mae
1.0.0
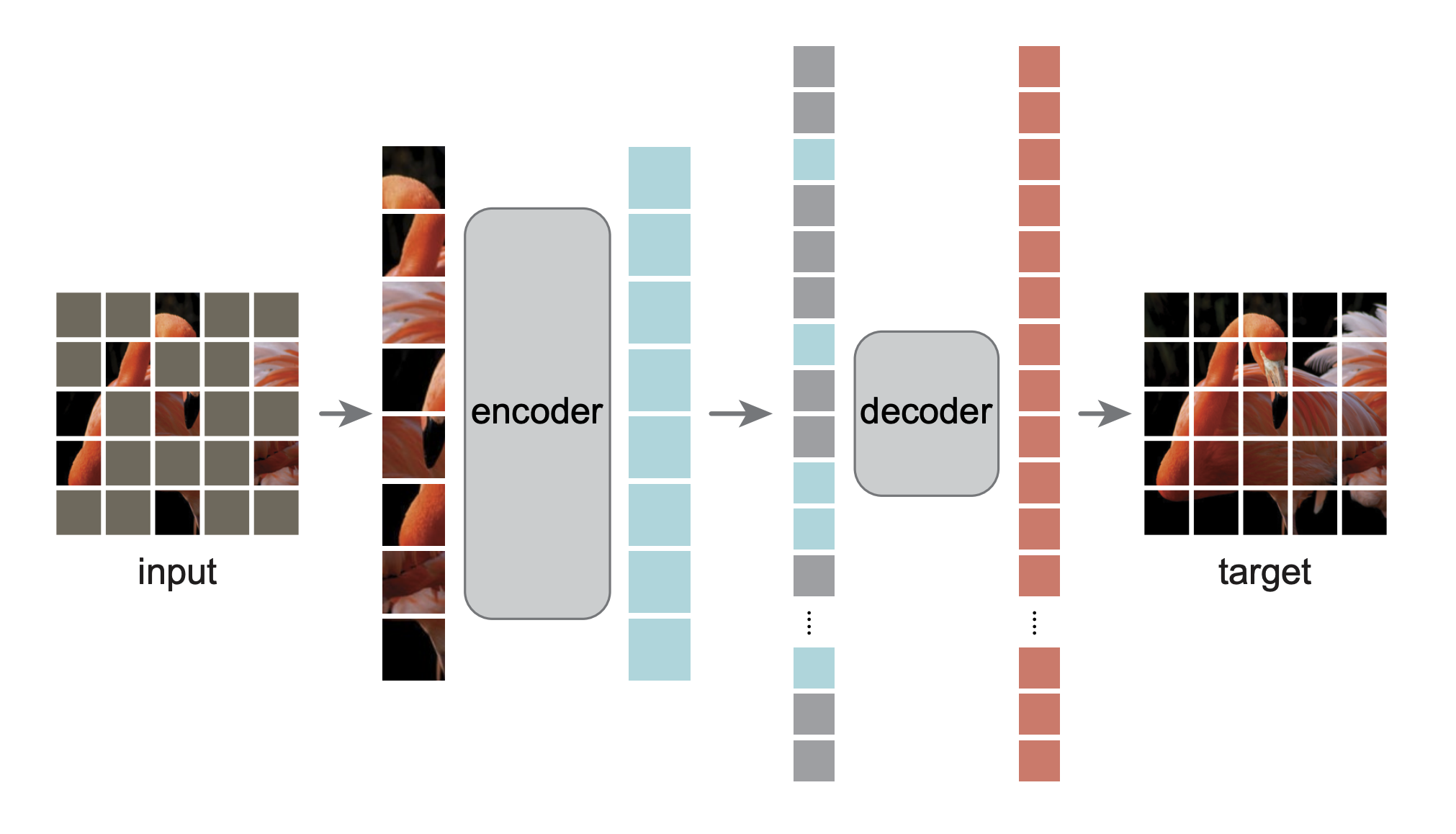
これは、論文「Masked Autoencoders Are Scalable Vision Learners」の PyTorch/GPU 再実装です。
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
元の実装は TensorFlow+TPU でした。この再実装は PyTorch+GPU で行われます。
このリポジトリは DeiT リポジトリを変更したものです。インストールと準備はそのリポジトリに従います。
このリポジトリはtimm==0.3.2に基づいており、PyTorch 1.8.1 以降で動作するには修正が必要です。
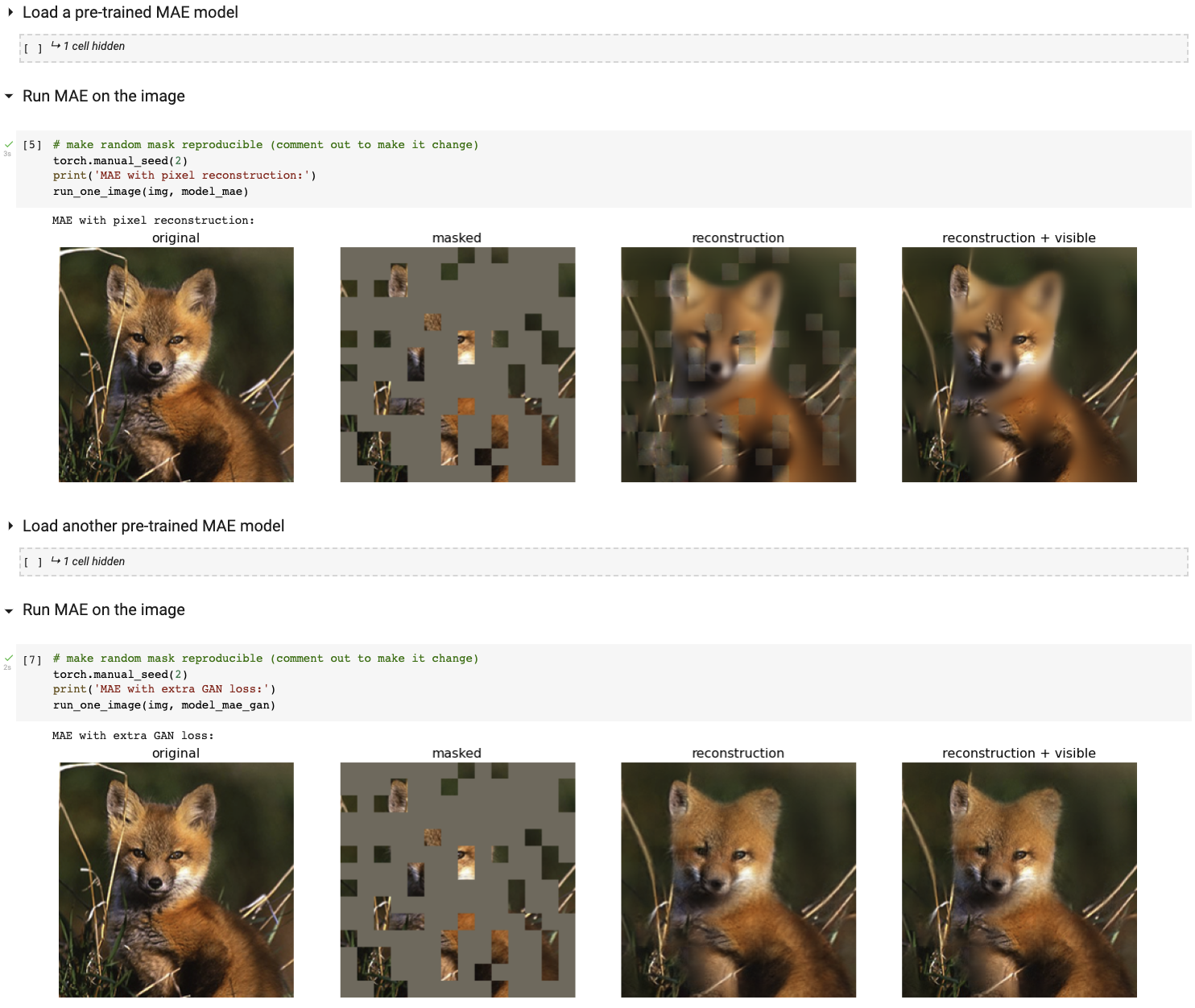
Colab ノートブックを使用してインタラクティブな視覚化デモを実行します (GPU は必要ありません)。
次の表は、この論文で使用されている事前トレーニング済みチェックポイントを TF/TPU から PT/GPU に変換して示しています。
| ViTベース | ViT-Large | ViT-Huge | |
|---|---|---|---|
| 事前に訓練されたチェックポイント | ダウンロード | ダウンロード | ダウンロード |
| MD5 | 8cad7c | b8b06e | 9bdbb0 |
微調整命令は FINETUNE.md にあります。
これらの事前トレーニング済みモデルを微調整することで、次の分類タスクで 1 位にランクされます (詳細は論文で説明しています)。
| ViT-B | ヴィットエル | ヴィット・エイチ | ViT-H 448 | 前のベスト | |
