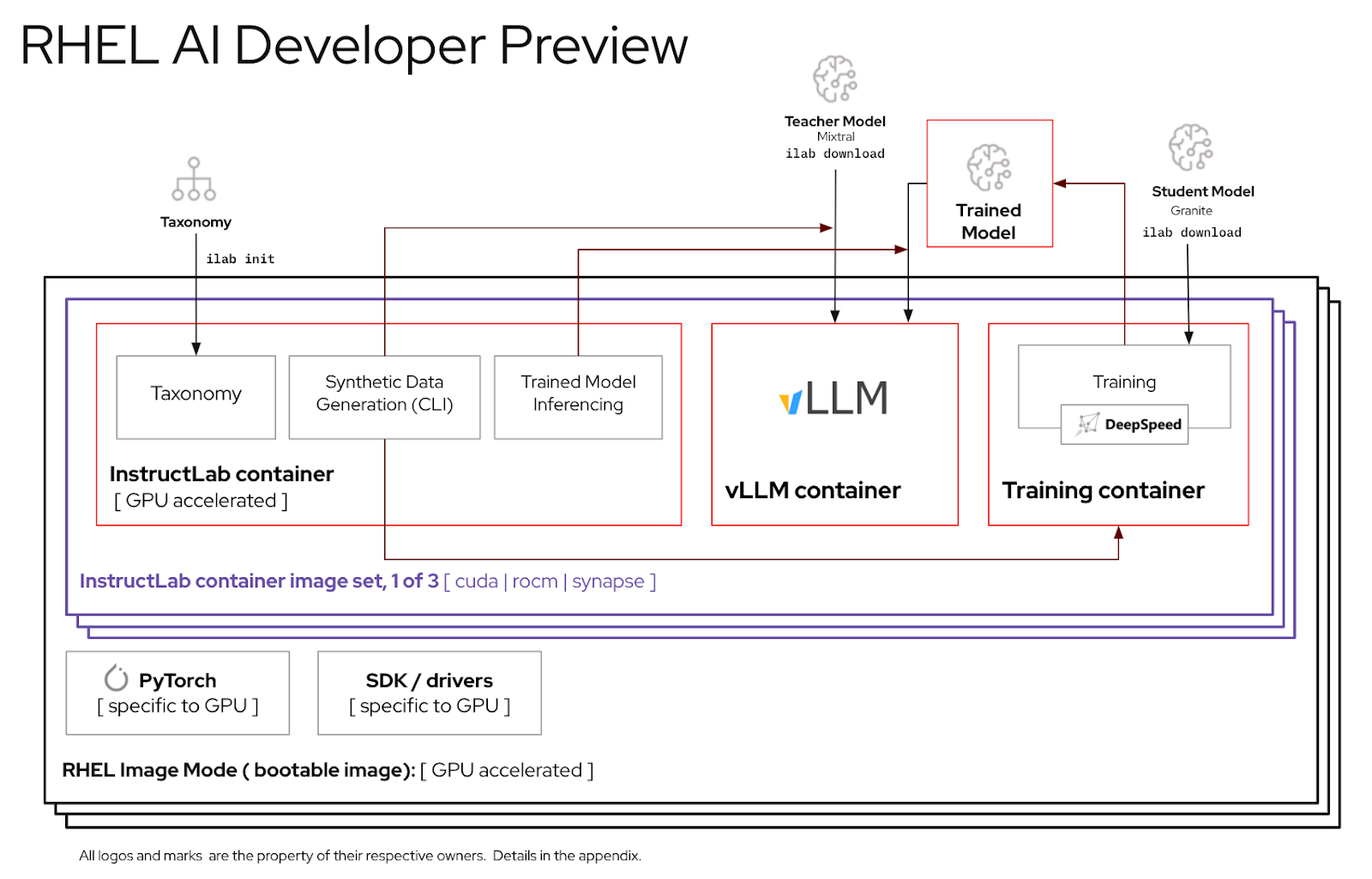
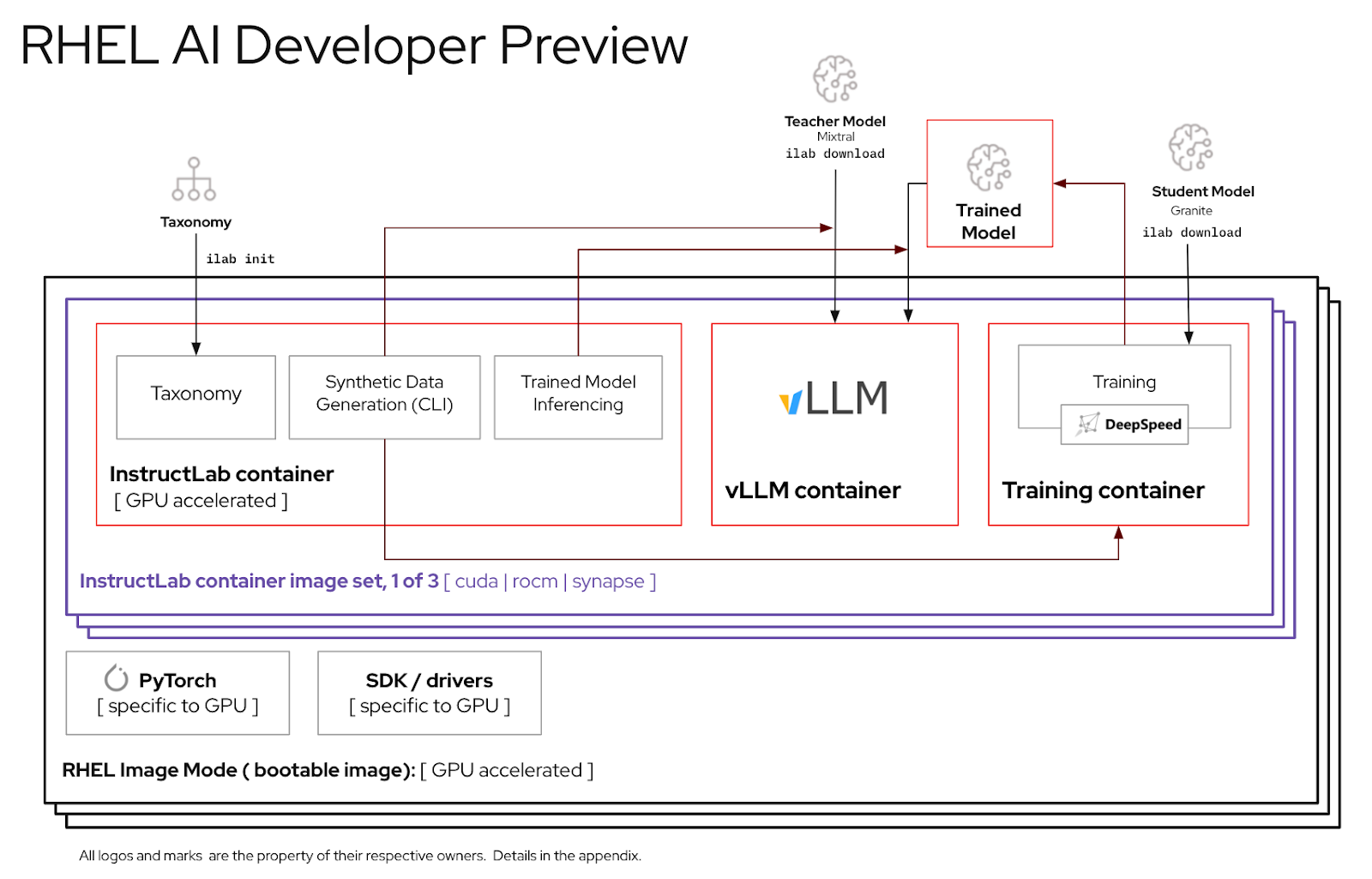
このガイドは、RHEL AI 製品の開発者プレビュー バージョンを組み立ててテストするのに役立ちます。
Red Hat Enterprise Linux AI 開発者プレビューへようこそ!このガイドは、RHEL AI Developer Preview の機能を紹介することを目的としています。他の開発者プレビューと同様に、GA の前に、これらのワークフローへの変更、追加の自動化と簡素化、機能の拡張、ハードウェアとソフトウェアのサポート バージョン、パフォーマンスの向上 (およびその他の最適化) が期待されます。
RHEL AI は、以下を含むオープンソース製品です。
注記
RHEL AI は、個別の GPU を備えたサーバー プラットフォームとワークステーションを対象としています。ラップトップの場合は、上流の InstructLab を使用してください。
以下は、RHEL AI Developer Preview で動作することが Red Hat エンジニアによって検証されたサーバーのリストです。以下にリストするような最近のデータセンター GPU を搭載した RHEL 9 の実行が認定された最近のシステムは、この開発者プレビューで動作すると予想されます。
| GPU ベンダー / スペック | RHEL AI 開発プレビュー |
|---|---|
| デル (4) NVIDIA H100 | はい |
IBM GX3インスタンス | はい |
| レノボ (8) AMD MI300x | はい |
| AWS p4 および p5 インスタンス (NVIDIA) | 進行中 |
| インテル | 進行中 |
RHEL AI 開発者プレビュー期間を使用して最高のエクスペリエンスを得るために、InstructLab コンテナー内に枝刈りされた分類ツリーが含まれています。これにより、単一サーバー上で妥当な時間枠内でトレーニングを完了することを検証できるようになります。
計算式: 1 つの GPU で 1 分あたり最大 250 のサンプルをトレーニングできます。 8 つの GPU と 10,000 のサンプルがある場合、それには時間がかかることが予想されます
この演習を終了するまでに、次のことができるようになります。
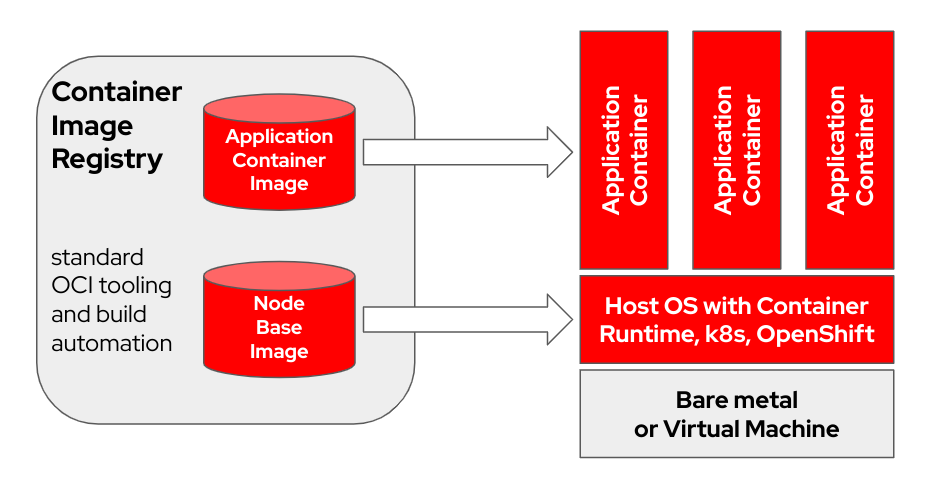
