paxml
paxml release 1.4.0
Pax는 Jax를 기반으로 기계 학습 실험을 구성하고 실행하는 프레임워크입니다.
Cloud TPU 프로젝트 시작에 대한 자세한 내용은 이 페이지를 참조하세요. 기업 머신에서 코어가 8개인 Cloud TPU VM을 만들려면 다음 명령어로 충분합니다.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR TPU Pod 슬라이스를 사용하는 경우 이 가이드를 참조하세요. --worker=all 옵션과 함께 gcloud를 사용하여 로컬 머신에서 모든 명령어를 실행합니다.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "다음 빠른 시작 섹션에서는 단일 호스트 TPU에서 실행한다고 가정하므로 VM에 SSH를 통해 연결하고 거기서 명령어를 실행할 수 있습니다.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEVM을 SSH로 연결한 후 PyPI에서 paxml 안정 릴리스를 설치하거나 github에서 dev 버전을 설치할 수 있습니다.
PyPI(https://pypi.org/project/paxml/)에서 안정 릴리스를 설치하려면:
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html 전이적 종속성 문제가 발생하고 기본 Cloud TPU VM 환경을 사용하는 경우 해당 릴리스 분기 rX.YZ로 이동하여 paxml/pip_package/requirements.txt 다운로드하세요. 이 파일에는 해당 릴리스를 빌드/테스트하는 기본 Cloud TPU VM 환경에 필요한 모든 전이 종속성의 정확한 버전이 포함되어 있습니다.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtGithub에서 개발 버전을 설치하고 코드를 쉽게 편집하려면 다음을 수행하세요.
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=True문서 및 Jupyter Notebook 튜토리얼을 보려면 docs 폴더를 방문하세요. Cloud TPU VM에서 Jupyter 노트북을 실행하는 방법에 대한 지침은 다음 섹션을 참조하세요.
방금 paxml을 설치한 TPU VM에서 예시 노트북을 실행할 수 있습니다. #### v4-8 에서 노트북을 활성화하는 단계
포트 전달을 사용하는 TPU VM의 ssh gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
TPU VM에 jupyter Notebook을 설치하고 markupsafe를 다운그레이드합니다.
pip install notebook
pip install markupsafe==2.0.1
jupyter 경로 내보내기 export PATH=/home/$USER/.local/bin:$PATH
TPU VM에 대한 예시 노트북을 scp gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
TPU VM에서 jupyter Notebook을 시작하고 jupyter Notebook jupyter notebook --no-browser --port=8080 에서 생성된 토큰을 기록해 둡니다.
그런 다음 로컬 브라우저에서 http://localhost:8080/으로 이동하여 제공된 토큰을 입력하세요.
참고: 첫 번째 노트북이 여전히 TPU를 점유하고 있는 동안 두 번째 노트북 사용을 시작해야 하는 경우 pkill -9 python3 실행하여 TPU를 확보할 수 있습니다.
참고: NVIDIA는 H100 FP8 지원 및 광범위한 GPU 성능 개선을 갖춘 업데이트된 Pax 버전을 출시했습니다. 자세한 내용과 사용 지침을 보려면 NVIDIA Rosetta 저장소를 방문하세요.
PGLE(Profile Guided Latency Estimator) 워크플로우는 컴퓨팅 및 집합체의 실제 실행 시간을 측정하고, 프로필 정보는 더 나은 예약 결정을 위해 XLA 컴파일러에 다시 공급됩니다.
프로필 기반 지연 추정기는 수동 또는 자동으로 사용할 수 있습니다. 자동 모드에서 JAX는 프로필 정보를 수집하고 단일 실행으로 모듈을 다시 컴파일합니다. 수동 모드에서는 작업을 두 번 실행해야 합니다. 첫 번째는 프로필을 수집하고 저장하고 두 번째는 제공된 데이터를 컴파일하고 실행해야 합니다.
다음 환경 변수를 설정하여 자동 PGLE를 켤 수 있습니다.
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
또는 JAX에서는 다음과 같이 설정할 수 있습니다.
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
JAX_PGLE_PROFILING_RUNS 변경하여 프로필 데이터를 수집하는 데 사용되는 재실행 횟수를 제어할 수 있습니다. 이 매개변수를 늘리면 프로필 정보가 더 좋아지지만 최적화되지 않은 훈련 단계의 양도 늘어납니다.
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY 매개변수를 사용하면 자동 PGLE와 함께 호스트 콜백을 사용할 수 있습니다.
JAX_PGLE_AGGREGATION_PERCENTILE 매개변수를 줄이면 단계 간 성능이 너무 복잡하여 관련 없는 측정값을 필터링할 수 없는 경우 도움이 될 수 있습니다.
주의: 자동 PGLE는 사전 컴파일된 모듈에서는 작동하지 않습니다. JAX는 실행 중에 모듈을 다시 컴파일해야 하므로 자동 PGLE은 AoT나 다음 경우에는 작동하지 않습니다.
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
수동 Profile Guided Latency Estimator를 계속 사용하려는 경우 XLA/GPU의 워크플로는 다음과 같습니다.
다음을 설정하여 그렇게 할 수 있습니다.
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) 이 단계가 끝나면 코드에 인쇄된 rundir 아래에 profile.pb 파일이 생성됩니다.
profile.pb 파일을 --xla_gpu_pgle_profile_file_or_directory_path 플래그에 전달해야 합니다.
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " XLA에서 로깅을 활성화하고 프로필이 양호한지 확인하려면 INFO 포함하도록 로깅 수준을 설정합니다.
export TF_CPP_MIN_LOG_LEVEL=0실제 워크플로를 실행합니다. 실행 중인 로그에서 이러한 로깅을 발견하면 프로파일러가 대기 시간 숨기기 스케줄러에 사용된다는 의미입니다.
