AttackVLM
1.0.0
[プロジェクトページ] | [スライド] | [arXiv] | [データリポジトリ]
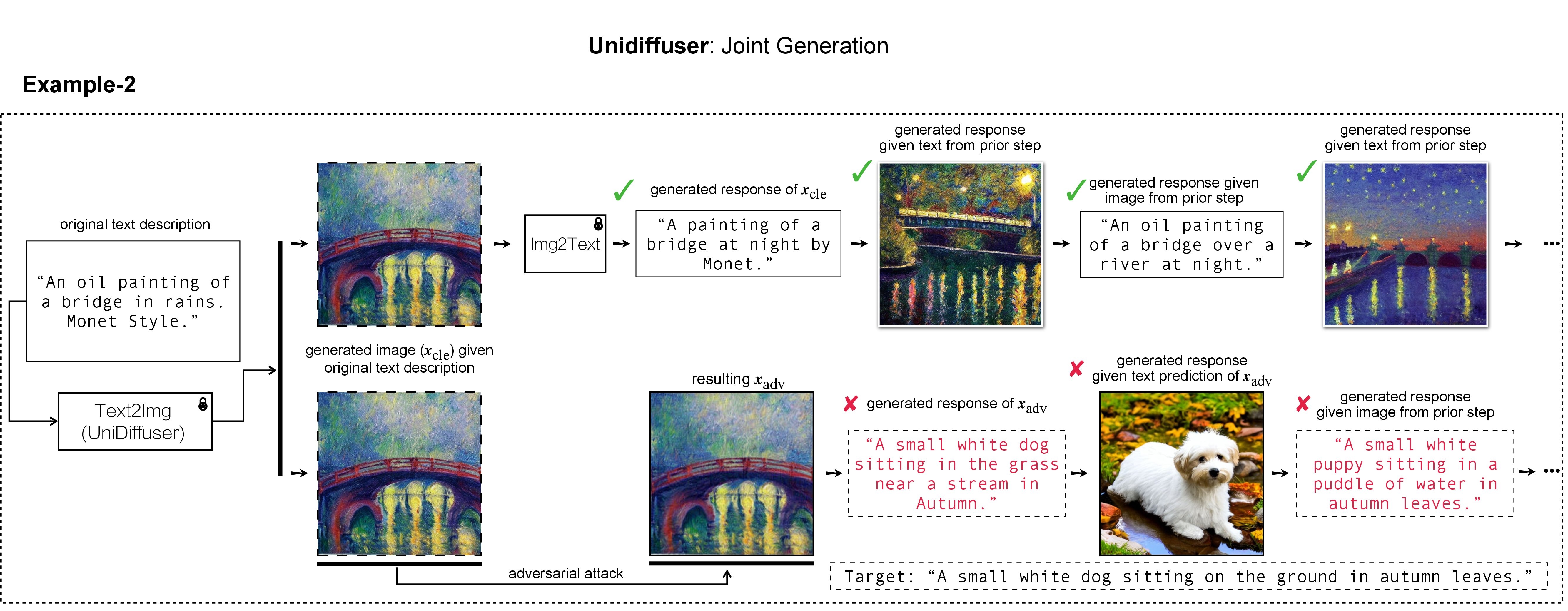
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

私たちの作業では、ターゲット画像の生成とデモンストレーションに DALL-E、Midjourney、および Stable Diffusion を使用しました。大規模な実験では、ターゲット画像の生成に安定拡散を適用します。 Stable Diffusion をインストールするには、潜在拡散モデルに従って conda 環境を初期化します。 ldmという名前の適切な基本 conda 環境は、次のように作成してアクティブ化できます。
conda env create -f environment.yaml
conda activate ldm
さまざまな被害者モデルについては、その公式実装と conda 環境に従うことに注意してください。
 私たちの論文で説明したように、柔軟な標的型攻撃を実現するために、事前トレーニングされたテキストから画像へのモデルを利用して、標的となるテキストとして単一のキャプションが与えられた標的型画像を生成します。これにより、攻撃対象となる字幕を自分で指定できるようになります!
私たちの論文で説明したように、柔軟な標的型攻撃を実現するために、事前トレーニングされたテキストから画像へのモデルを利用して、標的となるテキストとして単一のキャプションが与えられた標的型画像を生成します。これにより、攻撃対象となる字幕を自分で指定できるようになります!
