프로젝트 페이지 | 종이 | 모델 카드?
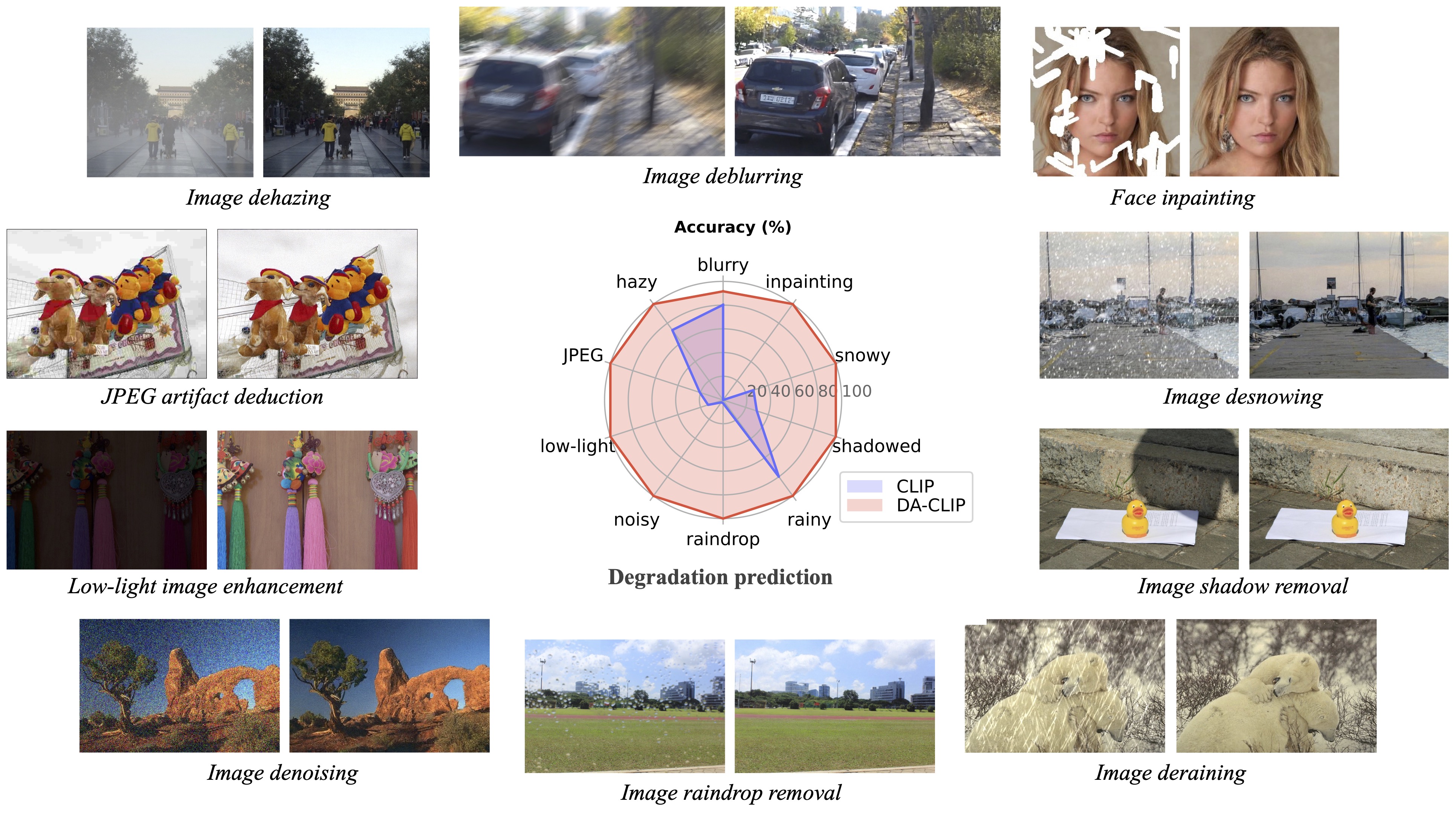
후속 작업인 CVPRW 2024(Controlled Vision-Language Models를 사용한 야생에서의 Photo-Realistic Image Restoration in the Wild)는 더 나은 이미지 생성을 위한 후방 샘플링을 제시하고 Real-ESRGAN과 유사한 실제 혼합 열화 이미지를 처리합니다.
[ 2024.04.16 ] 후속 논문 "Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models"가 현재 ArXiv에 게재되었습니다!
[ 2024.04.15 ] 더 나은 이미지 생성을 위해 실제 열화 및 후방 샘플링을 위한 야생 IR 모델을 업데이트했습니다. 사전 훈련된 가중치 wild-ir.pth 및 wild-daclip_ViT-L-14.pt도 wild-ir에 제공됩니다.
[ 2024.01.20 ] ??? 우리의 DA-CLIP 논문은 ICLR 2024에서 승인되었습니다 ??? 우리는 모델 카드에서 더욱 강력한 모델을 제공합니다.
