system design 101
1.0.0
【 ?? 유튜브 | ? 뉴스레터 】
시각적이고 간단한 용어를 사용하여 복잡한 시스템을 설명합니다.
시스템 설계 인터뷰를 준비 중이거나 단순히 시스템이 표면 아래에서 어떻게 작동하는지 이해하고 싶은 경우, 이 저장소가 이를 달성하는 데 도움이 되기를 바랍니다.
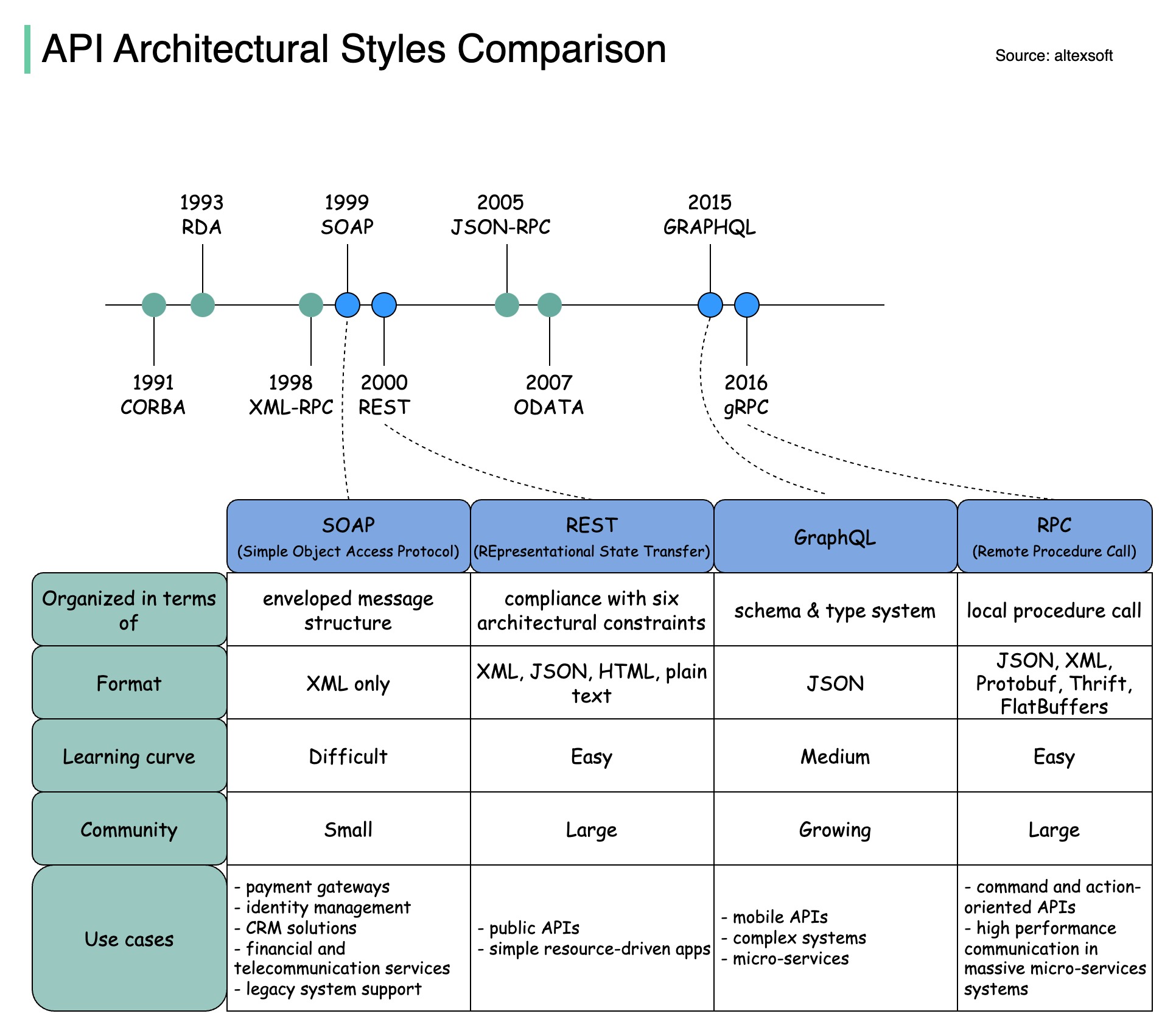
아키텍처 스타일은 API(응용 프로그래밍 인터페이스)의 다양한 구성 요소가 서로 상호 작용하는 방식을 정의합니다. 결과적으로 API 설계 및 구축에 대한 표준 접근 방식을 제공하여 효율성, 안정성 및 다른 시스템과의 통합 용이성을 보장합니다. 가장 많이 사용되는 스타일은 다음과 같습니다.
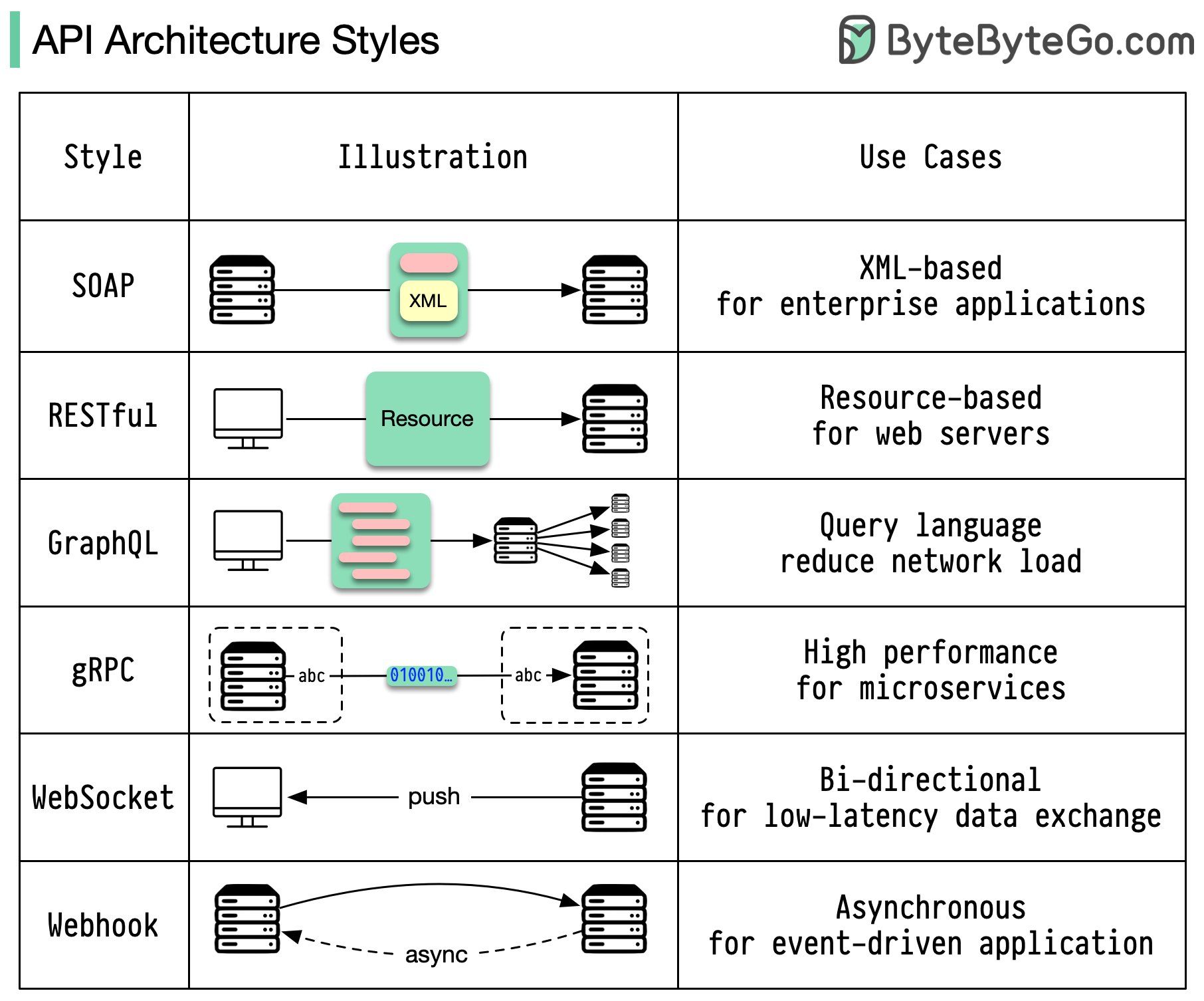
비누:
성숙하고 포괄적인 XML 기반
엔터프라이즈 애플리케이션에 가장 적합
평안한:
인기 있고 구현하기 쉬운 HTTP 메소드
웹 서비스에 이상적
GraphQL:
쿼리 언어, 특정 데이터 요청
네트워크 오버헤드 감소, 응답 속도 향상
gRPC:
최신 고성능 프로토콜 버퍼
마이크로서비스 아키텍처에 적합
웹소켓:
실시간, 양방향, 지속적인 연결
지연 시간이 짧은 데이터 교환에 적합
웹훅:
이벤트 기반, HTTP 콜백, 비동기식
이벤트가 발생하면 시스템에 알립니다.
API 디자인과 관련하여 REST와 GraphQL은 각각 고유한 장점과 단점을 가지고 있습니다.
아래 다이어그램은 REST와 GraphQL 간의 빠른 비교를 보여줍니다.
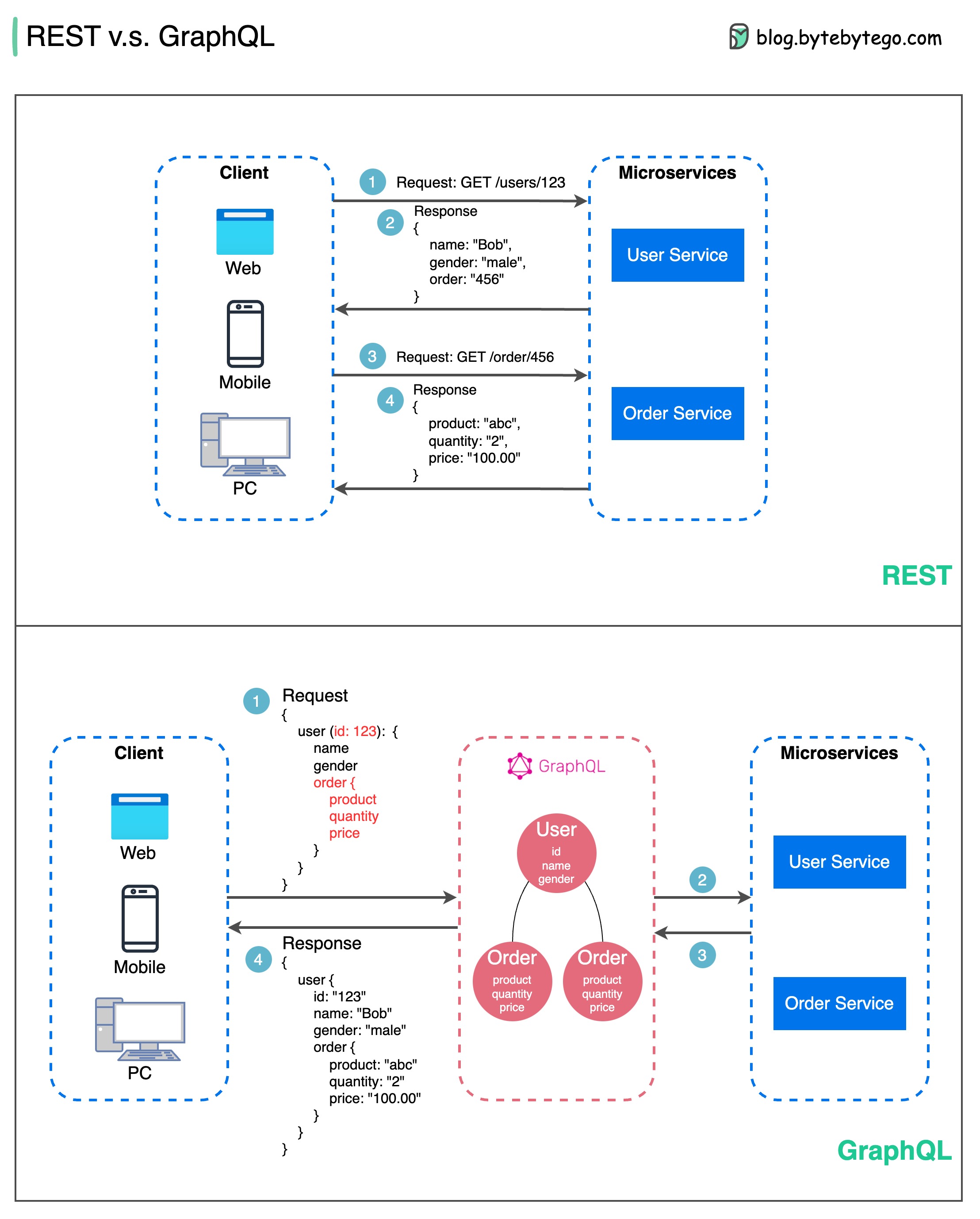
나머지
GraphQL
REST와 GraphQL 간의 최선의 선택은 애플리케이션 및 개발 팀의 특정 요구 사항에 따라 다릅니다. GraphQL은 복잡하거나 자주 변경되는 프런트엔드 요구 사항에 적합한 반면, REST는 간단하고 일관된 계약이 선호되는 애플리케이션에 적합합니다.
두 API 접근 방식 모두 만능은 아닙니다. 올바른 스타일을 선택하려면 요구 사항과 장단점을 신중하게 평가하는 것이 중요합니다. REST와 GraphQL은 모두 데이터를 노출하고 최신 애플리케이션을 지원하는 데 유효한 옵션입니다.
RPC(Remote Procedure Call)는 마이크로서비스 아키텍처 하에서 서비스가 서로 다른 서버에 배포될 때 원격 서비스 간의 통신을 가능하게 하기 때문에 " 원격 "이라고 합니다. 사용자의 관점에서는 로컬 함수 호출처럼 작동합니다.
아래 다이어그램은 gRPC 의 전체 데이터 흐름을 보여줍니다.
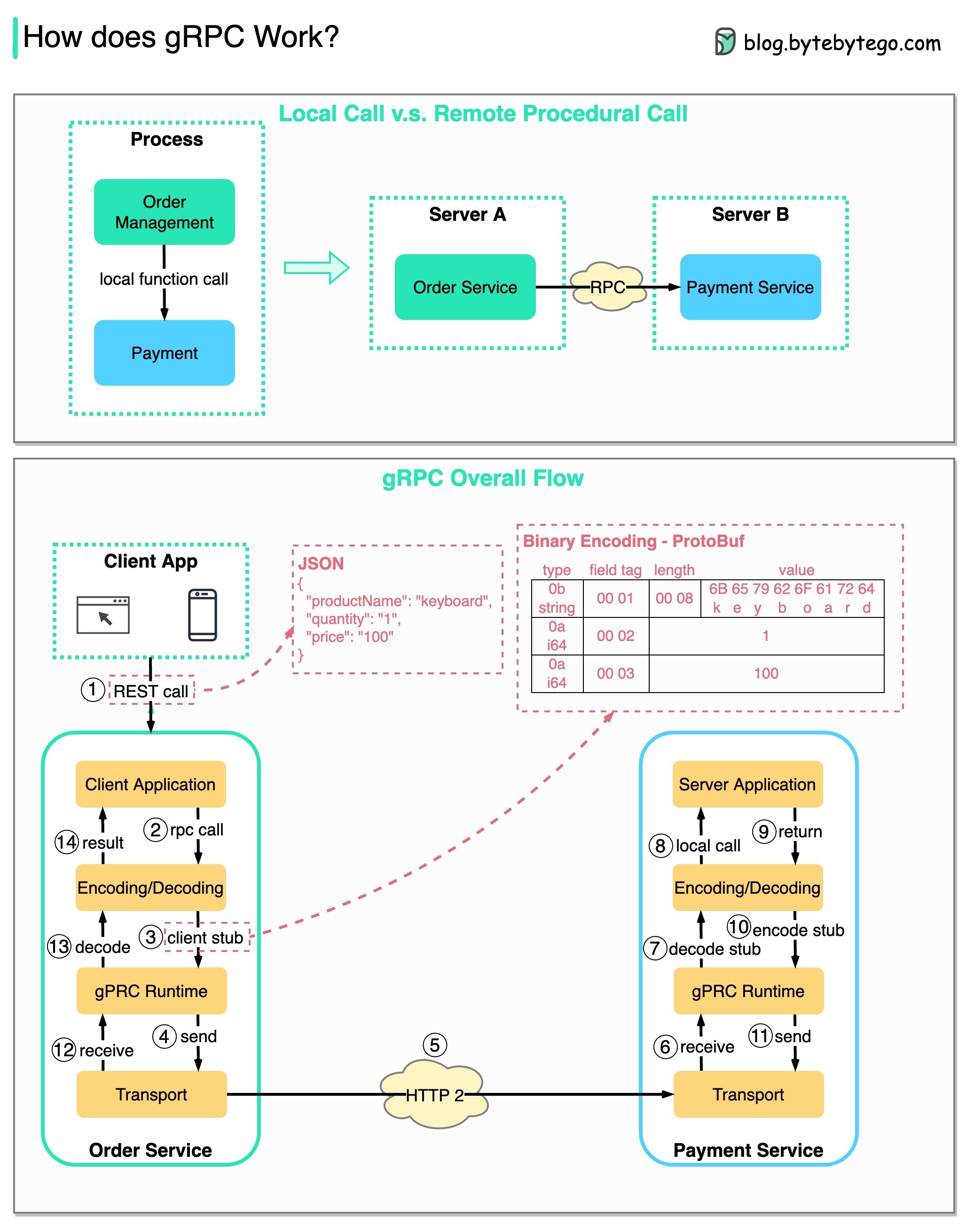
1단계: 클라이언트에서 REST 호출이 이루어집니다. 요청 본문은 일반적으로 JSON 형식입니다.
2~4단계: 주문 서비스(gRPC 클라이언트)는 REST 호출을 수신하고 이를 변환한 후 결제 서비스에 대해 RPC 호출을 수행합니다. gRPC는 클라이언트 스텁을 바이너리 형식으로 인코딩하여 하위 수준 전송 계층으로 보냅니다.
5단계: gRPC는 HTTP2를 통해 네트워크를 통해 패킷을 보냅니다. 바이너리 인코딩 및 네트워크 최적화로 인해 gRPC는 JSON보다 5배 더 빠른 것으로 알려져 있습니다.
6~8단계: 결제 서비스(gRPC 서버)가 네트워크에서 패킷을 수신하고 이를 디코딩한 후 서버 애플리케이션을 호출합니다.
9 - 11단계: 결과는 서버 애플리케이션에서 반환되고 인코딩되어 전송 계층으로 전송됩니다.
12~14단계: 주문 서비스는 패킷을 수신하고 디코딩한 후 결과를 클라이언트 애플리케이션에 보냅니다.
아래 다이어그램은 폴링과 Webhook의 비교를 보여줍니다.
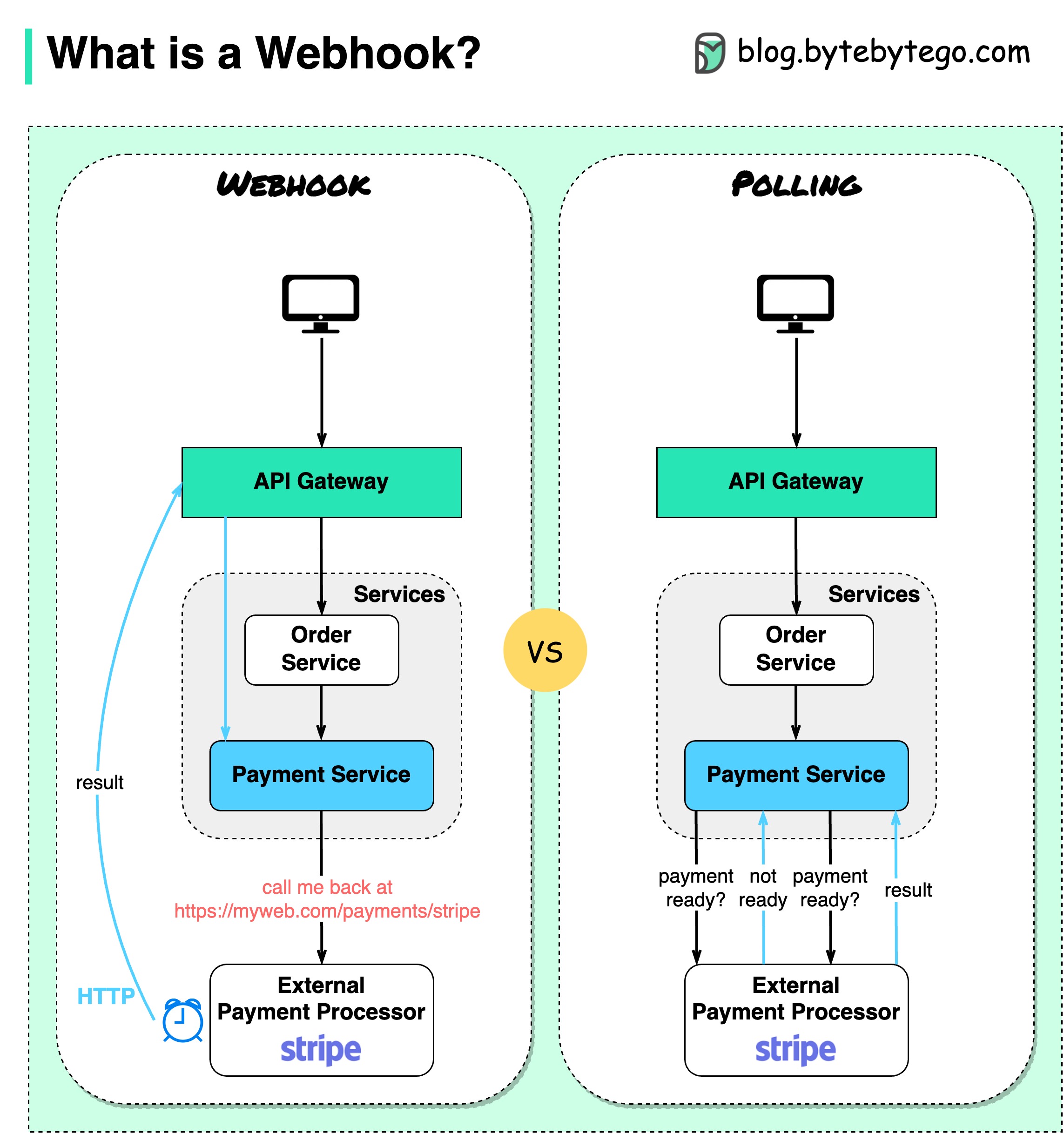
전자상거래 웹사이트를 운영한다고 가정해 보겠습니다. 클라이언트는 결제 거래를 위해 결제 서비스로 이동하는 API 게이트웨이를 통해 주문 서비스에 주문을 보냅니다. 그런 다음 결제 서비스는 외부 결제 서비스 제공업체(PSP)와 통신하여 거래를 완료합니다.
외부 PSP와의 통신을 처리하는 방법에는 두 가지가 있습니다.
1. 단기 폴링
PSP에 결제 요청을 보낸 후 결제 서비스에서는 PSP에 결제 상태를 계속 묻습니다. 여러 라운드 후에 PSP는 마침내 상태를 반환합니다.
짧은 폴링에는 두 가지 단점이 있습니다.
2. 웹훅
외부 서비스에 웹훅을 등록할 수 있습니다. 이는 요청에 대한 업데이트가 있으면 특정 URL로 다시 전화하라는 의미입니다. PSP가 처리를 완료하면 HTTP 요청을 호출하여 결제 상태를 업데이트합니다.
이러한 방식으로 프로그래밍 패러다임이 바뀌고 결제 서비스는 더 이상 결제 상태를 폴링하기 위해 리소스를 낭비할 필요가 없습니다.
PSP가 다시 전화하지 않으면 어떻게 되나요? 매시간 결제 상태를 확인하도록 하우스키핑 작업을 설정할 수 있습니다.
웹후크는 서버가 클라이언트에 HTTP 요청을 보내기 때문에 역방향 API 또는 푸시 API라고도 합니다. 웹훅을 사용할 때 3가지 사항에 주의해야 합니다.
아래 다이어그램은 API 성능을 향상시키는 5가지 일반적인 트릭을 보여줍니다.