実験では、テキストから画像へのジェネレーターとして、Stable Diffusion、DALL-E、または Midjourney を使用します。ここでは、デモのために Stable Diffusion を使用します (オープンソース化に感謝します!)。
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
次に、MS-COCO からターゲットを絞った完全なキャプションを準備するか、処理およびクリーンアップされたバージョンをダウンロードします。
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
それを./stable-diffusion/に移動します。実験では、敵対的攻撃のために COCO キャプションのサブセット (例: 10 、 100 、 1K 、 10K 、 50K ) をランダムにサンプリングできます。たとえば、ターゲット テキスト c_tar として10K COCO キャプションをランダムにサンプリングし、次のファイルに保存したと仮定します。
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
ターゲット画像 h_ξ(c_tar) は、以下のスクリプトとtxt2img_coco.py ( txt2img_coco.pyを./stable-diffusion/に移動してください。ハイパーパラメータは好みに応じて調整します):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
ここで、ckpt は Stable Diffusion v1 によって提供され、sd-v1-4-full-ema.ckpt からダウンロードできます。
安定拡散によるテキストから画像への生成の実装の詳細については、こちらをご覧ください。
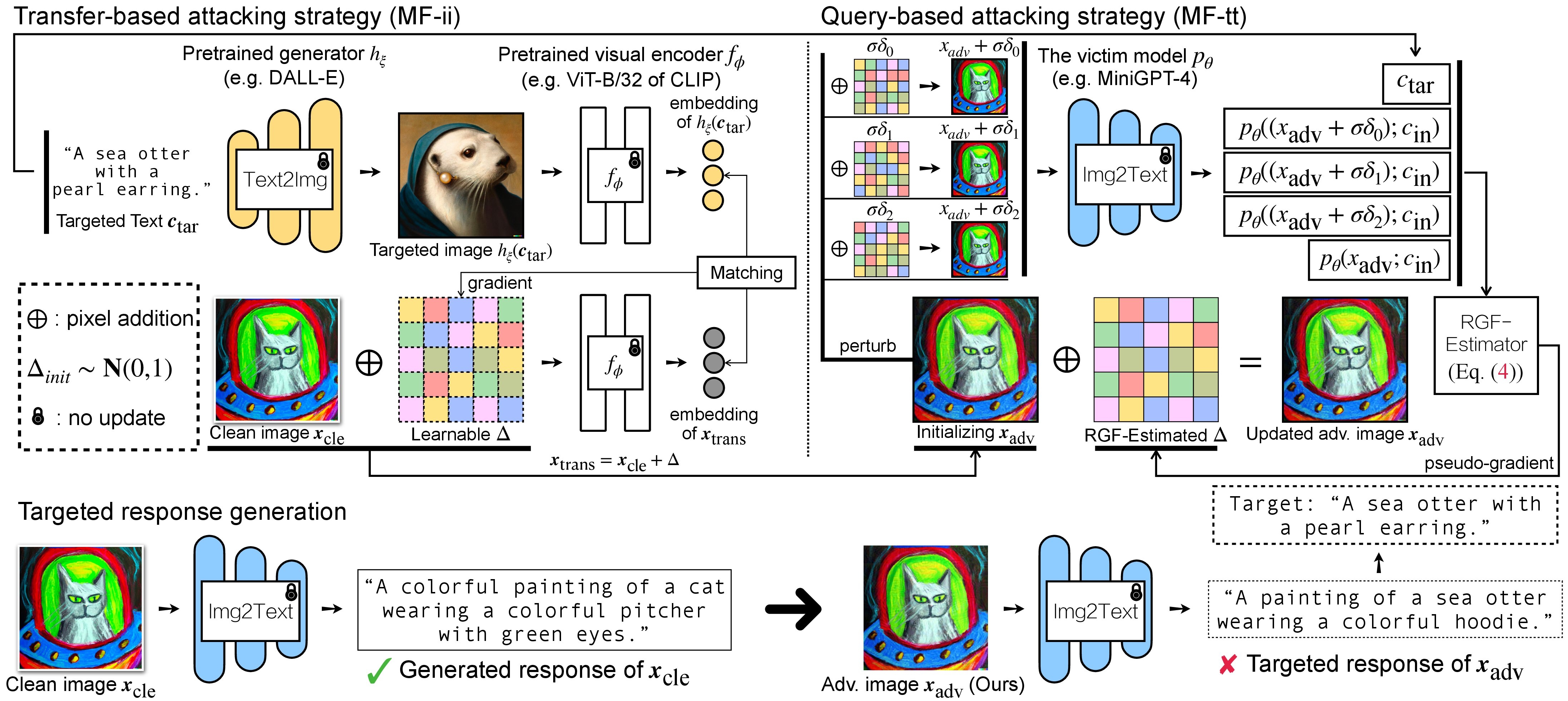
VLM に対する敵対的攻撃には 2 つのステップがあります: (1) 転送ベースの攻撃戦略、および (2) (1) を初期化として使用するクエリベースの攻撃戦略。 BLIP/BLIP-2/Img2Prompt モデルについては、 ./LAVIS_toolを参照してください。ここでは例として Unidiffuser を使用します。
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
次に、こちらの手順に従ってunidiffuserという名前の適切な conda 環境を作成し、対応するモデルの重みを準備します (U-ViT の重みとしてuvit_v1.pth使用します)。