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax는 Jax에서 실행됩니다. Cloud TPU에서 Jax 작업을 실행하는 방법에 대한 자세한 내용은 여기에서 확인할 수 있습니다. Cloud TPU Pod에서 Jax 작업을 실행하는 방법에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
종속성 오류가 발생하는 경우 설치하려는 안정 릴리스에 해당하는 브랜치의 요구 requirements.txt 파일을 참조하세요. 예를 들어, 안정 릴리스 0.4.0의 경우 r0.4.0 분기를 사용하고 안정 릴리스에 사용되는 종속성의 정확한 버전은 요구 사항.txt를 참조하세요.
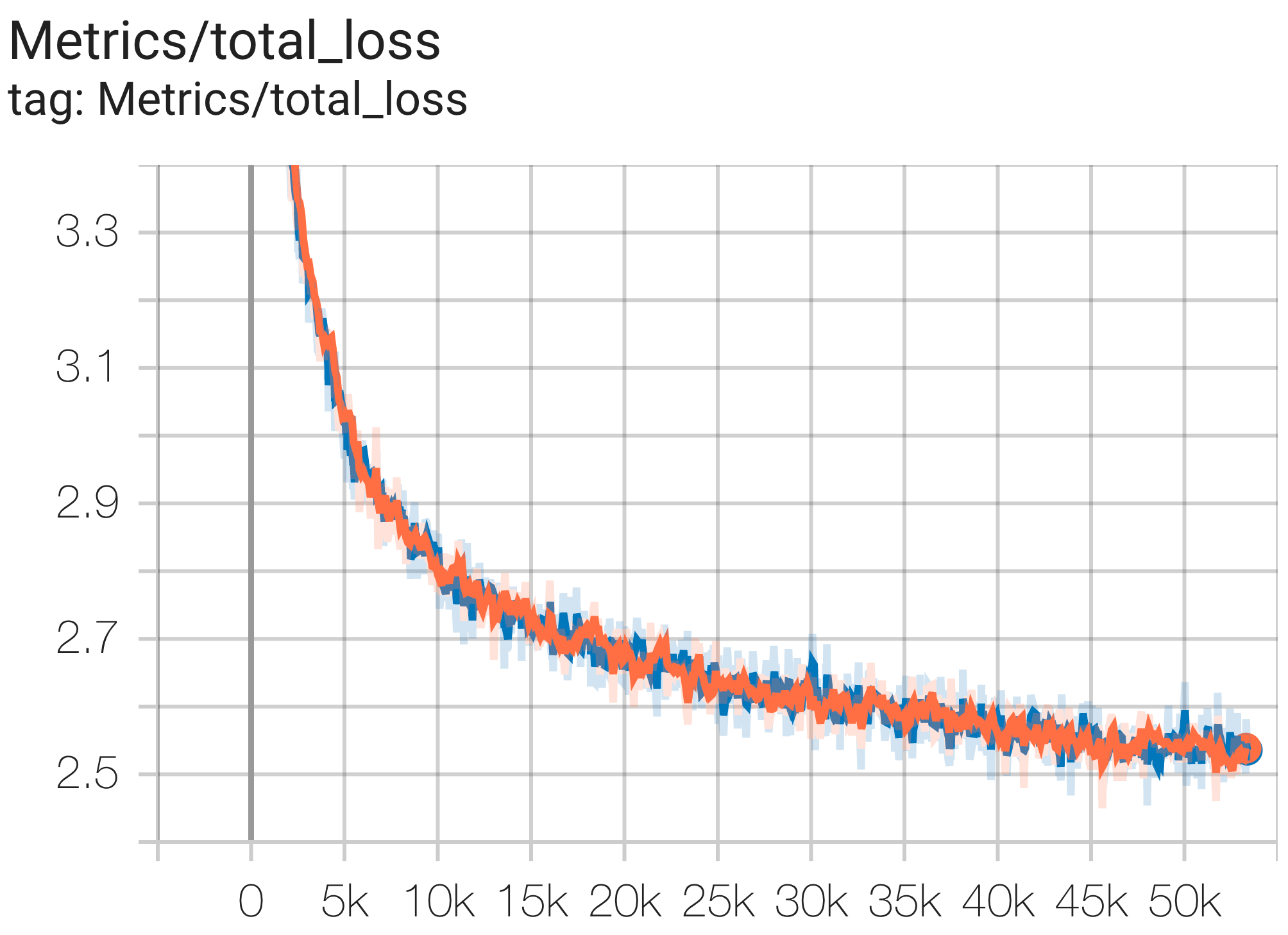
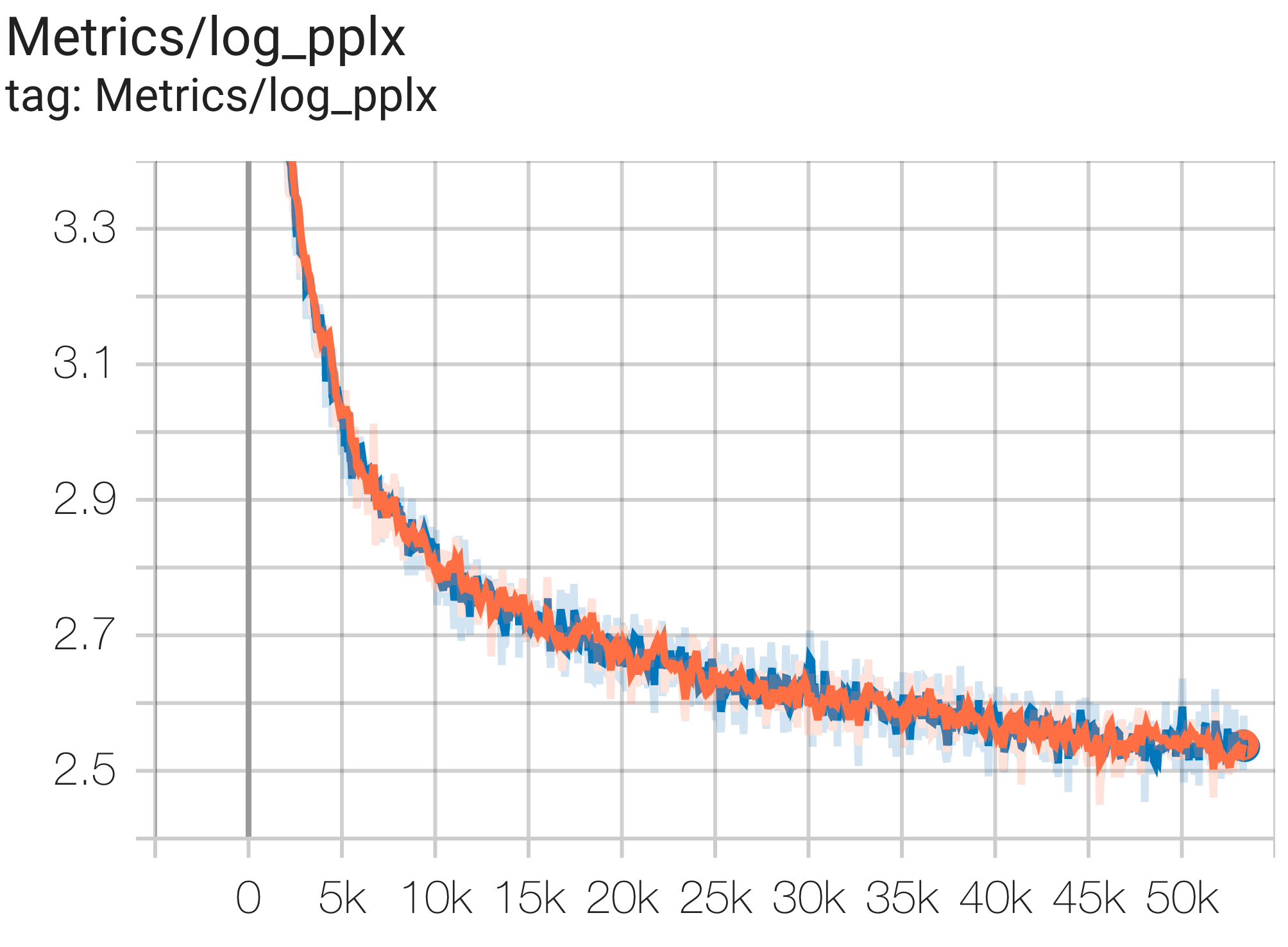
다음은 c4 데이터 세트에서 실행되는 몇 가지 샘플 수렴입니다.
다음과 같이 c4.py의 C4Spmd1BAdam4Replicas 구성을 사용하여 TPU v4-8 의 c4 데이터세트에서 1B 매개변수 모델을 실행할 수 있습니다.
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > 손실 곡선과 log perplexity 그래프는 다음과 같이 관찰할 수 있습니다.
