LLaMA LoRA Tuner
v0.0.20230421
低ランク適応 (LoRA) を使用した LLaMA モデルの評価と微調整が簡単になります。
アップデート:
devブランチには、新しいモデルをデモンストレーションするためのシンプルで簡単な方法として、新しいチャット UI と新しいデモ モード設定があります。ただし、新しいバージョンには微調整機能がまだなく、モデルのロード方法を定義する新しい方法と、(LangChain からの) プロンプト テンプレートの新しい形式が使用されているため、下位互換性もありません。
詳細については、#28 を参照してください。
LLM.チューナー.チャット.UI.in.デモ.モード.mp4
Hugging Face のデモを見る* UI のデモのみを提供します。トレーニングまたはテキスト生成を試すには、Colab 上で実行します。
ワンクリックで、標準の GPU ランタイムを備えた Google Colab で実行できます。
Google ドライブにデータをロードして保存します。
フォルダーまたは Hugging Face に保存されているさまざまな LLaMA LoRA モデルを評価します。 
decapoda-research/llama-7b-hf 、 nomic-ai/gpt4all-j 、 databricks/dolly-v2-7b 、 EleutherAI/gpt-j-6b 、またはEleutherAI/pythia-6.9bなどのベース モデルを切り替えます。
さまざまなプロンプト テンプレートとトレーニング データセット形式を使用して LLaMA モデルを微調整します。 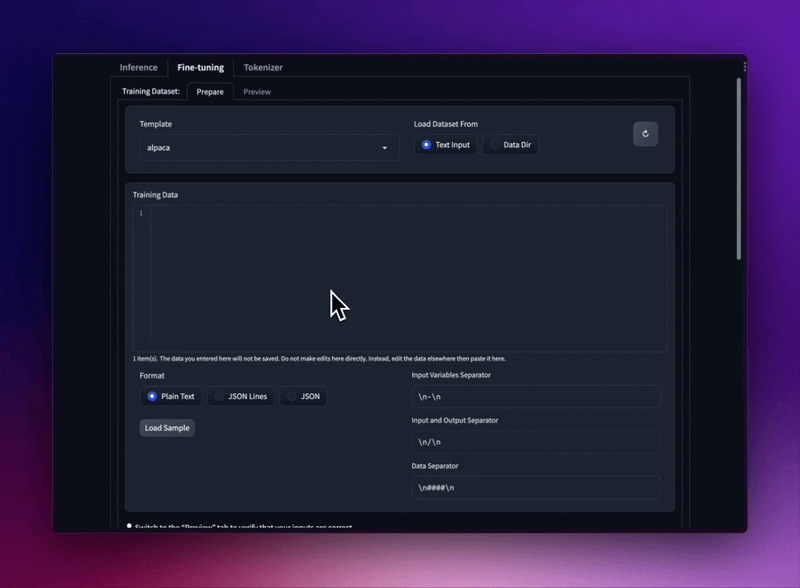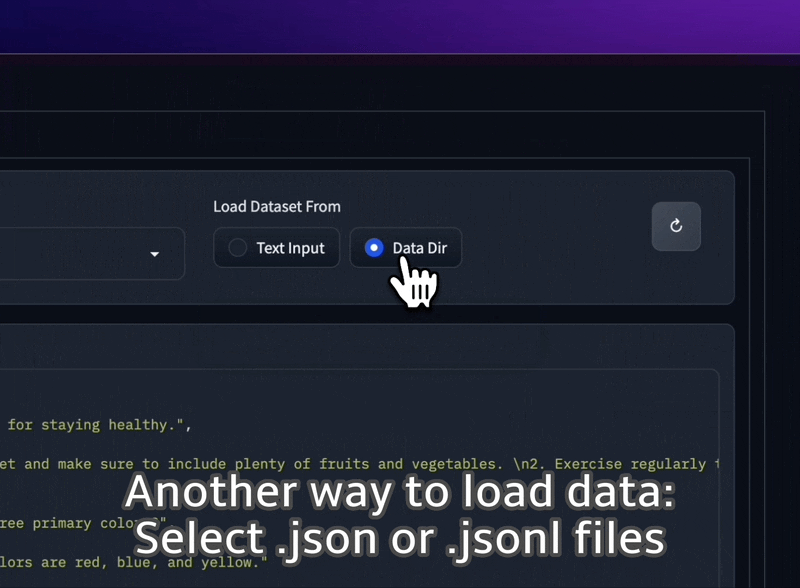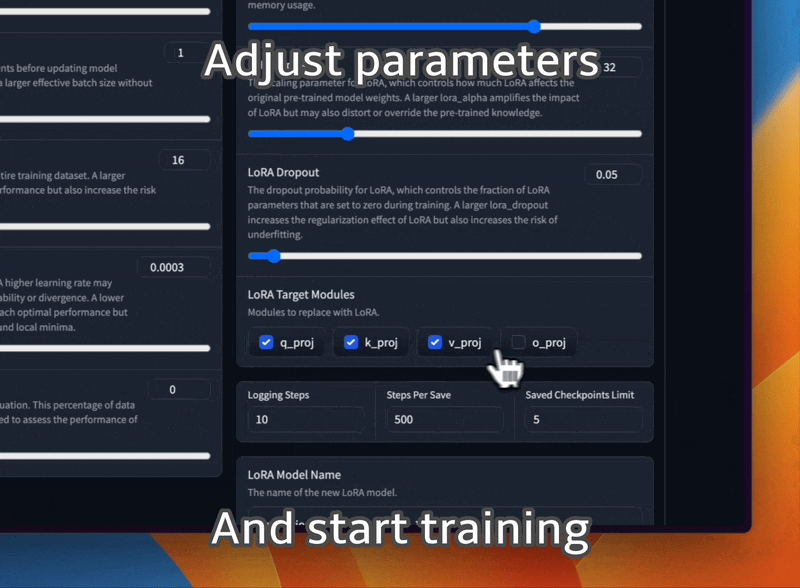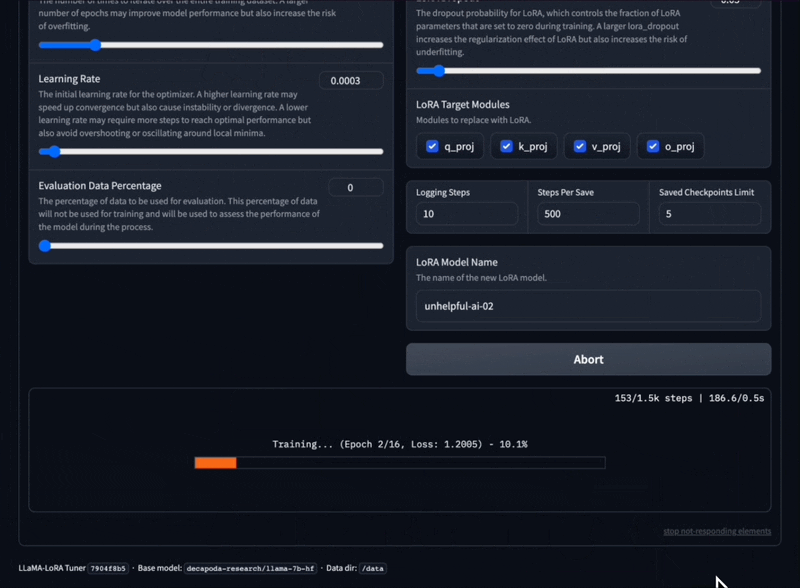
フォルダーから JSON および JSONL データセットをロードしたり、プレーン テキストを UI に直接貼り付けたりすることもできます。
Stanford Alpacaのseed_tasks、alpaca_data、OpenAIの「プロンプト」-「完了」形式をサポートします。
プロンプト テンプレートを使用して、データセットを DRY に保ちます。
このアプリを実行するにはさまざまな方法があります。
Google Colab で実行: 始める最も簡単な方法は、必要なのは Google アカウントだけです。標準 (無料) GPU ランタイムは、マイクロ バッチ サイズ 8 で生成とトレーニングを実行するのに十分です。ただし、テキストの生成とトレーニングは他のクラウド サービスよりもはるかに遅く、Colab は長時間のタスクの実行中に非アクティブな状態で実行を終了する可能性があります。
SkyPilot 経由でクラウド サービスで実行する: クラウド サービス (Lambda Labs、GCP、AWS、または Azure) アカウントをお持ちの場合は、SkyPilot を使用してクラウド サービスでアプリを実行できます。クラウド バケットをマウントしてデータを保存できます。
ローカルで実行: 使用しているハードウェアによって異なります。
詳しい手順についてはビデオをご覧ください。
この Colab ノートブックを開き、 [ランタイム] > [すべて実行] ( ⌘/Ctrl+F9 ) を選択します。
データの保存には Google ドライブが使用されるため、Google ドライブへのアクセスを承認するよう求められます。設定と詳細については、「構成」/「Google ドライブ」セクションを参照してください。