bootc 、OCI/Docker コンテナ イメージを使用してプロビジョニングおよび更新を行う、トランザクション対応のインプレース オペレーティング システムです。 bootc 、ブート可能コンテナーの広範な使命における重要なコンポーネントです。
「レイヤー」を使用してアプリケーションをモデル化するオリジナルの Docker コンテナ モデルは、非常に成功しました。このプロジェクトは、同じ技術をブート可能なホスト システムに適用することを目的としています。標準の OCI/Docker コンテナをベース オペレーティング システムのアップデートのトランスポートおよび配信形式として使用します。
コンテナイメージには、ブートに使用される Linux カーネル ( /usr/lib/modulesなど) が含まれています。ターゲット システムでの実行時、デフォルトでは、ベース ユーザー空間自体はコンテナ内で実行されません。たとえば、 systemd使用されていると仮定すると、 systemd通常どおりpid1として機能します。「外部」プロセスはありません。
次の例では、bootc コンテナーにはNode Base Imageラベルが付けられています。
ビルド ホスト ハードウェアとインターネット接続速度によっては、コンテナ イメージのビルドとアップロードに最大 2 時間かかる場合があります。
m5.xlargeでテスト済み)quay.ioまたは別のイメージ レジストリ)。 ホストの登録 (Red Hat Subscription-Manager を使用して RHEL システムを Red Hat カスタマーポータルに登録してサブスクライブする方法)
sudo subscription-manager register --username < username > --password < password >必要なパッケージをインストールする
sudo dnf install git make podman buildah lorax -yRHEL AI Developer Preview git リポジトリのクローンを作成します。
git clone https://github.com/RedHatOfficial/rhelai-dev-preview redhat.comアカウントを使用して、Red Hat レジストリーに対する認証 (Red Hat Container Registry Authentication) を行います。
