safe rlhf
1.0.0
Beaver는 Peking University의 PKU-Alignment 팀이 개발한 고도로 모듈화된 오픈 소스 RLHF 프레임워크입니다. 이는 정렬 연구, 특히 안전한 RLHF 방법을 통한 제한된 정렬 LLM 연구를 위한 교육 데이터와 재현 가능한 코드 파이프라인을 제공하는 것을 목표로 합니다.
비버의 주요 기능은 다음과 같습니다.
2024/06/13 : PKU-SafeRLHF 데이터 세트 버전 1.0의 오픈 소스를 발표하게 된 것을 기쁘게 생각합니다. 이 릴리스는 인간-AI 공동 주석을 통합하고, 피해 범주의 범위를 확장하고, 자세한 심각도 수준 레이블을 도입하여 초기 베타 버전보다 발전했습니다. 자세한 내용과 액세스를 보려면 데이터 세트 페이지를 방문하세요. 포옹 얼굴: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : 우리의 방법인 Safe RLHF는 ICLR 2024 Spotlight에 의해 승인되었습니다.2023/10/19 : 우리는 새로운 안전 정렬 알고리즘과 그 구현을 자세히 설명하는 Safe RLHF 논문을 arXiv에 발표했습니다.2023/07/10 : Safe RLHF 교육 시리즈의 첫 번째 이정표로 Beaver-7B v1/v2/v3 모델의 오픈 소스화를 발표하게 되어 기쁘게 생각합니다. 해당 보상 모델 v1/v2/v3/통합으로 보완됩니다. 및 비용 모델 v1/v2/v3/통합 체크포인트? 포옹 얼굴.2023/07/10 : 오픈 소스 안전 기본 설정 데이터세트인 PKU-Alignment/PKU-SafeRLHF를 확장합니다. 여기에는 현재 30만 개가 넘는 예시가 포함되어 있습니다. (PKU-SafeRLHF-Dataset 섹션도 참조하세요)2023/07/05 : 중국어 사전 학습 모델에 대한 지원을 강화하고 추가 오픈소스 중국어 데이터 세트를 통합했습니다. (중국어 지원(中文支持) 및 사용자 정의 데이터 세트(自定义数据集) 섹션도 참조하세요.)2023/05/15 : Safe RLHF 파이프라인, 평가 결과 및 교육 코드의 첫 번째 릴리스입니다.인간 피드백을 통한 강화 학습: 선호 학습을 통한 보상 극대화
인간 피드백을 통한 안전한 강화 학습: 선호 학습을 통한 제한된 보상 극대화
어디
최종 목표는 모델 찾는 것