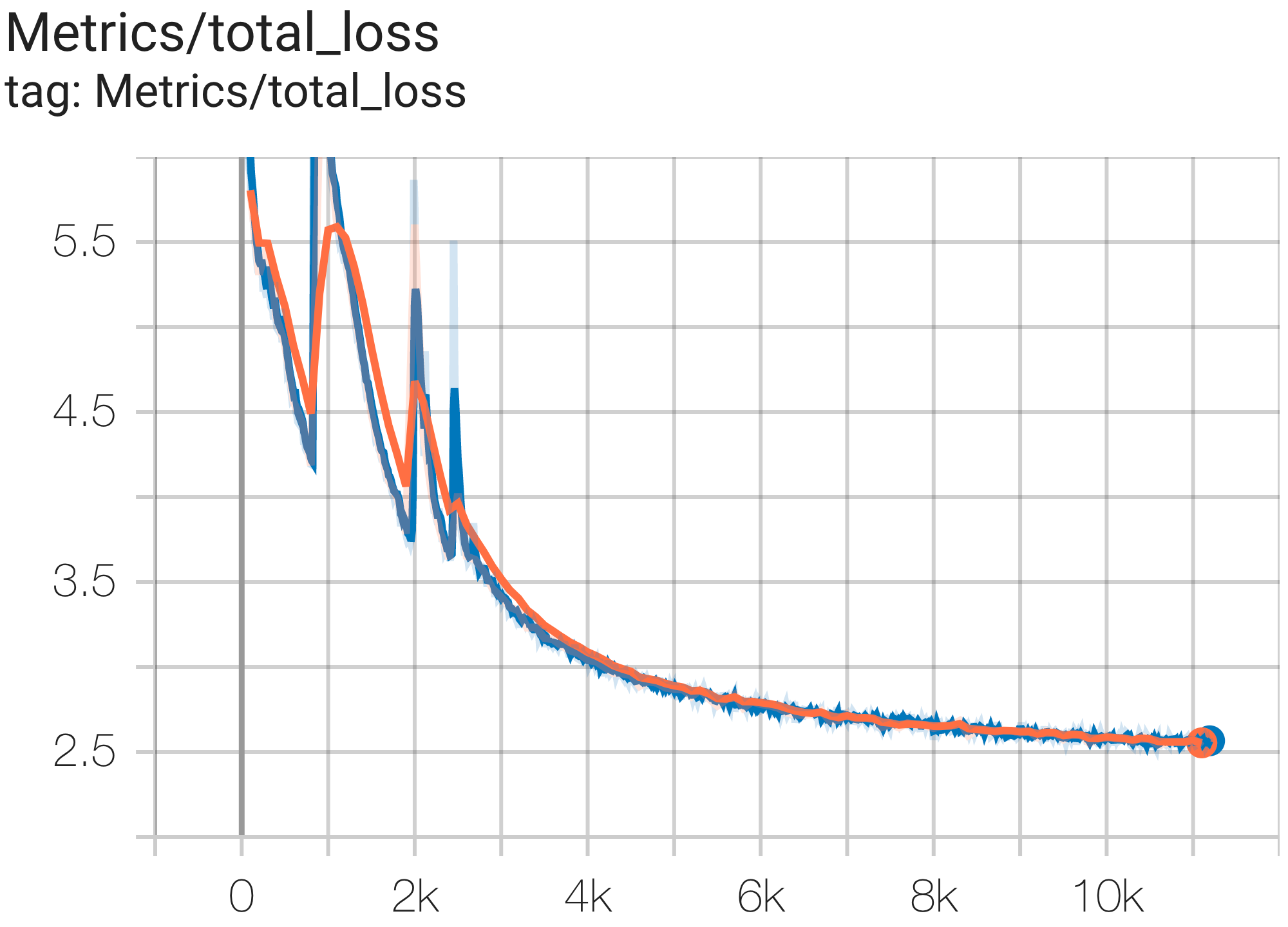
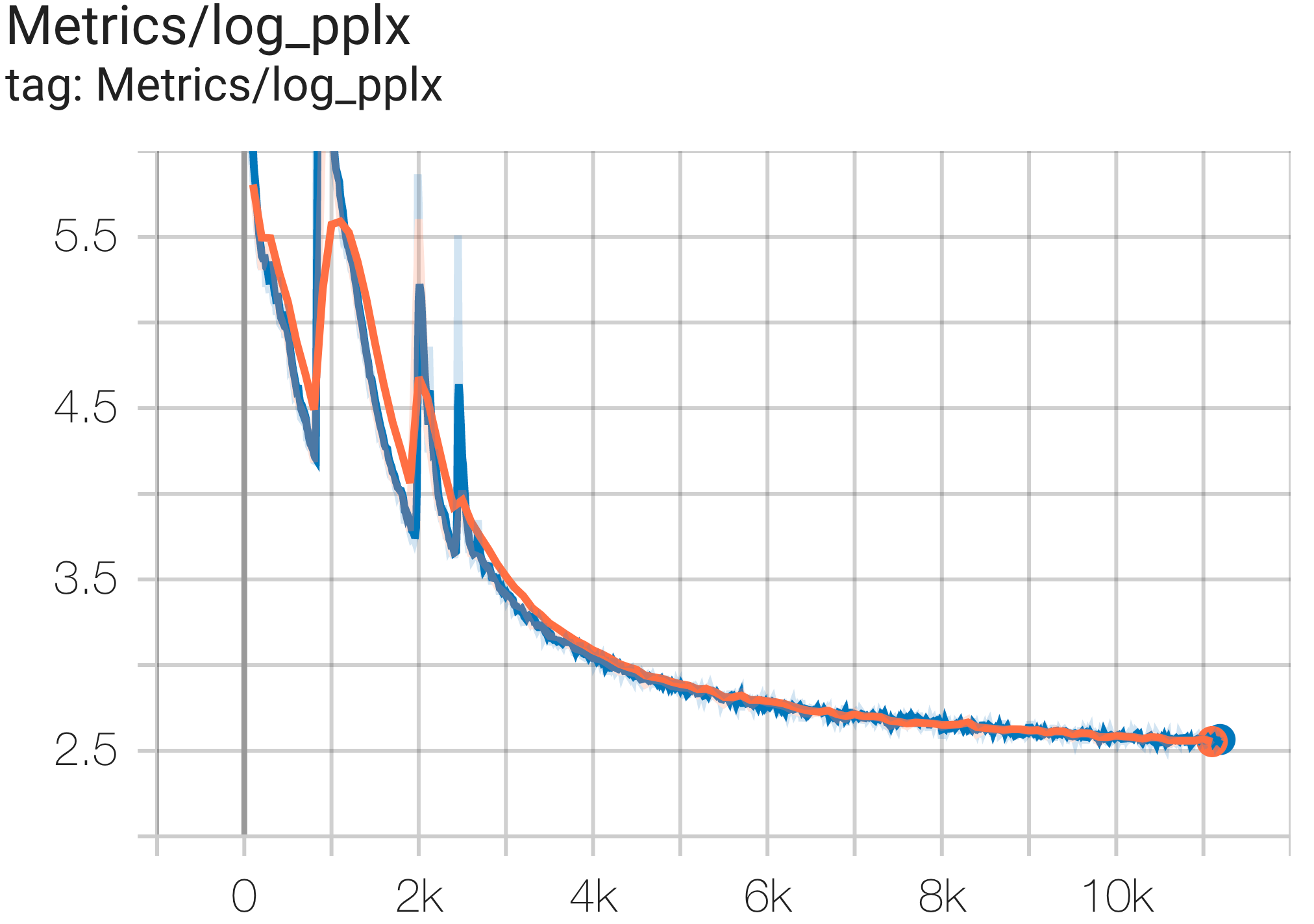
다음과 같이 c4.py의 C4Spmd16BAdam32Replicas 구성을 사용하여 TPU v4-64 의 c4 데이터세트에서 16B 매개변수 모델을 실행할 수 있습니다.
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > 손실 곡선과 log perplexity 그래프는 다음과 같이 관찰할 수 있습니다.