podman login registry.redhat.io --username < username > --password < password >
podman login --get-login registry.redhat.io
Your_login_hereビルド ホストに SSH キーがあることを確認してください。これは、ドライバー ツールキット イメージのビルド中に使用されます。 (Linux でのssh-keygenの使用とキーベースの認証の共有 | Sysadmin の有効化)
RHEL AI には、コンテナー イメージの作成を容易にする一連の Makefile が含まれています。ビルド ホスト ハードウェアとインターネット接続速度によっては、これには最大 1 時間かかる場合があります。
InstructLab NVIDIA コンテナー イメージをビルドします。
make instruct-nvidia vllmコンテナー イメージをビルドします。
make vllm deepspeedコンテナー イメージをビルドします。
make deepspeed最後に、RHEL AI NVIDIA bootcコンテナー イメージをビルドします。これは、RHEL イメージモードの「ブート可能」コンテナーです。上の 3 つの画像をこのコンテナに埋め込みます。
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY= < your-registry > REGISTRY_ORG= < your-org-name >結果のイメージには${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latestタグが付けられます。その他の変数と例については、トレーニング/README を参照してください。
結果のイメージをレジストリにプッシュします。次の手順で、キックスタート ファイル内でこの URL を参照します。
podman push ${REGISTRY} / ${REGISTRY_ORG} /nvidia-bootc:latest
e.g. podman push quay.io/ < your-user-name > /nvidia-bootc.latestこの時点で、RHEL AI ブート可能コンテナー イメージを物理ホストまたは仮想ホストにインストールする準備ができました。
