모든 다중 모드 기반 모델을 교육하기 위한 프레임워크입니다.
확장 가능. 오픈 소스. 수십 가지 양식과 작업에 걸쳐 있습니다.
EPFL-애플
Website | BibTeX | ? Demo
다음에 대한 공식 구현 및 사전 훈련된 모델:
4M: 대규모 다중 모드 마스크 모델링 , NeurIPS 2023(스포트라이트)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21: 수십 가지 작업 및 양식을 위한 Any-to-Any 비전 모델 , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
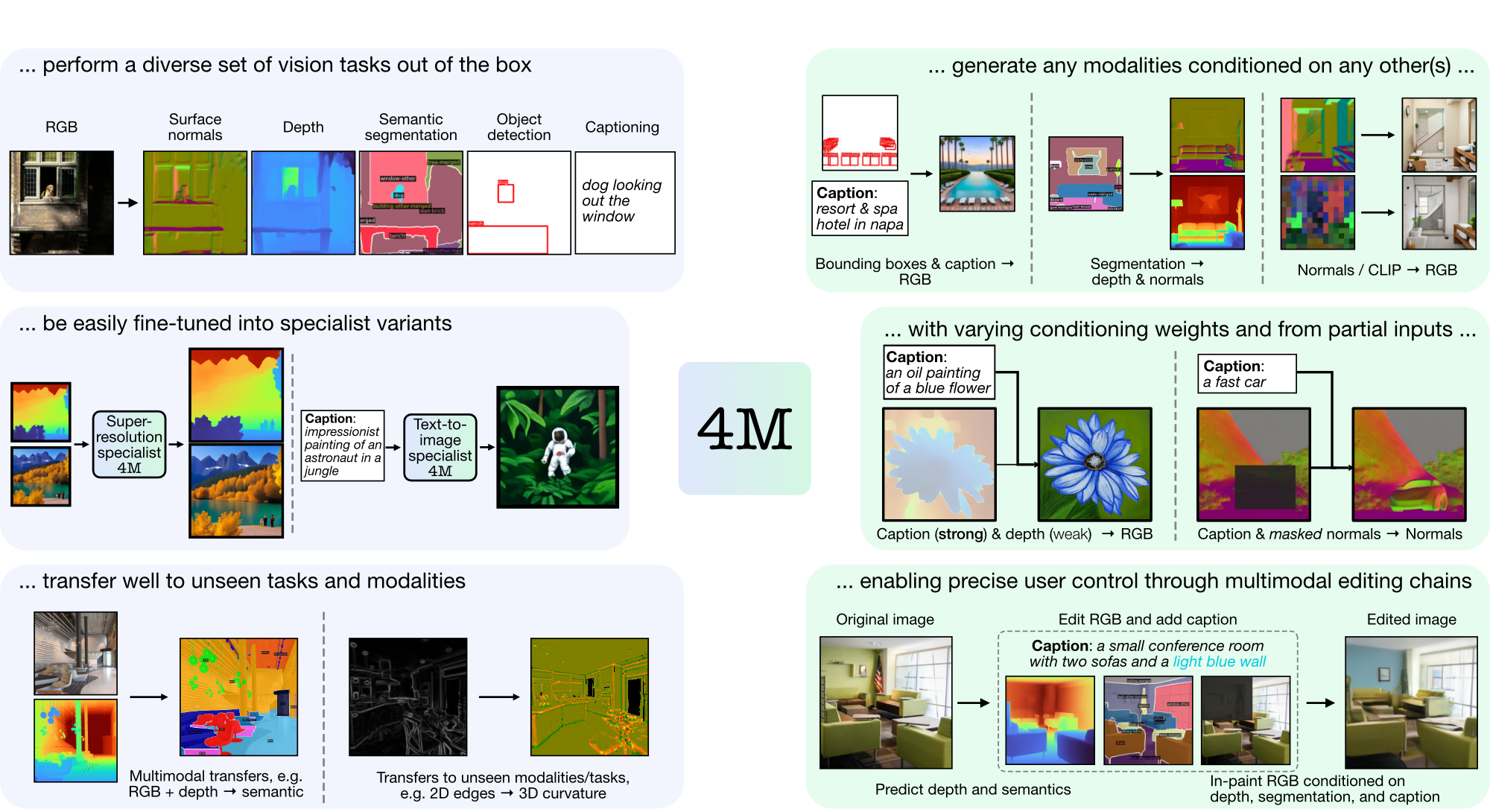
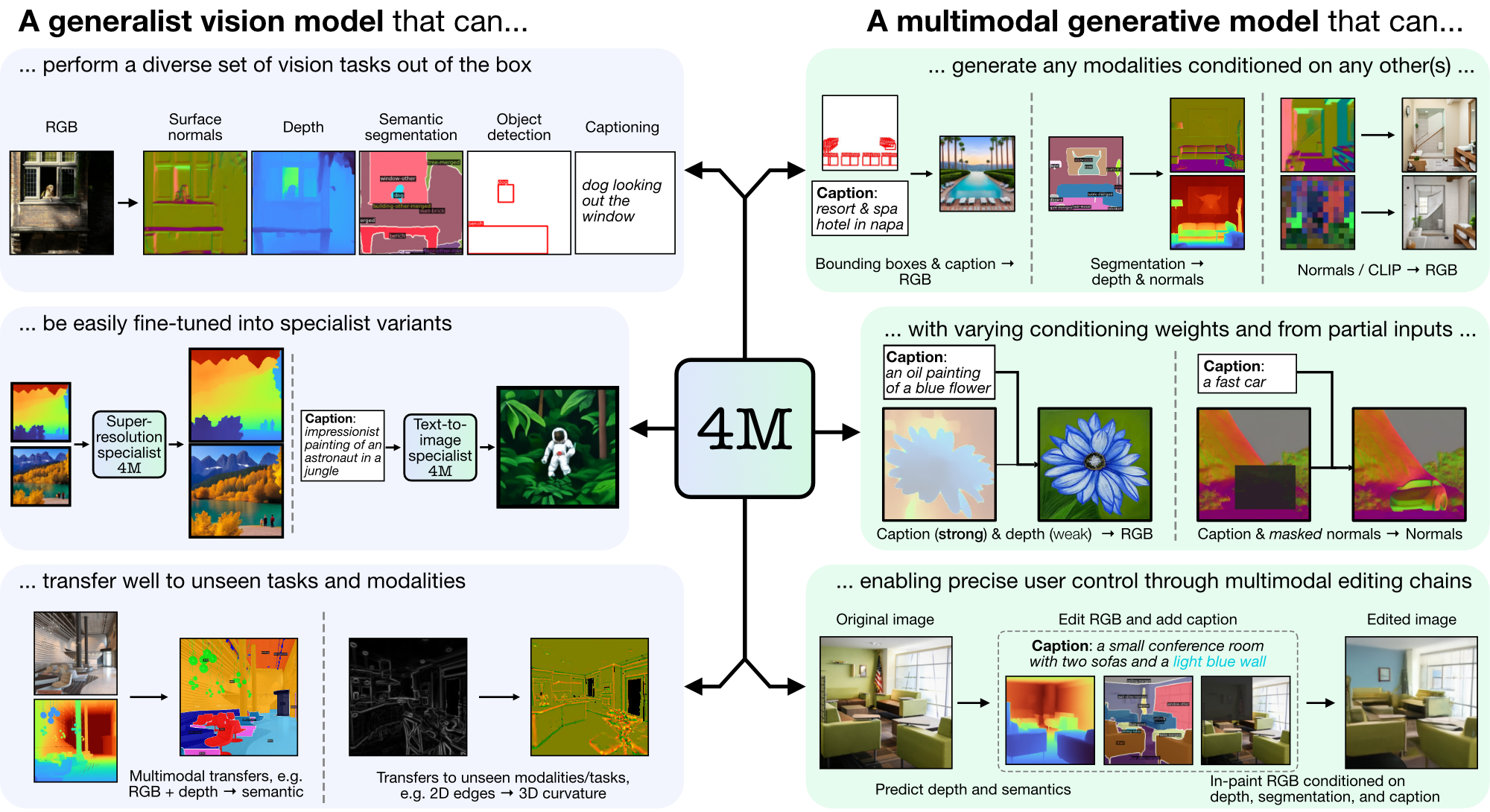
4M은 토큰화 및 마스킹을 사용하여 다양한 양식으로 확장하는 "모든 대 모든" 기반 모델을 교육하기 위한 프레임워크입니다. 4M을 사용하여 훈련된 모델은 광범위한 비전 작업을 수행하고, 보이지 않는 작업 및 양식으로 잘 전환할 수 있으며, 유연하고 조종 가능한 다중 모드 생성 모델입니다. 우리는 "4M: Massively Multimodal Masked Modeling"(여기에서는 4M-7로 표시)에 대한 코드와 모델을 출시하고 있으며, "4M-21: 수십 가지 작업 및 양식을 위한 Any-to-Any 비전 모델"(여기에서는 4M으로 표시)을 출시하고 있습니다. -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