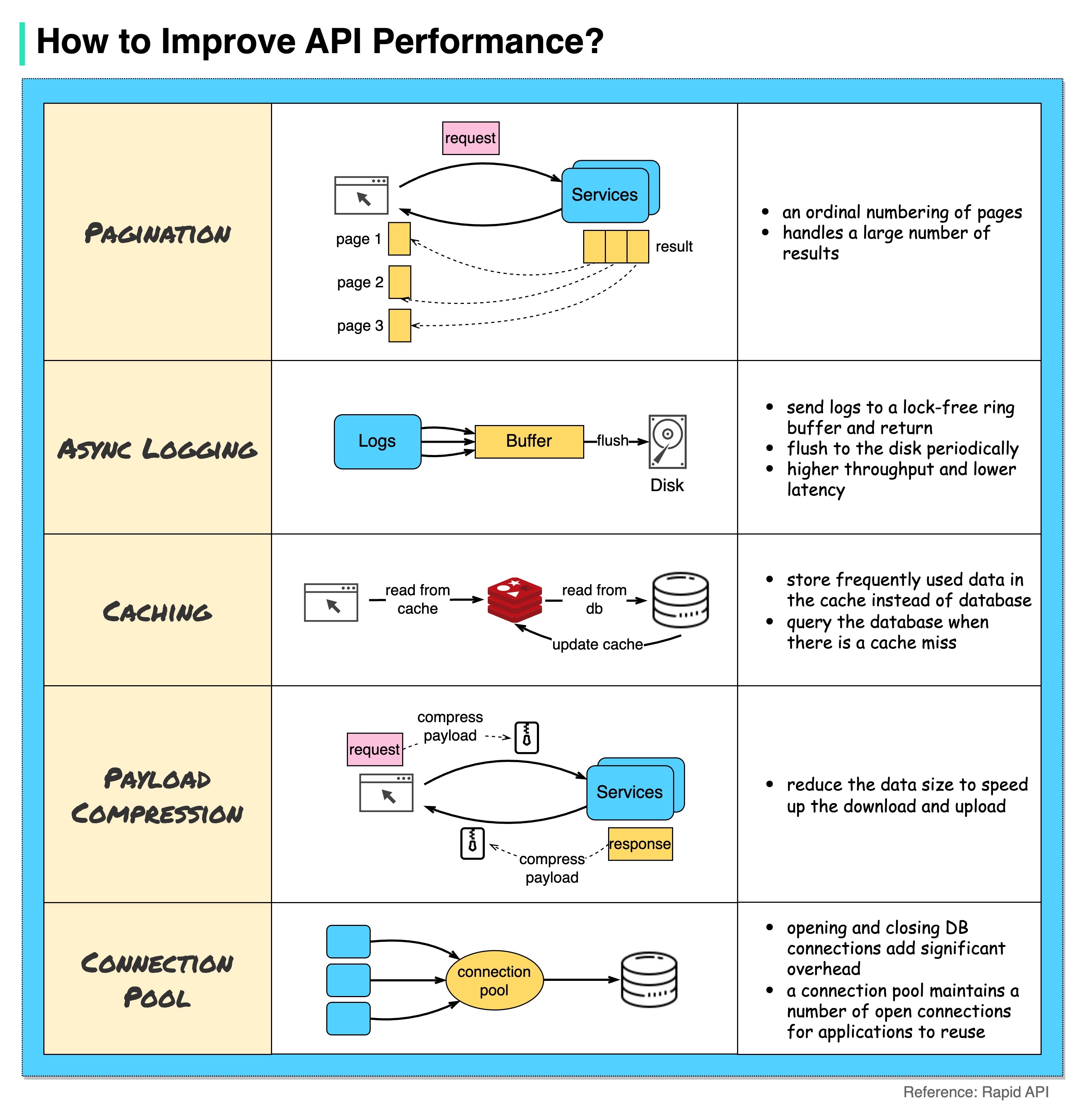
쪽수 매기기
이는 결과의 크기가 클 때 일반적인 최적화입니다. 결과는 클라이언트로 다시 스트리밍되어 서비스 응답성을 향상시킵니다.
비동기 로깅
동기 로깅은 모든 호출에 대해 디스크를 처리하며 시스템 속도를 저하시킬 수 있습니다. 비동기 로깅은 먼저 잠금이 없는 버퍼에 로그를 보내고 즉시 반환합니다. 로그는 주기적으로 디스크에 플러시됩니다. 이는 I/O 오버헤드를 크게 줄여줍니다.
캐싱
자주 액세스하는 데이터를 캐시에 저장할 수 있습니다. 클라이언트는 데이터베이스를 직접 방문하는 대신 먼저 캐시를 쿼리할 수 있습니다. 캐시 누락이 있는 경우 클라이언트는 데이터베이스에서 쿼리할 수 있습니다. Redis와 같은 캐시는 데이터를 메모리에 저장하므로 데이터 액세스가 데이터베이스보다 훨씬 빠릅니다.
페이로드 압축
요청과 응답은 gzip 등을 사용하여 압축할 수 있으므로 전송되는 데이터 크기가 훨씬 작습니다. 이렇게 하면 업로드 및 다운로드 속도가 빨라집니다.
연결 풀
리소스에 액세스할 때 데이터베이스에서 데이터를 로드해야 하는 경우가 많습니다. 닫는 DB 연결을 열면 상당한 오버헤드가 추가됩니다. 따라서 우리는 열린 연결 풀을 통해 DB에 연결해야 합니다. 연결 풀은 연결 수명주기를 관리하는 역할을 합니다.
각 세대의 HTTP는 어떤 문제를 해결합니까?
아래 다이어그램은 주요 기능을 보여줍니다.
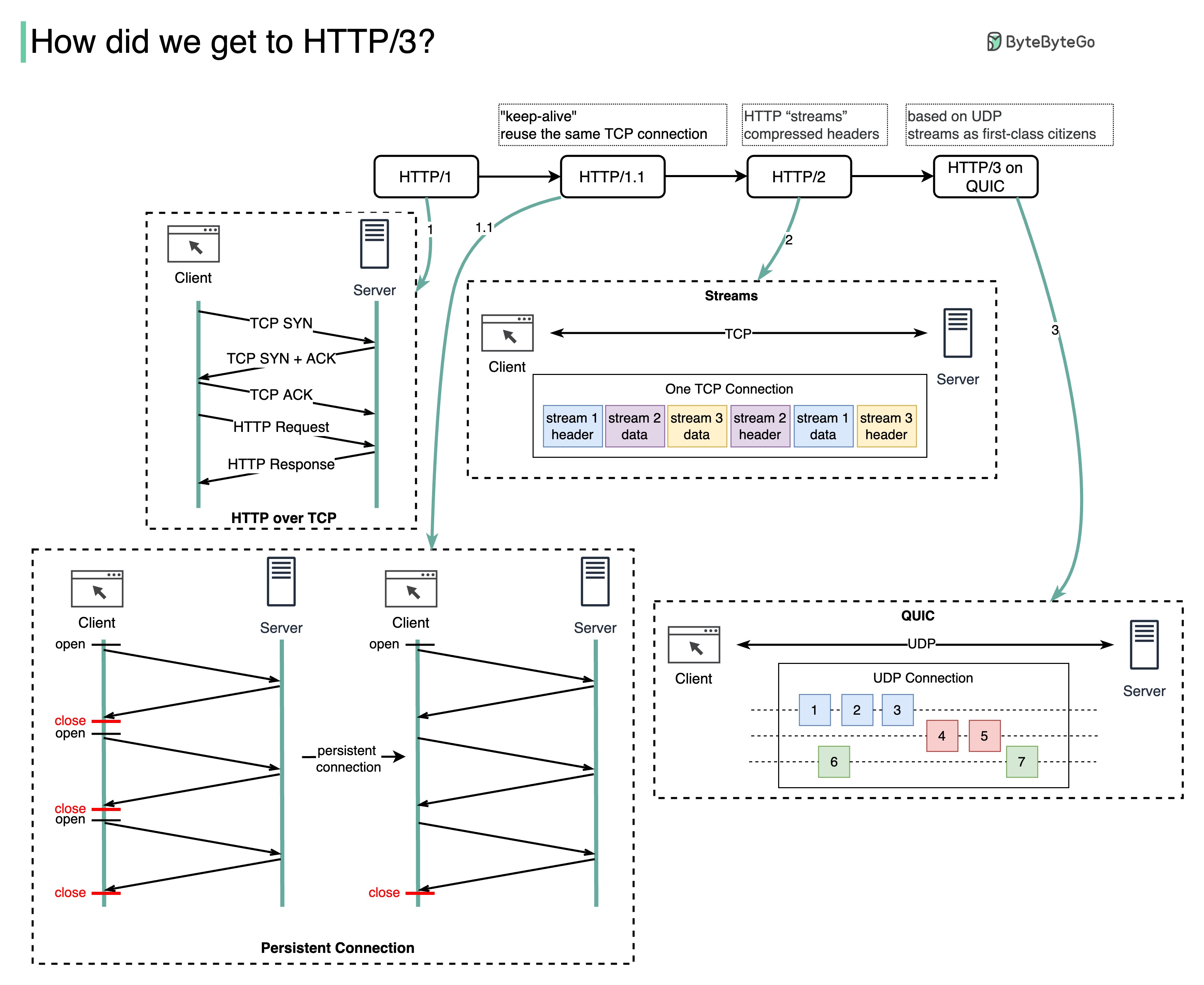
HTTP 1.0은 1996년에 완성되어 완전히 문서화되었습니다. 동일한 서버에 대한 모든 요청에는 별도의 TCP 연결이 필요합니다.
HTTP 1.1은 1997년에 발표되었습니다. 재사용을 위해 TCP 연결을 열어 둘 수 있지만(영구 연결) HOL(head-of-line) 차단 문제는 해결되지 않습니다.
HOL 차단 - 브라우저에서 허용된 병렬 요청 수가 모두 사용되면 후속 요청은 이전 요청이 완료될 때까지 기다려야 합니다.
HTTP 2.0은 2015년에 발표되었습니다. 요청 멀티플렉싱을 통해 HOL 문제를 해결합니다. 이는 애플리케이션 계층에서 HOL 차단을 제거하지만 HOL은 여전히 전송(TCP) 계층에 존재합니다.
다이어그램에서 볼 수 있듯이 HTTP 2.0은 HTTP "스트림" 개념을 도입했습니다. 이는 서로 다른 HTTP 교환을 동일한 TCP 연결에 다중화할 수 있는 추상화입니다. 각 스트림을 순서대로 전송할 필요는 없습니다.
HTTP 3.0 첫 번째 초안은 2020년에 발표되었습니다. 이는 HTTP 2.0의 후속 버전으로 제안되었습니다. 기본 전송 프로토콜에 TCP 대신 QUIC를 사용하므로 전송 계층에서 HOL 차단을 제거합니다.
QUIC은 UDP를 기반으로 합니다. 전송 계층에서 스트림을 일류 시민으로 소개합니다. QUIC 스트림은 동일한 QUIC 연결을 공유하므로 새 스트림을 생성하기 위해 추가 핸드셰이크와 느린 시작이 필요하지 않습니다. 그러나 QUIC 스트림은 대부분의 경우 한 스트림에 영향을 미치는 패킷 손실이 다른 스트림에 영향을 미치지 않도록 독립적으로 전달됩니다.
아래 다이어그램은 API 타임라인과 API 스타일 비교를 보여줍니다.
시간이 지남에 따라 다양한 API 아키텍처 스타일이 출시됩니다. 그들 각각은 데이터 교환을 표준화하는 고유한 패턴을 가지고 있습니다.
각 스타일의 사용 사례를 다이어그램에서 확인하실 수 있습니다.
아래 다이어그램은 코드 우선 개발과 API 우선 개발의 차이점을 보여줍니다. API 우선 설계를 고려하려는 이유는 무엇입니까?
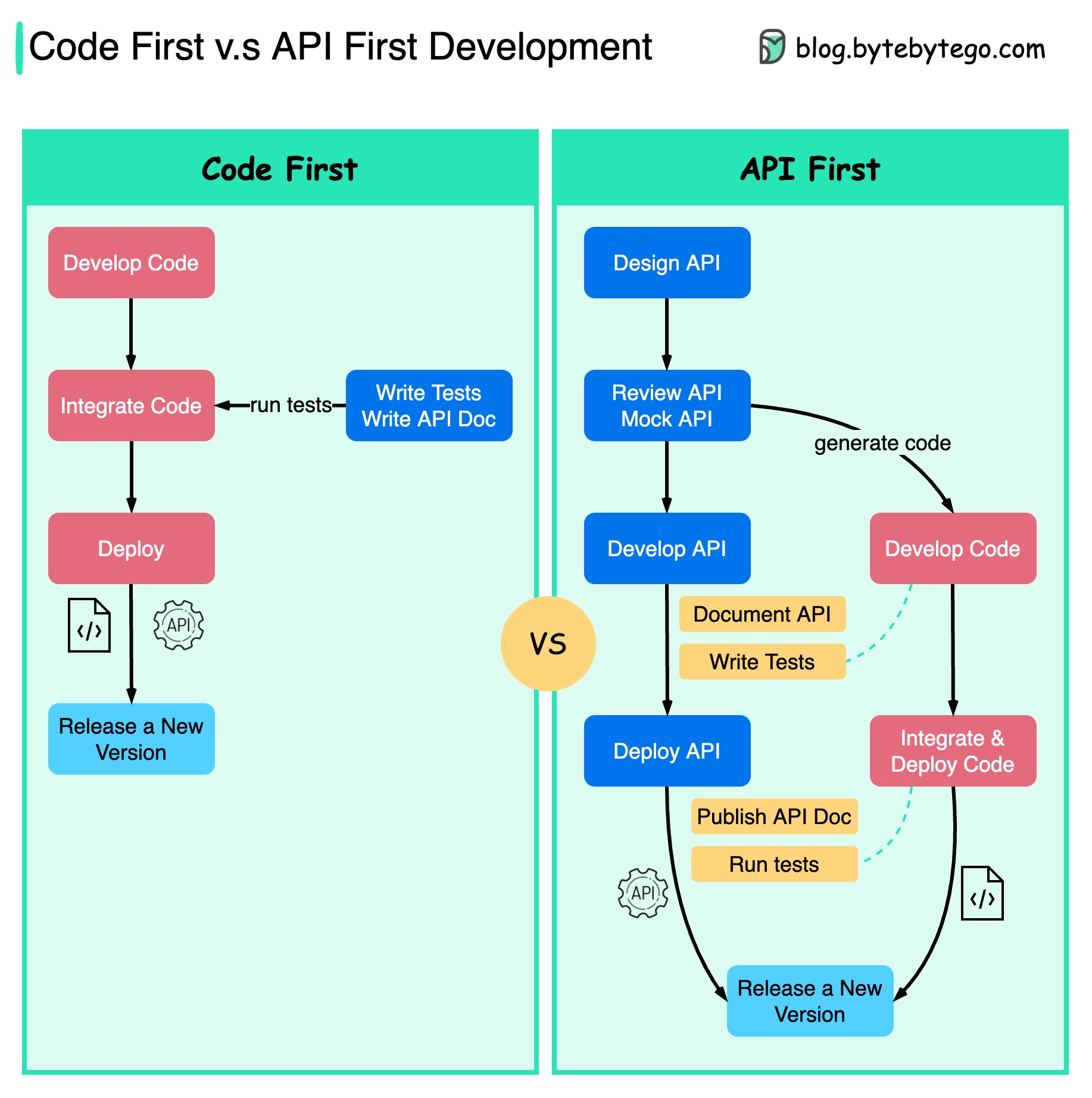
코드를 작성하고 서비스 경계를 신중하게 정의하기 전에 시스템의 복잡성을 고려하는 것이 좋습니다.
코드를 작성하기 전에 요청과 응답을 모의하여 API 디자인을 검증할 수 있습니다.
개발자도 갑작스러운 변경에 대해 협상하는 대신 기능 개발에 집중할 수 있기 때문에 프로세스에 만족합니다.
프로젝트 수명주기가 끝날 무렵 예상치 못한 상황이 발생할 가능성이 줄어듭니다.
API를 먼저 설계했기 때문에 코드가 개발되는 동안 테스트도 설계할 수 있습니다. 어떤 면에서는 API 우선 개발을 사용할 때 TDD(Test Driven Design)도 있습니다.
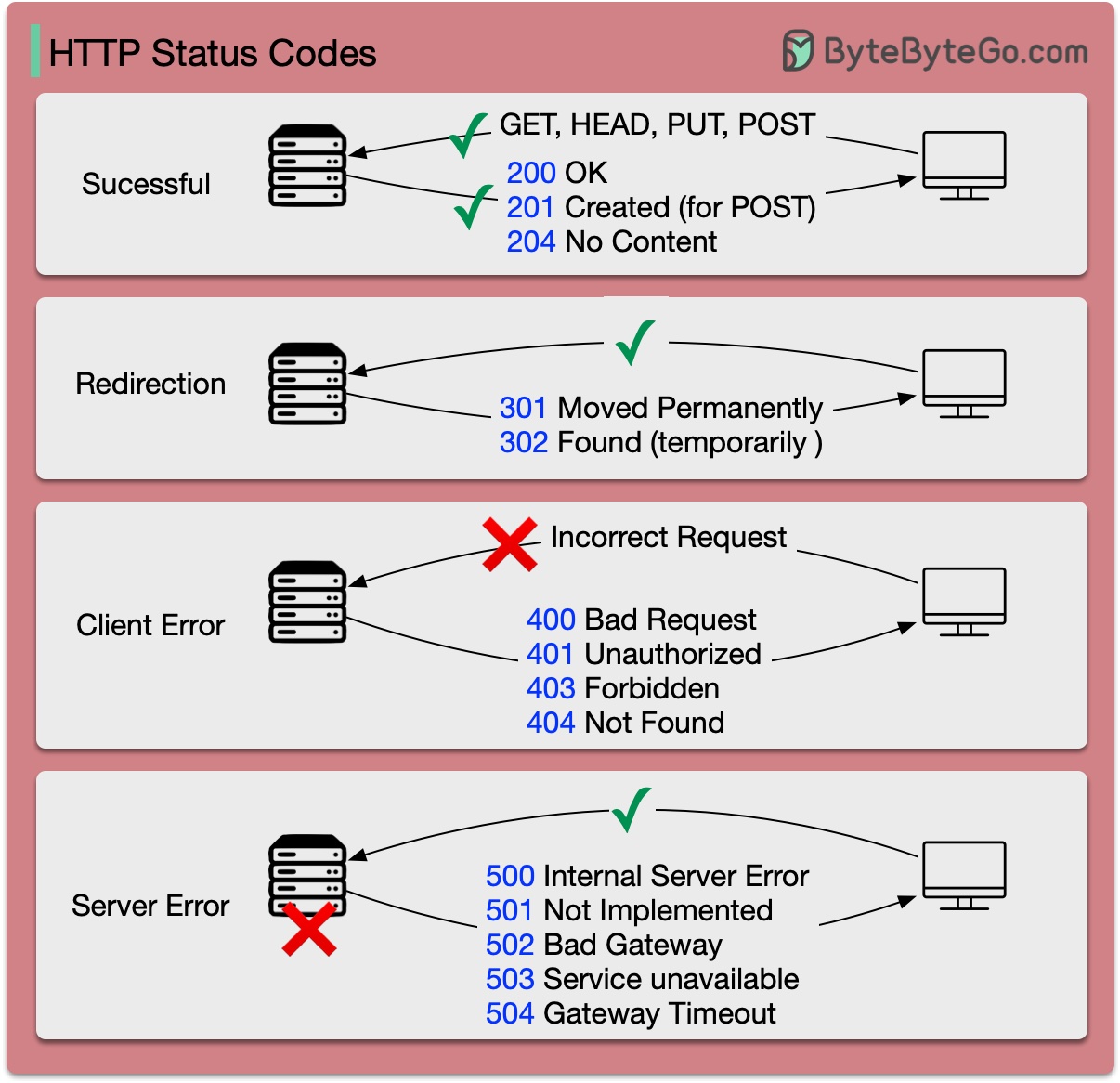
HTTP에 대한 응답 코드는 다섯 가지 범주로 나뉩니다.
정보(100-199) 성공(200-299) 리디렉션(300-399) 클라이언트 오류(400-499) 서버 오류(500-599)
아래 다이어그램은 세부 사항을 보여줍니다.
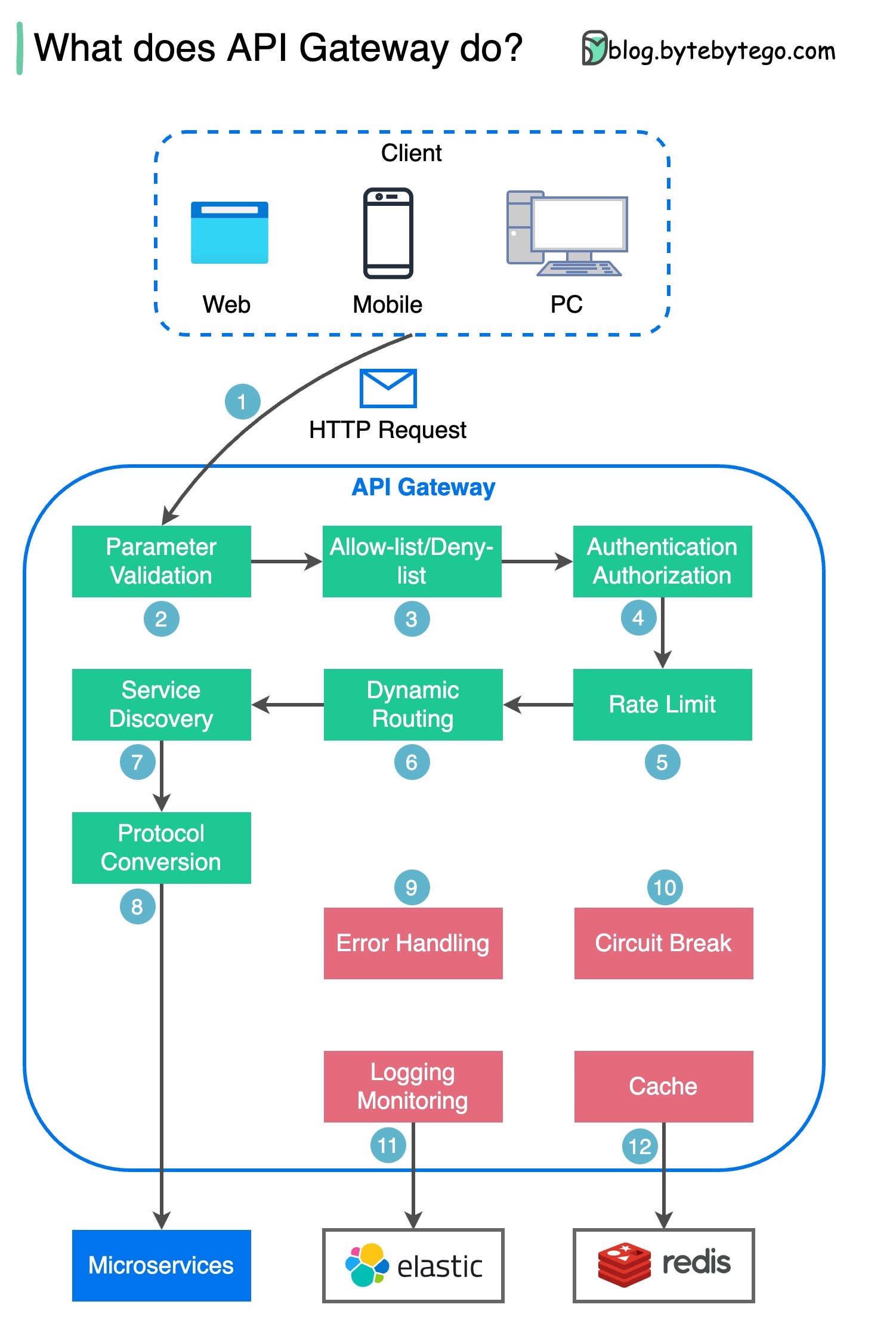
1단계 - 클라이언트가 API 게이트웨이에 HTTP 요청을 보냅니다.
2단계 - API 게이트웨이는 HTTP 요청의 속성을 구문 분석하고 검증합니다.
3단계 - API 게이트웨이는 허용 목록/거부 목록 확인을 수행합니다.
4단계 - API 게이트웨이는 인증 및 권한 부여를 위해 ID 공급자와 통신합니다.