Anaconda は Red Hat Enterprise Linux インストーラーであり、RHEL のダウンロード可能なすべての ISO イメージに組み込まれています。 RHEL のインストールを自動化する主な方法は、キックスタートと呼ばれるスクリプトを使用することです。 Anaconda と Kickstart の詳細については、これらのドキュメントを参照してください。
ostreecontainerと呼ばれる最近のキックスタート コマンドが RHEL 9.4 で導入されました。 ostreecontainer使用して、ネットワーク経由でレジストリにプッシュしたブート可能なnvidia-bootcコンテナをプロビジョニングします。
以下はキックスタート ファイルの例です。これをrhelai-dev-preview-bootc.ksというファイルにコピーし、環境に合わせてカスタマイズします。
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io//nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
RHEL 9.4「ブート ISO」をダウンロードし、 mkksisoコマンドを使用してキックスタートを RHEL ブート ISO に埋め込みます。
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoこの時点で、以下が必要になります。
nvidia-bootc:latest : NVIDIA GPU をサポートするブート可能なコンテナー イメージrhelai-dev-preview-bootc.ks : コンテナー レジストリからターゲット システムに RHEL をプロビジョニングするためにカスタマイズされたキックスタート ファイル。rhelai-dev-preview-bootc-ks.iso : キックスタートが組み込まれた起動可能な RHEL 9.4 ISO。 rhelai-dev-preview-bootc-ks.isoファイルを使用してターゲットシステムを起動します。 anaconda はレジストリから nvidia-bootc:latest イメージをプルし、キックスタート ファイルに従って RHEL をプロビジョニングします。
代替方法: キックスタート ファイルは HTTP 経由で提供できます。カーネルコマンドラインと外部 HTTP サーバーを介したインストールでは、 inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ksを追加します。
