SwiftInfer
1.0.0
Streaming-LLM 은 LLM 추론을 위해 무한한 입력 길이를 지원하는 기술입니다. Attention Sink를 활용하여 Attention Window가 이동할 때 모델이 붕괴되는 것을 방지합니다. 원본 작업은 PyTorch에서 구현되었으며 StreamingLLM을 보다 프로덕션 수준으로 만들기 위해 TensorRT 구현인 SwiftInfer를 제공합니다. 우리의 구현은 최근 출시된 TensorRT-LLM 프로젝트를 기반으로 구축되었습니다.
우리는 TensorRT-LLM 의 API를 사용하여 모델을 구성하고 추론을 실행합니다. TensorRT-LLM의 API는 안정적이지 않고 빠르게 변화하므로 구현을 v0.6.0 버전의 42af740db51d6f11442fd5509ef745a4c043ce51 커밋과 바인딩합니다. TensorRT-LLM의 API가 더욱 안정화되면 이 저장소를 업그레이드할 수 있습니다.
TensorRT-LLM V0.6.0을 빌드한 경우 다음을 실행하세요.
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .그렇지 않은 경우 먼저 TensorRT-LLM을 설치해야 합니다.
docker를 사용하는 경우 TensorRT-LLM 설치에 따라 TensorRT-LLM V0.6.0을 설치할 수 있습니다.
docker를 사용하면 다음을 실행하여 SwiftInfer를 설치할 수 있습니다.
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Docker를 사용하지 않는 경우 TensorRT-LLM을 자동으로 설치하는 스크립트를 제공합니다.
전제 조건
다음 패키지를 설치했는지 확인하십시오.
TensorRT 버전이 9.1.0 이상이고 CUDA 툴킷이 12.2 이상인지 확인하세요.
tensorrt를 설치하려면:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )nccl을 다운로드하려면 NCCL 다운로드 페이지를 따르세요.
cudnn을 다운로드하려면 cuDNN 다운로드 페이지를 따르세요.
명령
다음 명령을 실행하기 전에 nvcc 올바르게 설정했는지 확인하십시오. 확인하려면 다음을 실행하세요.
nvcc --versionTensorRT-LLM 및 SwiftInfer를 설치하려면 다음을 실행하세요.
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Llama 예제를 실행하려면 먼저 metal-llama/Llama-2-7b-chat-hf 모델 또는 lmsys/vicuna-7b-v1.3과 같은 기타 Llama 기반 변형에 대한 Hugging Face 저장소를 복제해야 합니다. 그런 다음 다음 명령을 실행하여 TensorRT 엔진을 빌드할 수 있습니다. <model-dir> Llama 모델의 실제 경로로 바꿔야 합니다.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1다음으로 LMSYS-FastChat에서 제공하는 MT-Bench 데이터를 다운로드해야 합니다.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonl마지막으로 다음 명령을 사용하여 Llama 예제를 실행할 준비가 되었습니다.
❗️❗️❗️ 그 전에 주의사항:
only_n_first 인수는 평가할 샘플 수를 제어하는 데 사용됩니다. 모든 샘플을 평가하려면 이 인수를 제거하세요. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5다음과 같이 세대가 표시될 것으로 예상해야 합니다.
우리는 원래 PyTorch 버전을 사용하여 Streaming-LLM 구현을 벤치마킹했습니다. 우리 구현을 위한 벤치마크 명령은 Run Llama 예제 섹션에 제공되고 원래 PyTorch 구현에 대한 벤치마크 명령은 torch_streamingllm 폴더에 제공됩니다. 사용된 하드웨어는 아래와 같습니다.
결과(20회 대화)는 다음과 같습니다.
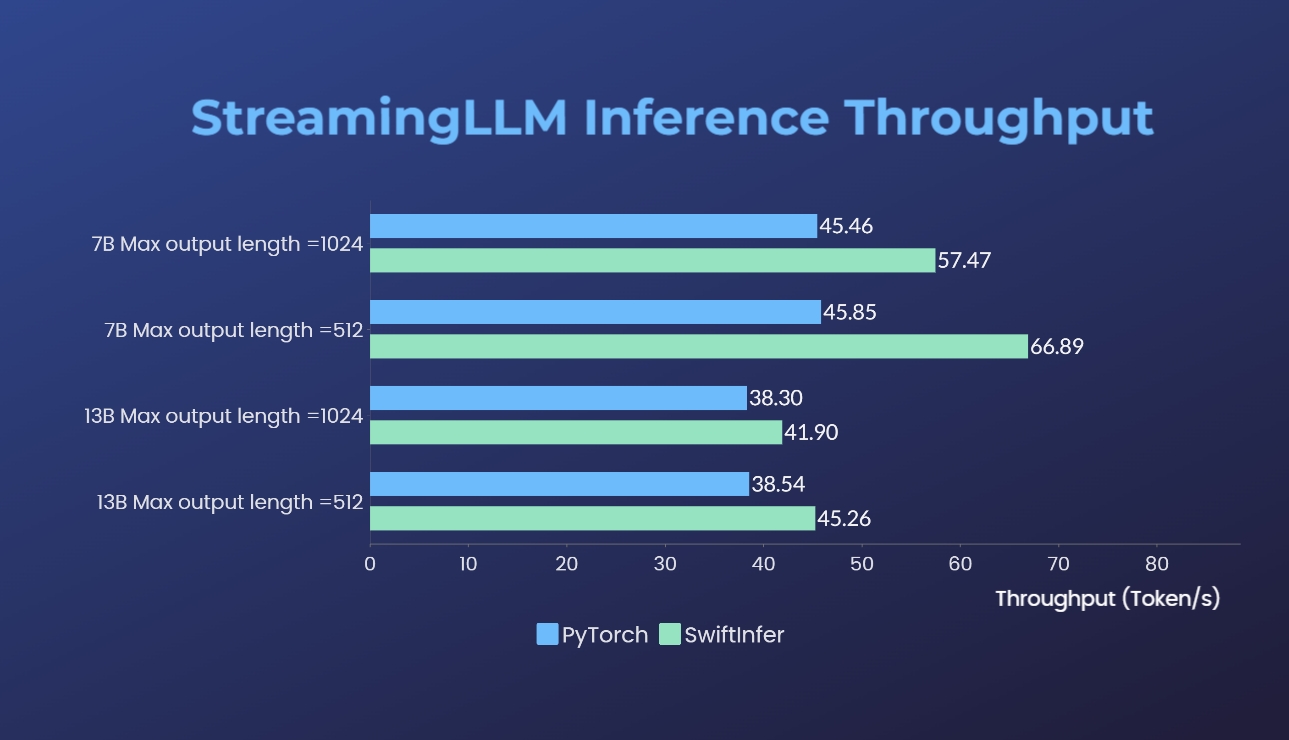
우리는 여전히 추가적인 성능 개선과 TensorRT V0.7.1 API 적응을 위해 노력하고 있습니다. 또한 TensorRT-LLM이 예제에서 StreamingLLM을 통합했지만 여러 라운드 대화 대신 단일 텍스트 생성에 더 적합한 것 같습니다.
이 작업은 Streaming-LLM에서 영감을 받아 프로덕션에 사용할 수 있도록 했습니다. 개발 전반에 걸쳐 다음 자료를 참조했으며 오픈 소스 커뮤니티와 학계에 대한 이들의 노력과 공헌에 감사를 표하고 싶습니다.
StreamingLLM과 TensorRT 구현이 유용하다고 생각하시면 Xiao et al이 제안한 원본 작업과 저장소를 친절하게 인용해 주세요. MIT 한 연구소 출신.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

