metal flash attention
v1.0.1
このリポジトリは、FlashAttendant の公式実装を Apple シリコンに移植します。これは、FlashAttendant アルゴリズムを再現する、最小限の保守可能なソース ファイルのセットです。
単一ヘッド アテンションのみ。さまざまなアテンション アルゴリズム (レジスタ圧力、並列処理) の中核となるボトルネックに焦点を当てます。基本的なアルゴリズムが正しく実行されていれば、ブロックのスパース性などのカスタマイズを追加するのは比較的簡単です。
すべては実行時に JIT コンパイルされます。これは、Xcode 14.2 に埋め込まれた実行可能ファイルに依存していた以前の実装とは対照的です。
バックワード パスは、Dao-AILab/flash-attention よりもメモリの使用量が少なくなります。公式実装では、アトミックと部分和にスクラッチ領域が割り当てられます。 Apple ハードウェアにはネイティブ FP32 アトミックがありません ( metal::atomic<float>がエミュレートされます)。ハードウェア サポートの欠如を回避しようとしているときに、FlashAttendant-2 後方カーネルの帯域幅と並列化のボトルネックが明らかになりました。代替のバックワード パスは、より高い計算コスト (5 GEMM ではなく 7 GEMM) で設計されました。アテンション行列の行次元と列次元の両方で 100% の並列化効率を達成します。最も重要なのは、コーディングと保守が容易になることです。
レジスタープレッシャーのボトルネックを克服するために、多くのクレイジーなことが行われました。大きなヘッド寸法 (例: 256) では、マトリックス ブロックのどれもレジスターに収まりません。アキュムレータでもできません。したがって、より最適化された方法で、意図的なレジスタ スピルが行われます。 3 番目のブロック次元がアテンション アルゴリズムに追加され、 Dに沿ってブロックされます。レジスタ スピルによる帯域幅コストを最小限に抑えるために、アテンション マトリックス ブロックのアスペクト比が大きく歪められました。たとえば、並列化次元では 16 ~ 32、横断次元では 80 ~ 128 です。 D次元を取り、どのオペランドがレジスタに収まるかを決定する大きなパラメータ ファイルがあります。次に、多くの競合するボトルネックのバランスをとるブロック サイズを割り当てます。
最終結果は、無限のシーケンス長と無限のヘッド寸法で、M1 Max (83% ALU 使用率) で一貫した 4400 ギガ命令/秒になります。混合精度に BF16 エミュレーションが使用されている場合 (Metal のbfloatは IEEE 準拠の丸め処理があり、ハードウェア BF16 のない古いチップでは大きなオーバーヘッドになります)。
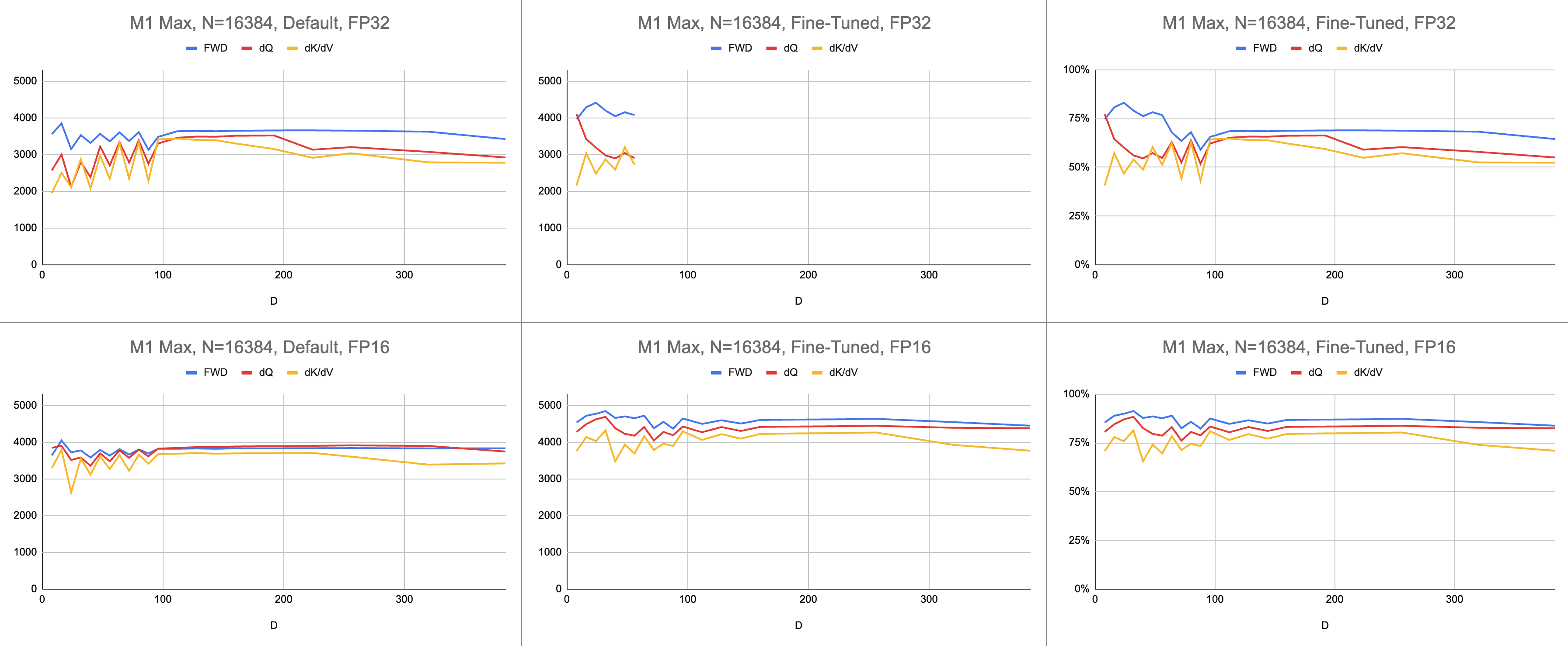
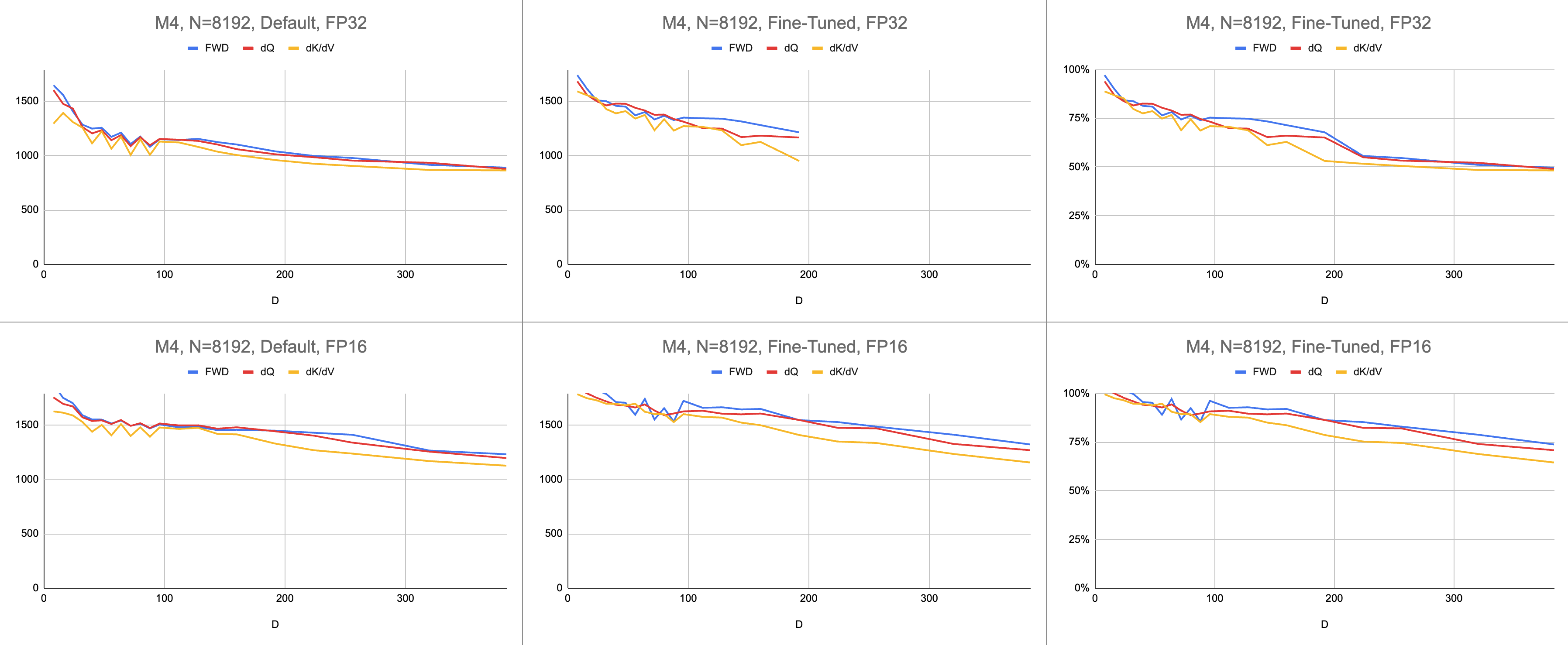
生データ: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