RHEL AI 環境を使用する前に、高忠実度チューニング プロセスの主要な機能に合わせて調整された 2 つのモデルをダウンロードする必要があります。 Granite はスチューデント モデルとして使用され、新しい微調整モードのトレーニングを促進する役割を果たします。 Mixtral は教師モデルとして使用され、LAB プロセスの生成フェーズを支援する役割を果たします。このフェーズでは、スキルと知識が連携して使用され、豊富なトレーニング データセットが生成されます。
Settingsクリックします。Access Tokensをクリックします。 New tokenボタンをクリックし、名前を入力します。新しいトークンはモデルをフェッチするためにのみ使用されるため、 Readアクセス許可の使用のみが必要です。この画面では、トークンの内容を生成し、認証するためのテキストを保存およびコピーできます。 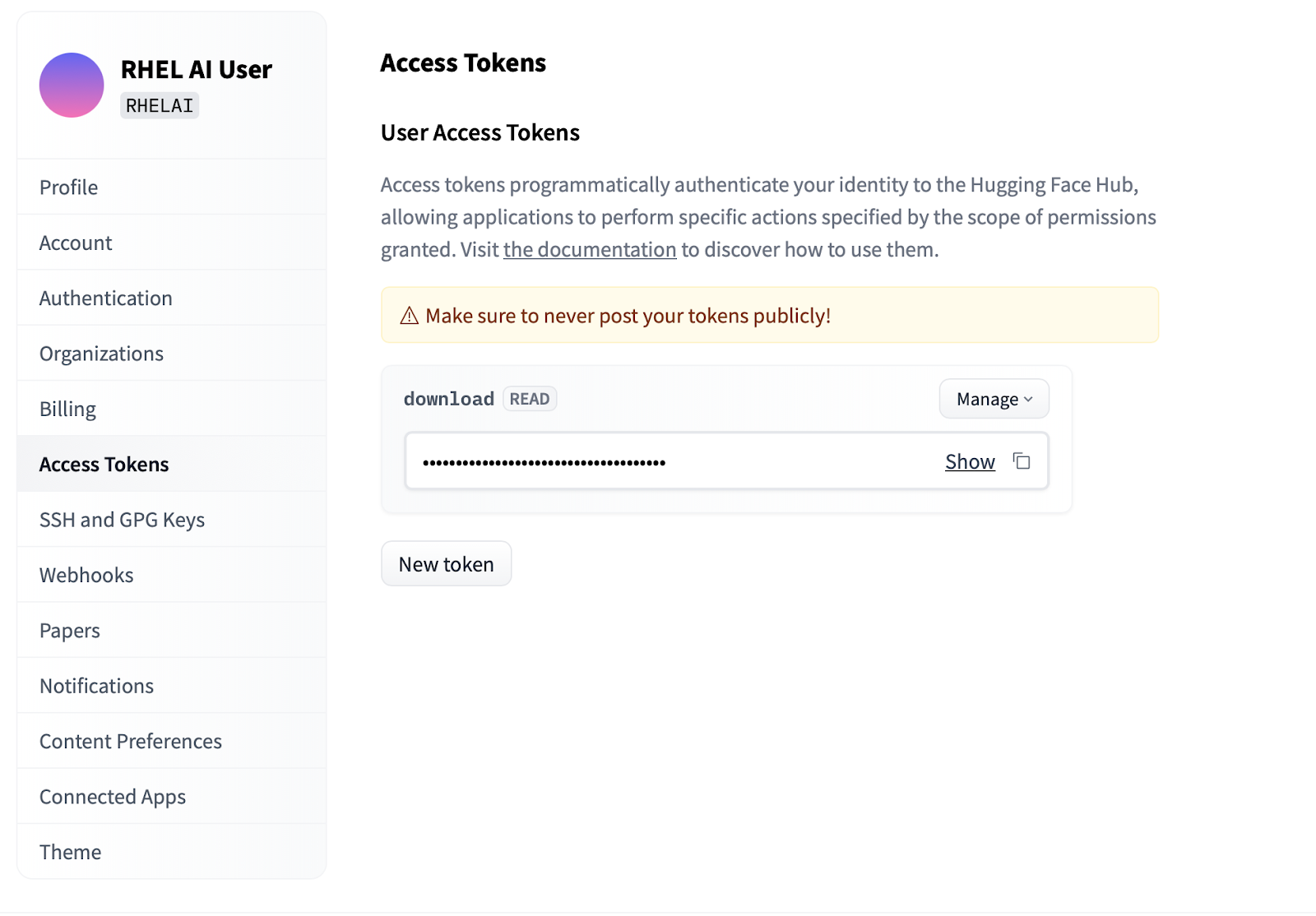
InstructLab プロジェクトの一部であるilabコマンド ライン インターフェイスは、ラップトップなどのパーソナル コンピューティング デバイス上で軽量の量子化モデルを実行することに重点を置いています。対照的に、RHEL AI では、完全精度モデルを使用した高忠実度のトレーニングの使用が可能になります。わかりやすくするために、コマンドとパラメーターは InstructLab のilabコマンドのものを反映しています。ただし、バッキングの実装は大きく異なります。
RHEL AI では、
ilabコマンドは、RHEL AI システムに事前にバンドルされているコンテナー アーキテクチャのフロントエンドとして機能するラッパーです。
ilabコマンドラインインターフェイスの使用最初のステップは、プロジェクト用の新しい作業ディレクトリを作成することです。すべてはこの作業ディレクトリに相対的なものになります。これには、モデル、ログ、トレーニング データが含まれます。
mkdir my-project
cd my-project最初に実行するilabコマンドは、選択した場合に分類リポジトリのダウンロードを含む、基本環境をセットアップします。これは後の手順で必要になるため、そうすることをお勧めします。
ilab init上記の「アクセス トークン」セクションで作成した HF トークンを使用して環境変数を定義します。