5단계 - 속도 제한 규칙이 요청에 적용됩니다. 한도를 초과하면 요청이 거부됩니다.
6단계 및 7단계 - 이제 요청이 기본 검사를 통과했으므로 API 게이트웨이는 경로 일치를 통해 라우팅할 관련 서비스를 찾습니다.
8단계 - API 게이트웨이는 요청을 적절한 프로토콜로 변환하고 이를 백엔드 마이크로서비스로 보냅니다.
9~12단계: API 게이트웨이는 오류를 적절하게 처리할 수 있으며, 오류를 복구하는 데 더 오랜 시간이 걸리는 경우(회로 차단) 오류를 처리할 수 있습니다. 또한 로깅 및 모니터링을 위해 ELK(Elastic-Logstash-Kibana) 스택을 활용할 수도 있습니다. 때때로 API 게이트웨이에 데이터를 캐시합니다.
아래 다이어그램은 장바구니 예시를 포함한 일반적인 API 디자인을 보여줍니다.
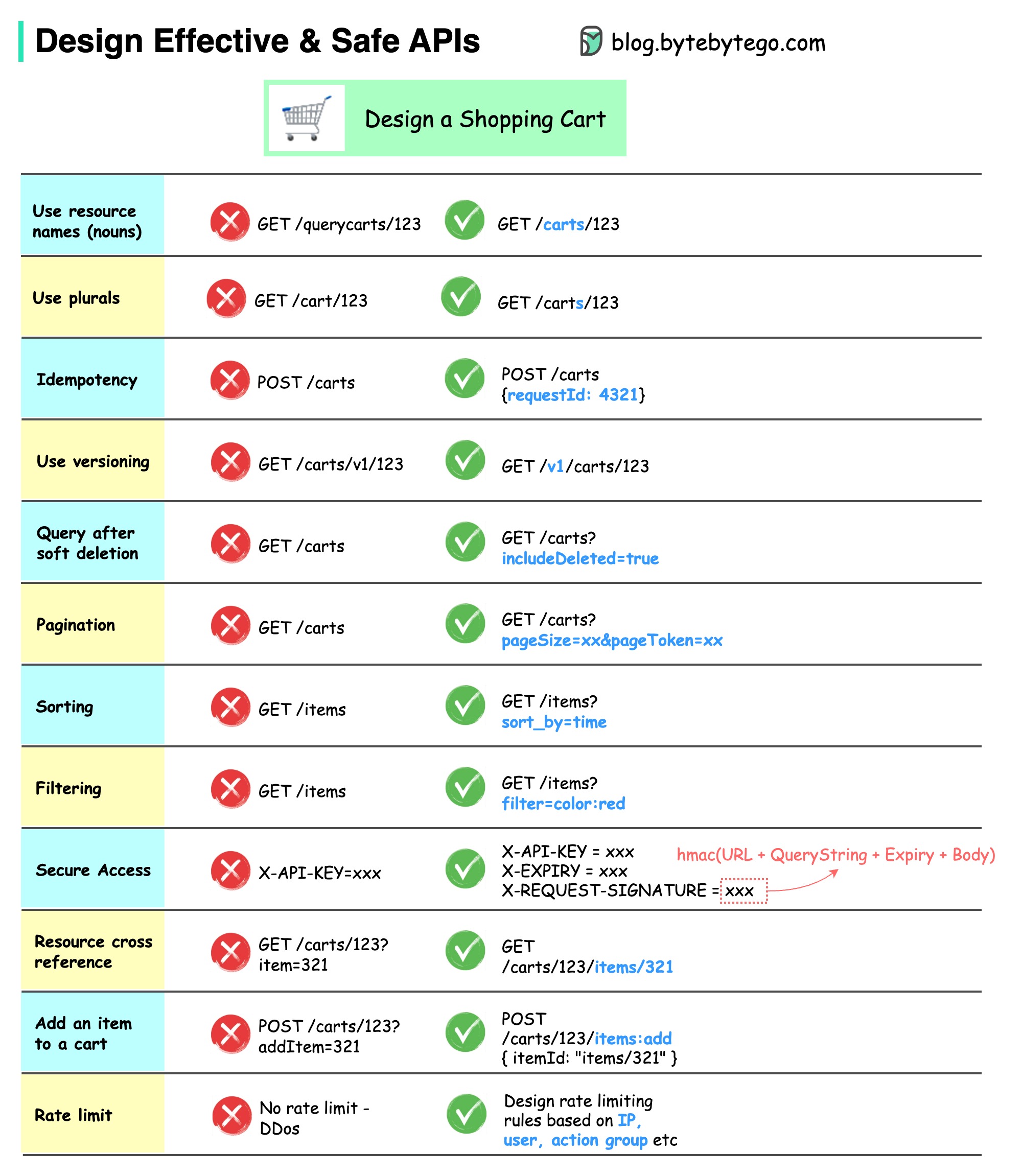
API 디자인은 단순한 URL 경로 디자인이 아닙니다. 대부분의 경우 적절한 리소스 이름, 식별자 및 경로 패턴을 선택해야 합니다. 적절한 HTTP 헤더 필드를 디자인하거나 API 게이트웨이 내에서 효과적인 속도 제한 규칙을 디자인하는 것도 마찬가지로 중요합니다.
데이터는 네트워크를 통해 어떻게 전송되나요? OSI 모델에 왜 그렇게 많은 레이어가 필요한가요?
아래 다이어그램은 네트워크를 통해 전송할 때 데이터가 캡슐화되고 캡슐화 해제되는 방식을 보여줍니다.
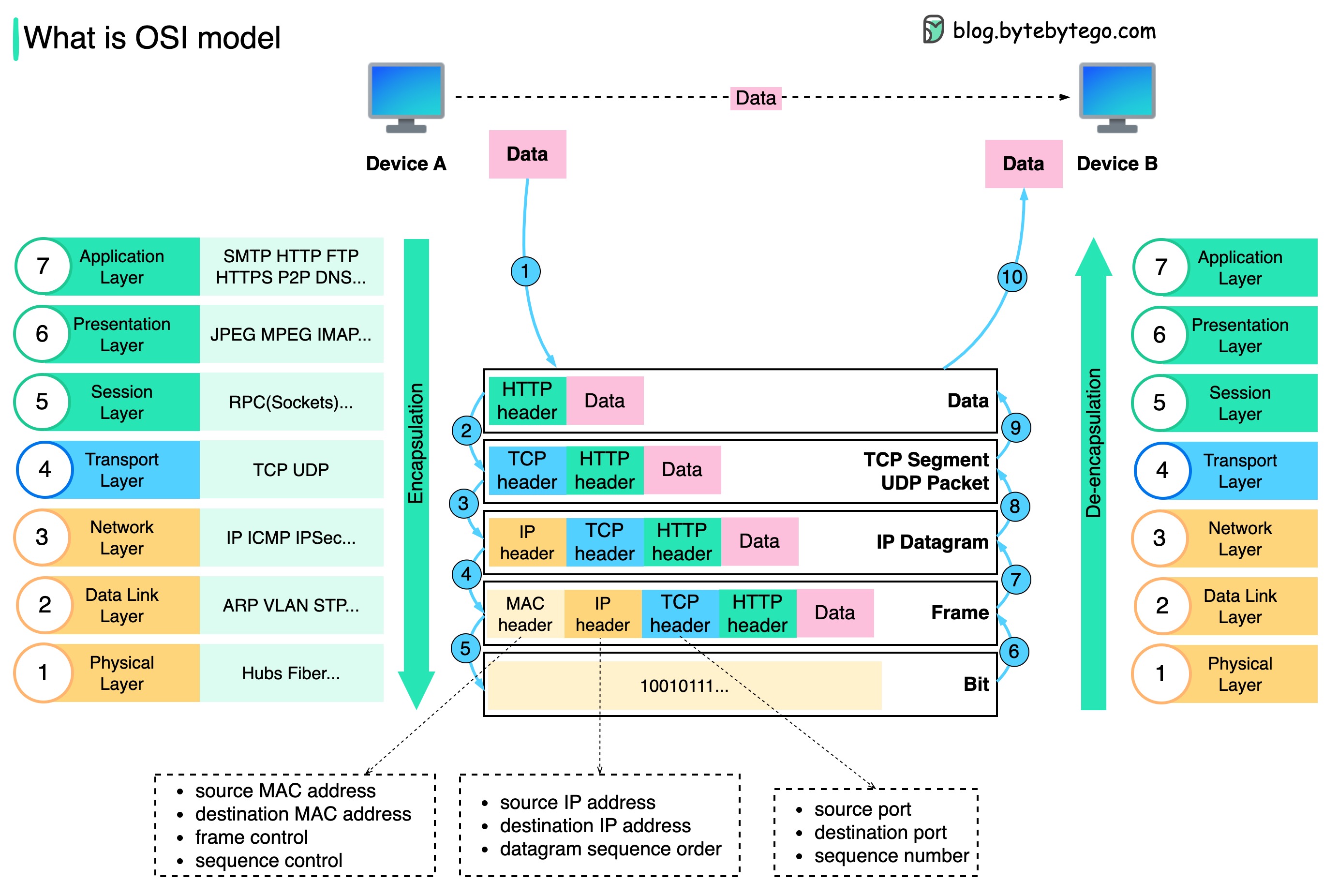
1단계: 장치 A가 HTTP 프로토콜을 통해 네트워크를 통해 장치 B에 데이터를 보낼 때 먼저 애플리케이션 계층에 HTTP 헤더가 추가됩니다.
2단계: 그런 다음 TCP 또는 UDP 헤더가 데이터에 추가됩니다. 이는 전송 계층에서 TCP 세그먼트로 캡슐화됩니다. 헤더에는 소스 포트, 대상 포트 및 시퀀스 번호가 포함됩니다.
3단계: 그런 다음 세그먼트는 네트워크 계층에서 IP 헤더로 캡슐화됩니다. IP 헤더에는 소스/대상 IP 주소가 포함됩니다.
4단계: IP 데이터그램은 소스/목적지 MAC 주소와 함께 데이터 링크 계층의 MAC 헤더에 추가됩니다.
5단계: 캡슐화된 프레임은 물리 계층으로 전송되고 이진 비트로 네트워크를 통해 전송됩니다.
6-10단계: 장치 B가 네트워크로부터 비트를 수신하면 캡슐화 프로세스의 역처리인 캡슐화 해제 프로세스를 수행합니다. 헤더는 레이어별로 제거되고 결국 장치 B는 데이터를 읽을 수 있습니다.
각 계층은 자신의 책임에 초점을 맞추기 때문에 네트워크 모델에 계층이 필요합니다. 각 계층은 처리 명령을 위해 헤더에 의존할 수 있으며 마지막 계층의 데이터 의미를 알 필요가 없습니다.
아래 다이어그램은 ????????의 차이점을 보여줍니다. ????? 그리고 ???????? ?????.
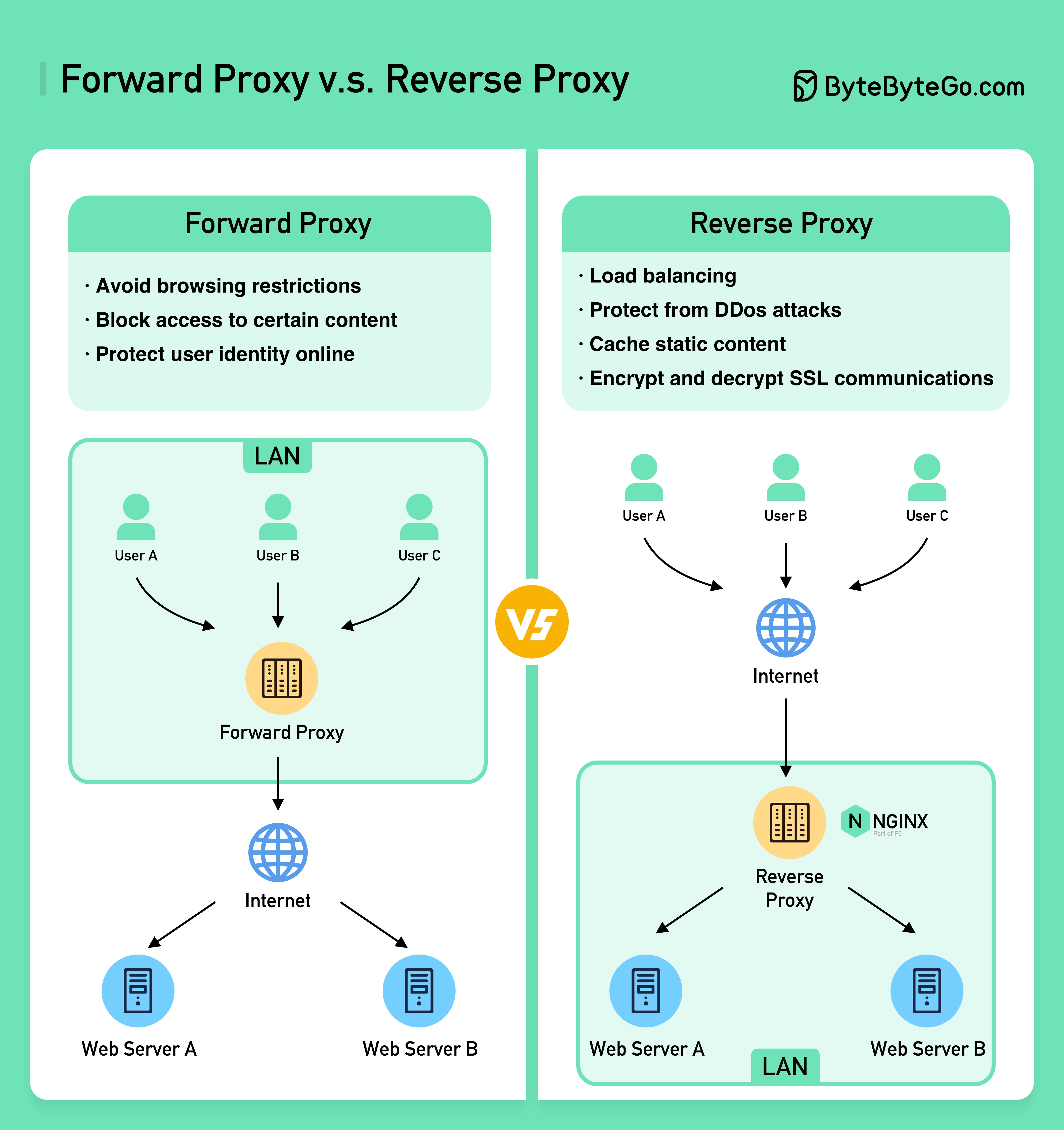
정방향 프록시는 사용자 장치와 인터넷 사이에 위치하는 서버입니다.
정방향 프록시는 일반적으로 다음 용도로 사용됩니다.
역방향 프록시는 클라이언트의 요청을 수락하고, 요청을 웹 서버로 전달하고, 마치 프록시 서버가 요청을 처리한 것처럼 결과를 클라이언트에 반환하는 서버입니다.
역방향 프록시는 다음에 적합합니다.
아래 다이어그램은 6가지 일반적인 알고리즘을 보여줍니다.
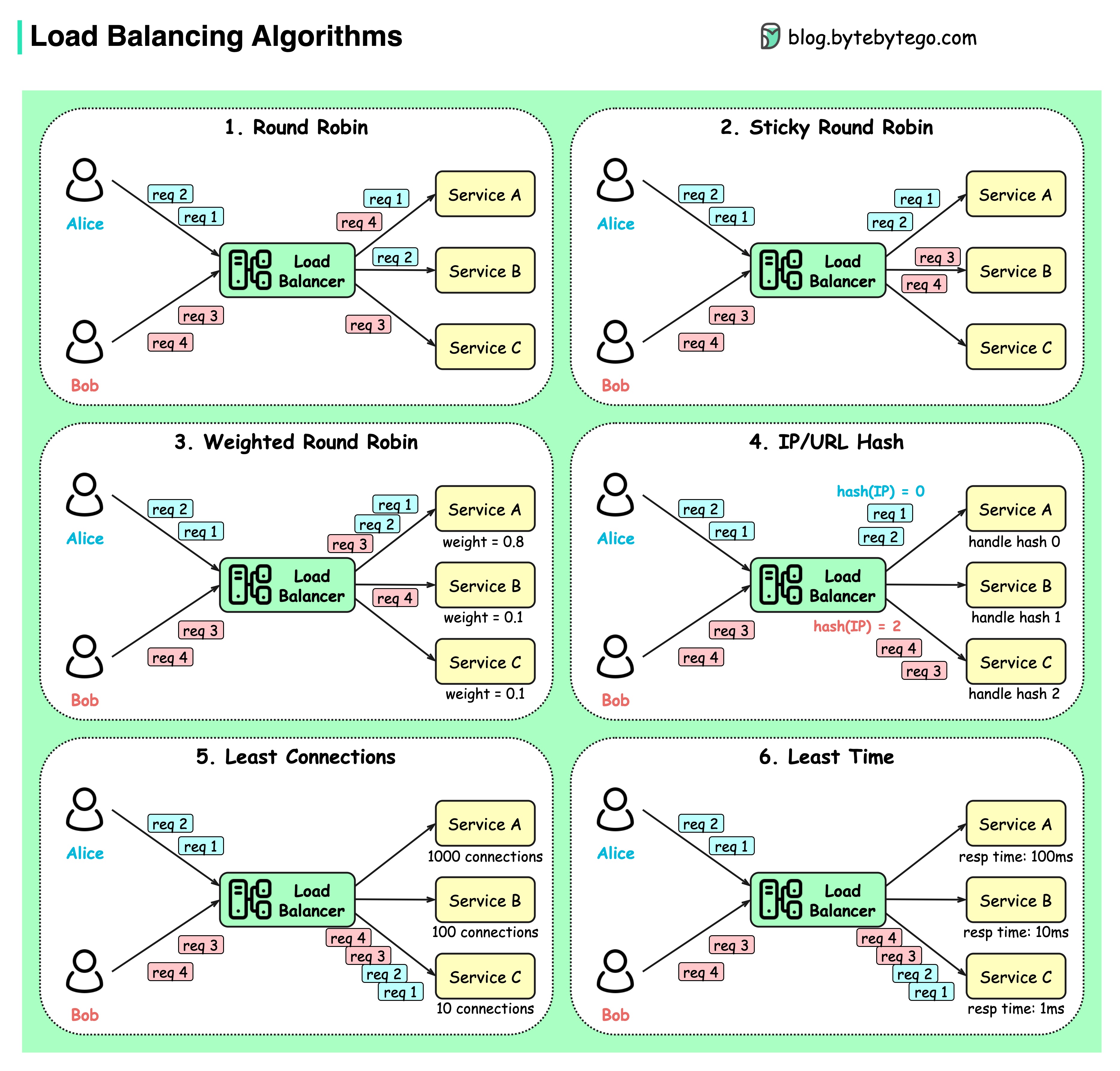
라운드 로빈
클라이언트 요청은 순차적으로 다른 서비스 인스턴스로 전송됩니다. 서비스는 일반적으로 Stateless여야 합니다.
끈끈한 라운드 로빈
이는 라운드 로빈 알고리즘이 개선된 것입니다. Alice의 첫 번째 요청이 서비스 A로 이동하면 다음 요청도 서비스 A로 이동합니다.
가중 라운드 로빈
관리자는 각 서비스에 대한 가중치를 지정할 수 있습니다. 가중치가 더 높은 항목은 다른 항목보다 더 많은 요청을 처리합니다.
해시시
이 알고리즘은 들어오는 요청의 IP 또는 URL에 해시 함수를 적용합니다. 요청은 해시 함수 결과에 따라 관련 인스턴스로 라우팅됩니다.
최소 연결
동시 연결이 가장 적은 서비스 인스턴스로 새 요청이 전송됩니다.
최소 응답 시간
응답 시간이 가장 빠른 서비스 인스턴스로 새 요청이 전송됩니다.
아래 다이어그램은 URL, URI, URN을 비교한 것입니다.
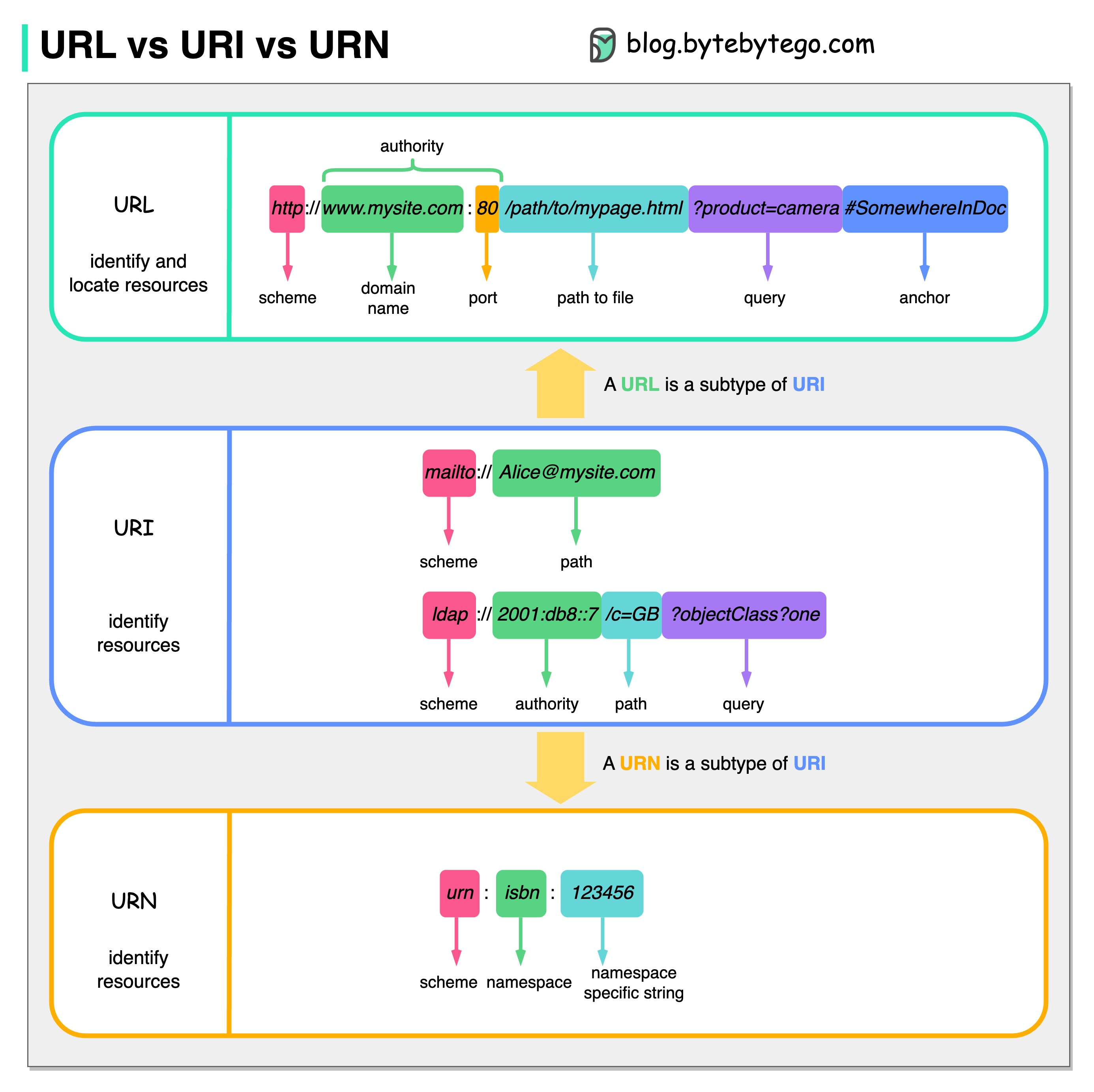
URI는 통일 자원 식별자(Uniform Resource Identifier)를 의미합니다. 웹에서 논리적 또는 물리적 리소스를 식별합니다. URL과 URN은 URI의 하위 유형입니다. URL은 리소스를 찾고 URN은 리소스의 이름을 지정합니다.
URI는 다음 부분으로 구성됩니다: 구성표:[//authority]경로[?query][#fragment]
URL은 HTTP의 핵심 개념인 Universal Resource Locator를 의미합니다. 웹에 있는 고유한 리소스의 주소입니다. FTP 및 JDBC와 같은 다른 프로토콜과 함께 사용할 수 있습니다.