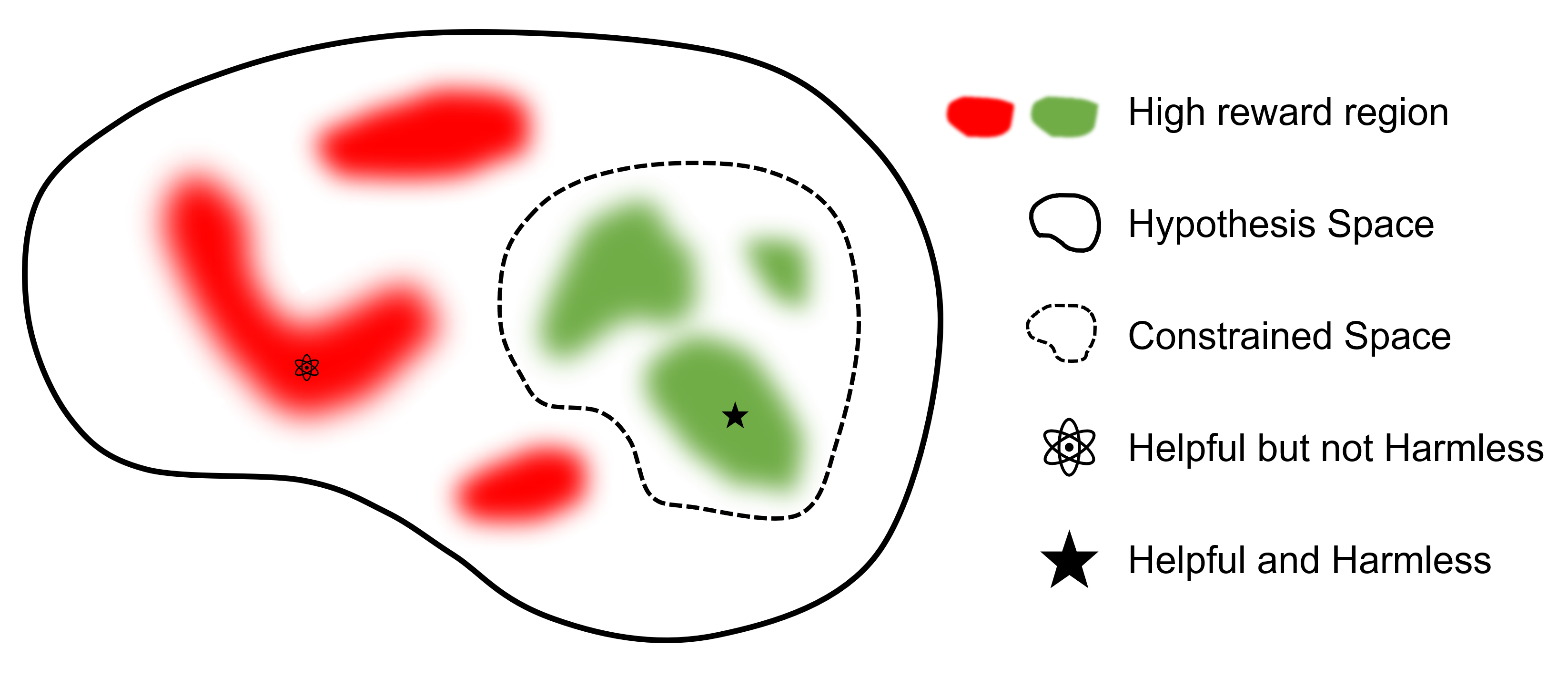
RLHF를 지원하는 다른 프레임워크와 비교할 때 safe-rlhf SFT에서 RLHF 및 평가까지 모든 단계를 지원하는 최초의 프레임워크입니다. 또한 safe-rlhf 는 RLHF 단계에서 고려되는 안전 우선순위를 고려하는 첫 번째 프레임워크입니다. 이는 정책 공간에서 제한된 매개변수 검색에 대해 보다 이론적으로 보장됩니다.
| SFT | 선호 모델 1 훈련 | RLHF | 안전한 RLHF | PTX 손실 | 평가 | 백엔드 | |
|---|---|---|---|---|---|---|---|
| 비버 (안전-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | 딥스피드 |
| trlX | ✔️ | 2 | ✔️ | 가속 / NeMo | |||
| DeepSpeed-채팅 | ✔️ | ✔️ | ✔️ | ✔️ | 딥스피드 | ||
| 거대 AI | ✔️ | ✔️ | ✔️ | ✔️ | 거대AI | ||
| 알파카팜 | 3 | ✔️ | ✔️ | ✔️ | 가속하다 |
PKU-SafeRLHF 데이터세트는 성능과 안전 기본 설정을 모두 포함하는 사람이 라벨을 붙인 데이터세트입니다. 여기에는 모욕, 부도덕, 범죄, 정서적 피해, 사생활 보호 등 10개 이상의 차원에 대한 제약이 포함됩니다. 이러한 제약 조건은 RLHF 기술에서 세밀한 값 정렬을 위해 설계되었습니다.
다중 라운드 미세 조정을 용이하게 하기 위해 각 라운드의 초기 매개변수 가중치, 필수 데이터 세트 및 훈련 매개변수를 공개합니다. 이는 과학 및 학술 연구의 재현성을 보장합니다. 데이터세트는 롤링 업데이트를 통해 점진적으로 출시될 예정입니다.
데이터 세트는 Hugging Face: PKU-Alignment/PKU-SafeRLHF에서 사용할 수 있습니다.
PKU-SafeRLHF-10K 는 안전 기본 설정을 포함하여 10K 인스턴스가 포함된 첫 번째 Safe RLHF 교육 데이터가 포함된 PKU-SafeRLHF 의 하위 집합입니다. Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K에서 찾을 수 있습니다.
우리는 유용한 환경 설정과 무해한 환경 설정 모두에 대해 인간이 라벨링한 100만 개의 쌍을 포함하는 전체 Safe-RLHF 데이터 세트를 점진적으로 출시할 예정입니다.
