SDV
v1.17.2 - 2024-11-18
このリポジトリは、DataCebo のプロジェクトである The Synthetic Data Vault Project の一部です。



Synthetic Data Vault (SDV) は、表形式の合成データを作成するためのワンストップ ショップとなるように設計された Python ライブラリです。 SDV は、さまざまな機械学習アルゴリズムを使用して実際のデータからパターンを学習し、合成データでパターンをエミュレートします。
?機械学習を使用して合成データを作成します。 SDV は、古典的な統計手法 (GaussianCopula) から深層学習手法 (CTGAN) に至るまで、複数のモデルを提供します。単一テーブル、接続された複数のテーブル、または順次テーブルのデータを生成します。
データを評価して視覚化します。さまざまな基準に対して合成データを実際のデータと比較します。問題を診断し、品質レポートを生成して、より多くの洞察を得ることができます。
前処理、匿名化、および制約の定義。データ処理を制御して合成データの品質を向上させ、さまざまな種類の匿名化から選択し、論理制約の形式でビジネス ルールを定義します。
| 重要なリンク | |
|---|---|
 チュートリアル チュートリアル | SDV を実際に体験してみましょう。チュートリアル ノートブックを起動し、自分でコードを実行します。 |
| ドキュメント | ユーザー ガイドと API リファレンスを使用して、SDV ライブラリの使用方法を学びます。 |
| ?ブログ | SDV の使用、モデルのデプロイ、合成データ コミュニティについてさらに詳しい情報を入手してください。 |
 コミュニティ コミュニティ | Slack ワークスペースに参加して、お知らせやディスカッションを行ってください。 |
| Webサイト | プロジェクトの詳細については、SDV Web サイトをご覧ください。 |
SDV はビジネス ソース ライセンスに基づいて公開されています。 pip または conda を使用して SDV をインストールします。デバイス上の他のソフトウェアとの競合を避けるために、仮想環境を使用することをお勧めします。
pip install sdvconda install -c pytorch -c conda-forge sdv開始するには、デモ データセットをロードします。このデータセットは、架空のホテルに滞在するゲストを記述する単一のテーブルです。
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )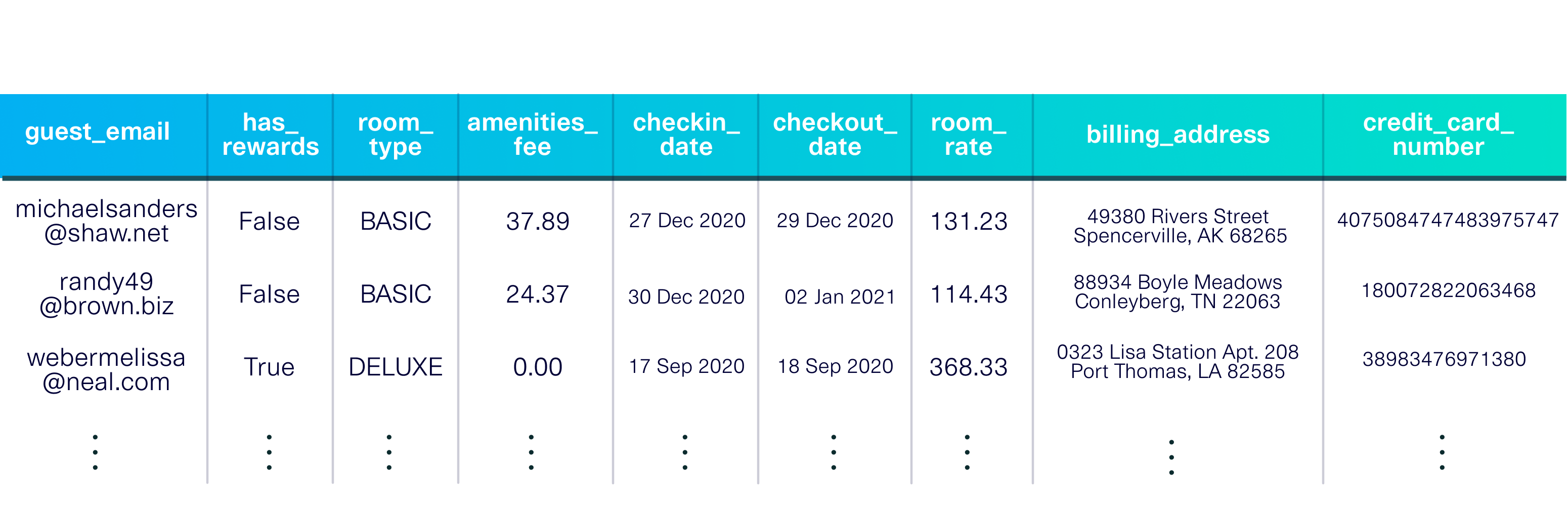
デモには、メタデータ、各列のデータ型や主キー ( guest_email ) などのデータセットの説明も含まれています。