|---|---|---|---|---|---|
| ImageNet-1K (外部データなし) | 83.6 | 85.9 | 86.9 | 87.8 | 87.1 |
| 以下は、同じモデルの重みの評価です (オリジナルの ImageNet-1K で微調整)。 | |||||
| ImageNet の破損 (エラー率) | 51.7 | 41.8 | 33.8 | 36.8 | 42.5 |
| ImageNet-敵対的 | 35.9 | 57.1 | 68.2 | 76.7 | 35.8 |
| ImageNet レンディション | 48.3 | 59.9 | 64.4 | 66.5 | 48.7 |
| ImageNet-Sketch | 34.5 | 45.3 | 49.6 | 50.9 | 36.0 |
| 以下は、ターゲット データセットで事前トレーニングされた MAE を微調整することによる転移学習です。 | |||||
| iナチュラリスト 2017 | 70.5 | 75.7 | 79.3 | 83.4 | 75.4 |
| iナチュラリスト 2018 | 75.4 | 80.1 | 83.0 | 86.8 | 81.2 |
| iナチュラリスト 2019 | 80.5 | 83.4 | 85.7 | 88.3 | 84.1 |
| 場所205 | 63.9 | 65.8 | 65.9 | 66.8 | 66.0 |
| 場所365 | 57.9 | 59.4 | 59.8 | 60.3 | 58.0 |
事前トレーニング命令は PRETRAIN.md にあります。
このプロジェクトは CC-BY-NC 4.0 ライセンスの下にあります。詳細については、「ライセンス」を参照してください。