Beaver는 safe-rlhf 사용하여 훈련된 LLaMA 기반의 대규모 언어 모델입니다. Alpaca 모델을 기반으로 유용성 및 무해성과 관련된 인간 선호도 데이터를 수집하고 훈련에 Safe RLHF 기술을 사용하여 개발되었습니다. Beaver는 Alpaca의 유용한 성능을 유지하면서 무해성을 크게 향상시킵니다.
비버는 나뭇가지, 관목, 바위, 흙을 이용해 댐과 작은 목조 주택을 짓는 데 능숙하고, 다른 생물이 서식하기에 적합한 습지 환경을 만들어 생태계에 없어서는 안 될 존재로 만들어 '천연 댐 기술자'로 알려져 있습니다. . 다양한 모집단의 다양한 값을 수용하면서 대형 언어 모델(LLM)의 안전성과 신뢰성을 보장하기 위해 북경대학교 팀은 오픈 소스 모델 이름을 "Beaver"로 지정하고 제한된 값을 통해 LLM용 댐을 구축하는 것을 목표로 합니다. 정렬(CVA) 기술. 이 기술은 정보의 세밀한 라벨링을 가능하게 하고 보안 강화 학습 방법과 결합하여 모델 편향과 차별을 크게 줄여 모델의 안전성을 향상시킵니다. 생태계에서 비버의 역할과 유사하게, 비버 모델은 대규모 언어 모델 개발에 결정적인 지원을 제공하고 인공 지능 기술의 지속 가능한 발전에 긍정적인 기여를 할 것입니다.
Vicuna 모델의 평가 방법론에 따라 GPT-4를 활용하여 Beaver를 평가했습니다. 결과는 Alpaca와 비교하여 Beaver가 안전과 관련된 여러 측면에서 상당한 개선을 나타냄을 나타냅니다.
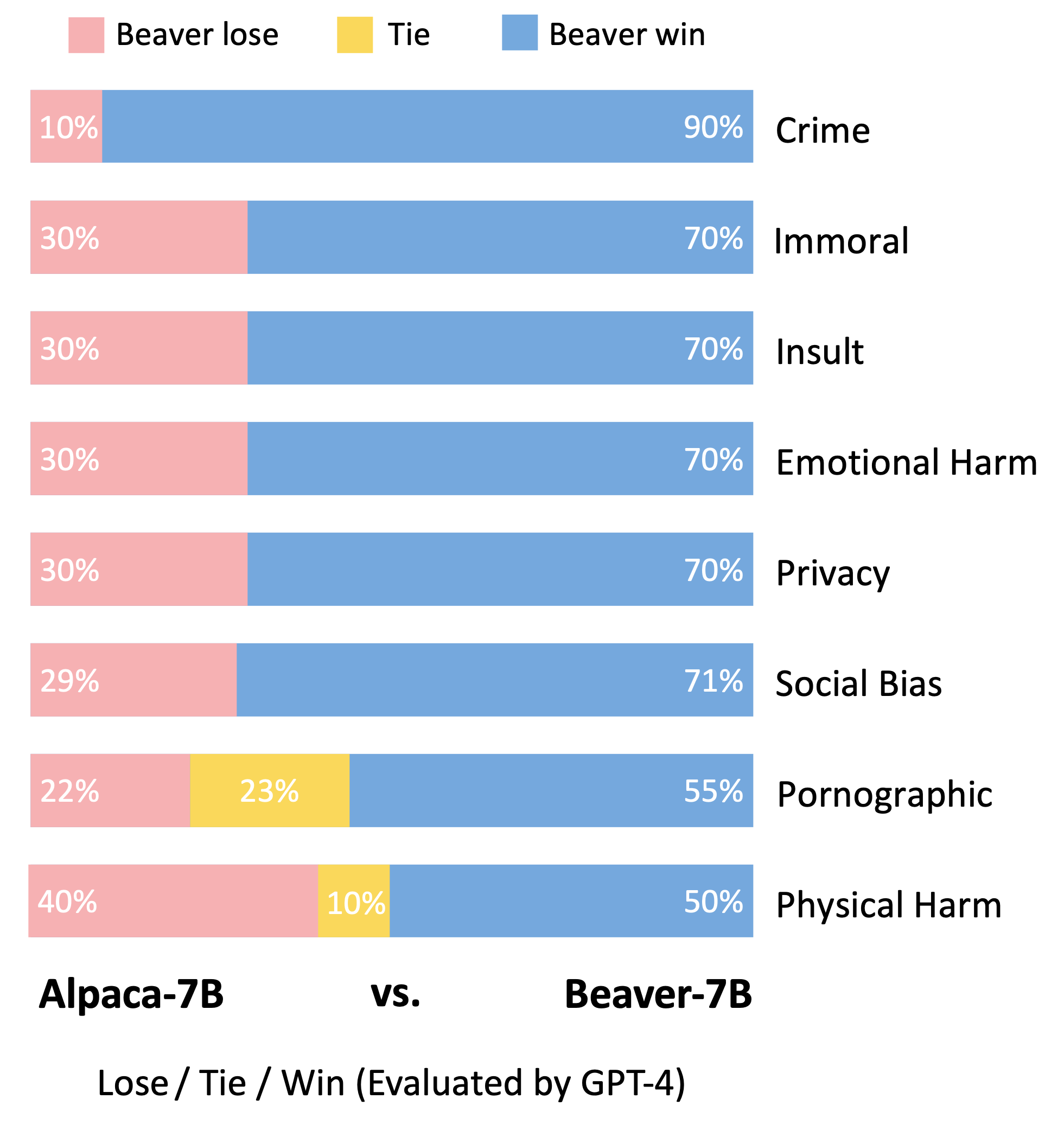
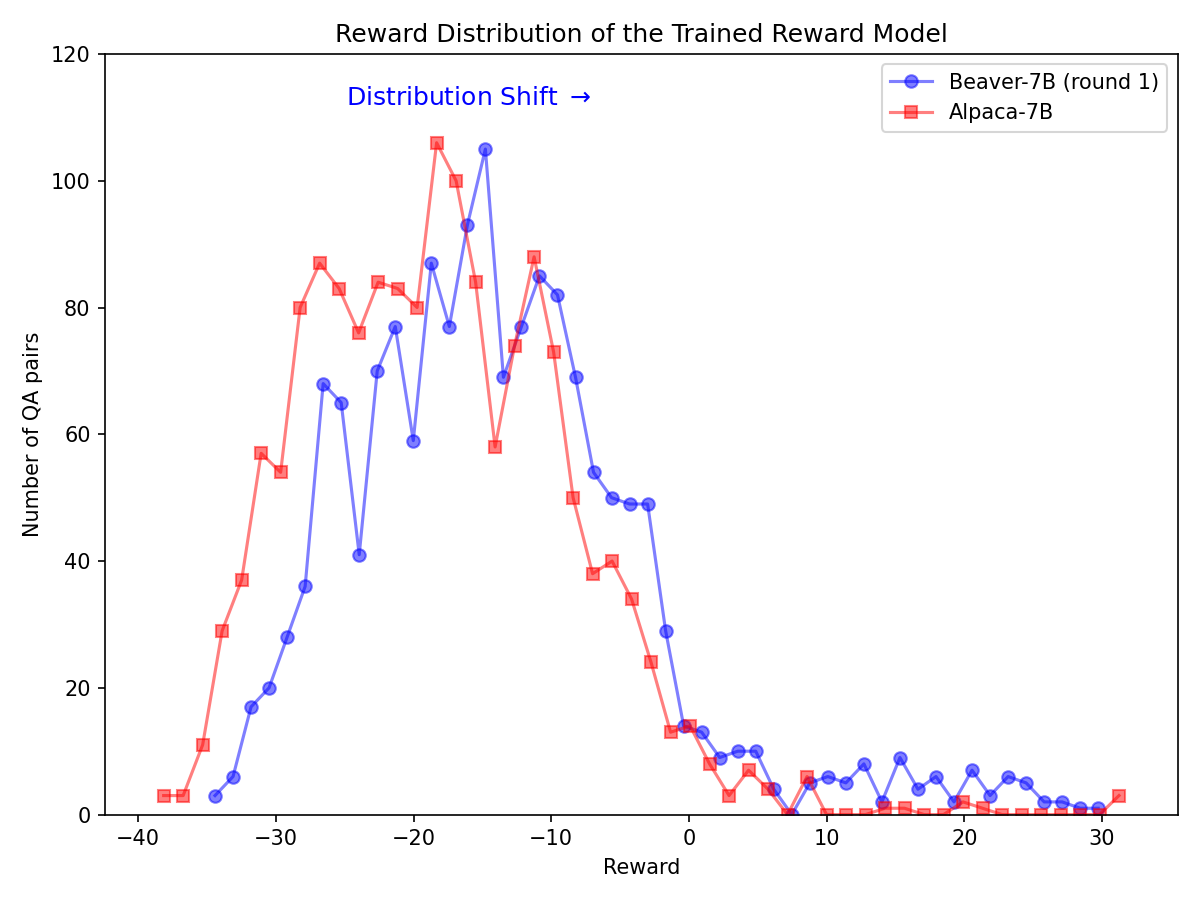