約 5 分間実行すると、「Launch」/「Start Gradio UI」セクションの出力にパブリック URL が表示されます ( Running on public URL: https://xxxx.gradio.live 」など)。ブラウザで URL を開いてアプリを使用します。
SkyPilot のインストール ガイドに従ってから、アプリを実行するタスクを定義する.yamlを作成します。
# llm-tuner.yamlresources:accelerators: A10:1 # 1x NVIDIA A10 GPU、Lambda クラウドで約 0.6 米ドル/時間。サポートされている GPU タイプについては「sky show-gpus」を実行し、GPU タイプの詳細情報については「sky show-gpus [GPU_NAME]」を実行します。
クラウド: ラムダ # オプション;省略した場合、SkyPilot は自動的に最も安価なcloud.file_mountsを選択します: # データ ディレクトリとして使用される既存のクラウド ストレージをマウントします。
# (トレーニング データセットとトレーニング済みモデルを保存するため)
# 詳細については、https://skypilot.readthedocs.io/en/latest/reference/storage.html を参照してください。
/data:name: llm-tuner-data # この名前が一意であるか、このバケットを所有していることを確認してください。存在しない場合、SkyPilot はこの名前でバケットの作成を試みます。store: s3 # [s3, gcs]mode のいずれかである可能性があります。MOUNT# LLaMA-LoRA Tuner リポジトリのクローンを作成し、その依存関係をインストールします。setup: | conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # LLaMA-LoRA Tuner リポジトリのクローンを作成し、その依存関係をインストールします [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo '依存関係をインストールしています...' pip install -r llm_tuner/requirements.lock.txt # オプション: wandb をインストールします重みとバイアスへのログ記録を有効にする pip install wandb # オプション: ビットサンドバイトをパッチして回避策エラー "libbitsandbytes_cpu.so: 未定義のシンボル: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'GPU サポート用にビットサンドバイトにパッチを適用しています...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo '依存関係がインストールされました。' # オプション: Cloudflare トンネルをインストールしてセットアップし、カスタム ドメイン名でアプリをインターネットに公開します [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Cloudflare のインストール" &&curl -L --output cloudflared.deb https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo Cloudflared サービスのアンインストール || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # オプション: 事前ダウンロード モデル echo "待つ必要がないように、基本モデルを事前にダウンロードしますアプリの準備ができたら、長い間...」 python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# アプリを起動します。 `hf_access_token`、`wandb_api_key`、および `wandb_project` はオプションです。 conda activate llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='Atlantic/Reykjavik' --base_model= 「十脚-リサーチ/ラマ-7b-hf」 --base_model_choices='decapoda-research/llama-7b-hf、nomic-ai/gpt4all-j、databricks/dolly-v2-7b' --share次に、クラスターを起動してタスクを実行します。
sky launch -c llm-tuner llm-tuner.yaml
-c ...クラスター名を指定するためのオプションのフラグです。指定しない場合、SkyPilot が自動的に生成します。
ターミナルにアプリのパブリック URL が表示されます。ブラウザで URL を開いてアプリを使用します。
sky launch終了するとログ ストリーミングが終了するだけで、タスクは停止されないことに注意してください。 sky queue --skip-finished使用して実行中または保留中のタスクのステータスを確認したり、 sky logs <cluster_name> <job_id>てログ ストリーミングに接続したり、 sky cancel <cluster_name> <job_id>てタスクを停止したりできます。
完了したら、 sky stop <cluster_name>を実行してクラスターを停止します。代わりにクラスターを終了するには、 sky down <cluster_name>を実行します。
予期せぬ料金が発生しないように、完了したら必ずクラスターを停止またはシャットダウンしてください。 sky cost-report実行して、クラスターのコストを確認します。
クラウド マシンにログインするには、 ssh <cluster_name> ssh llm-tunerなど) を実行します。
ローカル マシンにsshfsがインストールされている場合は、次のようなコマンドを実行して、クラウド マシンのファイル システムをローカル コンピュータにマウントできます。
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner conda で llm-tuner をアクティブ化します
pip install -rrequirements.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlantic/Reykjavik' --share
ターミナルにアプリのローカル URL とパブリック URL が表示されます。ブラウザで URL を開いてアプリを使用します。
その他のオプションについては、 python app.py --helpを参照してください。
言語モデルをロードせずに UI をテストするには、 --ui_dev_modeフラグを使用します。
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Gradio Auto-Reloading を使用するには、コマンド ライン引数がサポートされていないため、
config.yamlファイルが必要です。まずはサンプル ファイルcp config.yaml.sample config.yamlから始めます。次に、gradio app.py実行するだけです。
YouTube でビデオをご覧ください。
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
未定