다음과 같이 c4.py의 C4SpmdPipelineGpt3SmallAdam64Replicas 구성을 사용하여 TPU v4-128 의 c4 데이터 세트에서 GPT3-XL 모델을 실행할 수 있습니다.
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > 손실 곡선과 log perplexity 그래프는 다음과 같이 관찰할 수 있습니다.
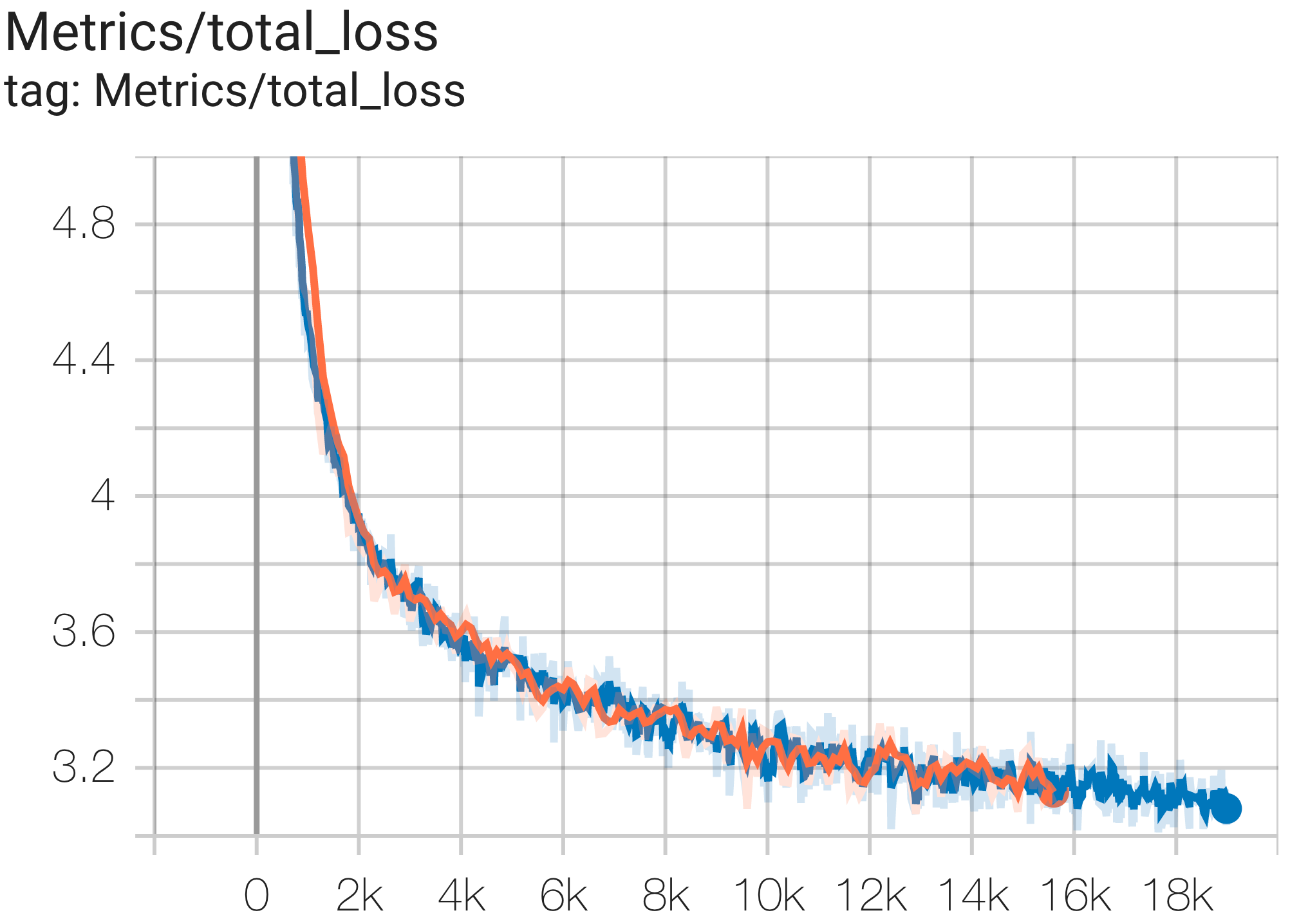
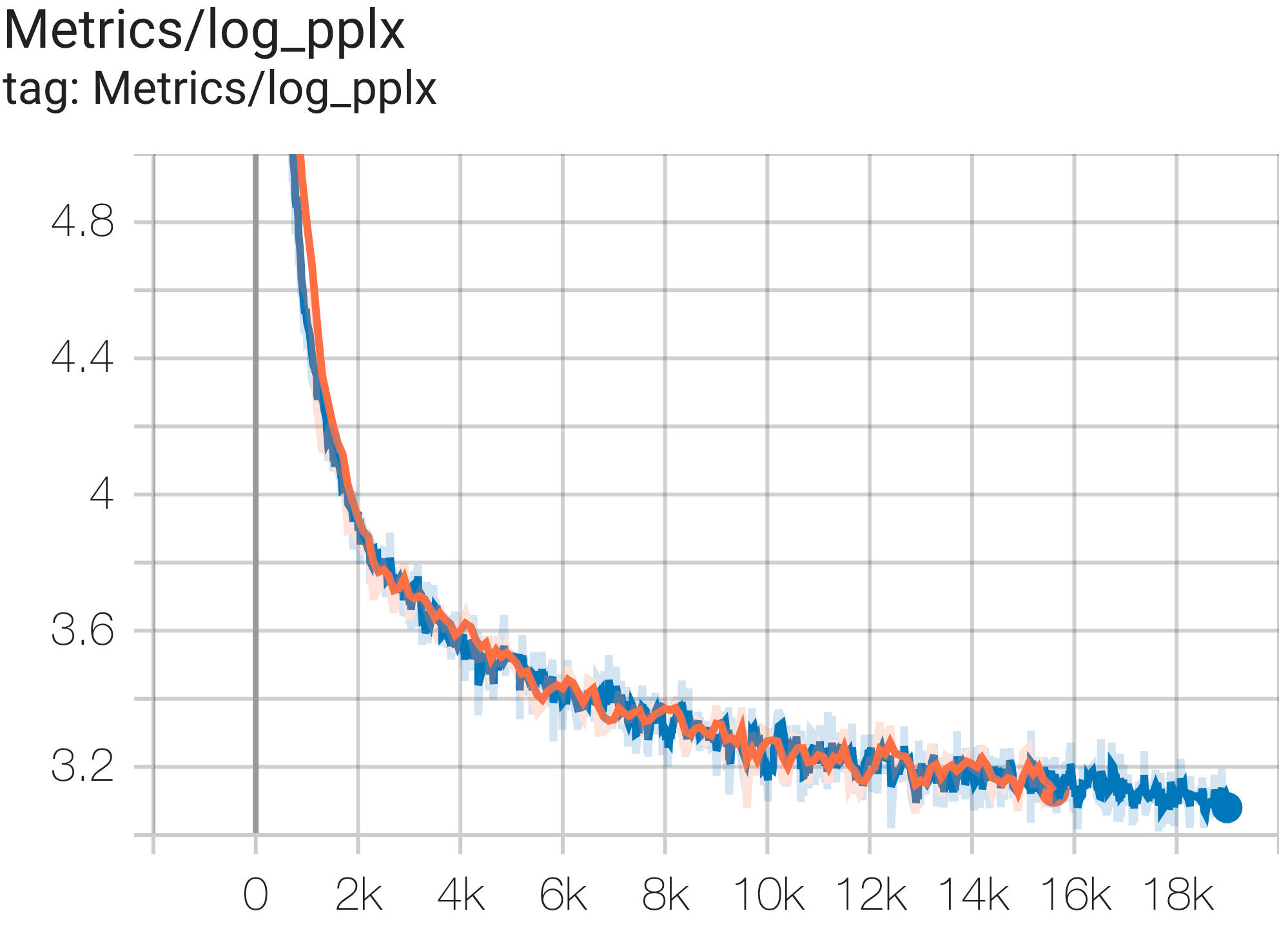
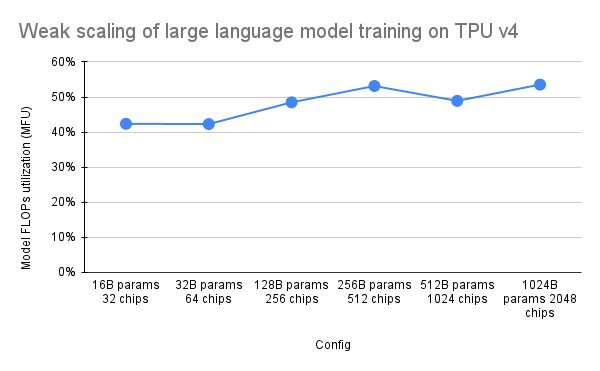
PaLM 문서에서는 MFU(Model FLOPs Utilization)라는 효율성 측정 기준을 소개했습니다. 이는 최대 FLOP를 100% 활용하는 시스템의 이론적 최대 처리량에 대한 관찰된 처리량(예: 언어 모델의 경우 초당 토큰 수)의 비율로 측정됩니다. 이는 역방향 전달 중에 활성화 재구체화에 소비된 FLOP를 포함하지 않기 때문에 컴퓨팅 활용도를 측정하는 다른 방법과 다릅니다. 즉, MFU로 측정한 효율성이 엔드투엔드 훈련 속도로 직접 변환됩니다.
Pax를 사용하는 TPU v4 Pod에서 주요 워크로드 클래스의 MFU를 평가하기 위해 수십억에서 수조에 이르는 매개변수 크기의 일련의 디코더 전용 변환기 언어 모델(GPT) 구성에 대한 심층 벤치마크 캠페인을 수행했습니다. c4 데이터 세트에서. 다음 그래프는 사용된 칩 수에 비례하여 모델 크기를 늘리는 "약한 스케일링" 패턴을 사용한 훈련 효율성을 보여줍니다.