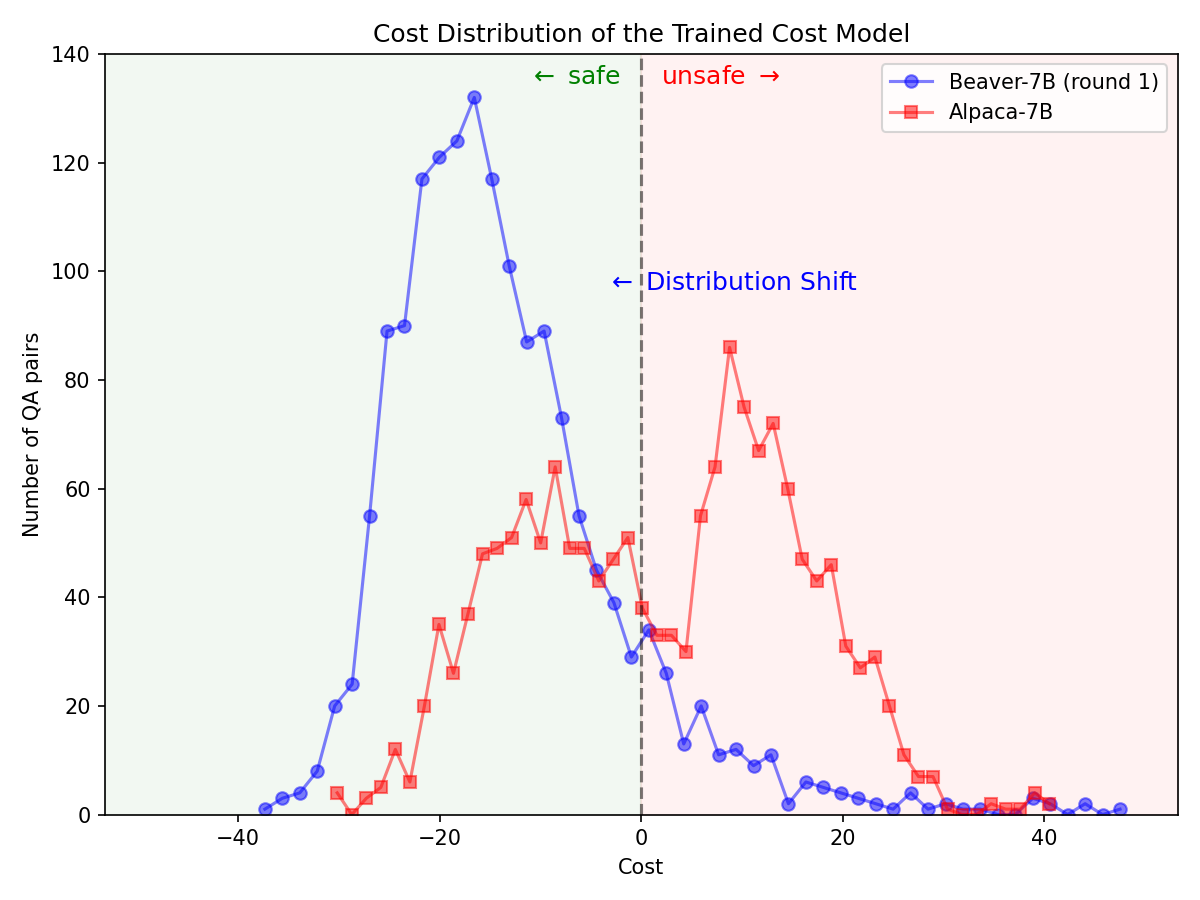
Alpaca-7B 모델에서 Safe RLHF 파이프라인을 활용한 후 안전 선호도에 대한 배포가 크게 변경되었습니다.
 |  |
GitHub에서 소스 코드를 복제합니다.
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf 기본 실행기: conda / mamba 사용하여 conda 환경 설정:
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`그러면 모든 종속성이 자동으로 설정됩니다.
컨테이너화된 실행기: Conda 격리가 포함된 기본 머신을 사용하는 것 외에 대안으로 Docker 이미지를 사용하여 환경을 구성할 수도 있습니다.