AI 分野では、パフォーマンスは 1 秒あたりのギガ浮動小数点演算 (GFLOPS) で報告されることがほとんどです。このメトリックは、すべての命令が GEMM で発生するという単純化されたパフォーマンス モデルを反映しています。ハードウェアが初期の FPU から最新のベクトル プロセッサに進歩するにつれて、最も一般的な浮動小数点演算が 1 つの命令に融合されました。融合乗算加算 (FMA)。 2 つの 100x100 行列を乗算すると、100 万の FMA 命令が発行されます。なぜこの FMA を 2 つの別個の命令として扱う必要があるのでしょうか?
この質問は、すべての浮動小数点演算が同じように作成されるわけではないことに注意する必要があります。他のほとんどの命令が FMA ユニットに送られることを前提として、ソフトマックス中のべき乗は 1 クロック サイクルで発生します。ソフトマックス中の乗算と加算の一部は、近くの加算または乗算と融合できません。これらを FMA と同じように扱い、ハードウェアが FMA を 2 倍遅く実行しているだけだとみなすべきでしょうか?私のシェーダーが ALU ハードウェアを効果的に使用しているかどうかを GEMM パフォーマンス モデルでどのように説明できるかは不明です。
シェーダーのパフォーマンスを理解するために、ギガフロップスの代わりにギガ命令を使用します。より直接的にアルゴリズムにマッピングされます。たとえば、1 つの GEMM はN^3 FMA 命令です。前方注意は 2 つの行列乗算、つまり2 * D * N^2 FMA 命令を実行します。バックワード アテンション (Dao-AILab/フラッシュ アテンション実装による) は5 * D * N^2 FMA 命令です。この表を Flash1、Flash2、または Flash3 の論文のルーフライン モデルと比較してみてください。
| 手術 | 仕事 |
|---|---|
| スクエアジェム | N^3 |
| 前方注意 | (2D + 5) * N^2 |
| 後ろ向きの素朴な注意 | 4D * N^2 |
| 後方フラッシュ注意 | (5D + 5) * N^2 |
| FF+BWDの組み合わせ | (7D + 10) * N^2 |
FP32 アトミックの複雑さのため、MFA はバックワード パスに異なるアプローチを使用しました。こちらの方が計算コストが高くなります。これは、バックワード パスを 2 つの別個のカーネルdQとdK/dVに分割します。ドロップダウンに疑似コードが表示されます。これを、Flash1、Flash2、または Flash3 論文のアルゴリズムのいずれかと比較してください。
| 手術 | 仕事 |
|---|---|
| フォワード | (2D + 5) * N^2 |
| 逆方向 dQ | (3D + 5) * N^2 |
| 逆方向 dK/dV | (4D + 5) * N^2 |
| FF+BWDの組み合わせ | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }パフォーマンスは、コンピューティング作業量を計算し、秒で割ることによって測定されます。最終結果は「1 秒あたりのギガ命令数」になります。次に、ルーフラインのモデルが必要です。以下の表は、GFLOPS の半分として計算された GINSTRS のルーフラインを示しています。 ALU 使用率は、(1 秒あたりの実際のギガ命令数) / (1 秒あたりの予想ギガ命令数) です。たとえば、M1 Max は通常、混合精度で 80% の ALU 使用率を達成します。