이 저장소의 다중 슬라이스 구성은 1. 구문/모델 아키텍처에 대한 단일 슬라이스 구성 및 구성 값에 대한 2. MaxText 저장소를 참조합니다.
멀티슬라이스에서 Pax의 시작점으로 c4_multislice.py`에서 예제 실행을 제공합니다.
다중 슬라이스 Cloud TPU 프로젝트에 대기 중인 리소스를 사용하는 방법에 대한 자세한 문서는 이 페이지를 참조하세요. 다음은 이 저장소에서 예시 구성을 실행하기 위해 TPU를 설정하는 데 필요한 단계를 보여줍니다.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run 예를 들어, v4-128의 2개 슬라이스에서 C4Spmd22BAdam2xv4_128 실행하려면 다음과 같은 방법으로 TPU를 설정해야 합니다.
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX 앞에서 설명한 설정 명령은 모든 슬라이스의 모든 작업자에서 실행되어야 합니다. 1) 각 작업자와 각 슬라이스에 개별적으로 SSH를 연결할 수 있습니다. 또는 2) 다음 명령과 같이 --worker=all 플래그와 함께 for 루프를 사용합니다.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done 다중 슬라이스 구성을 실행하려면 $NODE_COUNT와 동일한 수의 터미널을 엽니다. 2개의 슬라이스( C4Spmd22BAdam2xv4_128 )에 대한 실험을 위해 두 개의 터미널을 엽니다. 그런 다음 각 터미널에서 개별적으로 이러한 각 명령을 실행하십시오.