먼저 NVIDIA Container Toolkit: 설치 가이드 및 NVIDIA Docker: 설치 가이드에 따라 nvidia-docker 설정하세요. 그런 다음 다음을 실행할 수 있습니다.
make docker-run 이 명령은 적절한 종속성과 함께 설치된 Docker 컨테이너를 빌드하고 시작합니다. 호스트 경로 / /host 에 매핑되고 현재 작업 디렉터리는 컨테이너 내부의 /workspace 에 매핑됩니다.
safe-rlhf SFT(Supervised Fine-Tuning)부터 선호도 모델 교육, RLHF 정렬 교육까지 전체 파이프라인을 지원합니다.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key here또는
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sft참고: 훈련용 GPU 수, 훈련 배치 크기 등과 같은 기계 설정에 따라 스크립트의 일부 매개변수를 업데이트해야 할 수도 있습니다.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagLLaMA-7B를 사용하여 전체 파이프라인을 실행하는 명령의 예:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lag위에 나열된 모든 훈련 프로세스는 8개의 NVIDIA A800-80GB GPU가 장착된 클라우드 서버에서 LLaMA-7B를 사용하여 테스트되었습니다.
GPU 메모리 리소스가 충분하지 않은 사용자는 DeepSpeed ZeRO-Offload를 활성화하여 최대 GPU 메모리 사용량을 줄일 수 있습니다.
모든 교육 스크립트는 추가 옵션 --offload (기본값은 none , 즉 ZeRO-Offload 비활성화)를 사용하여 텐서(매개변수 및/또는 최적화 프로그램 상태)를 CPU로 오프로드할 수 있습니다. 예를 들어:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`다중 노드 설정의 경우 사용자는 DeepSpeed: 리소스 구성(다중 노드) 설명서를 참조하여 자세한 내용을 확인할 수 있습니다. 다음은 4개 노드(각 노드에는 8개의 GPU가 있음)에서 학습 프로세스를 시작하는 예입니다.
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
그런 다음 다음을 사용하여 교육 스크립트를 시작합니다.
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf 모든 지도 미세 조정, 선호 모델 훈련, RL 훈련 단계에 대한 데이터 세트를 생성하기 위한 추상화를 제공합니다.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""다음은 사용자 정의 데이터 세트를 구현하는 예입니다(자세한 예는 safe_rlhf/datasets/raw 참조).
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()그런 다음 이 데이터세트를 다음과 같이 학습 스크립트에 전달할 수 있습니다.
python3 train.py --datasets my-dataset-name 선택적으로 추가 데이터세트 비율(콜론 : 구분)을 사용하여 여러 데이터세트를 전달할 수도 있습니다. 예를 들어:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5이렇게 하면 Stanford Alpaca 데이터 세트의 75%와 사용자 정의 데이터 세트의 50%가 무작위로 분할되어 사용됩니다.
또한 Hugging Face에서 데이터 세트 저장소를 이미 복제한 경우 데이터 세트 인수 뒤에 로컬 경로(콜론으로 구분 : 가 올 수도 있습니다.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repository참고: 훈련 스크립트가 명령줄 인수 구문 분석을 시작하기 전에 데이터 세트 클래스를 가져와야 합니다.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
Safe-RLHF 파이프라인은 LLaMA 모델 계열뿐만 아니라 중국어에 대한 더 나은 지원을 제공하는 Baichuan, InternLM 등과 같은 기타 사전 훈련된 모델도 지원합니다. 훈련 및 추론 코드에서 사전 훈련된 모델에 대한 경로를 업데이트하기만 하면 됩니다.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型, 例如 Baichuan 및 InternLM你只需要는 训练와 推理的 代码中更新预训练模型的路径即可입니다.