このモデルには限界があります。 M3世代ではヘッド寸法が小さいと故障します。異なるコンピューティング ユニットが同時に利用され、見かけ上の使用率が 100% を超える場合があります。ほとんどの場合、ベンチマークは、どの程度のパフォーマンスが残っているかについての正確なモデルを提供します。
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| ハードウェア | GFLOPS | ジンスターズ |
|---|---|---|
| M1 マックス | 10616 | 5308 |
| M4 | 3580 | 1790年 |
Metal ポートは公式 FlashAttend リポジトリとどの程度比較できますか? 「atomic dQ」アルゴリズムを使用して 100% のパフォーマンスを達成したと想像してください。次に、実際の MFA リポジトリに切り替えたところ、モデルのトレーニングが 4 倍遅いことがわかりました。これは、公式リポジトリのルーフラインの 25% に相当します。このパーセンテージを取得するには、3 つのカーネルすべての平均 ALU 使用率を7 / 9で乗算します。 Apple ハードウェアの統計には、より微妙なモデルが使用されましたが、これがその要点です。
Nvidia ハードウェアの使用率を計算するために、FP16/BF16 ALU に GFLOPS を使用しました。論文内の各グラフの最高 GFLOPS を 312000 (A100 SXM)、989000 (H100 SXM) で割りました。より大きなヘッド寸法とレジスタ集中型カーネル (逆方向パス) では、ベンチマークが報告されていないことに注意してください。私は、無限のヘッド寸法における見当圧力の問題を解決していないことを確認しました。たとえば、アキュムレータは常にレジスタに保持されます。これを書いている時点では、D=256 の後方勾配が正しい結果で実行されるという具体的な証拠はまだ見ていません。
| A100、フラッシュ2、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 192000 | 223000 | 0 |
| 後方へ | 170000 | 196000 | 0 |
| 進む + 戻る | 176000 | 203000 | 0 |
| H100、フラッシュ3、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 497000 | 648000 | 756000 |
| 後方へ | 474000 | 561000 | 0 |
| 進む + 戻る | 480000 | 585000 | 0 |
| H100、フラッシュ3、FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 613000 | 1008000 | 1171000 |