CUDA를 사용할 수 없는 경우 공식 설치 지침에 따라 PyTorch를 다시 설치하는 것이 좋습니다. 마찬가지로, xFormers(더 빠른 토크나이저를 위한 선택 사항)를 설치하려면 해당 README를 따라 CUDA 버전이 올바른지 확인하세요.
우리는 RGB-to-all 또는 {캡션, 경계 상자}-to-all 생성 작업을 위한 4M 모델 사용을 빠르게 시작할 수 있도록 데모 래퍼를 제공합니다. 예를 들어, 주어진 RGB 입력에서 모든 양식을 생성하려면 다음을 호출하십시오.
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )다음과 같은 출력이 표시될 것으로 예상됩니다.


전체 캡션 생성을 수행하려면 샘플러 입력을 다음과 같이 바꿀 수 있습니다. preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . 사용 가능한 4M 모델 목록을 보려면 아래 모델 동물원을 참조하고, 생성에 대한 자세한 지침은 README_GENERATION.md를 참조하세요.
정렬된 다중 모드 데이터 세트를 준비하는 방법에 대한 지침은 README_DATA.md를 참조하세요.
양식별 토크나이저를 훈련하는 방법에 대한 지침은 README_TOKENIZATION.md를 참조하세요.
4M 모델을 훈련하는 방법에 대한 지침은 README_TRAINING.md를 참조하세요.
추론/생성을 위해 4M 모델을 사용하는 방법에 대한 지침은 README_GENERATION.md를 참조하세요. 또한 조건부 이미지 생성 및 일반적인 비전 작업(예: RGB-to-All)을 수행하는 4M 추론에 대한 예제가 포함된 생성 노트북도 제공합니다.
우리는 4M 및 토크나이저 체크포인트를 세이프텐서로 제공하고 Hugging Face Hub를 통해 손쉬운 로딩도 제공합니다.
| 모델 | # 모드. | 데이터 세트 | # 매개변수 | 구성 | 가중치 |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | 구성 | 체크포인트 / HF 허브 |
| 4M-B | 7 | COYO700M | 198M | 구성 | 체크포인트 / HF 허브 |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | 구성 | 체크포인트 / HF 허브 |
| 4M-L | 7 | CC12M | 705M | 구성 | 체크포인트 / HF 허브 |
| 4M-L | 7 | COYO700M | 705M | 구성 | 체크포인트 / HF 허브 |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | 구성 | 체크포인트 / HF 허브 |
| 4M-XL | 7 | CC12M | 2.8B | 구성 | 체크포인트 / HF 허브 |
| 4M-XL | 7 | COYO700M | 2.8B | 구성 | 체크포인트 / HF 허브 |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2.8B | 구성 | 체크포인트 / HF 허브 |
Hugging Face Hub에서 모델을 로드하려면:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )체크포인트를 수동으로 로드하려면 먼저 위 링크에서 safetensors 파일을 다운로드하고 다음을 호출하세요.