터미널 0에서 다음과 같이 슬라이스 0에 대한 훈련 명령을 실행합니다.
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "터미널 1에서 다음과 같이 슬라이스 1에 대한 훈련 명령을 동시에 실행합니다.
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "이 표에서는 MaxText 변수 이름이 Pax로 변환된 방법에 대한 세부 정보를 다루고 있습니다.
MaxText에는 최종 값에 대한 여러 매개변수(base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads)에 곱해지는 "규모"가 있습니다.
또 다른 언급할 점은 Pax가 DCN 및 ICN MESH_SHAPE를 배열로 다루는 반면 MaxText에는 DCN 및 ICI에 대한 data_parallelism, fsdp_parallelism 및 tensor_parallelism의 별도 변수가 있다는 것입니다. 이들 값은 기본적으로 1로 설정되어 있으므로 1보다 큰 값을 갖는 변수만 이 변환표에 기록됩니다.
즉, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] 및 DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| 팍스 C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (스케일 적용 후) | ||
|---|---|---|---|---|
| 척도(다음 4개 변수에 적용) | 3 | |||
| NUM_LAYERS개 | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | 베이스_emb_dim | 2048년 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS개 | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | 머리_어두움 | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | 최대_대상_길이 | 1024 | |
| VOCAB_SIZE | 32768 | 어휘_크기 | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | 진실 | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_병렬성 | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelism | 2 |
입력은 학습/평가/디코드를 위해 모델로 데이터를 가져오기 위한 BaseInput 클래스의 인스턴스입니다.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass 이는 반복자처럼 작동합니다. get_next() NestedMap 을 반환합니다. 여기서 각 필드는 배치 크기를 선행 차원으로 갖는 숫자 배열입니다.
각 입력은 BaseInput.HParams 의 하위 클래스로 구성됩니다. 이 페이지에서는 p 사용하여 BaseInput.Params 의 인스턴스를 나타내고 input 으로 인스턴스화합니다.
Pax에서 데이터는 항상 멀티호스트입니다. 각 Jax 프로세스에는 인스턴스화된 별도의 독립적인 input 있습니다. 해당 매개변수는 Pax가 자동으로 설정하는 다른 p.infeed_host_index 갖습니다.
따라서 각 호스트에 표시되는 로컬 배치 크기는 p.batch_size 이고 전역 배치 크기는 (p.batch_size * p.num_infeed_hosts) 입니다. p.batch_size jax.local_device_count() * PERCORE_BATCH_SIZE 로 설정된 경우가 종종 있습니다.
이러한 멀티호스트 특성으로 인해 input 적절하게 분할되어야 합니다.
훈련의 경우 각 input 동일한 배치를 생성해서는 안 되며, 유한 데이터 세트에 대한 평가의 경우 각 input 동일한 수의 배치 후에 종료되어야 합니다. 가장 좋은 해결책은 서로 다른 호스트의 각 input 겹치지 않도록 입력 구현에서 데이터를 적절하게 분할하는 것입니다. 실패하면 훈련 중에 중복 배치를 피하기 위해 다른 무작위 시드를 사용할 수도 있습니다.
input.reset() 교육 데이터에서는 호출되지 않지만 평가(또는 디코딩) 데이터에는 호출될 수 있습니다.
각 평가(또는 디코드) 실행에 대해 Pax는 input.get_next() N 번 호출하여 input 에서 N 배치를 가져옵니다. 사용된 배치 수 N 은 p.eval_loop_num_batches 를 통해 사용자가 지정한 고정 숫자일 수 있습니다. 또는 N 동적일 수 있습니다( p.eval_loop_num_batches=None ). 즉 모든 데이터를 소진할 때까지( StopIteration 또는 tf.errors.OutOfRange 발생시켜) input.get_next() 호출합니다.
p.reset_for_eval=True 인 경우 p.eval_loop_num_batches 는 무시되고 N 데이터를 소진할 배치 수로 동적으로 결정됩니다. 이 경우 p.repeat False로 설정해야 합니다. 그렇지 않으면 무한한 디코딩/평가가 발생하기 때문입니다.
p.reset_for_eval=False 이면 Pax는 p.eval_loop_num_batches 배치를 가져옵니다. 데이터가 조기에 소진되지 않도록 p.repeat=True 로 설정해야 합니다.
LingvoEvalAdaptor 입력에는 p.reset_for_eval=True 필요합니다.
N : 정적 | N : 동적 | |
|---|---|---|
p.reset_for_eval=True | 각 평가 실행에서는 다음을 사용합니다. | 평가 실행당 하나의 에포크입니다. |
: : 처음 N 배치. 아님 : eval_loop_num_batches : | ||
| : : 아직 지원되지 않습니다. : 무시됩니다. 입력해야 할 사항은 다음과 같습니다. | ||
| : : : 유한하다 : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | 각 평가 실행에서는 다음을 사용합니다. | 지원되지 않습니다. |
: : 겹치지 않음 N : : | ||
| : : 롤링의 배치 : : | ||
| : : 기준, : :에 따름 | ||
: : eval_loop_num_batches : : | ||
| : : . 입력은 반복되어야 합니다 : : | ||
| : : 무기한 : : | ||
: : ( p.repeat=True ) 또는 : : | ||
| : : 그렇지 않으면 다음이 발생할 수 있습니다. : : | ||
| : : 예외 : : |
정확히 한 에포크에서 디코드/평가를 실행하는 경우(예: p.reset_for_eval=True 인 경우) 정확히 동일한 수의 배치가 생성된 후 각 샤드가 동일한 단계에서 발생하도록 입력이 샤딩을 올바르게 처리해야 합니다. 이는 일반적으로 입력이 평가 데이터를 채워야 함을 의미합니다. 이는 SeqIOInput 및 LingvoEvalAdaptor 에 의해 자동으로 수행됩니다(자세한 내용은 아래 참조).