URN은 유니폼 리소스 이름(Uniform Resource Name)을 나타냅니다. 그것은 항아리 구성표를 사용합니다. URN은 리소스를 찾는 데 사용할 수 없습니다. 다이어그램에 제공된 간단한 예는 네임스페이스와 네임스페이스별 문자열로 구성됩니다.
해당 주제에 대해 더 자세히 알고 싶다면 W3C의 설명을 추천합니다.
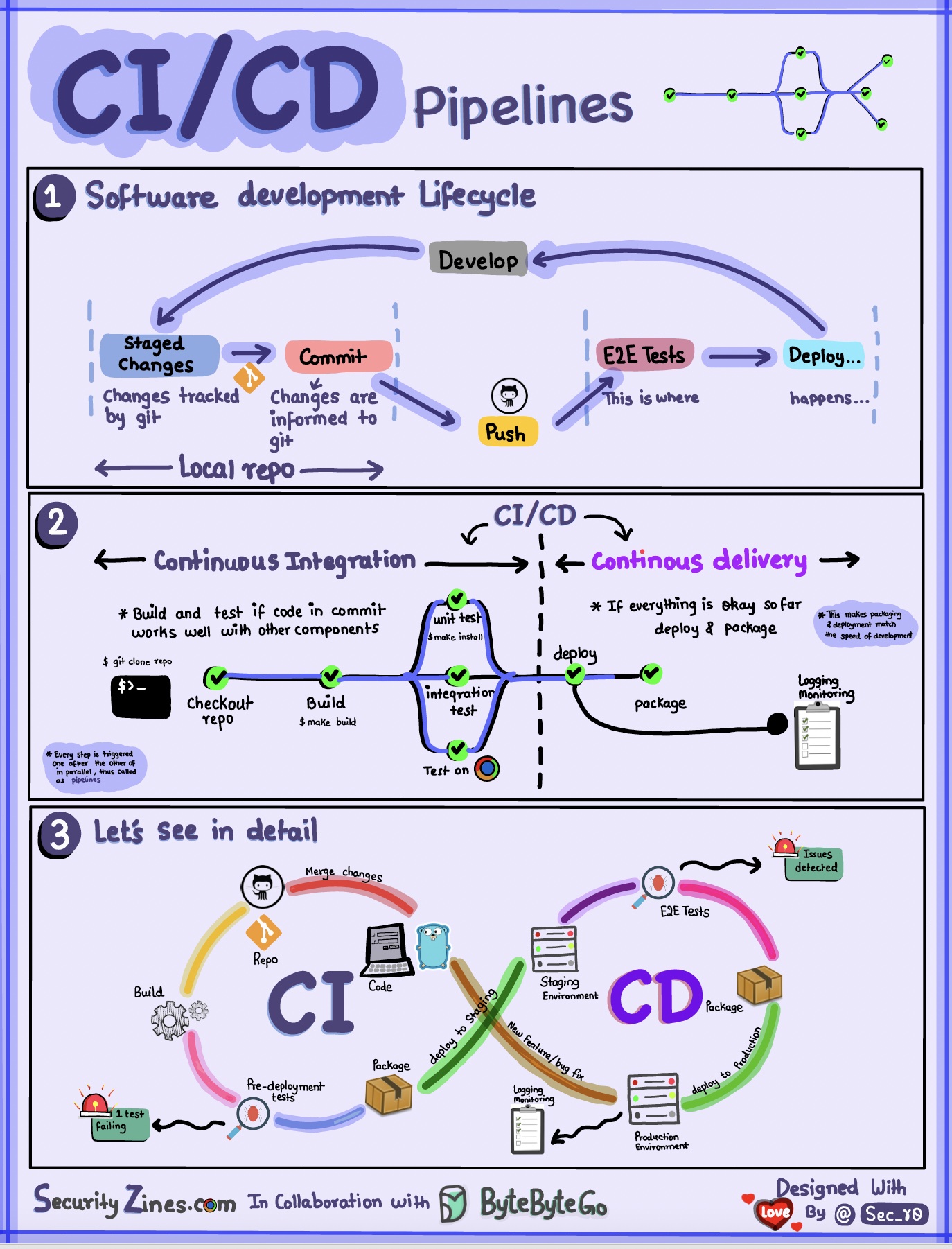
섹션 1 - CI/CD가 포함된 SDLC
소프트웨어 개발 수명주기(SDLC)는 개발, 테스트, 배포, 유지 관리 등 여러 주요 단계로 구성됩니다. CI/CD는 이러한 단계를 자동화하고 통합하여 더 빠르고 안정적인 릴리스를 가능하게 합니다.
코드가 git 저장소로 푸시되면 자동화된 빌드 및 테스트 프로세스가 시작됩니다. 코드 검증을 위해 엔드투엔드(e2e) 테스트 케이스가 실행됩니다. 테스트가 통과되면 코드가 스테이징/프로덕션에 자동으로 배포될 수 있습니다. 문제가 발견되면 버그 수정을 위해 코드가 개발팀으로 다시 전송됩니다. 이 자동화는 개발자에게 빠른 피드백을 제공하고 프로덕션에서 버그가 발생할 위험을 줄여줍니다.
섹션 2 - CI와 CD의 차이점
CI(지속적 통합)는 빌드, 테스트 및 병합 프로세스를 자동화합니다. 통합 문제를 조기에 감지하기 위해 코드가 커밋될 때마다 테스트를 실행합니다. 이는 빈번한 코드 커밋과 빠른 피드백을 장려합니다.
CD(지속적인 전달)는 인프라 변경 및 배포와 같은 릴리스 프로세스를 자동화합니다. 자동화된 워크플로를 통해 언제든지 소프트웨어를 안정적으로 출시할 수 있습니다. CD는 또한 프로덕션 배포 전에 필요한 수동 테스트 및 승인 단계를 자동화할 수도 있습니다.
섹션 3 - CI/CD 파이프라인
일반적인 CI/CD 파이프라인에는 여러 개의 연결된 단계가 있습니다.
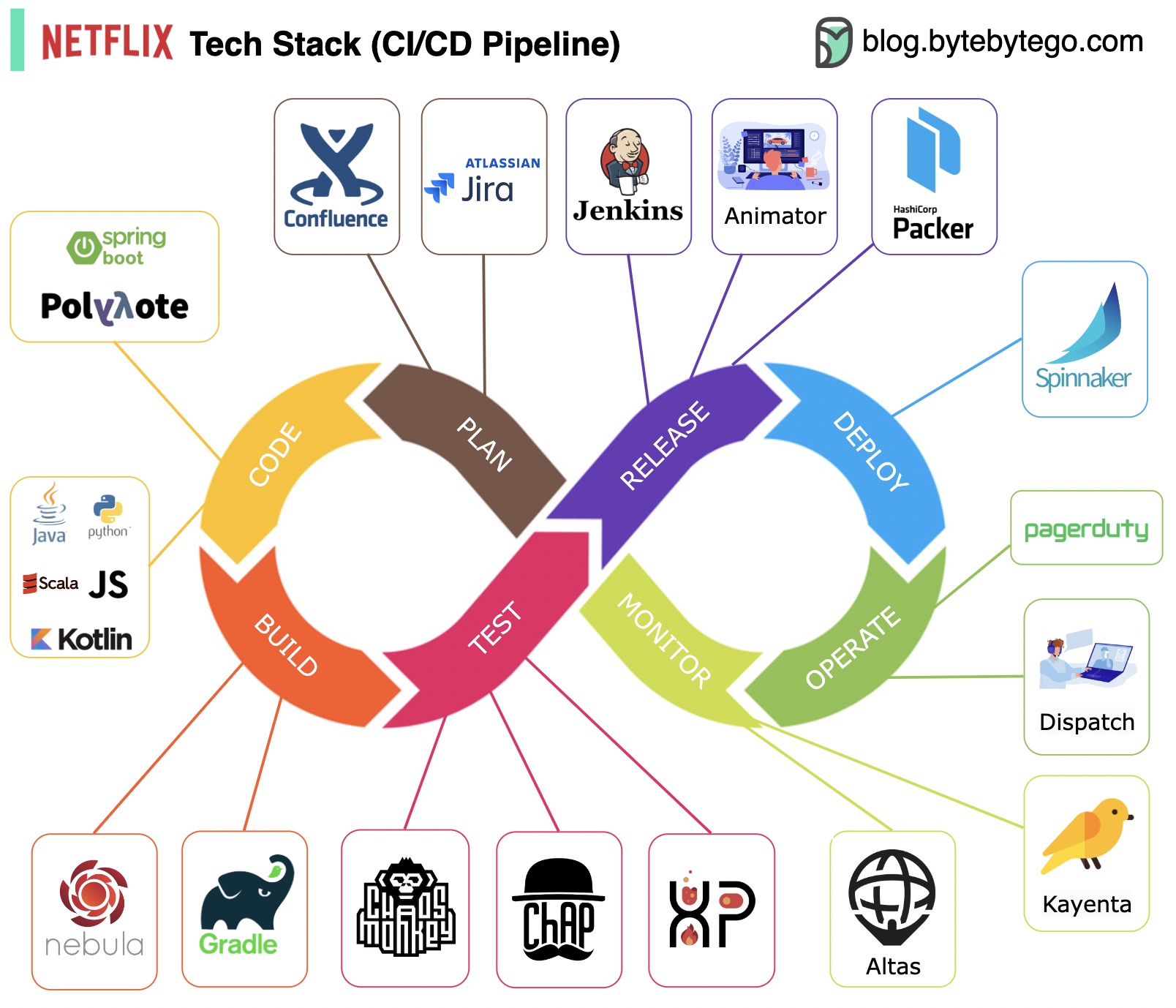
계획: Netflix Engineering은 계획을 위해 JIRA를 사용하고 문서화를 위해 Confluence를 사용합니다.
코딩: Java는 백엔드 서비스의 기본 프로그래밍 언어인 반면, 다른 언어는 다양한 사용 사례에 사용됩니다.
빌드: Gradle은 주로 빌드에 사용되며 Gradle 플러그인은 다양한 사용 사례를 지원하기 위해 빌드됩니다.
패키징: 패키지 및 종속성은 릴리스를 위해 Amazon 머신 이미지(AMI)에 패키징됩니다.
테스트: 테스트는 카오스 도구 구축에 대한 생산 문화의 초점을 강조합니다.
배포: Netflix는 카나리아 롤아웃 배포를 위해 자체 구축된 Spinnaker를 사용합니다.
모니터링: 모니터링 지표는 Atlas에 중앙 집중화되어 있으며 Kayenta는 이상 현상을 감지하는 데 사용됩니다.
사고 보고서: 사고는 우선순위에 따라 발송되며, 사고 처리에는 PagerDuty가 사용됩니다.
이러한 아키텍처 패턴은 iOS 또는 Android 플랫폼에서 앱 개발에 가장 일반적으로 사용됩니다. 개발자들은 이전 패턴의 한계를 극복하기 위해 이를 도입했습니다. 그렇다면 그것들은 어떻게 다릅니까?
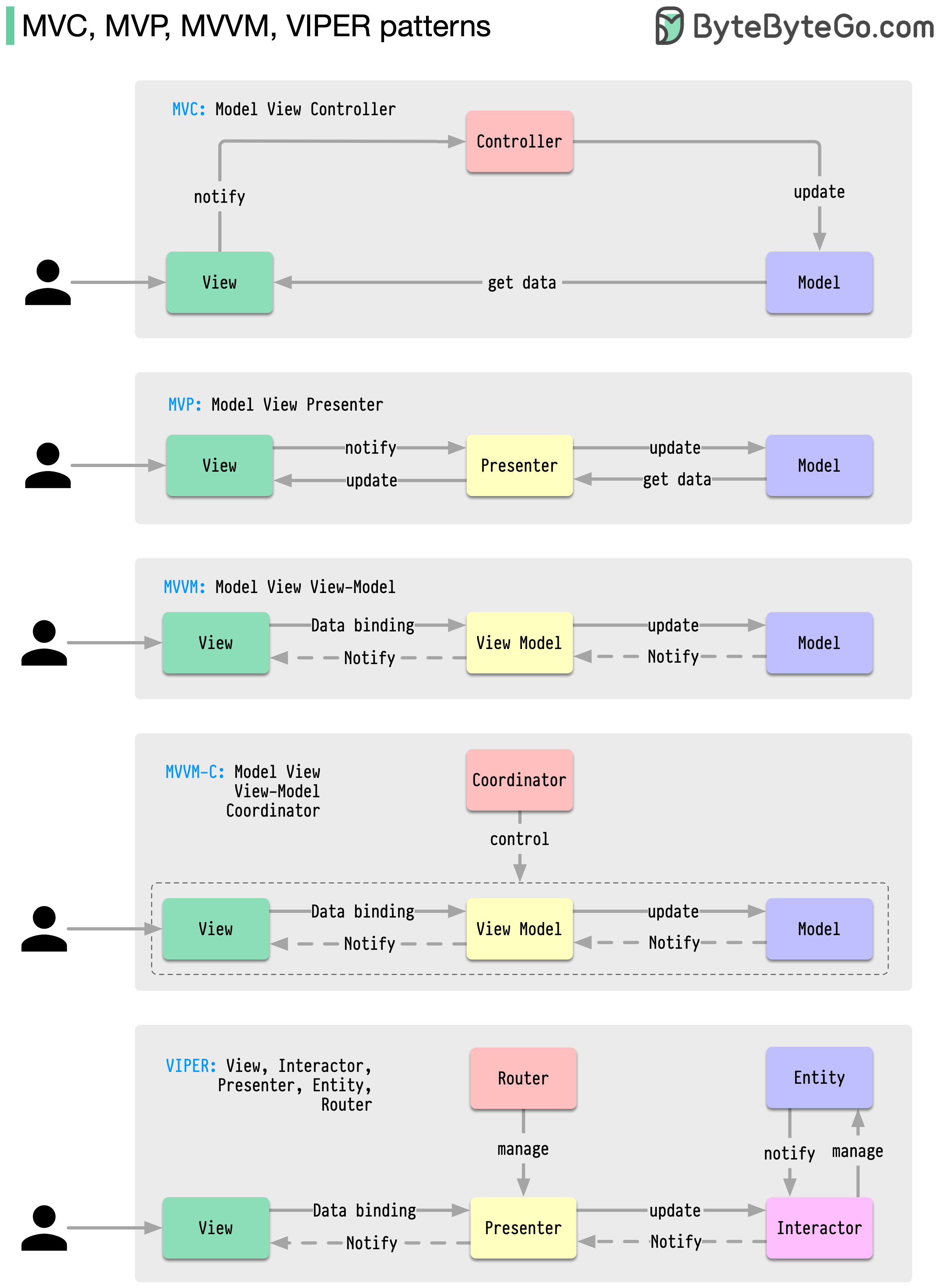
패턴은 일반적인 디자인 문제에 대한 재사용 가능한 솔루션이므로 개발 프로세스가 더욱 원활하고 효율적으로 진행됩니다. 이는 더 나은 소프트웨어 구조를 구축하기 위한 청사진 역할을 합니다. 다음은 가장 인기 있는 패턴 중 일부입니다.

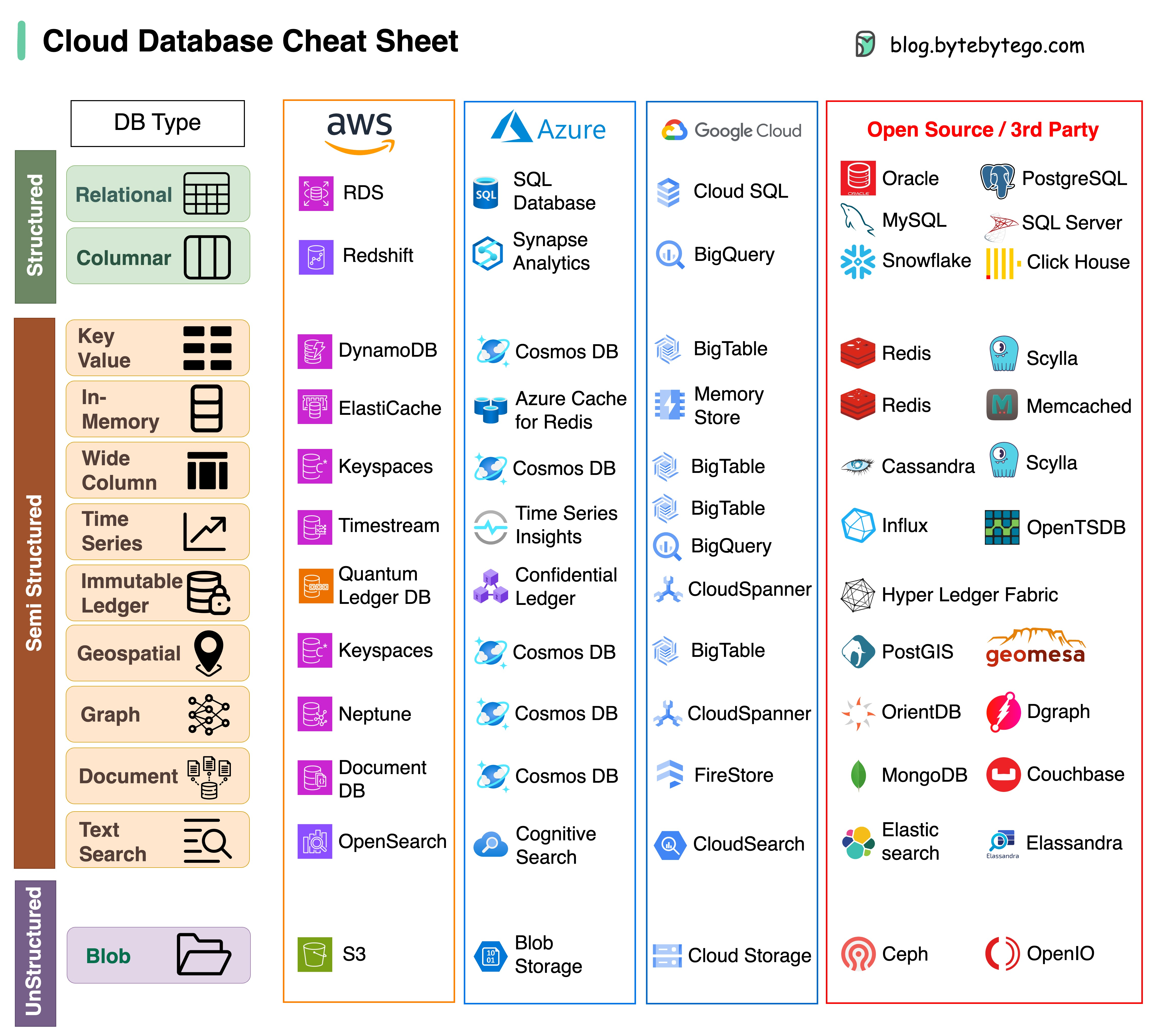
프로젝트에 적합한 데이터베이스를 선택하는 것은 복잡한 작업입니다. 각기 다른 사용 사례에 적합한 많은 데이터베이스 옵션은 결정 피로를 빠르게 초래할 수 있습니다.
이 치트 시트가 프로젝트 요구 사항에 맞는 올바른 서비스를 정확히 찾아내고 잠재적인 위험을 피할 수 있는 높은 수준의 지침을 제공하기를 바랍니다.
참고: Google은 데이터베이스 사용 사례에 대한 문서를 제한적으로 제공합니다. 사용 가능한 항목을 살펴보고 최상의 옵션에 도달하기 위해 최선을 다했지만 일부 항목은 더 정확해야 할 수도 있습니다.
대답은 사용 사례에 따라 달라집니다. 데이터는 메모리나 디스크에서 인덱싱될 수 있습니다. 마찬가지로 숫자, 문자열, 지리 좌표 등과 같은 데이터 형식도 다양합니다. 시스템은 쓰기 중심이거나 읽기 중심일 수 있습니다. 이러한 모든 요소는 데이터베이스 인덱스 형식 선택에 영향을 미칩니다.
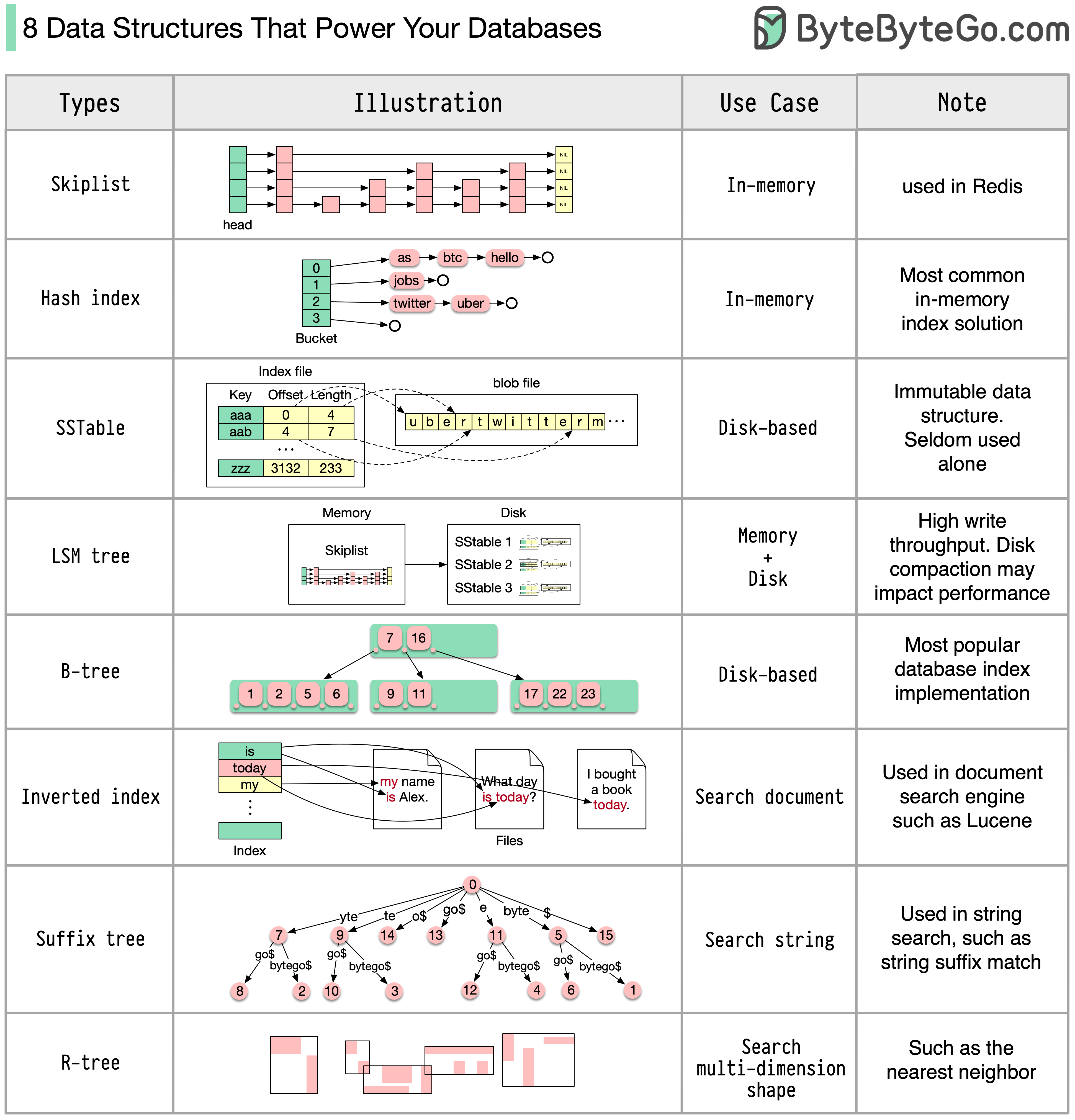
다음은 데이터 인덱싱에 사용되는 가장 널리 사용되는 데이터 구조 중 일부입니다.
아래 다이어그램은 프로세스를 보여줍니다. 데이터베이스마다 아키텍처가 다르기 때문에 다이어그램에서는 몇 가지 일반적인 디자인을 보여줍니다.
