LipGER
Initial Release
これは、InterSpeech 2024 での口頭発表に選ばれた論文「LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition」の正式な実装です。
LipHypのデータはこちらからダウンロードできます!
pip install -r requirements.txt
まず、以下を使用してチェックポイントを準備します。
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hf利用可能なチェックポイントをすべて表示するには、次を実行します。
python scripts/download.py | grep Llama-2詳細については、このリンクを参照してください。ここでは、他のモデル用の他のチェックポイントを準備することもできます。具体的には、実験には TinyLlama を使用します。
チェックポイントはここから入手できます。ダウンロード後、ここでチェックポイントのパスを変更します。
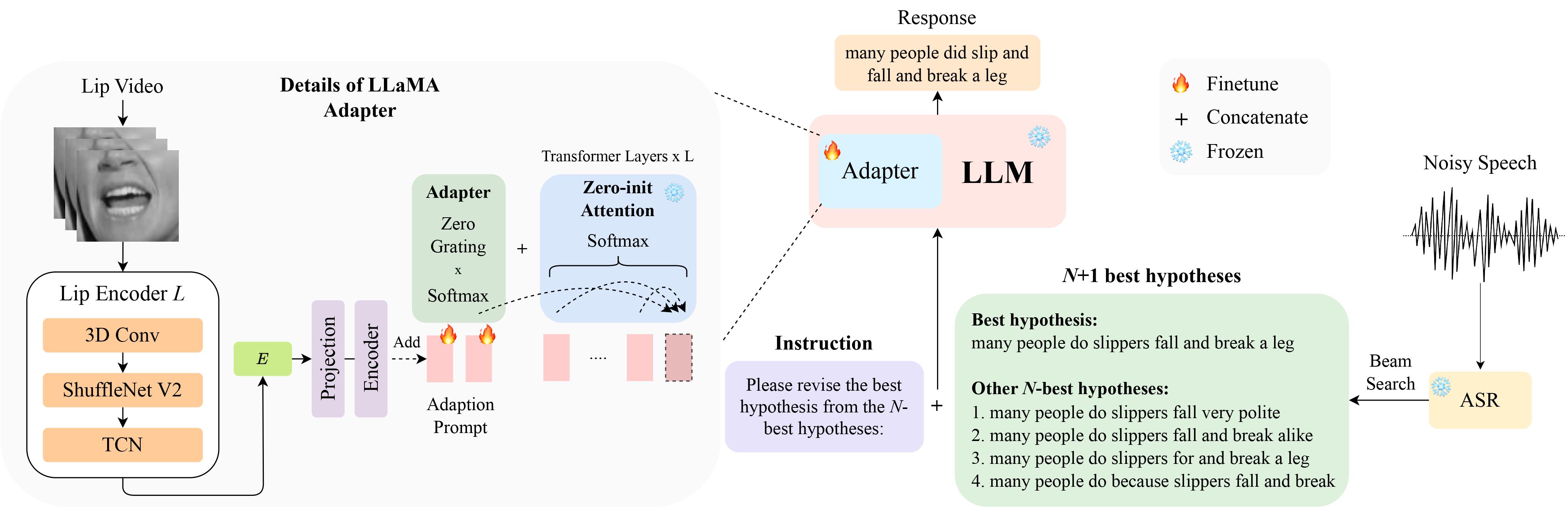
LipGER は、すべての train、val、test ファイルがsample_data.json の形式であることを想定しています。ファイル内のインスタンスは次のようになります。
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
N 最良の仮説を生成できるトレーニング済みの ASR モデルに音声ファイルを渡す必要があります。このリポジトリでは、これを達成するのに役立つ 2 つの方法を提供します。他の方法も自由に使用してください。
pip install whisperを使用して Whisper をインストールし、 dataフォルダーから nhyps.py を実行すれば、うまくいくはずです。どちらの方法でも、リストの最初の仮説が最良の仮説であり、残りが N 番目の最良の仮説であることに注意してください (これらは、JSON のリストnhyps_baseフィールドとして渡され、次の手順でプロンプトを構築するために使用されます)。
さらに、提供されるメソッドは入力として音声のみを使用します。オーディオビジュアルの N ベスト仮説生成には、Auto-AVSR を使用しました。コードに関してサポートが必要な場合は、問題を提起してください。
すべての音声ファイルに対応するビデオがあると仮定して、次の手順に従ってビデオから口の ROI を切り抜きます。
python crop_mouth_script.py
python covert_lip.py
これにより、mp4 ROI が hdf5 に変換され、コードは同じ json ファイル内で mp4 ROI のパスを hdf5 ROI に変更します。 default.yaml の「検出器」を変更することで、「mediapipe」検出器と「retinaface」検出器から選択できます。
N 最良の仮説を取得したら、必要な形式で JSON ファイルを構築します。データの準備は人によって異なる可能性があるため、この部分には特定のコードは提供しませんが、コードは単純である必要があります。繰り返しになりますが、疑問がある場合は問題を提起してください。
LipGER トレーニング スクリプトは、トレーニングまたは評価のために JSON を取り込みません。それらを pt ファイルに変換する必要があります。これを実現するには、convert_to_pt.py を実行します。 27行目でmodel_name希望に応じて変更し、58行目でJSONへのパスを追加します。
LipGER を微調整するには、次を実行するだけです。
sh finetune.sh
ここでは、 data (データセット名を使用)、 --train_pathおよび--val_path (トレーニングおよび有効な .pt ファイルへの絶対パスを使用) の値を手動で設定する必要があります。
推論するには、まず lipger.py 内のそれぞれのパス ( exp_pathおよびcheckpoint_dir ) を変更してから、(適切なテスト データ パス引数を使用して) 実行します。
sh infer.sh
口の ROI をトリミングするコードは、Visual_Speech_Recognition_for_Multiple_Languages からインスピレーションを得ています。
LipGER のコードは RobustGER からインスピレーションを得ています。私たちの論文やコードが役立つと思われる場合は、彼らの論文も引用してください。
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