[ 2023.10.25 ] 학습 및 테스트용 데이터 세트 링크를 추가했습니다.
[ 2023.10.13 ] Replicate 데모 및 API를 추가했습니다. @chenxwh 감사합니다!!! Hugging Face 데모와 온라인 Colab 데모를 업데이트했습니다. @fffiloni와 @camenduru에게 감사드립니다 !!! Hugging Face ?에서 모델 카드도 만들었어요. 테스트를 위해 더 많은 예제를 제공했습니다.
[ 2023.10.09 ] DA-CLIP과 Universal IR 모델의 사전 학습된 가중치가 각각 link1과 link2에 공개되었습니다. 또한, 자신이 만든 이미지를 테스트하고 싶은 경우를 위해 Gradio 앱 파일도 제공하고 있습니다.
OS: 우분투 20.04
엔비디아:
쿠다: 11.4
파이썬 3.8
먼저 다음을 사용하여 가상 환경을 만드는 것이 좋습니다.
python3 -m venv .envsource .env/bin/activate pip 설치 -U pip pip 설치 -r 요구사항.txt
universal-image-restoration 디렉토리로 들어가서 다음을 실행하십시오.
import torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')이미지 = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['motion-blurry','hazy','jpeg-compressed','low-light','noisy','raindrop' ,'rainy','shadowed','snowy','uncompleted']text = torch.no_grad()를 사용한 토크나이저(저하), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"작업: {task_name}: {degradations[index]} - {text_probs[0 ][색인]}")데이터 세트 구성 섹션에 따라 학습 및 테스트 데이터 세트를 다음과 같이 준비합니다.
#### 교육 데이터세트용 ########(미완료는 인페인팅을 의미함) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--hazy|--jpeg-압축|--저조도|--noisy|--raindrop|--rainy|--shadowed|--snowy|--uncompleted## ## 데이터세트 테스트용 ########(기차와 동일한 구조) ####datasets/universal/val ...#### 깨끗한 캡션용 ####datasets/universal/daclip_train.csv 데이터 세트/universal/daclip_val.csv
그런 다음 universal-image-restoration/config/daclip-sde 디렉터리로 이동하여 options/train.yml 및 options/test.yml 에 있는 옵션 파일의 데이터 세트 경로를 수정합니다.
train 및 val 디렉터리 모두에 더 많은 작업이나 데이터세트를 추가하고 distortion 에 성능 저하 단어를 추가할 수 있습니다.
| 하락 | 모션 블러 | 흐릿한 | JPEG 압축* | 저조도 | 시끄러운* (jpeg와 동일) |
|---|---|---|---|---|---|
| 데이터 세트 | 고프로 | 레지던스-6k | DIV2K+Flickr2K | ㅋㅋㅋ | DIV2K+Flickr2K |
| 하락 | 빗방울 | 비오는 | 그림자가 있는 | 눈 내리는 | 미완성 |
|---|---|---|---|---|---|
| 데이터 세트 | 빗방울 | Rain100H: 훈련, 테스트 | SRD | 눈10만 | 셀레바HQ-256 |
훈련용 열차 데이터세트만 추출 해야 하며 모든 검증 데이터세트는 Google 드라이브에서 다운로드할 수 있습니다. JPEG 및 시끄러운 데이터세트의 경우 이 스크립트를 사용하여 LQ 이미지를 생성할 수 있습니다.
자세한 내용은 DA-CLIP.md를 참조하세요.
훈련을 위한 주요 코드는 universal-image-restoration/config/daclip-sde 에 있고 DA-CLIP의 핵심 네트워크는 universal-image-restoration/open_clip/daclip_model.py 에 있습니다.
사전 학습된 DA-CLIP 가중치를 pretrained 디렉터리에 넣고 daclip 경로를 확인합니다.
그런 다음 아래 bash 스크립트에 따라 모델을 훈련할 수 있습니다.
cd universal-image-restoration/config/daclip-sde# 단일 GPU의 경우:python3 train.py -opt=options/train.yml# 분산 교육의 경우 filepython3 -m torch.distributed.launch 옵션에서 gpu_ids를 변경해야 합니다. -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
모델과 훈련 로그는 log/universal-ir 에 저장됩니다. tail -f log/universal-ir/train_universal-ir_***.log -n 100 실행하여 해당 시점에 로그를 인쇄할 수 있습니다.