export HF_TOKEN= < paste token value here > 次に、IBM Granite 基本モデルをダウンロードします。重要: モデルの「ラボ」バージョンをダウンロードしないでください。花崗岩のベースモデルは、高忠実度のトレーニングを実行する場合に最も効果的です。
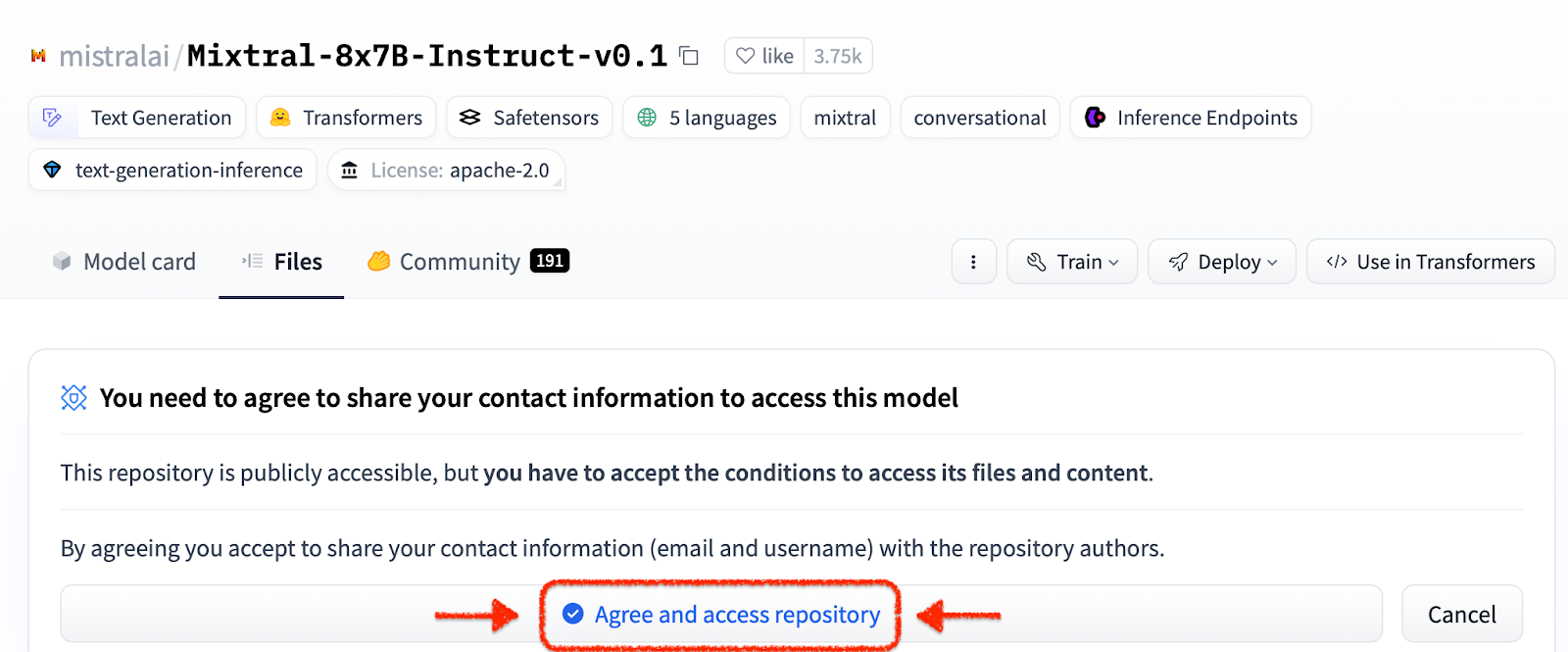
ilab download --repository ibm/granite-7b-base同じプロセスに従って、Mixtral モデルをダウンロードします。
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1プロジェクトを初期化し、最初のモデルをダウンロードしたので、プロジェクトのディレクトリ構造を観察してください。
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| フォルダ | 目的 |
|---|---|
| モデル | RHEL AI で生成した保存された出力を含む、すべての言語モデルを保持します。 |
| 生成された | 分類リポジトリへの変更に基づいて構築された、生成フェーズからの生成データ出力 |
| 分類学 | トレーニング用の合成データを生成するために LAB メソッドで使用されるスキルまたは知識データ |
| トレーニング | トレーニングプロセスを容易にするために変換されたシードデータ |
| トレーニング出力 | ログや実行中のサンプル チェックポイントを含む、トレーニング プロセスのすべての一時的な出力 |
| キャッシュ | モデルデータによって使用される内部キャッシュ |
次のステップは、新しい知識やスキルを分類リポジトリに提供することです。これを行う方法の詳細と例については、InstructLab のドキュメントを参照してください。ここには一連のラボ演習もあります。
追加の分類データが追加されたことで、新しい合成データを生成して、最終的に新しいモデルをトレーニングできるようになりました。ただし、生成を開始する前に、ジェネレーターによる新しいデータの構築を支援するために、まず教師モデルを開始する必要があります。別の端末セッションで「serve」コマンドを実行し、VLLM の起動が完了するまで待ちます。このプロセスが完了するまでに数分かかる場合があることに注意してください