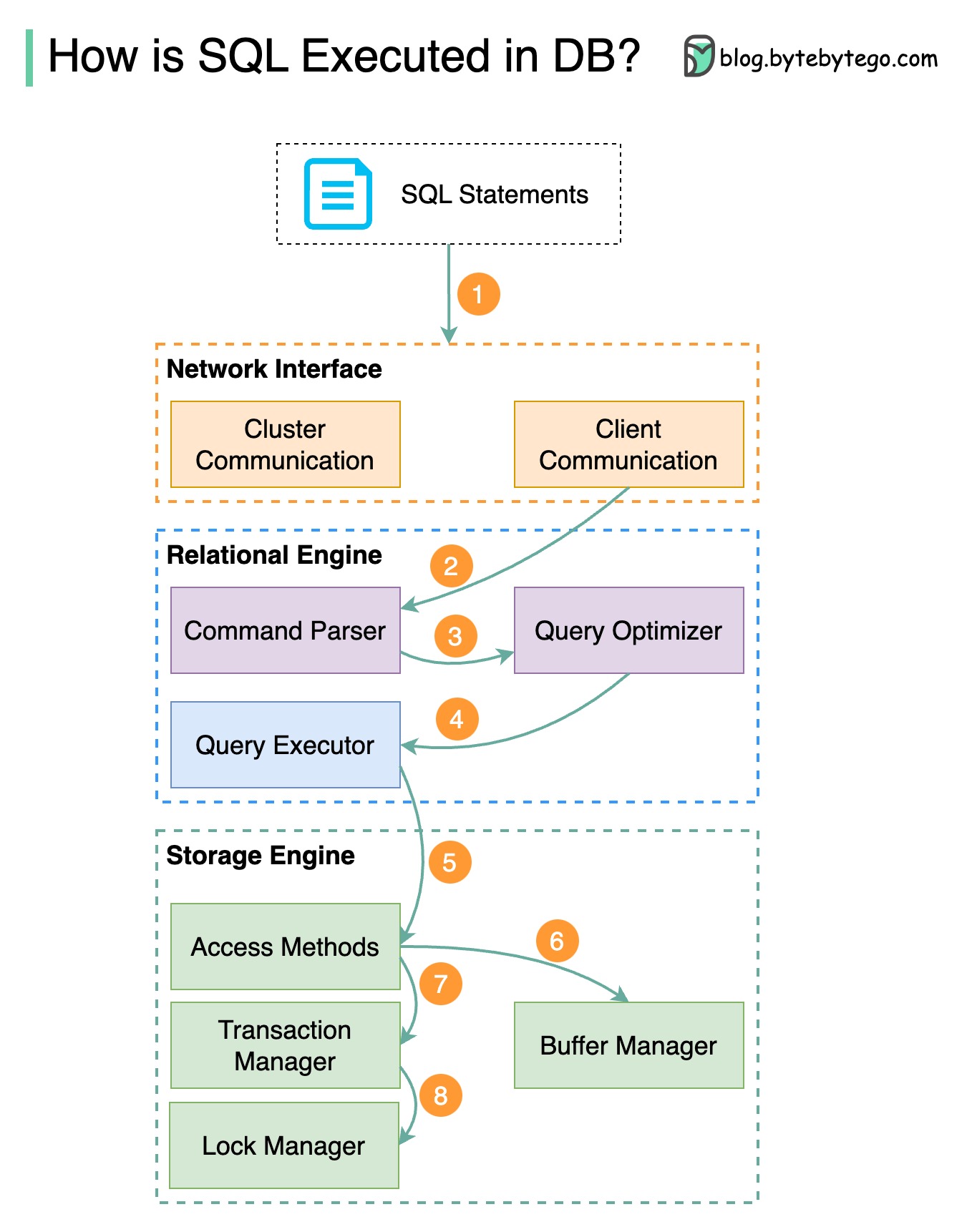
1단계 - SQL 문은 전송 계층 프로토콜(예: TCP)을 통해 데이터베이스로 전송됩니다.
2단계 - SQL 문은 명령 구문 분석기로 전송되어 구문 및 의미 분석을 거치며 나중에 쿼리 트리가 생성됩니다.
3단계 - 쿼리 트리가 최적화 프로그램으로 전송됩니다. 옵티마이저는 실행 계획을 생성합니다.
4단계 - 실행 계획이 실행자에게 전송됩니다. 실행자는 실행에서 데이터를 검색합니다.
5단계 - 액세스 방법은 실행에 필요한 데이터 가져오기 논리를 제공하고 스토리지 엔진에서 데이터를 검색합니다.
6단계 - 액세스 방법은 SQL 문이 읽기 전용인지 여부를 결정합니다. 쿼리가 읽기 전용(SELECT 문)인 경우 추가 처리를 위해 버퍼 관리자로 전달됩니다. 버퍼 관리자는 캐시나 데이터 파일에서 데이터를 찾습니다.
7단계 - 문이 UPDATE 또는 INSERT인 경우 추가 처리를 위해 트랜잭션 관리자로 전달됩니다.
8단계 - 트랜잭션 중에 데이터는 잠금 모드에 있습니다. 이는 잠금 관리자에 의해 보장됩니다. 또한 트랜잭션의 ACID 속성을 보장합니다.
CAP 정리는 컴퓨터 과학에서 가장 유명한 용어 중 하나이지만, 개발자마다 이해하는 방식이 다를 것이라고 확신합니다. 그것이 무엇인지, 왜 혼란스러울 수 있는지 살펴보겠습니다.
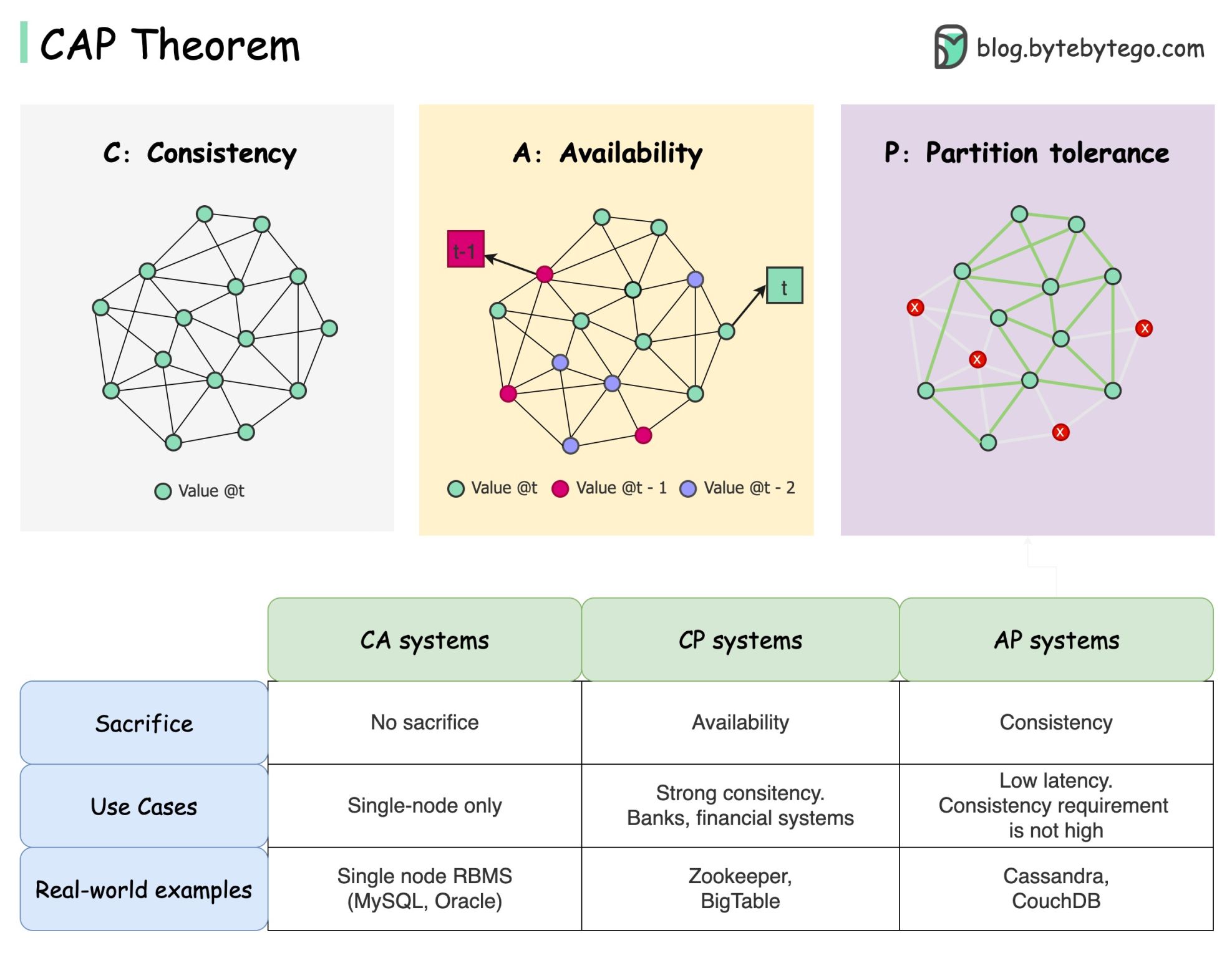
CAP 정리에 따르면 분산 시스템은 이 세 가지 보장 중 두 가지 이상을 동시에 제공할 수 없습니다.
일관성 : 일관성은 어떤 노드에 연결하든 모든 클라이언트가 동시에 동일한 데이터를 볼 수 있음을 의미합니다.
가용성(Availability ) : 가용성은 일부 노드가 다운되더라도 데이터를 요청하는 모든 클라이언트가 응답을 받는 것을 의미합니다.
파티션 허용 오차 : 파티션은 두 노드 간의 통신 중단을 나타냅니다. 파티션 허용이란 네트워크 파티션에도 불구하고 시스템이 계속 작동함을 의미합니다.
"2/3" 공식은 유용할 수 있지만 이러한 단순화는 오해의 소지가 있습니다 .
데이터베이스를 선택하는 것은 쉽지 않습니다. 순전히 CAP 정리에 기초하여 우리의 선택을 정당화하는 것만으로는 충분하지 않습니다. 예를 들어 회사에서는 단순히 AP 시스템이라는 이유만으로 채팅 애플리케이션에 Cassandra를 선택하지 않습니다. Cassandra를 채팅 메시지 저장에 바람직한 옵션으로 만드는 좋은 특성 목록이 있습니다. 우리는 더 깊이 파고들 필요가 있습니다.
"CAP는 디자인 공간의 아주 작은 부분만을 금지합니다. 즉, 드물게 파티션이 있을 때 완벽한 가용성과 일관성을 제공하는 것입니다." 논문에서 인용: CAP 12년 후: "규칙"이 어떻게 바뀌었나요?
정리는 가용성과 일관성이 약 100%라는 것입니다. 보다 현실적인 논의는 네트워크 파티션이 없을 때 대기 시간과 일관성 간의 균형을 맞추는 것입니다. 자세한 내용은 PACELC 정리를 참조하세요.
CAP 정리가 실제로 유용합니까?
나는 그것이 우리의 마음을 일련의 절충 논의에 열어주기 때문에 여전히 유용하다고 생각하지만 그것은 이야기의 일부일뿐입니다. 올바른 데이터베이스를 선택할 때 더 자세히 조사해야 합니다.
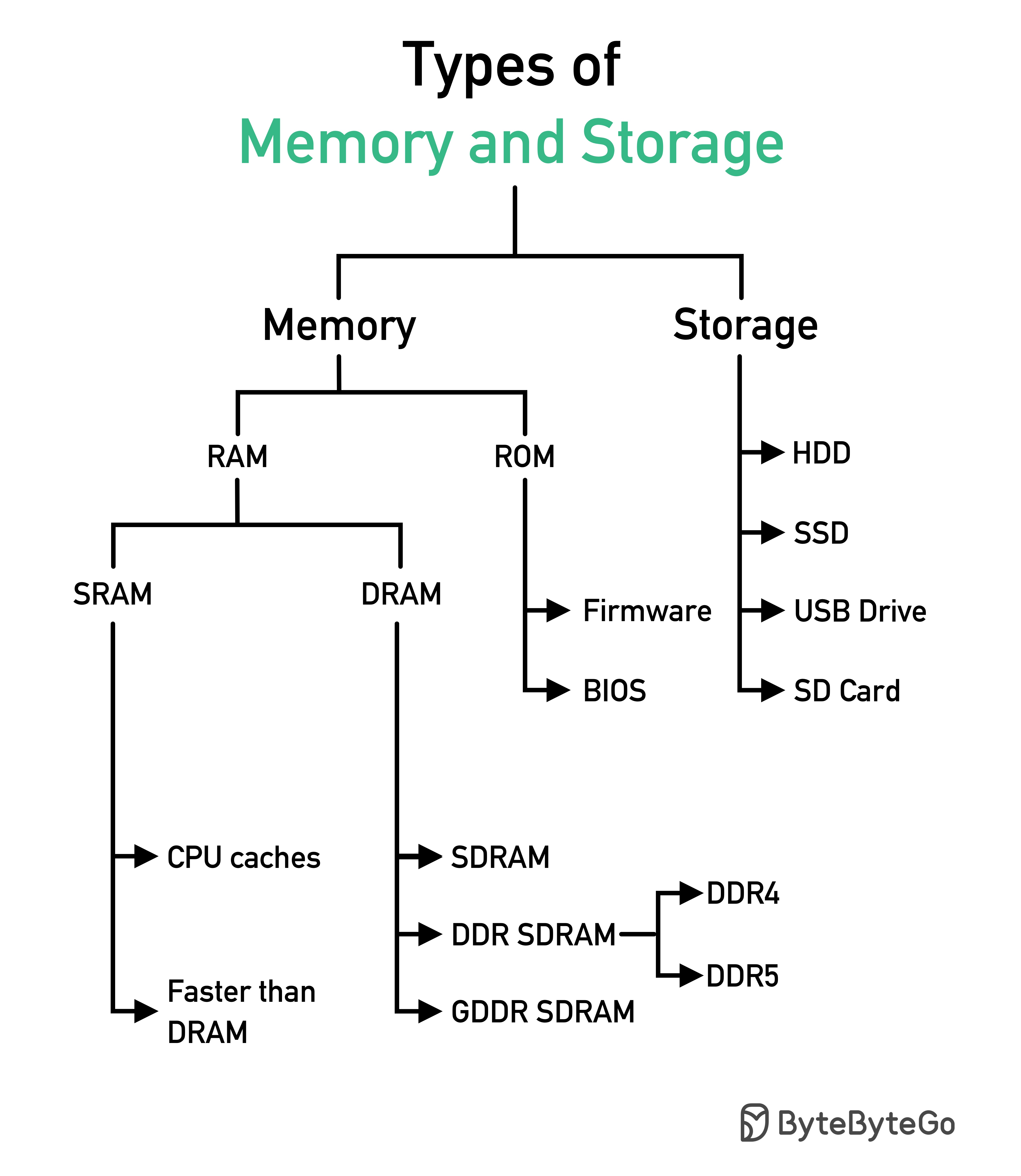
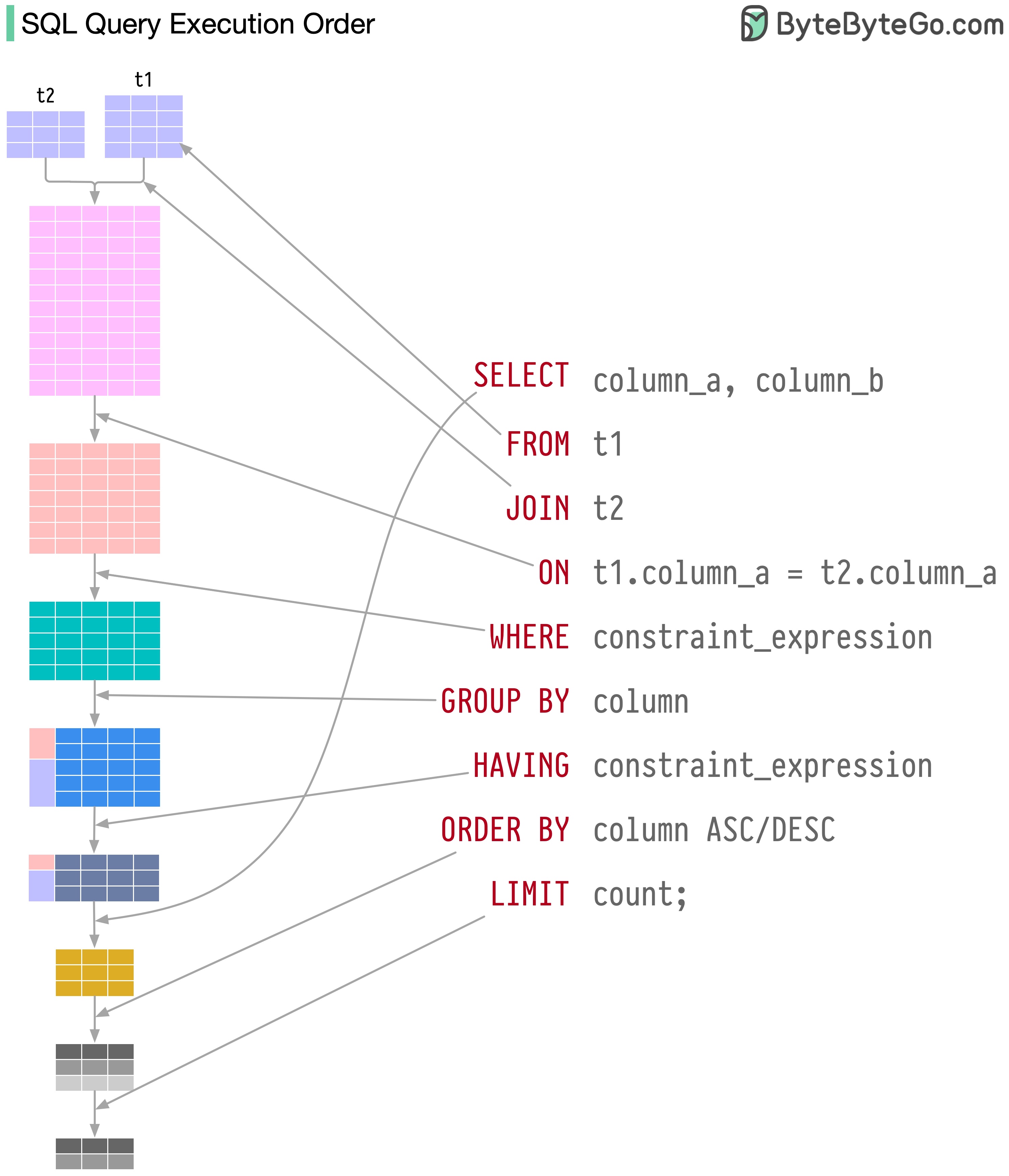
SQL 문은 다음을 포함하여 여러 단계로 데이터베이스 시스템에서 실행됩니다.
SQL 실행은 매우 복잡하며 다음과 같은 많은 고려 사항이 필요합니다.
1986년에는 SQL(Structured Query Language)이 표준이 되었습니다. 이후 40년 동안 관계형 데이터베이스 관리 시스템의 주요 언어가 되었습니다. 최신 표준(ANSI SQL 2016)을 읽는 데는 시간이 많이 걸릴 수 있습니다. 어떻게 배울 수 있나요?
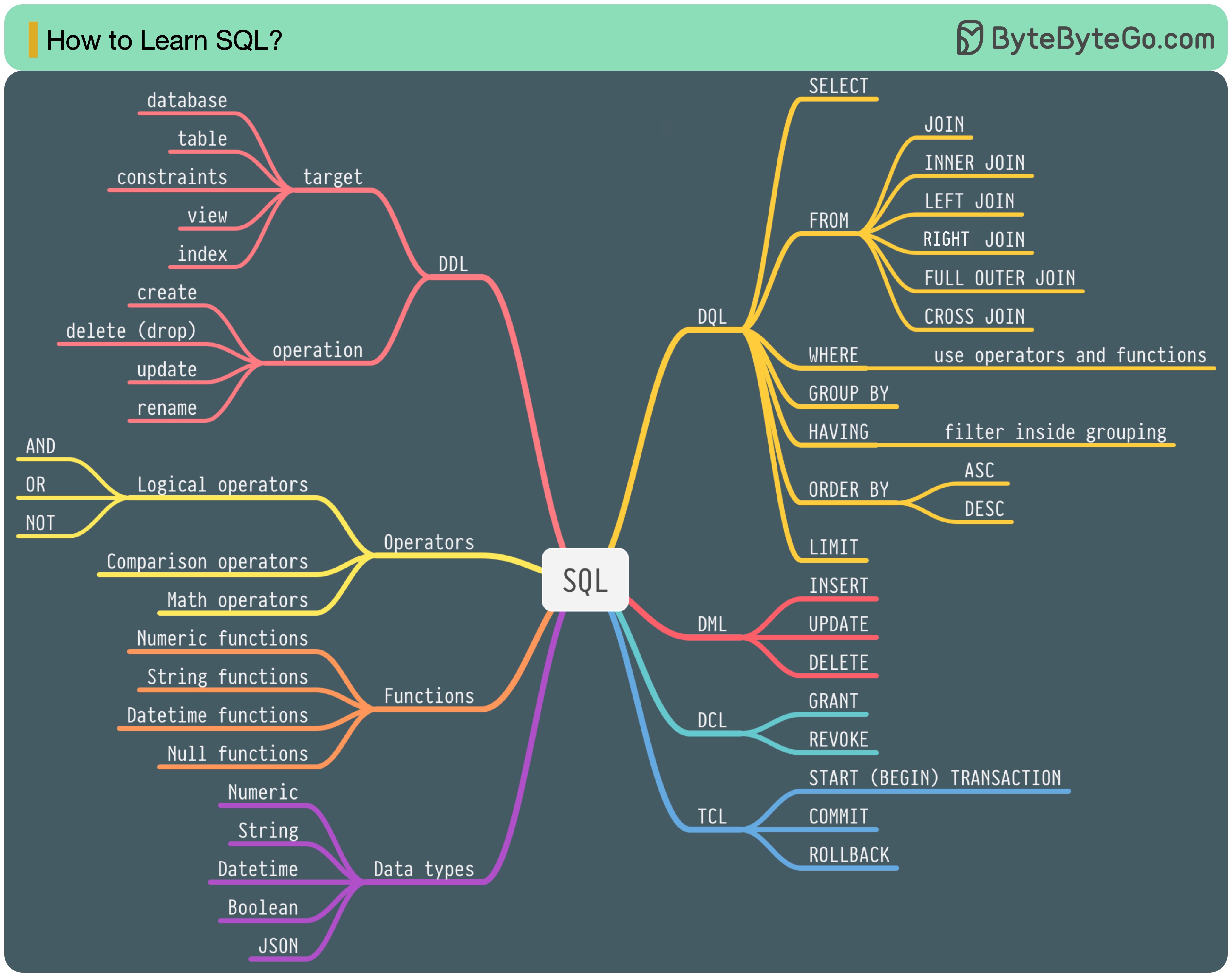
SQL 언어에는 5가지 구성 요소가 있습니다.
백엔드 엔지니어의 경우 대부분을 알아야 할 수도 있습니다. 데이터 분석가로서 DQL을 잘 이해해야 할 수도 있습니다. 귀하와 가장 관련성이 높은 주제를 선택하십시오.
이 다이어그램은 일반적인 아키텍처에서 데이터를 캐시하는 위치를 보여줍니다.
