Apache Kylin 분석 데이터 웨어하우스 v4.0.3 공식 버전
4.0.3
Apache Kylin: 매우 큰 규모의 데이터를 위한 1초 미만의 쿼리 도구
다운코드 편집기
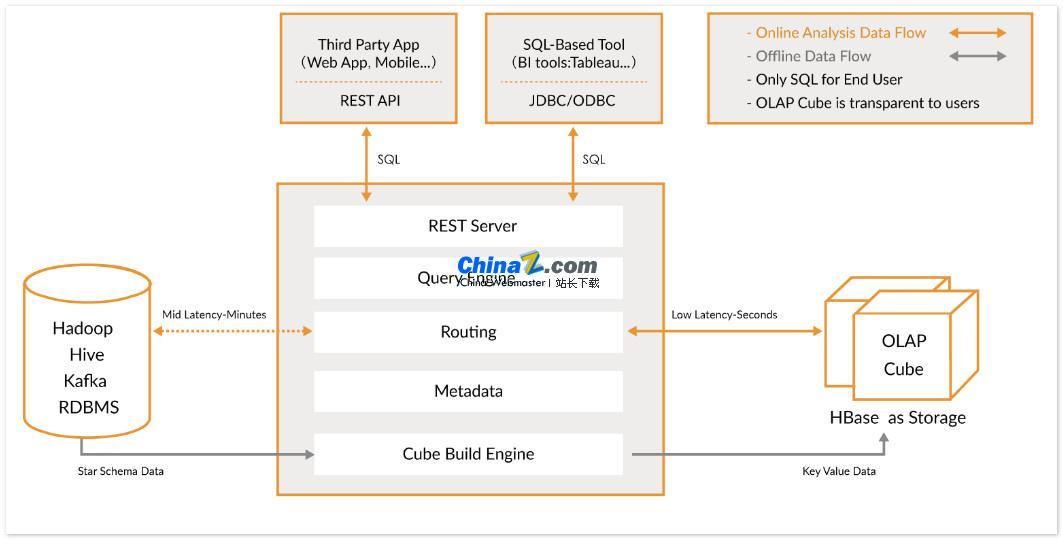
Apache Kylin은 Hadoop/Spark를 기반으로 SQL 쿼리 인터페이스 및 다차원 분석(OLAP) 기능을 제공하고 초대형 데이터를 효율적으로 처리할 수 있는 오픈 소스 분산 분석 데이터 웨어하우스입니다. 원래 eBay에서 개발하고 오픈 소스 커뮤니티에 기여한 이 솔루션은 대용량 데이터에 대한 쿼리를 몇 초 안에 완료합니다.
Kylin의 세 가지 주요 단계
Kylin을 사용하면 사용자는 단 3단계만으로 매우 큰 데이터 세트에 대해 1초 미만의 쿼리를 구현할 수 있습니다.
1. 데이터 세트에 별 또는 눈송이 모델을 정의합니다. 먼저 데이터 세트를 설명하기 위해 별 또는 눈송이 모델을 정의해야 합니다. 이는 Kylin이 데이터 간의 관계를 이해하고 쿼리 성능을 최적화하는 데 도움이 됩니다.
2. 큐브 구축: 정의된 데이터 테이블에 큐브를 구축합니다. 큐브는 Kylin이 데이터를 미리 계산하고 저장하는 단위로, 쿼리 속도를 크게 향상시킬 수 있습니다.
3. 표준 SQL 쿼리 사용: 표준 SQL 구문을 사용하여 ODBC, JDBC 또는 RESTFUL API를 통해 Cube를 쿼리하면 Kylin은 몇 초 안에 쿼리 결과를 반환할 수 있습니다.
Kylin의 통합 기능
Kylin은 Tableau, Power BI 등과 같은 다양한 데이터 시각화 도구와 통합됩니다. 사용자는 이러한 BI 도구를 사용하여 Hadoop 데이터를 분석하고 데이터 통찰력을 시각적으로 표시할 수 있습니다.
요약
Apache Kylin은 사용자가 매우 큰 규모의 데이터에 대한 쿼리를 몇 초 안에 완료할 수 있도록 도와주는 강력한 도구입니다. 사용 편의성, 확장성 및 효율성으로 인해 대규모 데이터 분석을 처리하는 데 이상적입니다.