야생(wild-ir)에서의 이미지 복원에도 동일한 훈련 단계를 사용할 수 있습니다.
| 모델명 | 설명 | 구글드라이브 | 포옹얼굴 |
|---|---|---|---|
| 다클립 | 열화 인식 CLIP 모델 | 다운로드 | 다운로드 |
| 범용-IR | DA-CLIP 기반 범용 영상 복원 모델 | 다운로드 | 다운로드 |
| DA-CLIP-믹스 | 저하 인식 CLIP 모델(가우시안 블러 + 면 인페인팅 및 가우시안 블러 + Rainy 추가) | 다운로드 | 다운로드 |
| 범용-IR-믹스 | DA-CLIP 기반 범용 이미지 복원 모델(강력한 훈련 및 혼합 저하 추가) | 다운로드 | 다운로드 |
| 와일드다클립 | 실제 성능 저하 인식 CLIP 모델(ViT-L-14) | 다운로드 | 다운로드 |
| 야생 IR | DA-CLIP 기반의 실제 영상 복원 모델 | 다운로드 | 다운로드 |
이미지 복원 방법을 평가하려면 벤치마크 경로와 모델 경로를 수정하고 실행하십시오.
CD 범용-이미지-복원/config/universal-ir 파이썬 test.py -opt=options/test.yml
여기서는 자신의 이미지를 테스트하기 위한 app.py 파일을 제공합니다. 그 전에 사전 훈련된 가중치(DA-CLIP 및 UIR)를 다운로드하고 options/test.yml 에서 모델 경로를 수정해야 합니다. 그런 다음 python app.py 실행하면 http://localhost:7860 열어 모델을 테스트할 수 있습니다. (우리는 또한 images 디렉토리에서 품질 저하가 다른 여러 이미지를 제공합니다). 또한 Google 드라이브의 테스트 데이터 세트에서 더 많은 예를 제공합니다.
야생(wild-ir)에서의 이미지 복원에도 동일한 단계를 사용할 수 있습니다.
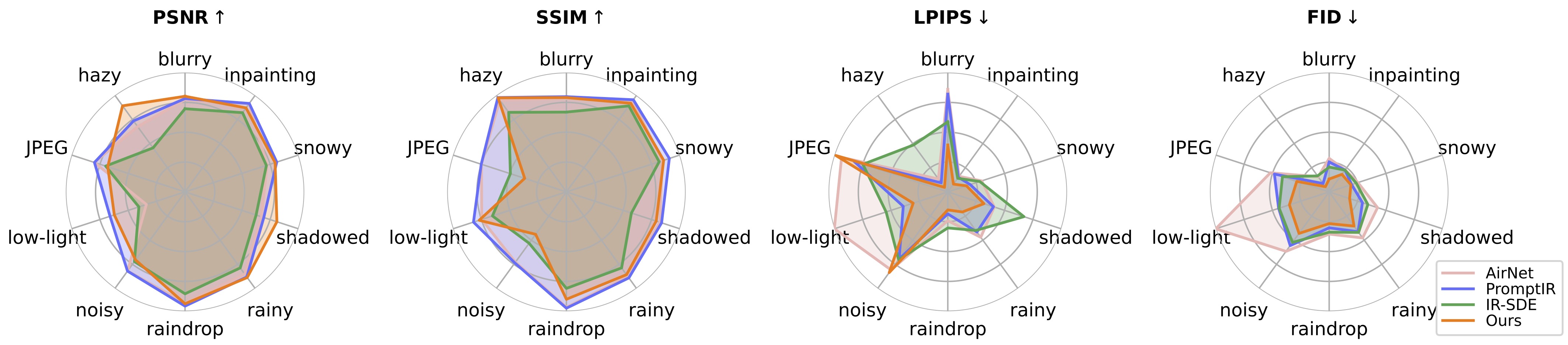



? 테스트에서 우리는 현재의 사전 훈련된 모델이 훈련 데이터 세트(다른 장치에서 캡처했거나 다른 해상도 또는 성능 저하로 캡처한)로 분포 변화가 있을 수 있는 일부 실제 이미지를 처리하기가 여전히 어렵다는 것을 발견했습니다. 우리는 이를 향후 작업으로 간주하고 모델을 더욱 실용적으로 만들기 위해 노력할 것입니다! 또한 우리 작업에 관심이 있는 사용자가 더 큰 데이터 세트와 더 많은 저하 유형을 사용하여 자신의 모델을 교육하도록 권장합니다.
? 그런데 우리는 또한 입력 이미지의 크기를 직접 조정하면 대부분의 작업에서 성능이 저하된다는 사실도 발견했습니다 . 훈련에 크기 조정 단계를 추가하려고 시도할 수 있지만 보간으로 인해 항상 이미지 품질이 손상됩니다.
? 인페인팅 작업의 경우 현재 모델은 데이터 세트 제한으로 인해 얼굴 인페인팅만 지원합니다. 우리는 마스크 예제를 제공하며 generate_masked_face 스크립트를 사용하여 완성되지 않은 얼굴을 생성할 수 있습니다.
감사의 말: 당사의 DA-CLIP은 IR-SDE 및 open_clip을 기반으로 합니다. 코드를 보내주셔서 감사합니다!
질문이 있으시면 [email protected]로 문의해 주세요.
우리 코드가 귀하의 연구나 작업에 도움이 된다면, 우리 논문을 인용하는 것을 고려해 보십시오. 다음은 BibTeX 참고자료입니다:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