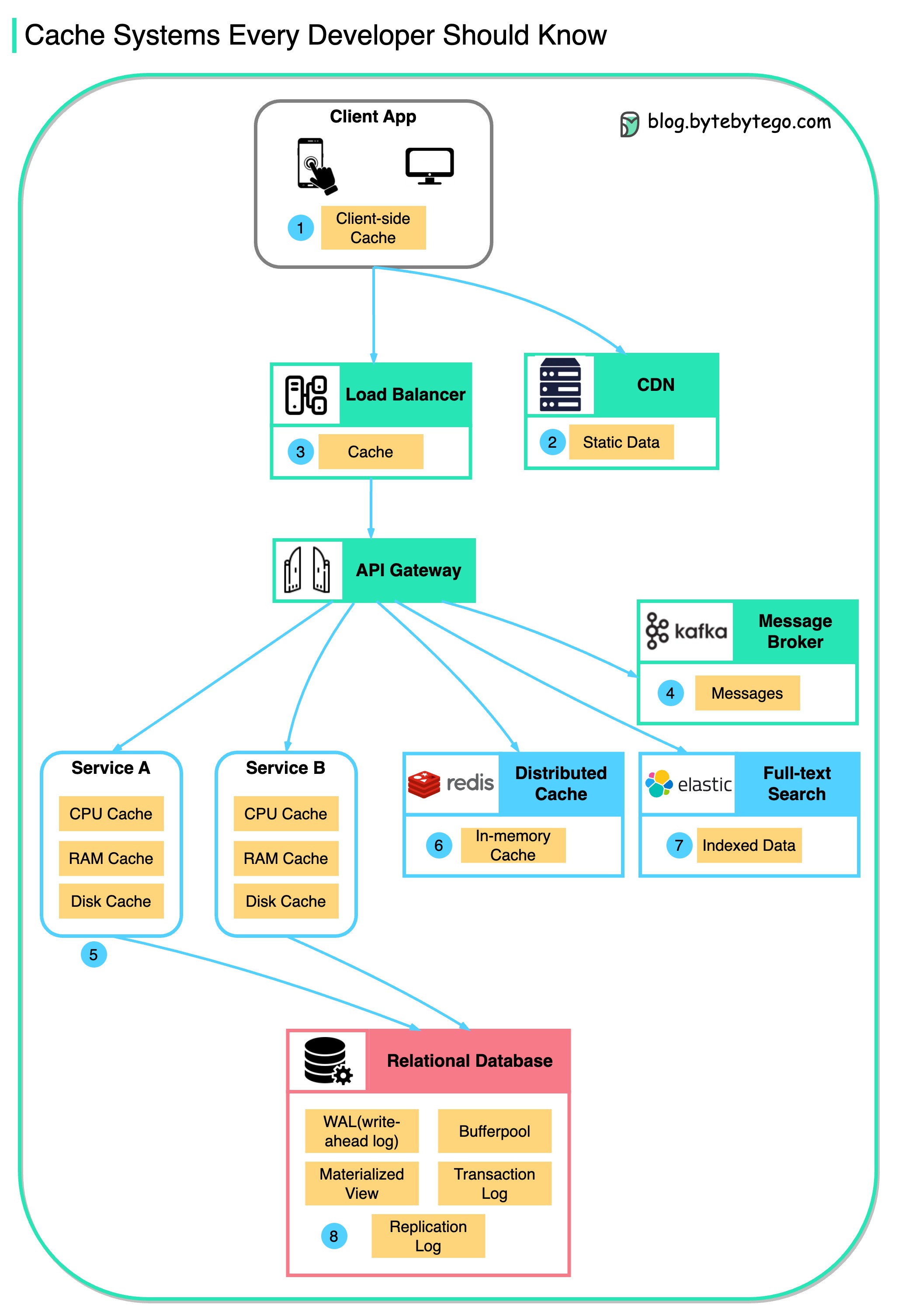
흐름에는 여러 레이어가 있습니다.
아래 그림과 같이 크게 3가지 이유가 있습니다.
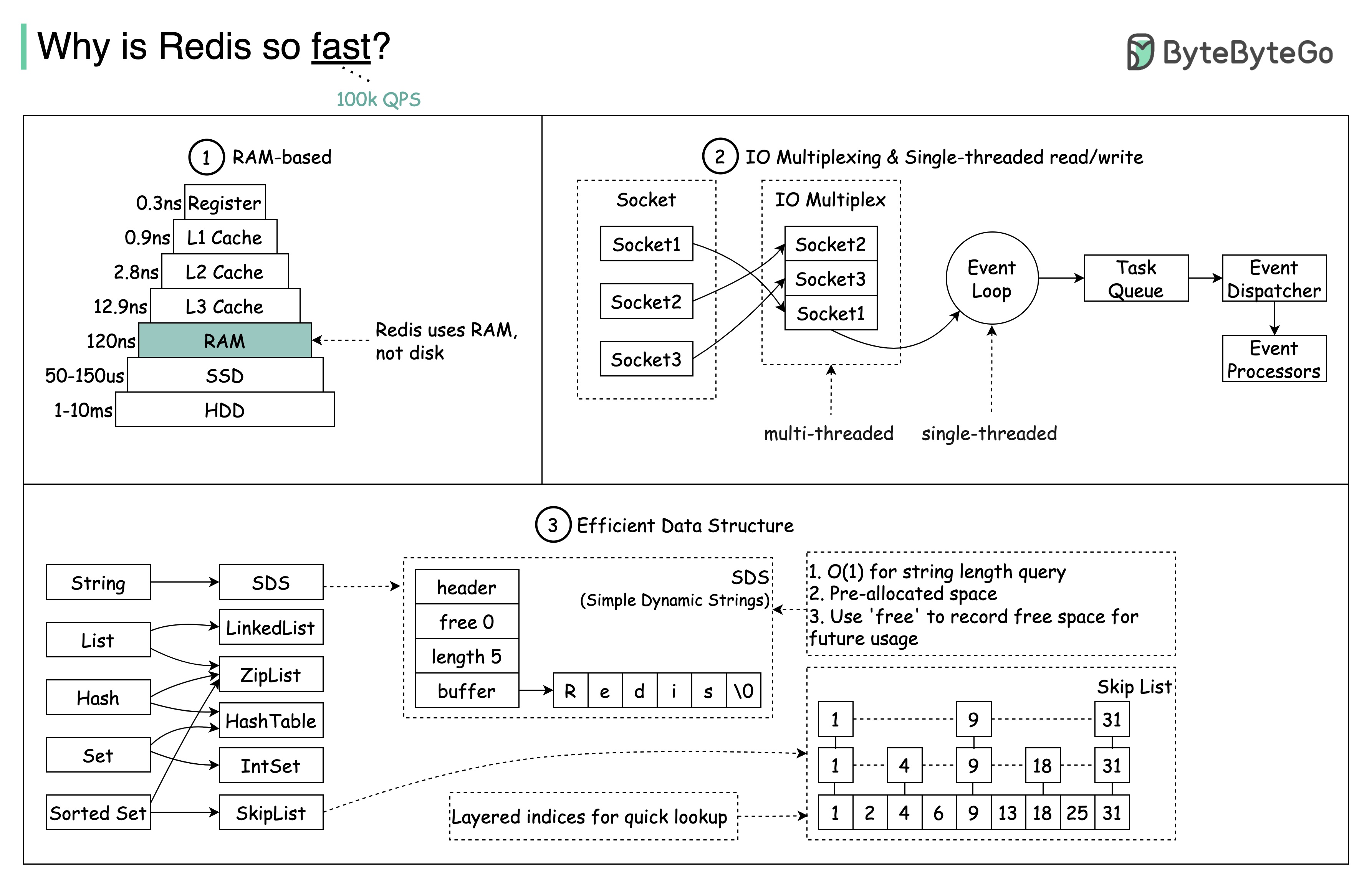
질문: 또 다른 인기 있는 메모리 내 저장소는 Memcached입니다. Redis와 Memcached의 차이점을 알고 계십니까?
이 다이어그램의 스타일이 이전 게시물과 다르다는 것을 알았을 것입니다. 어떤 것을 선호하는지 알려주세요.
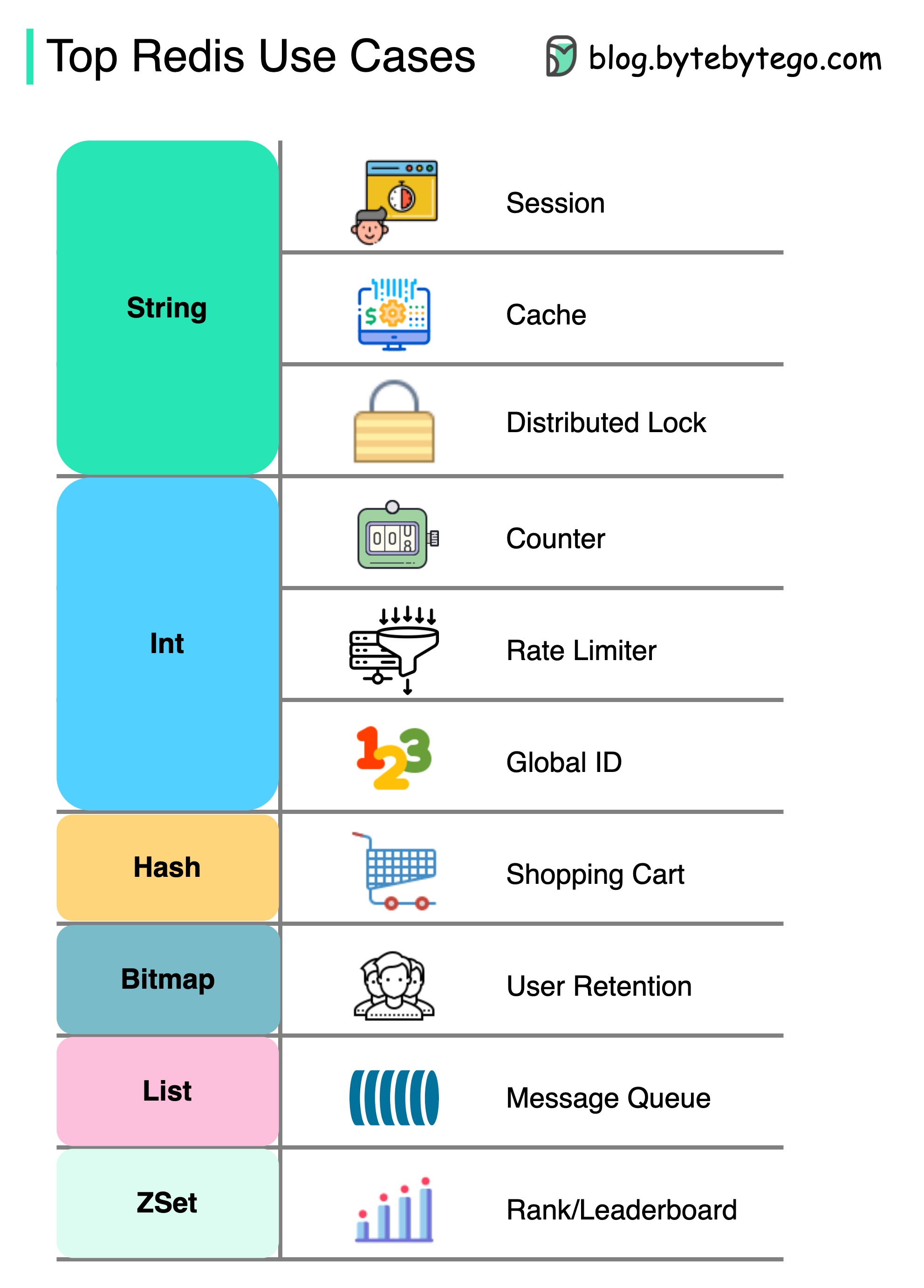
캐싱보다 레 디스에는 더 많은 것이 있습니다.
Redis는 다이어그램과 같이 다양한 시나리오에서 사용할 수 있습니다.
세션
Redis를 사용하여 다른 서비스간에 사용자 세션 데이터를 공유 할 수 있습니다.
은닉처
Redis를 사용하여 객체 나 페이지, 특히 핫스팟 데이터를 캐시 할 수 있습니다.
분산 잠금
Redis String을 사용하여 분산 서비스 중 자물쇠를 얻을 수 있습니다.
계수기
우리는 기사를 얼마나 좋아하는지 또는 얼마나 많은 독서를 읽을 수 있습니다.
속도 제한기
특정 사용자 IPS에 대한 속도 리미터를 적용 할 수 있습니다.
글로벌 ID 생성기
Global ID에는 Redis Int를 사용할 수 있습니다.
장바구니
우리는 Redis Hash를 사용하여 쇼핑 카트에서 키 값 쌍을 나타낼 수 있습니다.
사용자 유지를 계산합니다
BitMap을 사용하여 사용자 로그인을 매일 나타내고 사용자 유지를 계산할 수 있습니다.
메시지 대기열
메시지 대기열에 목록을 사용할 수 있습니다.
순위
ZSET을 사용하여 기사를 정렬 할 수 있습니다.
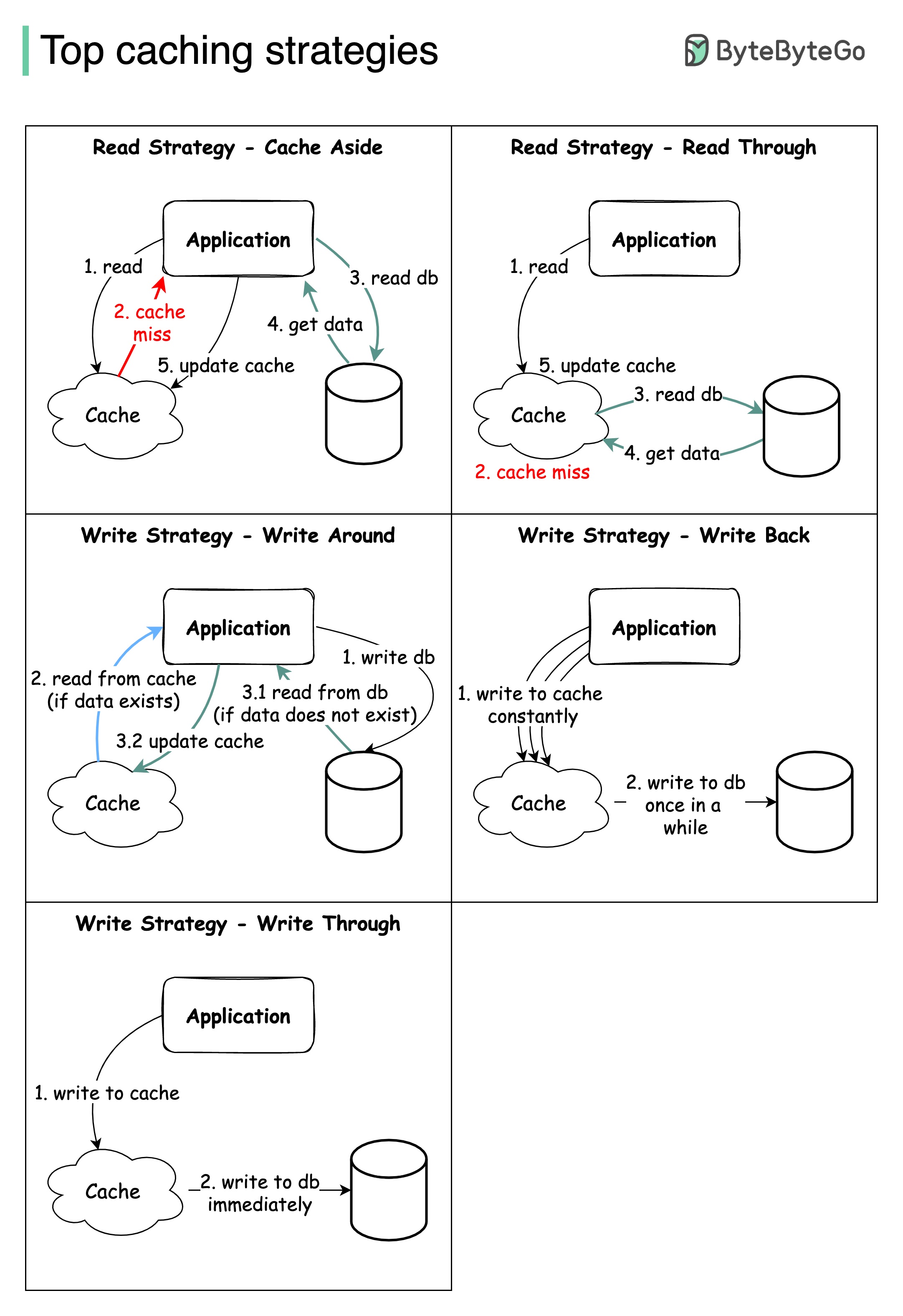
대규모 시스템을 설계하려면 일반적으로 캐싱을 신중하게 고려해야합니다. 다음은 자주 활용되는 5 가지 캐싱 전략입니다.
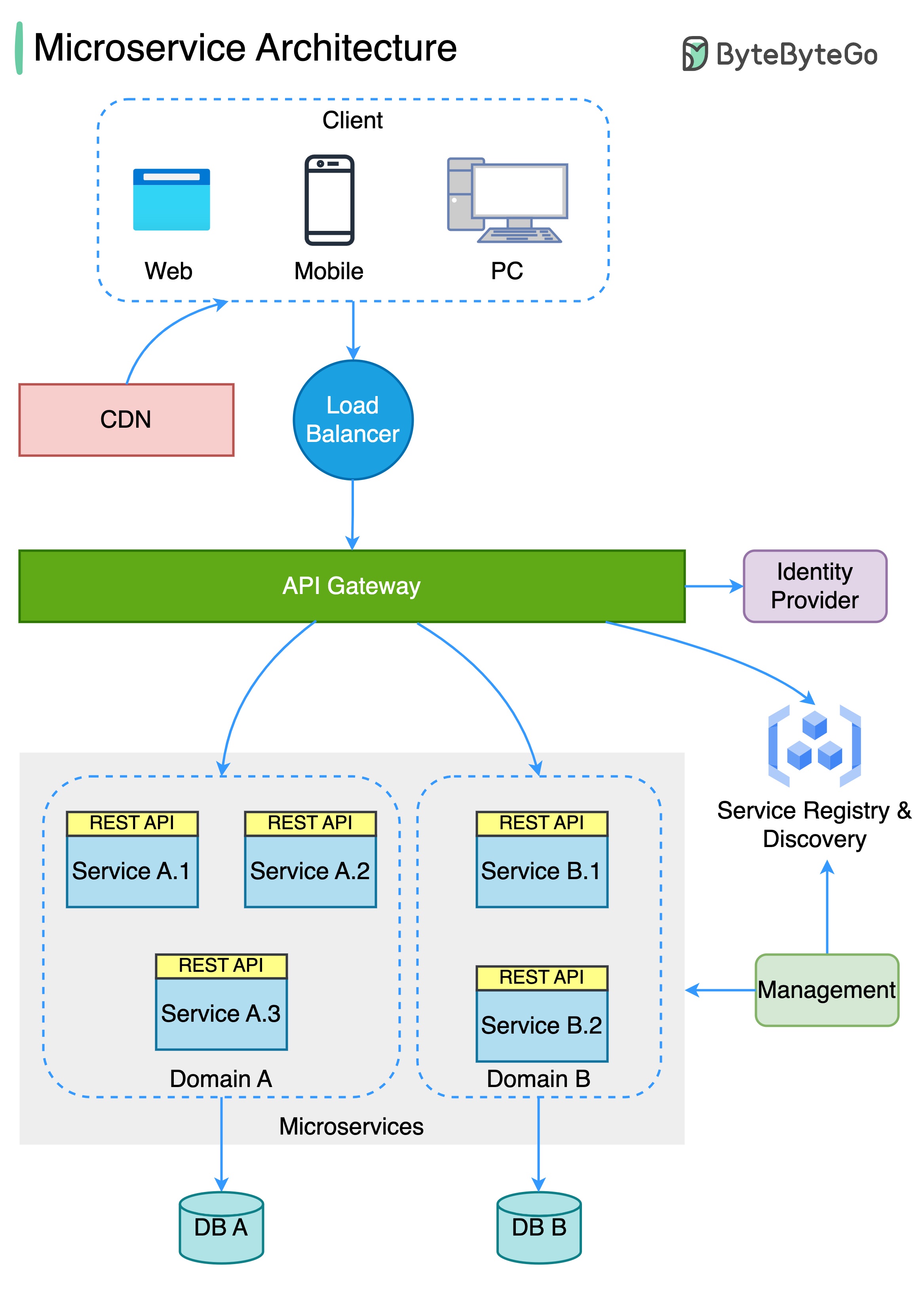
아래 다이어그램은 일반적인 마이크로 서비스 아키텍처를 보여줍니다.
마이크로 서비스의 이점 :
그림은 천 단어의 가치가 있습니다 : 9 마이크로 서비스 개발을위한 9 가지 모범 사례.
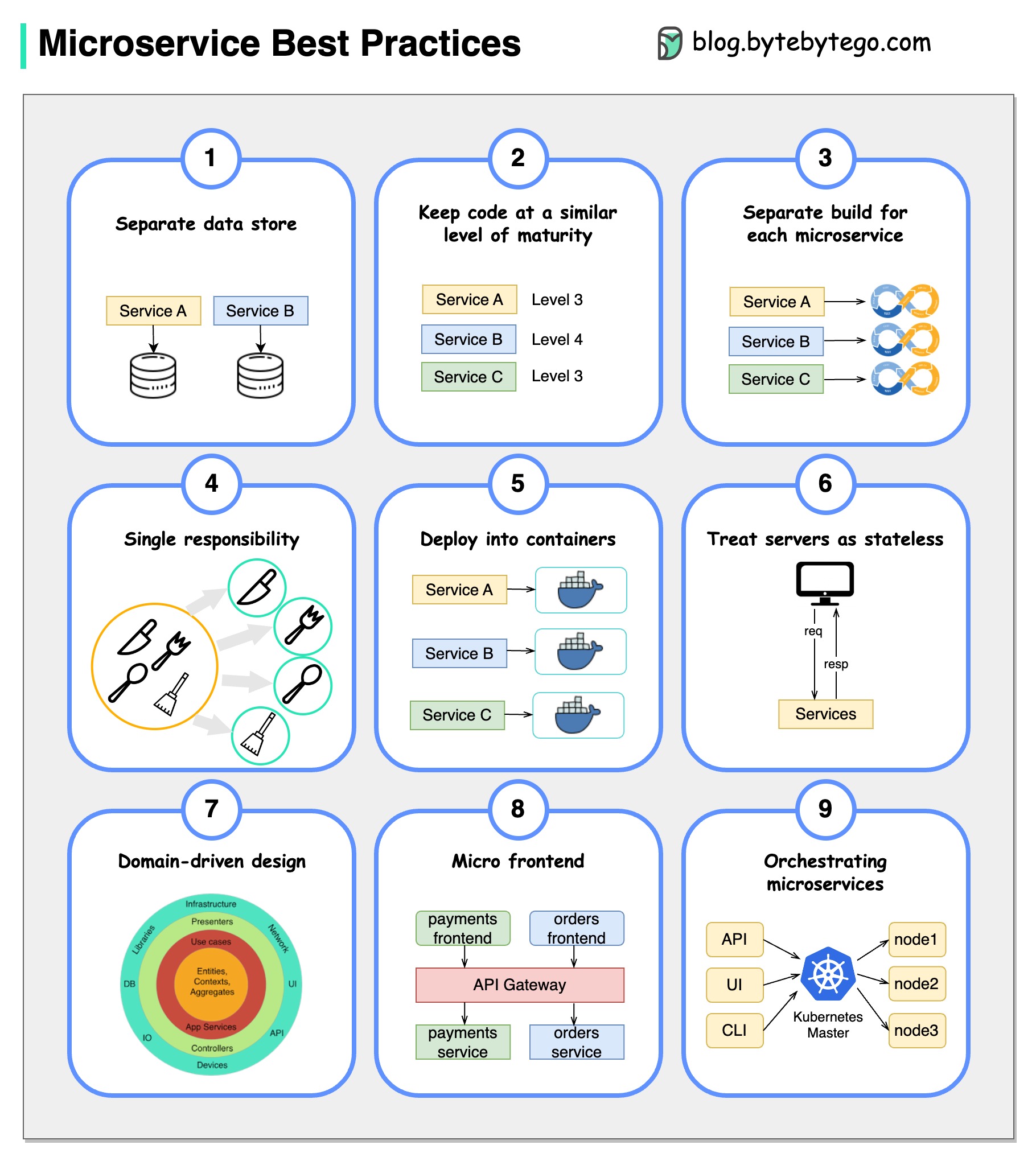
마이크로 서비스를 개발할 때 다음 모범 사례를 따라야합니다.