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)VLLM が教師モードとして機能するようになったので、 ilab生成コマンドを使用して生成プロセスを開始できます。このプロセスは完了するまでに時間がかかり、更新されるたびに生成された命令の総数が継続的に出力されます。これはデフォルトで 5000 命令ですが、 --num-instructionsオプションを使用して調整できます。
ilab generate Q> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
生成中に画面に表示される現在のデータに加えて、完全な出力が生成されたフォルダーに記録されます。トレーニングの前に、この出力をレビューして、期待を満たしていることを確認することをお勧めします。満足のいくものでない場合は、分類法内の例を変更または作成して再実行してください。
less generated/generated_Mixtral * .json生成されたデータが満足のいくものであれば、トレーニング プロセスを開始できます。ただし、最初に、生成のために開始されたターミナル セッションで VLLM インスタンスを閉じます。
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
Python KeyboardInterrupt 例外とスタック トレースを受け取る場合があります。これは無視しても問題ありません。
VLLM を停止し、新しいデータを生成したら、 ilab trainコマンドを使用してトレーニング プロセスを開始できます。デフォルトでは、トレーニング プロセスは 4999 サンプルごとにモデル チェックポイントを保存します。 --num-samplesパラメーターを使用してこれを調整できます。さらに、トレーニングはデフォルトで 10 エポック実行されますが、これは--num-epochsパラメーターで調整することもできます。一般に、エポック数が多いほど良いですが、ある時点を超えると、エポック数が増えると過剰適合が発生します。通常は、10 エポック以下にとどめ、さまざまなサンプル ポイントを調べて最良の結果を見つけることをお勧めします。
ilab train --num-epochs 9 RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
トレーニング プロセスが完了すると、新しいモデル エントリがモデル ディレクトリに保存され、場所が端末に出力されます。
