このラボでは、前のレッスンで見た数式を実践して、MLE が正規分布でどのように機能するかを確認します。
次のことができるようになります。
注: *証明付きのすべての MLE 方程式の詳細な導出は、この Web サイトで参照できます。 *
以下に Python を使用した MLE と分布フィッティングの例を見てみましょう。ここで、 scipy.stats.norm.fit最尤推定を使用して分布パラメーターを計算します。
from scipy . stats import norm # for generating sample data and fitting distributions
import matplotlib . pyplot as plt
plt . style . use ( 'seaborn' )
import numpy as np sample = Nonestats.norm.fit(data)を使用して、分布を上記のデータに適合させます。 param = None
#param[0], param[1]
# (0.08241224761452863, 1.002987490235812)x = np.linspace(-5,5,100)を使用して近似されたパラメータから PDF を計算します。 x = np . linspace ( - 5 , 5 , 100 )
# Generate the pdf from fitted parameters (fitted distribution)
fitted_pdf = None
# Generate the pdf without fitting (normal distribution non fitted)
normal_pdf = None # Your code here 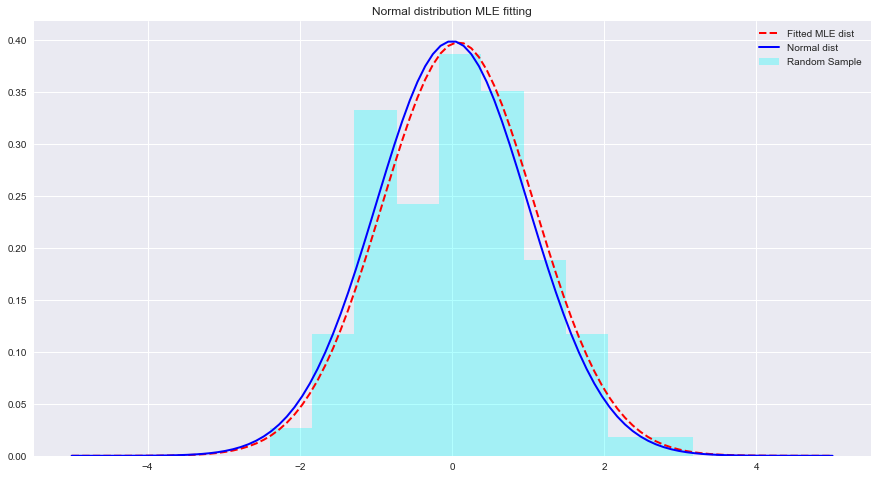
# Your comments/observations この短いラボでは、ガウスのコンテキスト、つまり基礎となる確率変数が正規分布している場合のベイジアン設定を調べました。 MLE は、期待される平均値の尤度を最大化することで、正規分布の未知のパラメーターを推定できることを学びました。期待される平均は、そのパラメーター空間内の非適合正規分布の平均に非常に近づきます。この理解を進めて、単純ベイズ分類器を使用してデータ分布に存在する多数のクラスの推定手段でそのような推定がどのように実行されるかを学習します。


