SynMeter
1.0.0

[2024.11.24] 新しい SOTA HP シンセサイザー REaLTabFormer を SynMeter に追加しました。試してみてください!
[2024.09.18] 新しい SOTA HP シンセサイザー TabSyn を SynMeter に追加しました。試してみてください!
新しい conda 環境を作成してセットアップします。
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library ./lib/info/ROOT_DIRのベース辞書を変更します。
ROOT_DIR = root_to_synmeter
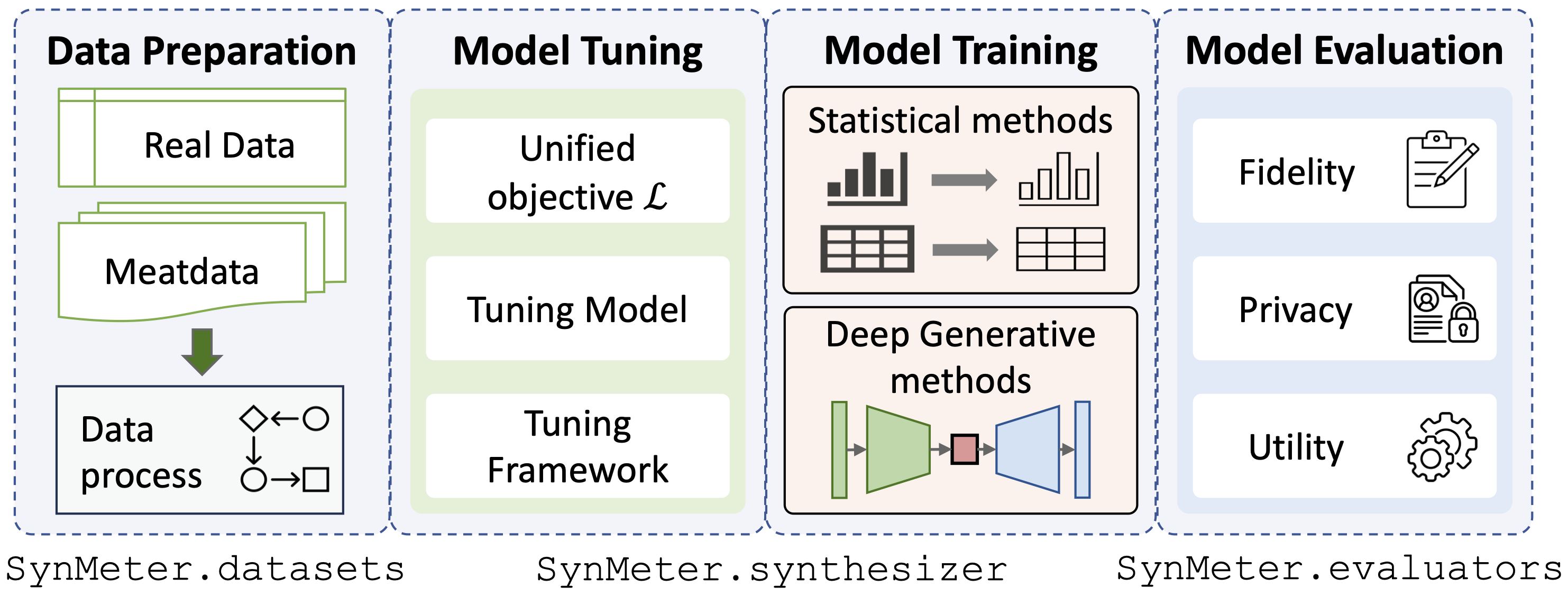
./datasetに置くことで簡単に使用することもできます。./exp/evaluatorsで提供します。python scripts/tune_evaluator.py -d [dataset] -c [cuda]モデル調整のための統一された調整目標を提供するため、あらゆる種類のシンセサイザーを 1 つのコマンドだけで調整できます。
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]チューニング後、構成は/exp/dataset/synthesizerに記録される必要があります。 SynMeter はそれを使用してシンセサイザーをトレーニングおよび保存できます。
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]合成データの忠実性の評価:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] 合成データのプライバシーを評価する:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]合成データの有用性の評価:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed]評価の結果は、対応する辞書/exp/dataset/synthesizerの下に保存する必要があります。
SynMeter の利点の 1 つは、新しい合成アルゴリズムを追加する最も簡単な方法を提供することです。次の 3 つの手順が必要です。
./synthesizer/my_synthesiszerに書き込みます。./exp/base_configに基本構成を作成します。./synthesizerに呼び出し元の Python 関数を作成します。これには、 train 、 sample 、 tune 3 つの関数が含まれます。その後、新しいシンセサイザーを自由に調整、実行、テストできます。
| 方法 | タイプ | 説明 | 参照 |
|---|---|---|---|
| MST | DP | この方法では、確率的グラフィカル モデルを使用して、データ合成の低次元周縁の依存性を学習します。 | 紙、コード |
| PrivSyn | DP | ノンパラメトリック DP シンセサイザー。合成データセットを繰り返し更新して、ターゲットのノイズ限界に一致させます。 | 紙、コード |
| 方法 | タイプ | 説明 | 参照 |
|---|---|---|---|
| CTGAN | HP | 表形式のデータを処理できる条件付き敵対的生成ネットワーク。 | 紙、コード |
| パテガン | DP | この方法では、Private Aggregation of Teacher Ensembles (PATE) フレームワークを使用し、それを GAN に適用します。 | 紙、コード |
| 方法 | タイプ | 説明 | 参照 |
|---|---|---|---|
| TVAE | HP | 表形式のデータを処理できる条件付き VAE ネットワーク。 | 紙、コード |
| 方法 | タイプ | 説明 | 参照 |
|---|---|---|---|
| タブDDPM | HP | 表形式のデータ合成に拡散モデルを使用する | 紙、コード |
| TabSyn | HP | 合成には潜在拡散モデルと VAE を使用します。 | 紙、コード |
| テーブル拡散 | DP | 差分プライバシーの下で表形式のデータセットを生成します。 | 紙、コード |
| 方法 | タイプ | 説明 | 参照 |
|---|---|---|---|
| 素晴らしい | HP | LLM を使用して表形式のデータセットを微調整します。 | 紙、コード |
| REaLTabFormer | HP | GPT-2 を使用して、表形式データのリレーショナル依存性を学習します。 | 紙、コード |
忠実度メトリクス: Wasserstein 距離を原則に基づいた忠実度メトリクスとして考慮し、すべての一元配置および二元配置限界によって計算されます。
プライバシー指標: HP と DP シンセサイザーの両方のメンバーシップ プライバシー リスクを測定するために、メンバーシップ開示スコア (MDS) を考案します。
ユーティリティ メトリクス: 機械学習アフィニティとクエリ エラーを使用して、合成データのユーティリティを測定します。
詳細と使用法については、論文を参照してください。
このプロジェクトでは、多くの優れた合成アルゴリズムとオープンソース ライブラリが使用されています。