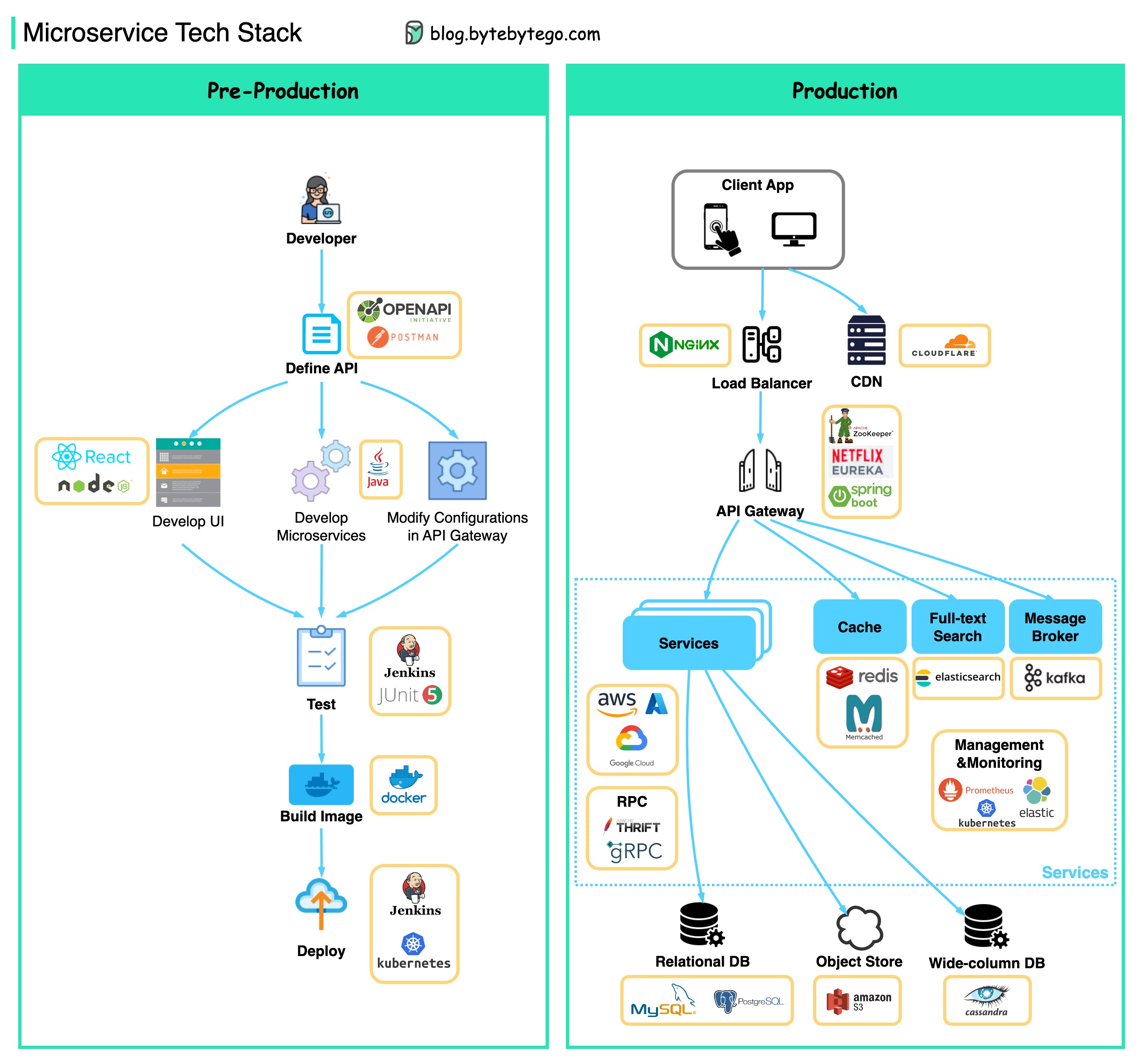
아래에는 개발 단계와 생산에 대한 마이크로 서비스 기술 스택을 보여주는 다이어그램이 있습니다.
Kafka의 성능에 기여한 많은 설계 결정이 있습니다. 이 게시물에서는 두 가지에 중점을 둡니다. 우리는이 두 사람이 가장 큰 체중을 가지고 있다고 생각합니다.
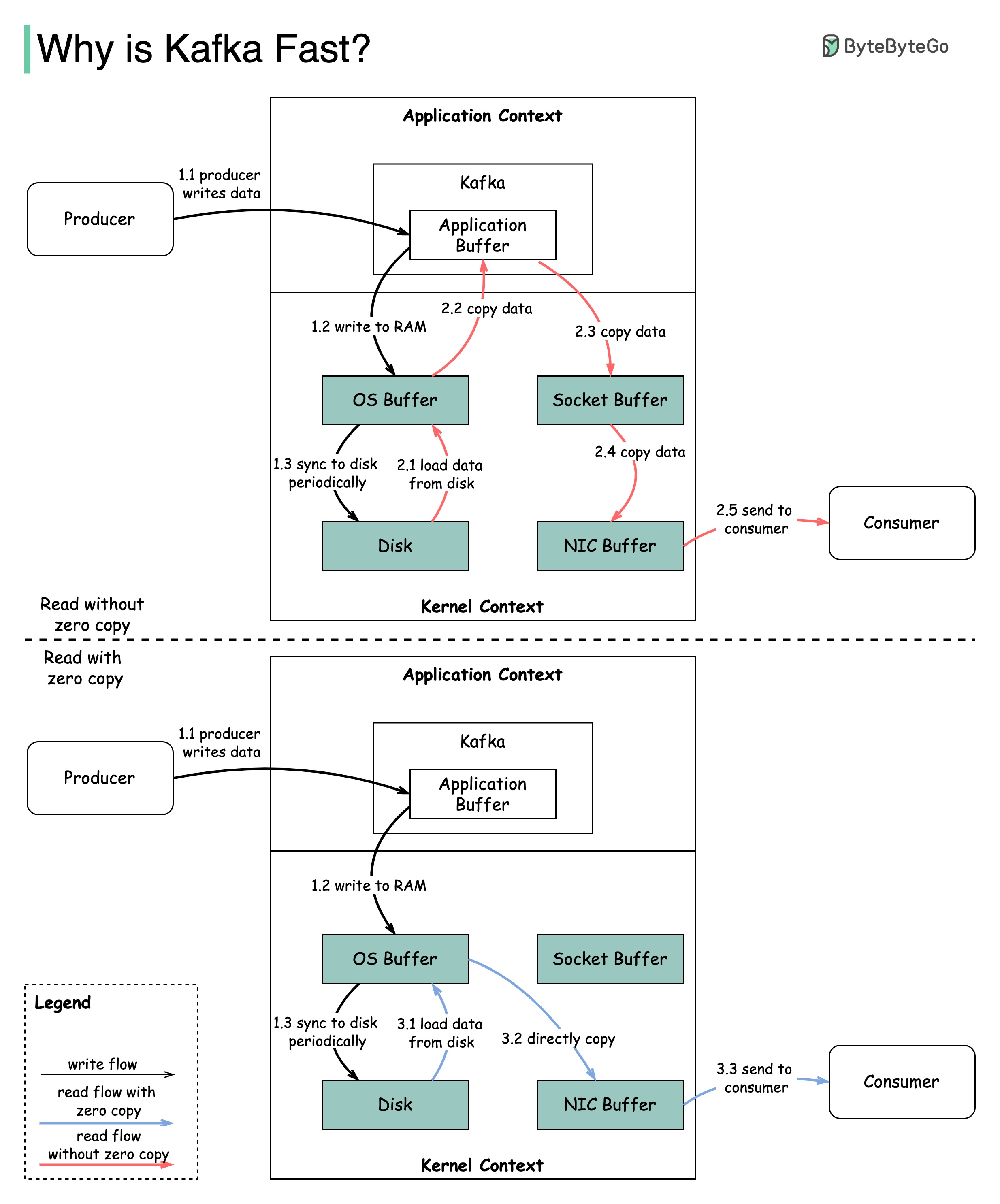
이 다이어그램은 생산자와 소비자 사이에 데이터가 어떻게 전송되는지, 그리고 제로 카피의 의미를 보여줍니다.
2.1 데이터는 디스크에서 OS 캐시로로드됩니다.
2.2 데이터는 OS 캐시에서 Kafka 응용 프로그램으로 복사됩니다.
2.3 Kafka 응용 프로그램은 데이터를 소켓 버퍼에 복사합니다.
2.4 데이터는 소켓 버퍼에서 네트워크 카드로 복사됩니다.
2.5 네트워크 카드는 데이터를 소비자에게 보냅니다.
3.1 : 데이터가 디스크에서 OS 캐시로로드됩니다.
제로 사본은 응용 프로그램 컨텍스트와 커널 컨텍스트 사이에 여러 데이터 사본을 저장하는 바로 가기입니다.
아래 다이어그램은 신용 카드 결제 흐름의 경제성을 보여줍니다.
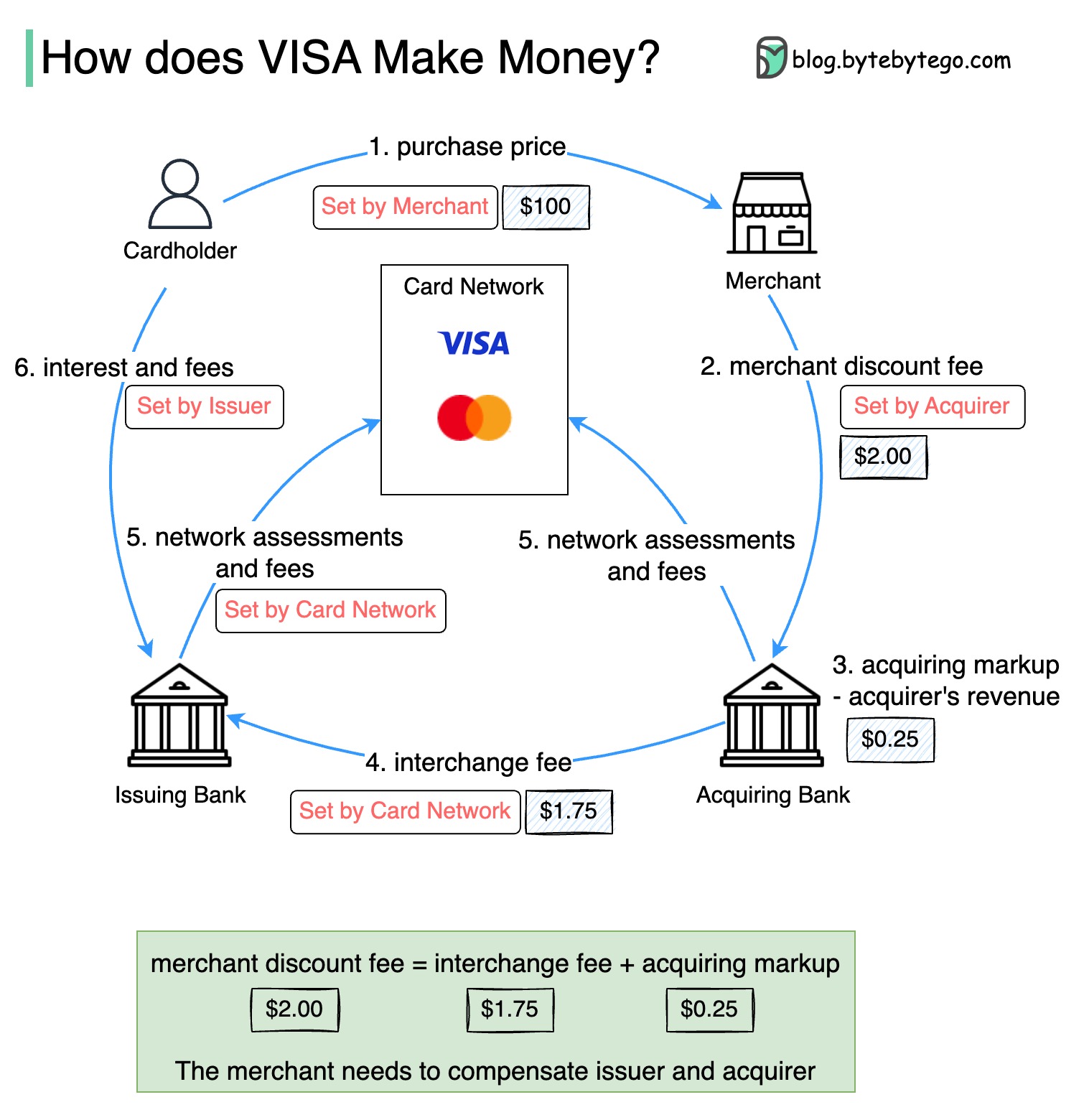
1. 카드 소지자는 제품을 구매하기 위해 판매자에게 $ 100를 지불합니다.
2. 판매량이 높은 신용 카드 사용으로 인한 상인은 지불 서비스를 제공하기 위해 발행자와 카드 네트워크를 보상해야합니다. 인수 은행은 가맹점과“판매자 할인 수수료”라고 불리는 수수료를 설정합니다.
3-4. 인수 은행은 인수 마크 업으로 $ 0.25를 유지하고, $ 1.75는 발급 은행에 교환 수수료로 지불됩니다. 가맹점 할인 수수료는 교환 수수료를 충당해야합니다.
인터체인지 수수료는 각 발행 은행이 각 판매자와의 수수료를 협상하는 데 덜 효율적이기 때문에 카드 네트워크에 의해 설정됩니다.
5. 카드 네트워크는 각 은행에 네트워크 평가 및 수수료를 설정하여 매달 서비스에 대한 카드 네트워크를 지불합니다. 예를 들어, 비자는 스 와이프마다 0.11% 평가와 $ 0.0195의 사용 수수료를 청구합니다.
6. 카드 소지자는 서비스에 대해 발행 은행에 지불합니다.
발행 은행을 보상 해야하는 이유는 무엇입니까?
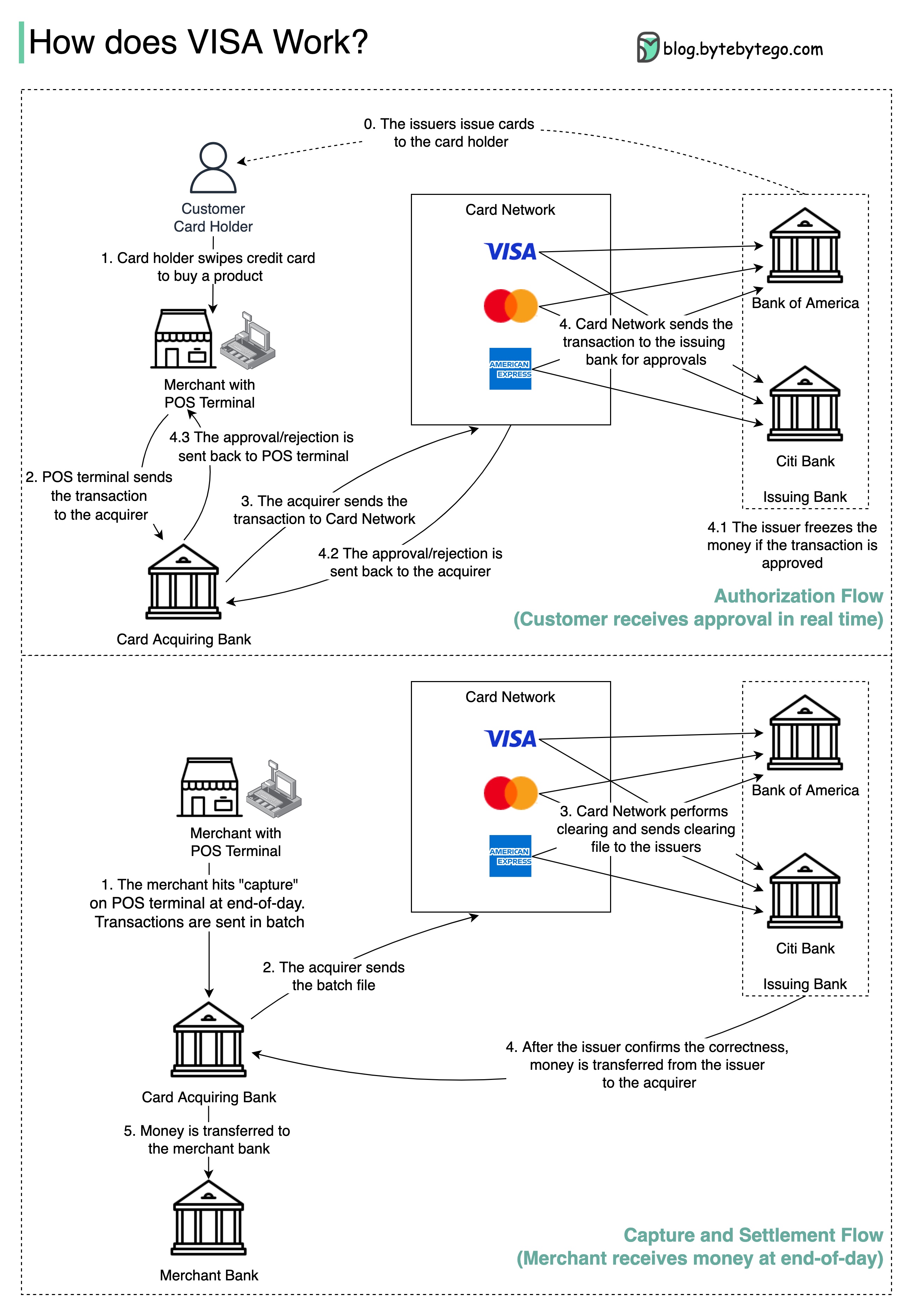
Visa, MasterCard 및 American Express는 자금 청산 및 정산을위한 카드 네트워크 역할을합니다. 은행 인수 카드와 카드 발급 은행은 종종 다를 수 있습니다. 은행이 중개자없이 거래를 하나씩 정산 해야하는 경우, 각 은행은 다른 모든 은행과 거래를 해결해야합니다. 이것은 매우 비효율적입니다.
아래 다이어그램은 신용 카드 결제 프로세스에서 비자의 역할을 보여줍니다. 두 가지 흐름이 관련되어 있습니다. 승인 흐름은 고객이 신용 카드를 스 와이프 할 때 발생합니다. 체포 및 정착 흐름은 상인이 하루가 끝날 때 돈을 받기를 원할 때 발생합니다.
단계 0 : 은행 발행 카드는 신용 카드를 고객에게 발행합니다.
1 단계 : 카드 소지자는 상인의 상점에서 제품을 구매하고 판매 시점 (POS) 터미널에서 신용 카드를 스 와이프합니다.
2 단계 : POS 터미널은 POS 터미널을 제공 한 인수 은행으로 거래를 보냅니다.
3 단계 및 4 단계 : 인수 은행은 트랜잭션을 카드 네트워크로, 카드 체계라고도합니다. 카드 네트워크는 승인을 위해 거래를 발행 은행으로 보냅니다.
4.1, 4.2 및 4.3 단계 : 발행 은행은 거래가 승인되면 돈을 동결시킵니다. 승인 또는 거부는 POS 터미널뿐만 아니라 취득자에게 다시 전송됩니다.
1 단계와 2 : 상인은 하루가 끝날 때 돈을 모으기를 원합니다. 거래는 배치로 인수자에게 전송됩니다. 인수자는 트랜잭션으로 배치 파일을 카드 네트워크로 보냅니다.
3 단계 : 카드 네트워크는 다른 인수자로부터 수집 한 트랜잭션에 대한 청소를 수행하고 청산 파일을 다른 발행 은행으로 보냅니다.
4 단계 : 발행 은행은 청산 파일의 정확성을 확인하고 관련 인수 은행으로 송금합니다.
5 단계 : 인수 은행은 돈을 가맹점 은행으로 이체합니다.
4 단계 : 카드 네트워크는 다른 인수 은행의 거래를 정리합니다. 청산은 상호 상쇄 트랜잭션이 해결되는 프로세스이므로 총 트랜잭션의 수가 줄어 듭니다.
이 과정에서 카드 네트워크는 각 은행과 대화하는 부담을 받아 대가로 서비스 요금을받습니다.
UPI는 무엇입니까? UPI는 인도의 National Payments Corporation에서 개발 한 즉각적인 실시간 지불 시스템입니다.
오늘날 인도에서 디지털 소매 거래의 60%를 차지합니다.
UPI = 지불 마크 업 언어 + 상호 운용 가능한 지불에 대한 표준
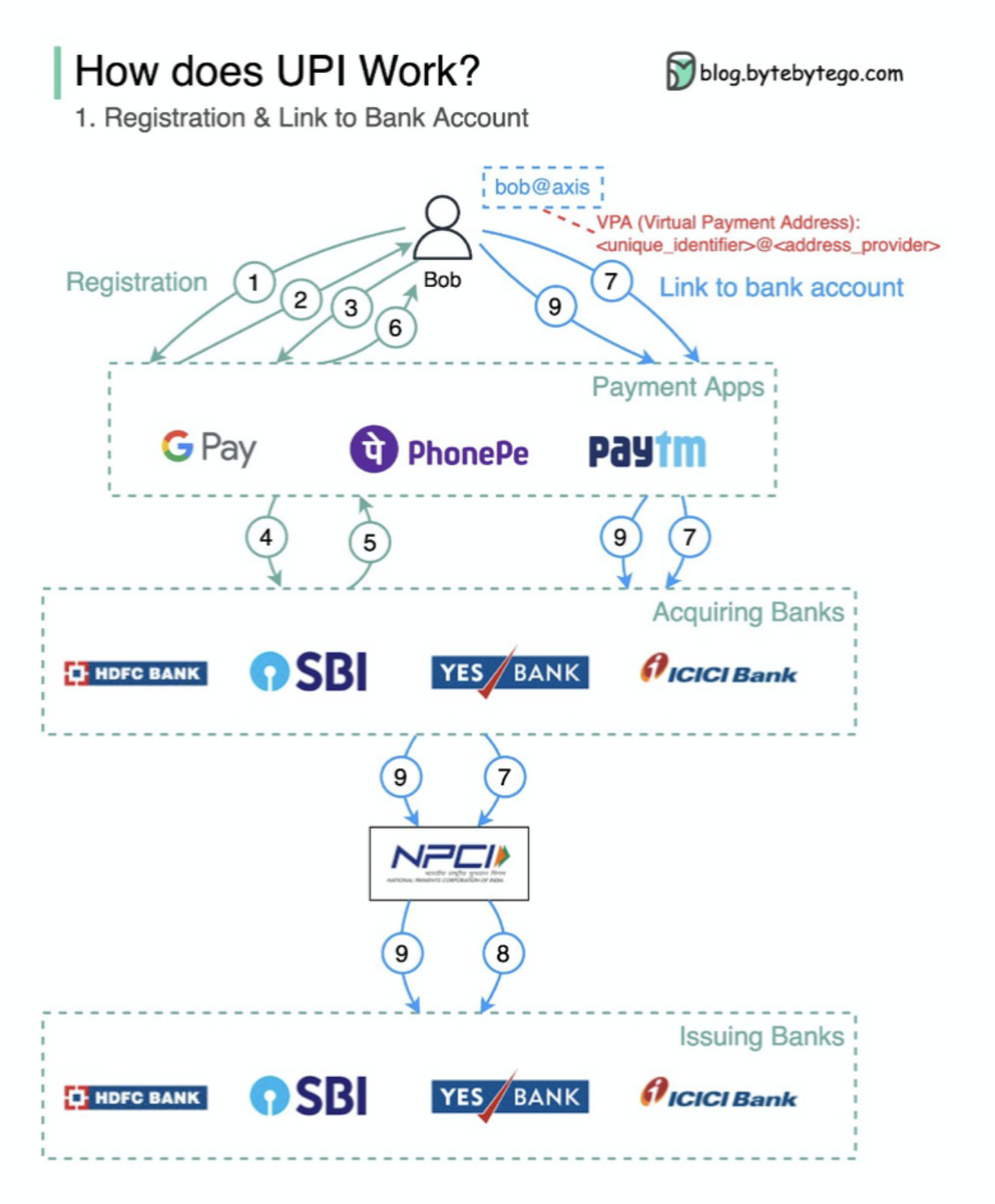
DevOps, SRE 및 플랫폼 엔지니어링의 개념은 다양한시기에 등장했으며 다양한 개인과 조직에 의해 개발되었습니다.
