRAバージョンをロードするには、 xturing.modelsのGenericLoraKbitModelクラスを利用する必要があります。使用方法は以下のとおりです。
model = GenericLoraKbitModel ( '<model_path>' ) model_path 、ローカル ディレクトリまたはfacebook/opt-1.3bなどの HuggingFace ライブラリ モデルに置き換えることができます。
LLaMA 、 GPT-J 、 GPT-2 、 OPT 、 Cerebras-GPT 、 Galactica 、 BloomモデルのサポートGeneric modelラッパーのサポートFalcon-7Bモデルのサポートご質問がある場合は、このリポジトリで問題を作成できます。
Discord サーバーに参加して、 #xturingチャンネルでディスカッションを開始することもできます。
このプロジェクトは、Apache License 2.0 に基づいてライセンスされています。詳細については、LICENSE ファイルを参照してください。
急速に進化する分野のオープンソース プロジェクトとして、私たちは新機能やドキュメントの改善など、あらゆる種類の貢献を歓迎します。参加方法については、貢献ガイドをお読みください。