| 後方へ | 0 | 0 | 0 |
| 進む + 戻る | 0 | 0 | 0 |
| A100、フラッシュ2、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 62% | 71% | 0% |
| 進む + 戻る | 56% | 65% | 0% |
| H100、フラッシュ3、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 50% | 66% | 76% |
| 進む + 戻る | 48% | 59% | 0% |
| M1 アーキテクチャ、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 86% | 85% | 86% |
| 進む + 戻る | 62% | 63% | 64% |
| M3 アーキテクチャ、FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| フォワード | 94% | 91% | 82% |
| 進む + 戻る | 71% | 69% | 61% |
| 2020年に製造されたハードウェア | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| M1—M2 アーキテクチャ | 62% | 63% | 64% |
| 2023 年に製造されたハードウェア | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (FP8 GFLOPS を使用) | 24% | 30% | 0% |
| H100 (FP16 GFLOPS を使用) | 48% | 59% | 0% |
| M3—M4 アーキテクチャ | 71% | 69% | 61% |
Apple ハードウェアは、より多くの計算を発行しているにもかかわらず、同じ作業を行う Nvidia ハードウェアよりも速くトランスフォーマーをトレーニングしています。異なる GPU 間のサイズの違いを正規化します。 GPU がいかに効率的に利用されるかにのみ焦点を当てます。
おそらくメイン リポジトリは、FP32 アトミックを回避し、レジスタが GPU コアに収まらない場合に意図的にレジスタをスピルするアルゴリズムを試行する必要があります。考えられる問題サイズの小さなサブセットに対するサポートがハードコーディングされているため、これは起こりそうにありません。その動機は、 Dが 2 の累乗で 128 未満である最も一般的なモデルをサポートしているようです。それ以外の場合、ユーザーは代替フォールバック実装 (MFA リポジトリなど) に依存する必要があり、これは完全に異なる基盤を使用する可能性があります。アルゴリズム。
macOS では、Swift パッケージをダウンロードし、 -Xswiftc -Ouncheckedでコンパイルします。このコンパイラ オプションは、パフォーマンス重視の CPU コードに必要です。リリース モードは、変更が 1 つあるたびにコードベース全体を最初から再コンパイルする必要があるため、使用できません。 Finder で Git リポジトリに移動し、 Package.swiftダブルクリックします。 Xcode ウィンドウがポップアップするはずです。左側にはファイルの階層があるはずです。階層を解明できない場合は、何か問題が発生しています。