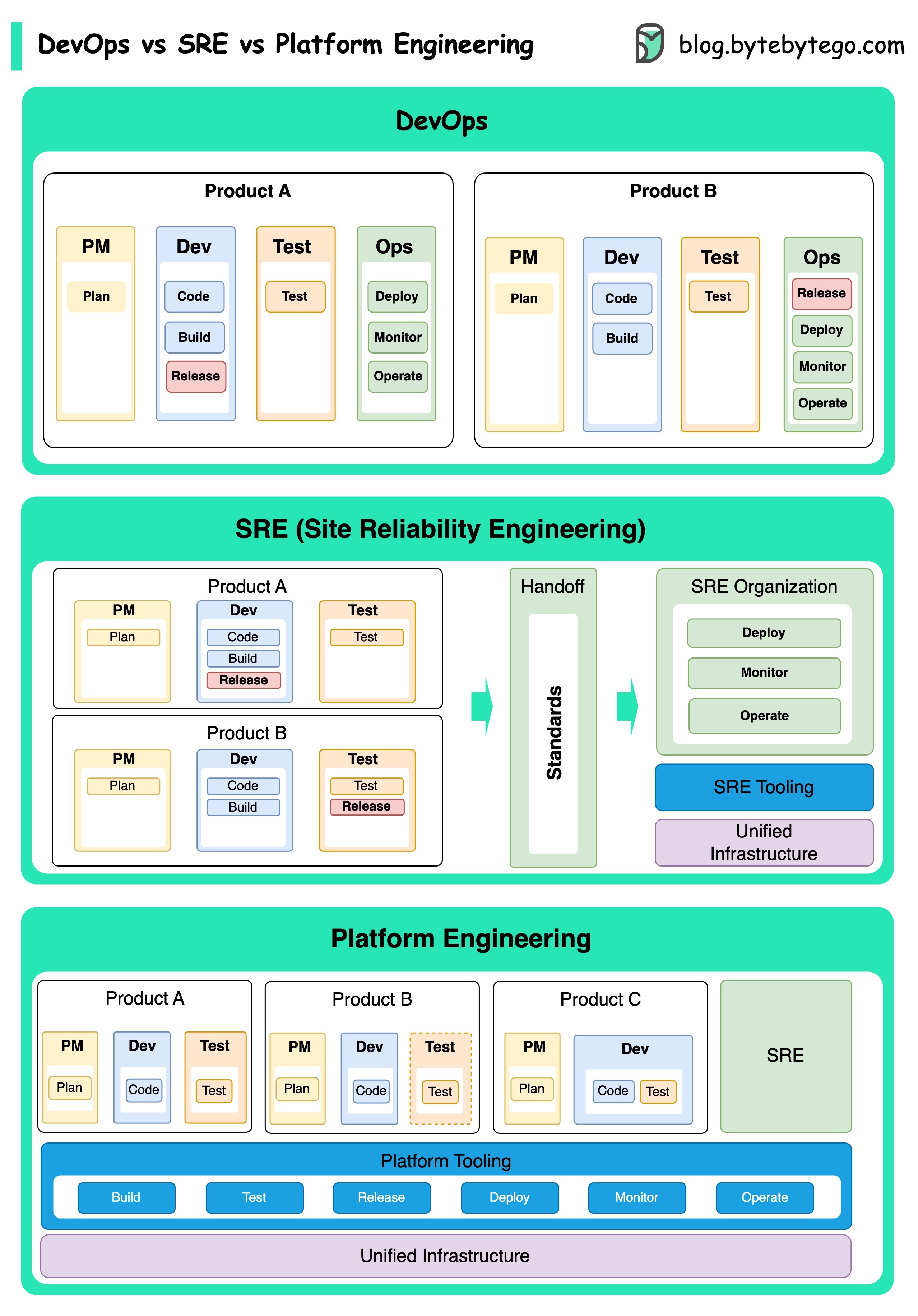
Agile Conference에서 2009 년 Patrick Debois와 Andrew Shafer가 컨셉으로 소개했습니다. 그들은 협업 문화를 홍보하고 전체 소프트웨어 개발 라이프 사이클에 대한 책임을 공유함으로써 소프트웨어 개발과 운영 사이의 격차를 해소하려고 노력했습니다.
SRE 또는 사이트 신뢰성 엔지니어링은 2000 년대 초 Google에 의해 개척하여 대규모 복잡한 시스템 관리의 운영 문제를 해결했습니다. Google은 서비스의 신뢰성과 효율성을 향상시키기 위해 BORG 클러스터 관리 시스템 및 Monarch Monitoring System과 같은 SRE 관행 및 도구를 개발했습니다.
플랫폼 엔지니어링은 SRE 엔지니어링의 기초를 구축하는 가장 최근의 개념입니다. 플랫폼 엔지니어링의 정확한 기원은 명확하지 않지만 일반적으로 전체 비즈니스 관점을 지원하는 제품 개발을위한 포괄적 인 플랫폼을 제공하는 데 중점을 둔 DevOps 및 SRE 관행의 확장으로 이해됩니다.
이러한 개념이 다른시기에 등장했지만 주목할 가치가 있습니다. 이들은 모두 소프트웨어 개발 및 운영의 협업, 자동화 및 효율성 향상의 광범위한 추세와 관련이 있습니다.
K8S는 컨테이너 오케스트레이션 시스템입니다. 컨테이너 배포 및 관리에 사용됩니다. 그 설계는 Google의 내부 시스템 Borg에 의해 크게 영향을받습니다.
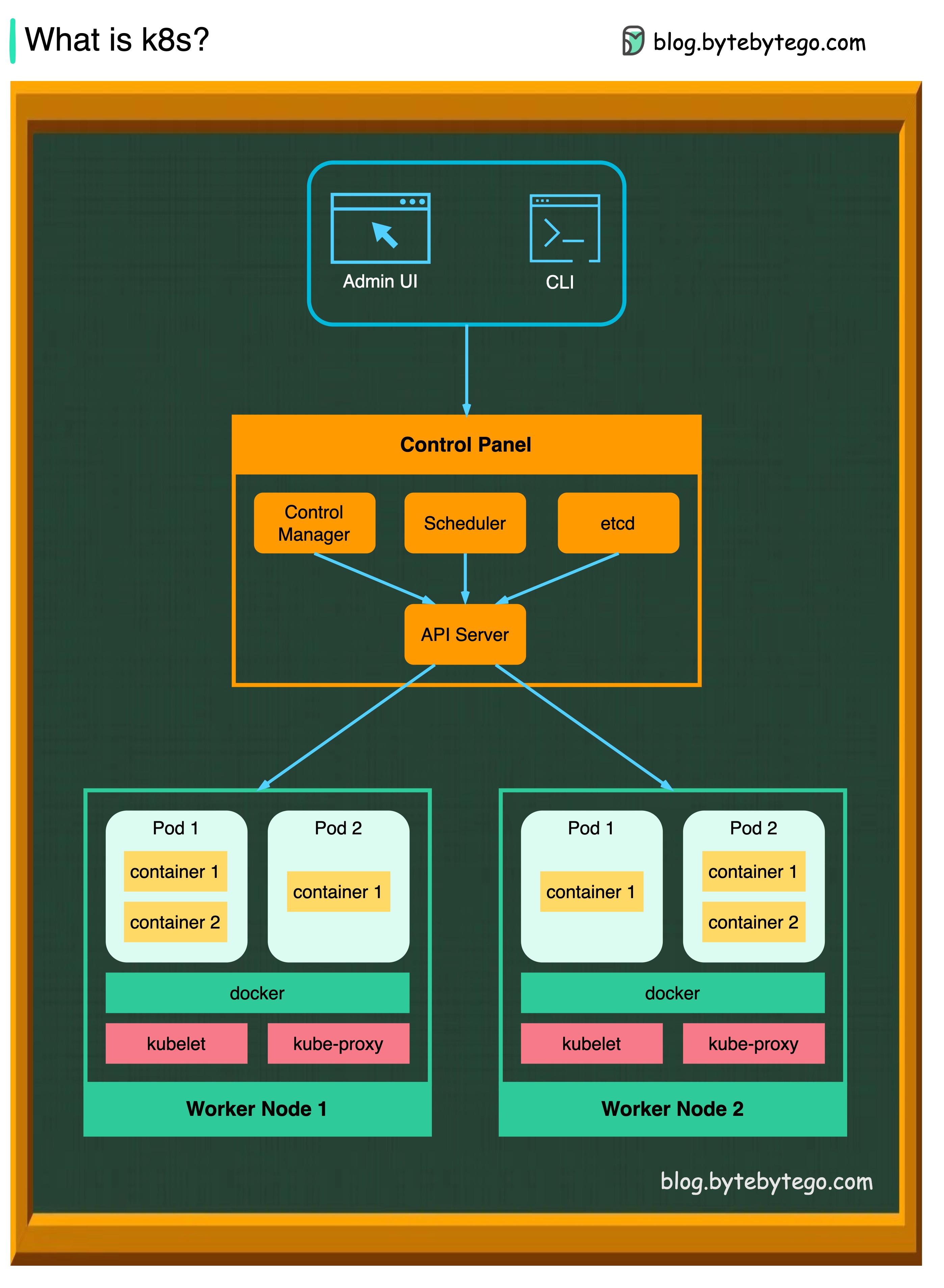
K8S 클러스터는 컨테이너화 된 응용 프로그램을 실행하는 노드라고하는 일련의 작업자 기계로 구성됩니다. 모든 클러스터에는 하나 이상의 작업자 노드가 있습니다.
작업자 노드는 응용 프로그램 워크로드의 구성 요소 인 포드를 호스팅합니다. 제어 평면은 클러스터의 작업자 노드와 포드를 관리합니다. 생산 환경에서 제어 평면은 일반적으로 여러 컴퓨터를 가로 질러 실행되며 클러스터는 일반적으로 여러 노드를 실행하여 결함 공차 및 고 가용성을 제공합니다.
API 서버
API 서버는 K8S 클러스터의 모든 구성 요소와 대화합니다. 포드의 모든 작업은 API 서버와 대화하여 실행됩니다.
스케줄러
스케줄러는 포드 워크로드를보고 새로 생성 된 포드에로드를 할당합니다.
컨트롤러 관리자
컨트롤러 관리자는 노드 컨트롤러, 작업 컨트롤러, endpointslice 컨트롤러 및 ServiceAccount 컨트롤러를 포함한 컨트롤러를 실행합니다.
etcd
ETCD는 모든 클러스터 데이터에 대한 Kubernetes의 백킹 스토어로 사용되는 키 가치 저장소입니다.
포드
포드는 컨테이너 그룹이며 K8S가 관리하는 가장 작은 장치입니다. 포드에는 포드 내의 모든 컨테이너에 단일 IP 주소가 적용됩니다.
쿠버 벨트
클러스터의 각 노드에서 실행되는 에이전트. 컨테이너가 포드로 작동하도록합니다.
Kube 프록시
Kube-Proxy는 클러스터의 각 노드에서 실행되는 네트워크 프록시입니다. 트래픽이 서비스에서 노드로 나옵니다. 작업 요청을 올바른 컨테이너로 전달합니다.

Docker는 무엇입니까?
Docker는 고립 된 컨테이너로 응용 프로그램을 패키지, 배포 및 실행할 수있는 오픈 소스 플랫폼입니다. 컨테이너화에 중점을 두어 응용 프로그램과 종속성을 캡슐화하는 가벼운 환경을 제공합니다.
Kubernetes는 무엇입니까?
K8S라고하는 Kubernetes는 오픈 소스 컨테이너 오케스트레이션 플랫폼입니다. 노드 클러스터에서 컨테이너화 된 응용 프로그램의 배포, 스케일링 및 관리를 자동화하기위한 프레임 워크를 제공합니다.
둘 다 서로 어떻게 다릅니 까?
Docker : Docker는 단일 운영 체제 호스트의 개별 컨테이너 레벨에서 운영됩니다.
각 호스트를 수동으로 관리하고 네트워크, 보안 정책을 설정하고 여러 관련 컨테이너를위한 스토리지가 복잡 할 수 있습니다.
Kubernetes : Kubernetes는 클러스터 레벨에서 작동합니다. 여러 호스트에서 여러 컨테이너화 된 응용 프로그램을 관리하여로드 밸런싱, 스케일링 및 원하는 응용 프로그램 상태를 보장하는 것과 같은 작업에 자동화를 제공합니다.
요컨대, Docker는 개별 호스트에서 컨테이너 화 및 컨테이너에 중점을두고 있으며 Kubernetes는 컨테이너를 다양한 호스트에서 규모로 관리하고 조정하는 것을 전문으로합니다.
아래 다이어그램은 Docker의 아키텍처와 "Docker Build", "Docker Pull"및 "Docker Run"을 실행할 때 작동 방식을 보여줍니다.
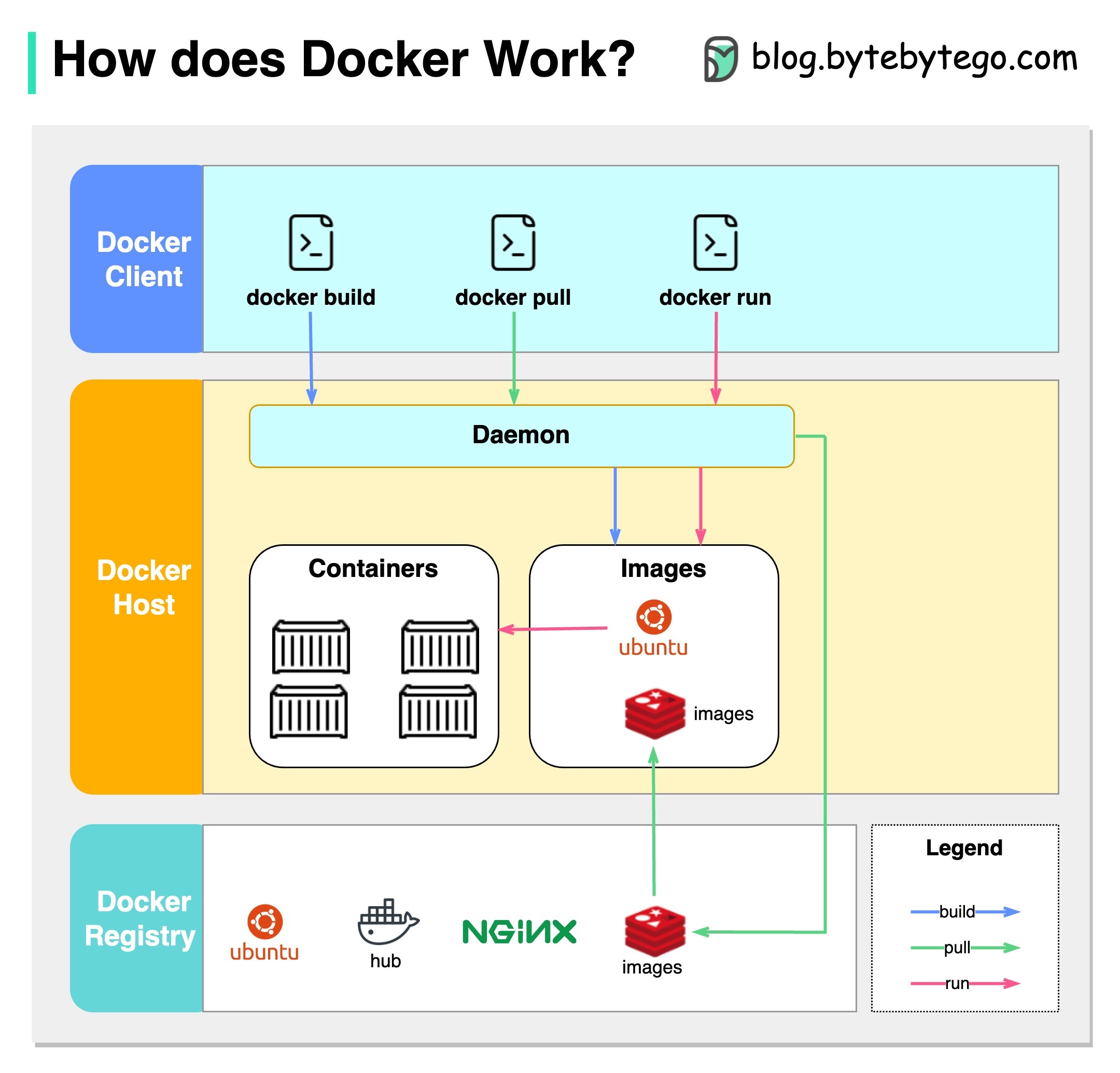
Docker Architecture에는 3 가지 구성 요소가 있습니다.
도커 클라이언트
Docker 클라이언트는 Docker Deomon과 대화합니다.
도커 호스트
Docker Deomon은 Docker API 요청 및 이미지, 컨테이너, 네트워크 및 볼륨과 같은 Docker 객체를 청소합니다.
도커 레지스트리
도커 레지스트리는 도커 이미지를 저장합니다. Docker Hub는 누구나 사용할 수있는 공개 레지스트리입니다.
"Docker Run"명령을 예로 들어합시다.
우선 코드가 저장되는 위치를 식별하는 것이 필수적입니다. 일반적인 가정은 Github와 같은 원격 서버에 있고 다른 하나는 로컬 컴퓨터에있는 두 위치 만 있다는 것입니다. 그러나 이것은 완전히 정확하지 않습니다. GIT는 우리 기계에 3 개의 로컬 스토리지를 유지 관리하므로 코드는 4 곳에서 찾을 수 있음을 의미합니다.
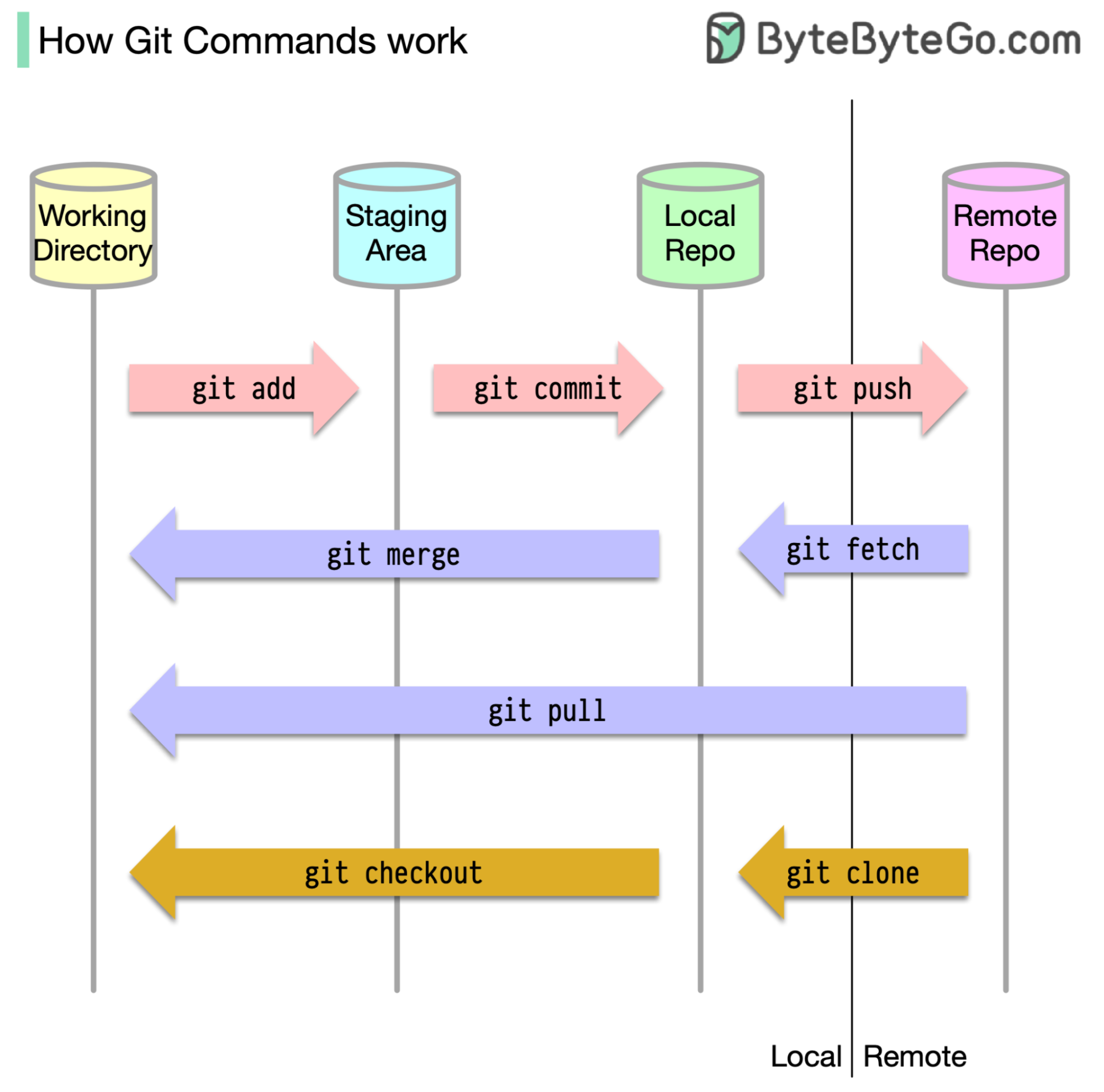
대부분의 git 명령은 주로이 네 위치 사이에서 파일을 이동합니다.
아래 다이어그램은 git 워크 플로를 보여줍니다.
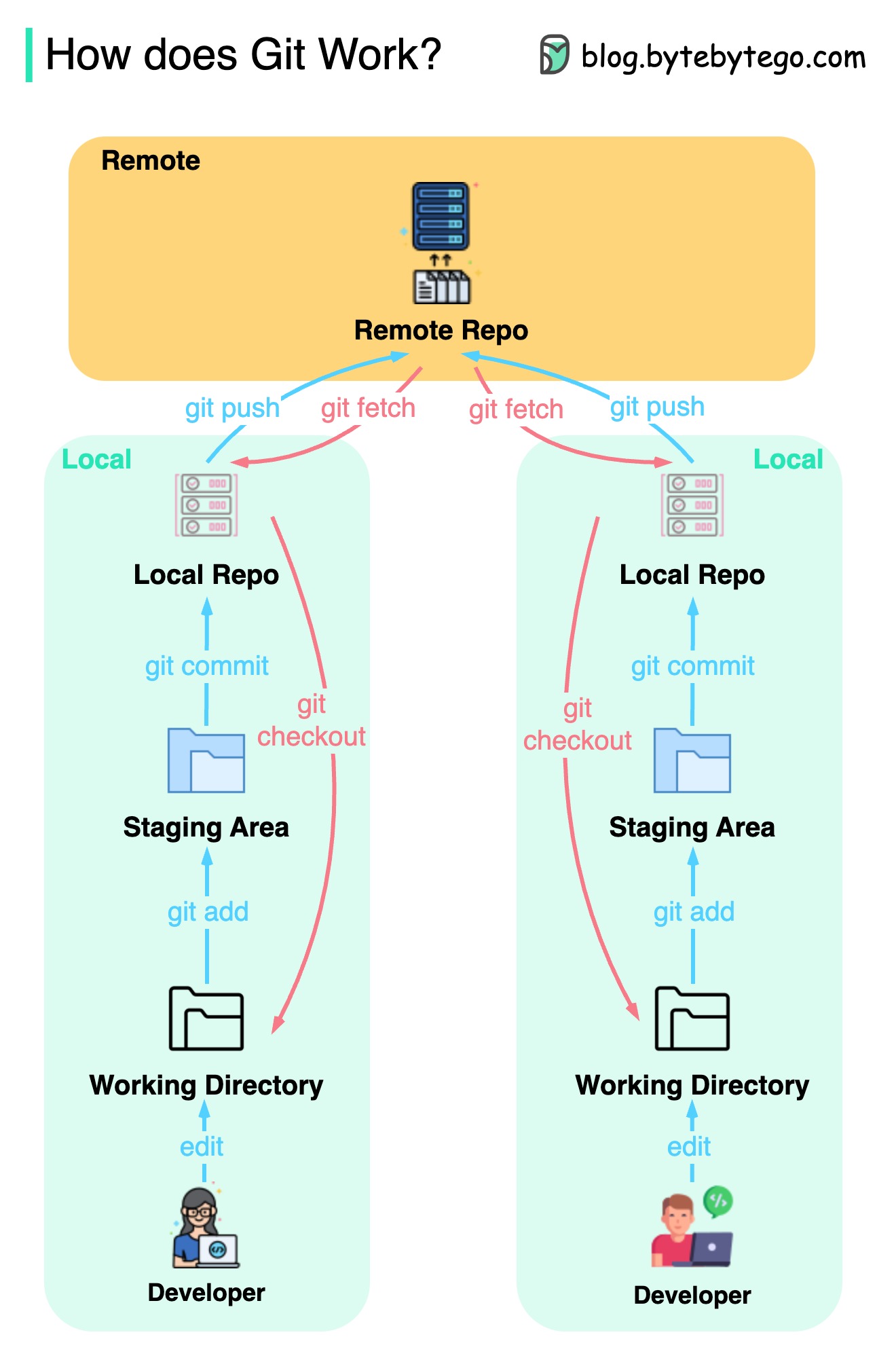
GIT는 분산 버전 제어 시스템입니다.
모든 개발자는 메인 리포지토리의 로컬 사본을 유지하고 편집하고 로컬 사본을 사용합니다.
작업이 원격 저장소와 상호 작용하지 않기 때문에 커밋은 매우 빠릅니다.
원격 저장소가 충돌하면 로컬 리포지토리에서 파일을 복구 할 수 있습니다.
차이점은 무엇입니까?


