FLASH pytorch
0.1.9
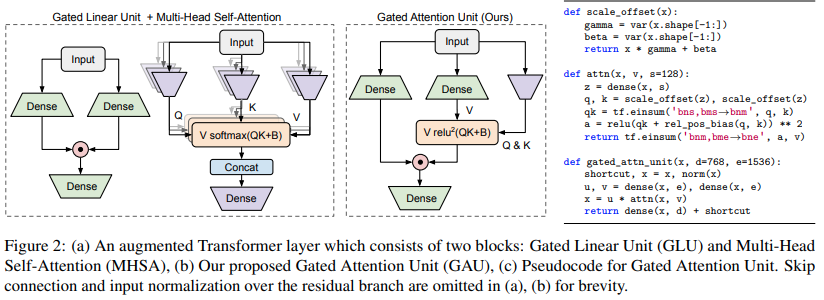
論文「線形時間におけるトランスの品質」で提案されているトランスのバリアントの実装
$ pip install FLASH-pytorchこの論文の主要な新しい回路は「ゲート アテンション ユニット」で、これは複数のヘッドによるアテンションを 1 つのヘッドに削減しながら置き換えることができると彼らは主張しています。
これは、Softmax の代わりに Relu 二乗アクティベーションを使用します。そのアクティベーションは、Primer 論文で最初に確認され、ReLA Transformer での ReLU の使用が示されています。ゲート スタイルは主に gMLP からインスピレーションを得ているようです。
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512)次に著者らは、シーケンスのグループ化を使用してGAUとカタロプロスの線形注意を組み合わせ、自己回帰線形注意に関する既知の問題を克服します。
彼らは、二次的なゲート型注意ユニットとグループ化された線形注意を組み合わせたものを FLASH と名付けました。
これも非常に簡単に使用できます
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)最後に、論文で説明されているように、完全な FLASH トランスを使用できます。これには、論文で言及されているすべての位置埋め込みが含まれています。絶対位置埋め込みでは、スケーリングされた正弦波を使用します。 GAU 二次注意は、片頭の T5 相対位置バイアスを取得します。これらすべてに加えて、GAU アテンションとリニア アテンションの両方がロータリー エンベデッド (RoPE) になります。
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