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
または、SwiftUI テンプレートを使用して新しい Xcode プロジェクトを作成します。 "Hello, world!"オーバーライドします。 String返す関数の呼び出しを含む string 。この関数は、選択したスクリプトを実行してからexit(0)を呼び出すため、画面に何かをレンダリングする前にアプリがクラッシュします。 Xcode コンソールの出力をコードに関するフィードバックとして使用します。このワークフローは、macOS と iOS の両方と互換性があります。
[プロジェクト] > プロジェクトの名前 > [ビルド設定] > [Swift コンパイラー - コード生成] > [最適化レベル]から-Xswiftc -Ouncheckedオプションを追加します。表の 2 番目の列には、プロジェクトの名前がリストされます。ドロップダウンで「その他」をクリックし、表示されるパネルに-Ouncheckedと入力します。次に、このリポジトリを Swift パッケージの依存関係として追加します。 Tests/FlashAttentionの下にあるいくつかのテストを確認してください。これらのテストのいずれかの生のソース コードをプロジェクトにコピーします。前の段落の関数からテストを呼び出します。コンソールに何が表示されるかを調べます。
Metal コードの生成を変更するには (マルチヘッドまたはマスクのサポートを追加するなど)、生の Swift コードを Xcode プロジェクトにコピーします。別のフォルダーでgit clone使用するか、GitHub 上の RAW ファイルを ZIP としてダウンロードします。 metal-flash-attentionのフォークにリンクして、変更をクラウドに自動保存する方法もありますが、これは設定がより困難です。前の段落から Swift パッケージの依存関係を削除します。選択したテストを再実行します。コンパイルしてコンソールに何か表示しますか?
次のいずれかのフォルダーで、複数行の文字列リテラルの 1 つを見つけます。
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
そのうちの 1 つにランダムなテキストを追加します。プロジェクトを再度コンパイルして実行します。何かがひどく間違っているはずです。たとえば、Metal コンパイラはエラーをスローする場合があります。これが起こらない場合は、別の場所に別のコード行を書き換えてみてください。それでもテストに合格した場合、Xcode は変更を登録していません。
ブロックのスパース性などのコーディングを進めます。コードがまったく動作するかどうか、高速に動作するかどうか、あらゆる問題サイズで高速に動作するかどうかに関するフィードバックを取得します。生のソース コードをアプリに統合するか、別のプログラミング言語に翻訳します。