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )이러한 모델은 표준 4M-7 CC12M 모델로 초기화되었지만 텍스트 입력에 크게 편향된 양식 혼합을 사용하여 계속해서 훈련했습니다. 여전히 다른 모든 작업을 수행할 수 있지만 미세 조정되지 않은 모델에 비해 텍스트-이미지 생성 성능이 더 좋습니다.
| 모델 | # 모드. | 데이터 세트 | # 매개변수 | 구성 | 가중치 |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | 구성 | 체크포인트 / HF 허브 |
| 4M-T2I-L | 7 | CC12M | 705M | 구성 | 체크포인트 / HF 허브 |
| 4M-T2I-XL | 7 | CC12M | 2.8B | 구성 | 체크포인트 / HF 허브 |
Hugging Face Hub에서 모델을 로드하려면:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )체크포인트에서 수동으로 로드하는 것은 기본 4M 모델의 경우와 동일한 방식으로 수행됩니다.
| 모델 | # 모드. | 데이터 세트 | # 매개변수 | 구성 | 가중치 |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | 구성 | 체크포인트 / HF 허브 |
Hugging Face Hub에서 모델을 로드하려면:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )체크포인트에서 수동으로 로드하는 것은 기본 4M 모델의 경우와 동일한 방식으로 수행됩니다.
| 양식 | 해결 | 토큰 수 | 코드북 크기 | 확산 디코더 | 가중치 |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16,000 | ✓ | 체크포인트 / HF 허브 |
| 깊이 | 224-448 | 196-784 | 8천 | ✓ | 체크포인트 / HF 허브 |
| 법선 | 224-448 | 196-784 | 8천 | ✓ | 체크포인트 / HF 허브 |
| 엣지(캐니, SAM) | 224-512 | 196-1024 | 8천 | ✓ | 체크포인트 / HF 허브 |
| COCO 의미론적 세분화 | 224-448 | 196-784 | 4K | ✗ | 체크포인트 / HF 허브 |
| 클립-B/16 | 224-448 | 196-784 | 8천 | ✗ | 체크포인트 / HF 허브 |
| DINOV2-B/14 | 224-448 | 256-1024 | 8천 | ✗ | 체크포인트 / HF 허브 |
| DINOv2-B/14(글로벌) | 224 | 16 | 8천 | ✗ | 체크포인트 / HF 허브 |
| 이미지바인드-H/14 | 224-448 | 256-1024 | 8천 | ✗ | 체크포인트 / HF 허브 |
| ImageBind-H/14(글로벌) | 224 | 16 | 8천 | ✗ | 체크포인트 / HF 허브 |
| SAM 인스턴스 | - | 64 | 1천 | ✗ | 체크포인트 / HF 허브 |
| 3D 인간 포즈 | - | 8 | 1천 | ✗ | 체크포인트 / HF 허브 |
Hugging Face Hub에서 모델을 로드하려면:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )체크포인트를 수동으로 로드하려면 먼저 위 링크에서 safetensors 파일을 다운로드하고 다음을 호출하세요.
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )이 저장소의 코드는 LICENSE 파일에 있는 Apache 2.0 라이센스에 따라 릴리스됩니다.
이 저장소의 모델 가중치는 LICENSE_WEIGHTS 파일에 있는 샘플 코드 라이센스에 따라 릴리스됩니다.
이 저장소가 도움이 된다면 우리 작업을 인용해 보세요.
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