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
同じilab serveコマンドを使用して、名前とサンプルを指定した –model オプションを渡すことで、新しいモデルを提供できます。
ilab serve --model tuned-0504-0051/samples_49920新しいモデルで VLLM が開始された後、新しいターミナル セッションを作成し、同じ--modelパラメータをチャットに渡すことで、チャット セッションを開始できます (これが一致しない場合は、404 エラー メッセージが表示されることに注意してください)。分類学の貢献に関連した質問をしてください。
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils ?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯セッションを終了するには、
exitと入力します
それでおしまい!開発者プレビューの目的は、ユーザーに早期のフィードバックを得るために何かを提供することです。バグがある可能性があることは承知しております。ここまで来てくださった方には、時間と労力をかけていただいたことに感謝いたします。何らかの問題が発生したか、トラブルシューティングが必要な可能性があります。バグレポート、機能リクエストを提出し、質問することをお勧めします。その方法については、以下の連絡先情報を参照してください。ありがとう!
$ sudo subscription-manager config --rhsm.manage_repos=1nvidia-smiドライバーが動作し、GPU を認識できることを確認します。nvtop (EPEL で利用可能) を使用して、GPU が使用されているかどうかを確認します (一部のコード パスには CPU フォールバックが含まれていますが、これはここでは望ましくない)make prune実行します。これにより、古いビルド アーティファクトがクリーンアップされます。--no-cacheパラメータをビルド プロセスに渡すことで可能になります。 make nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS= " --no-cache "TMPDIR環境変数を使用してこれを行うことができます。 make < platform > TMPDIR=/path/to/tmp