conda activate unidiffuser
bash _train_adv_img_trans.sh
細工された adv イメージ x_trans は、 --outputで指定されたdir of white-box transfer imagesに保存されます。次に、image-to-text を実行し、生成された x_trans の応答を保存します。これは次の方法で実現できます。
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
生成された応答はdir of white-box transfer captionsに.txt形式で保存されます。これらを RGF 推定器による擬似勾配推定に使用します。
MF-ii + MF-tt (例: 8 ピクセル) に固定摂動バジェットを使用すると仮定します。 bash _train_trans_and_query_fixed_budget.sh
一方、別の摂動バジェットを使用して転送 + クエリベースの攻撃を実行したい場合は、追加でスクリプトを提供します。
bash _train_trans_and_query_more_budget.sh
ここでは、 wandbを使用して CLIP スコア (RN50、ViT-B/32、ViT-L/14 など) の移動平均を動的に監視し、(a) 生成された応答 (trans/クエリ画像)、および (b) 事前定義されたターゲット テキストc_tar 。
以下に例を示します。点線は、クエリ後の (画像キャプションの) CLIP スコアの移動平均を示します。 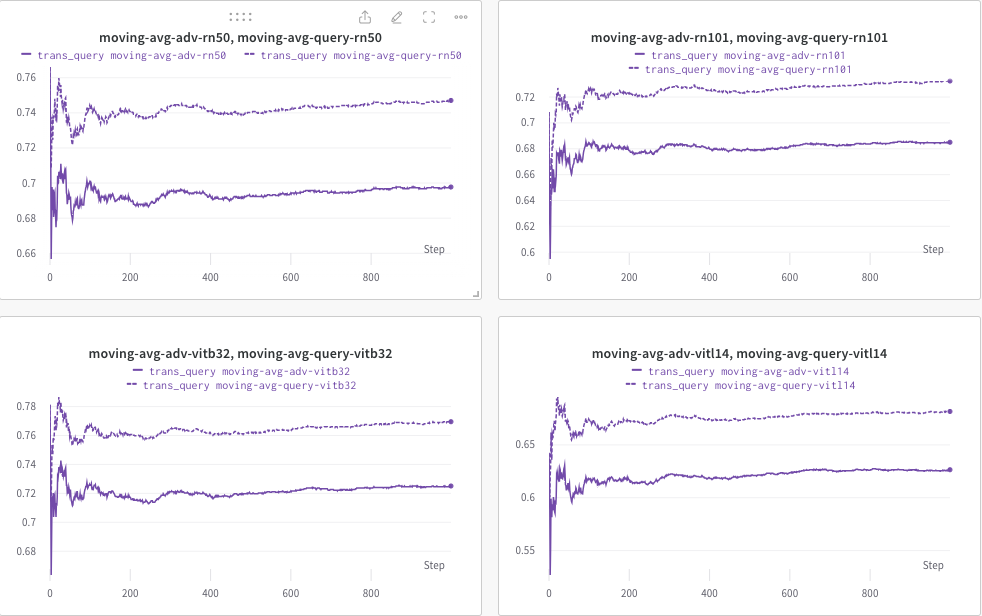
一方、クエリ後の画像キャプションは保存され、ディレクトリは--outputで指定できます。
このプロジェクトがあなたの研究に役立つと思われる場合は、私たちの論文を引用することを検討してください。
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
一方、(マルチモーダル)拡散モデルに透かしを埋め込むことを目的とした関連研究は次のとおりです。
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
MiniGPT-4、LLaVA、Unidiffuser、LAVIS、CLIP の素晴らしい基本実装に感謝します。また、LLaMA チェックポントをオープンソース化した @MetaAI にも感謝します。 @Midjourney が私たちの研究で生成した楽しくて視覚的に楽しい画像を提供してくれた SiSi に感謝します。