대부분의 입력에 대해 get_next() 만 호출하여 일괄 데이터를 가져옵니다. 한 가지 유형의 평가 데이터는 이에 대한 예외입니다. 여기서 "메트릭을 계산하는 방법"도 입력 개체에 정의됩니다.
이는 일부 표준 평가 벤치마크를 정의하는 SeqIOInput 에서만 지원됩니다. 특히 Pax는 SeqIO 작업에 정의된 predict_metric_fns 및 score_metric_fns() 사용하여 평가 지표를 계산합니다(Pax는 SeqIO 평가자에 직접 의존하지 않지만).
모델이 훈련/평가 사이 또는 사전 훈련/미세 조정 사이의 다른 훈련 데이터 사이에서 여러 입력을 사용하는 경우, 사용자는 특히 다른 사람이 구현한 다른 입력을 가져올 때 입력에서 사용하는 토크나이저가 동일한지 확인해야 합니다.
사용자는 input.ids_to_strings() 로 일부 ID를 디코딩하여 토크나이저의 온전성을 확인할 수 있습니다.
항상 몇 개의 배치를 살펴보며 데이터의 상태를 확인하는 것이 좋습니다. 사용자는 Colab에서 매개변수를 쉽게 재현하고 데이터를 검사할 수 있습니다.
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) 훈련 데이터는 일반적으로 고정된 무작위 시드를 사용해서는 안 됩니다. 훈련 작업이 선점되면 훈련 데이터가 반복되기 시작하기 때문입니다. 특히 Lingvo 입력의 경우 학습 데이터에 p.input.file_random_seed = 0 설정하는 것이 좋습니다.
샤딩이 올바르게 처리되는지 테스트하기 위해 사용자는 p.num_infeed_hosts, p.infeed_host_index 에 대해 서로 다른 값을 수동으로 설정하고 인스턴스화된 입력이 서로 다른 배치를 내보내는지 확인할 수 있습니다.
Pax는 SeqIO, Lingvo 및 custom의 3가지 유형의 입력을 지원합니다.
SeqIOInput 사용하여 데이터세트를 가져올 수 있습니다.
SeqIO 입력은 평가 데이터의 올바른 샤딩 및 패딩을 자동으로 처리합니다.
LingvoInputAdaptor 사용하여 데이터 세트를 가져올 수 있습니다.
입력은 자동으로 샤딩을 처리하거나 처리하지 않을 수 있는 Lingvo 구현에 완전히 위임됩니다.
고정된 packing_factor 사용하는 GenericInput 기반 Lingvo 입력 구현의 경우 LingvoInputAdaptorNewBatchSize 사용하여 내부 Lingvo 입력에 대해 더 큰 배치 크기를 지정하고 p.batch_size 에 원하는(일반적으로 훨씬 작은) 배치 크기를 배치하는 것이 좋습니다.
평가 데이터의 경우 LingvoEvalAdaptor 사용하여 한 에포크에 걸쳐 평가를 실행하기 위한 샤딩 및 패딩을 처리하는 것이 좋습니다.
BaseInput 의 사용자 정의 하위 클래스입니다. 사용자는 일반적으로 tf.data 또는 SeqIO를 사용하여 자신의 하위 클래스를 구현합니다.
사용자는 기존 입력 클래스를 상속하여 일괄 처리 후 처리만 사용자 지정할 수도 있습니다. 예를 들어:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batch초매개변수는 모델을 정의하고 실험을 구성하는 데 중요한 부분입니다.
Python 도구와 더 효과적으로 통합하기 위해 Pax/Praxis는 하이퍼파라미터에 Python 데이터 클래스 기반 구성 스타일을 사용합니다.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0HParams 데이터 클래스를 중첩하는 것도 가능합니다. 아래 예에서 선형_tpl 속성은 중첩된 Linear.HParams입니다.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )레이어는 훈련 가능한 매개변수가 있는 임의의 함수를 나타냅니다. 레이어에는 다른 레이어가 하위 레이어로 포함될 수 있습니다. 레이어는 모델의 필수 구성 요소입니다. 레이어는 Flax nn.Module에서 상속됩니다.
일반적으로 레이어는 두 가지 방법을 정의합니다.
이 방법은 훈련 가능한 가중치와 하위 레이어를 생성합니다.
이 방법은 순방향 전파 함수를 정의하여 입력을 기반으로 일부 출력을 계산합니다. 또한 fprop는 요약을 추가하거나 보조 손실을 추적할 수 있습니다.
Fiddle은 ML 애플리케이션용으로 설계된 오픈 소스 Python 우선 구성 라이브러리입니다. Pax/Praxis는 Fiddle Config/Partial(s)과의 상호 운용성과 열성적인 오류 확인 및 공유 매개변수와 같은 일부 고급 기능을 지원합니다.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Fiddle을 사용하면 레이어를 공유하도록 구성할 수 있습니다(예: 공유된 훈련 가능한 가중치를 사용하여 한 번만 인스턴스화).
모델은 일반적으로 레이어 모음인 네트워크만 정의하고 디코딩 등 모델과 상호 작용하기 위한 인터페이스를 정의합니다.
몇 가지 기본 모델 예시는 다음과 같습니다.
작업에는 하나 이상의 모델과 학습자/최적화가 포함됩니다. 가장 간단한 Task 하위 클래스는 다음 Hparams가 필요한 SingleTask 입니다.
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| PyPI 버전 | 저지르다 |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