次に、合成データの作成に使用できるオブジェクトであるSDV シンセサイザーを作成できます。実際のデータからパターンを学習し、それを複製して合成データを生成します。 GaussianCopulaSynthesizer を使ってみましょう。
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )これで、シンセサイザーで合成データを作成する準備が整いました。
synthetic_data = synthesizer . sample ( num_rows = 500 )合成データには次のプロパティがあります。
SDV ライブラリを使用すると、合成データを実際のデータと比較して評価できます。品質レポートを生成することから始めます。
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
このオブジェクトは、0 ~ 100% (100 が最高) のスケールで全体的な品質スコアと詳細な内訳を計算します。さらに詳しい洞察が必要な場合は、合成データと実際のデータを視覚化することもできます。
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()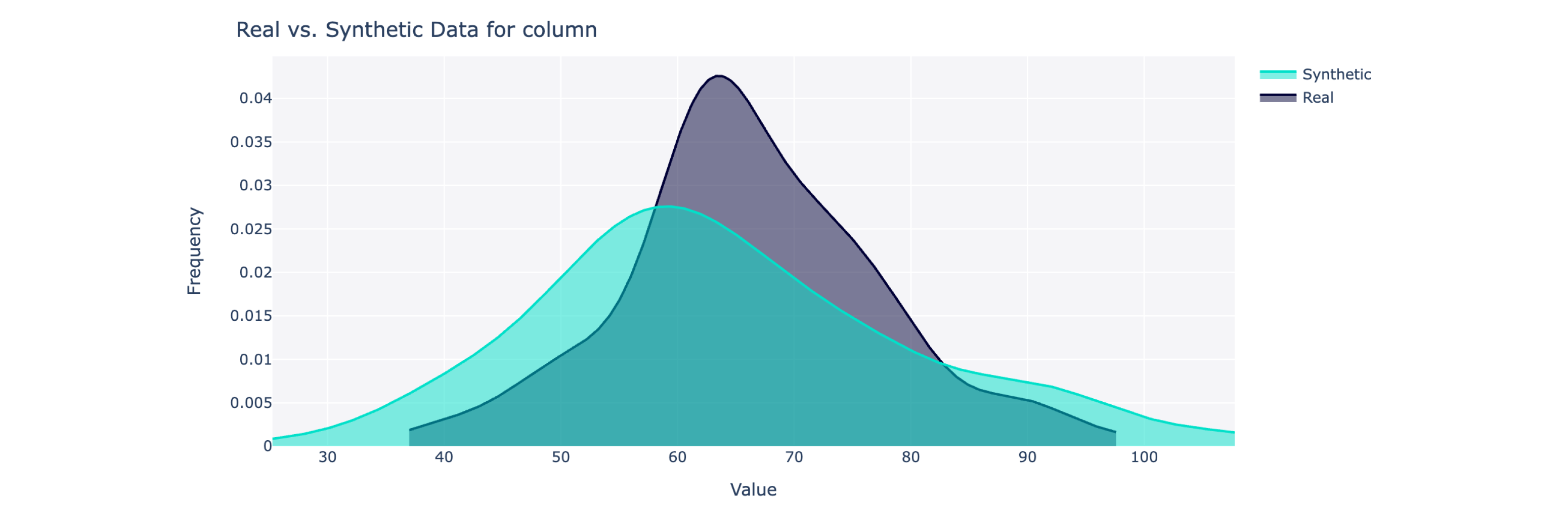
SDV ライブラリを使用すると、単一テーブル、複数テーブル、およびシーケンシャル データを合成できます。前処理、匿名化、制約の追加など、完全な合成データのワークフローをカスタマイズすることもできます。
詳細については、SDV デモ ページをご覧ください。
長年にわたって SDV エコシステムを構築、維持してきた貢献者チームに感謝します。
寄稿者を表示
研究に SDV を使用する場合は、次の論文を引用してください。
ネーハ・パトキ、ロイ・ウェッジ、カリヤン・ヴィラマチャネニ。合成データ ボールト。 IEEE DSAA 2016。
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Synthetic Data Vault プロジェクトは、2016 年に MIT の Data to AI Lab で初めて作成されました。4 年間の研究と企業との協力を経て、プロジェクトの成長を目的として 2020 年に DataCebo を作成しました。現在、DataCebo は、合成データの生成と評価のための最大のエコシステムである SDV の開発者として誇りを持っています。ここには、合成データをサポートする次のような複数のライブラリがあります。
SDV パッケージの使用を開始してください。これは完全に統合されたソリューションであり、合成データのワンストップ ショップです。または、特定のニーズに応じてスタンドアロン ライブラリを使用します。