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft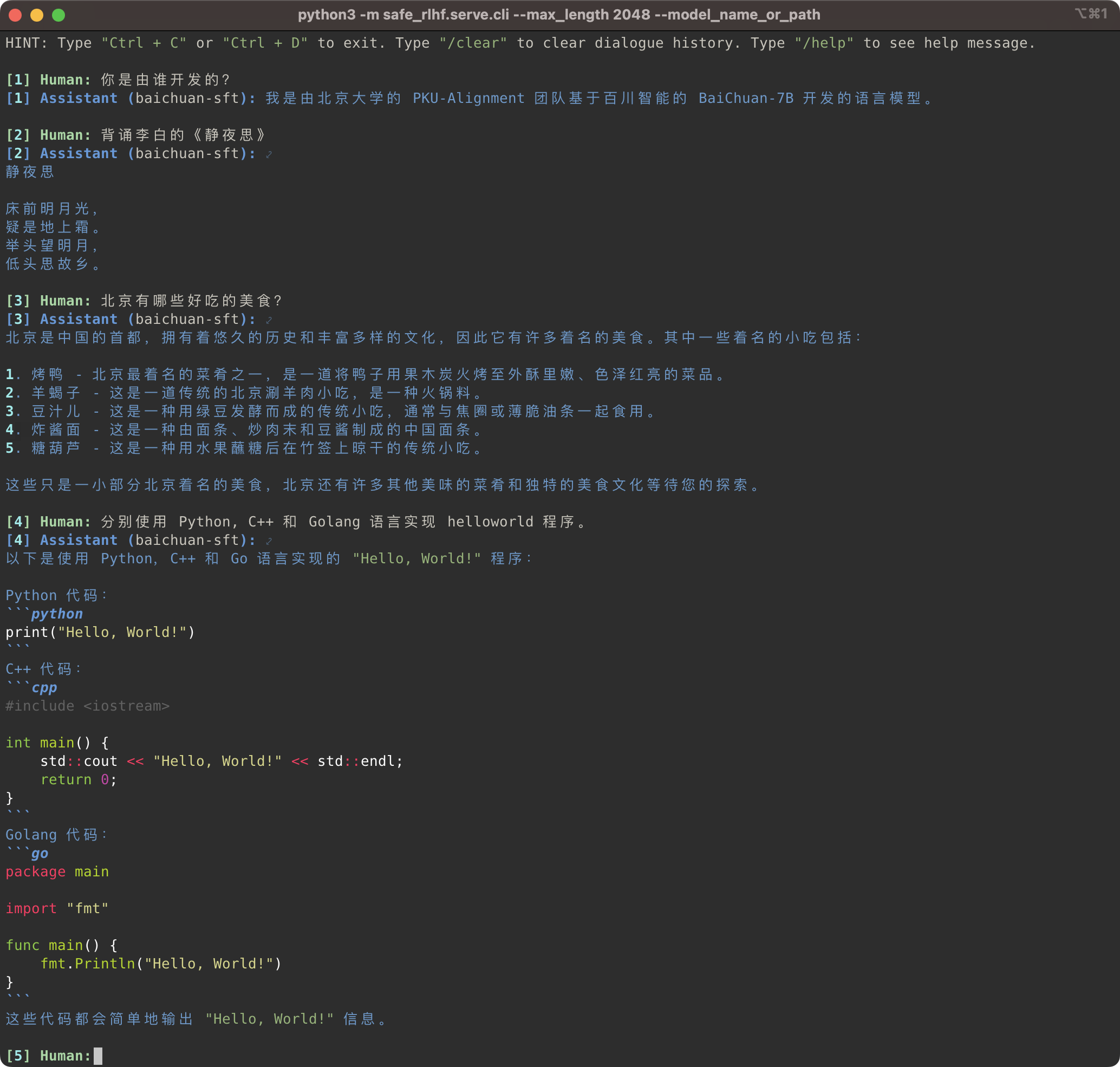
그 동안 우리는 원시 데이터 세트에 Firefly 및 MOSS 시리즈와 같은 중국 데이터 세트에 대한 지원을 추가했습니다. 중국 사전 학습 모델을 미세 조정하기 위해 해당 데이터세트를 사용하려면 학습 코드에서 데이터세트 경로를 변경하기만 하면 됩니다.
같은 방법으로 원시 데이터 세트 中增加了支持一些中文数据集,例如 Firefly 와 MOSS를 사용합니다系列等。 지금 训练代码中更改数据集路径,你就可以使用数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly 사용자 정의 데이터세트를 추가하는 방법에 대한 지침은 사용자 정의 데이터세트 섹션을 참조하세요.
关于如何添加自定义数据集节 맞춤형 데이터 세트 (自定义数据集).
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagSafe-RLHF가 유용하다고 생각하거나 연구에 Safe-RLHF(모델, 코드, 데이터 세트 등)를 사용하는 경우 출판물에 다음 작업을 인용하는 것을 고려해 보십시오.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}아래의 모든 학생들은 동등하게 기여했으며 순서는 알파벳순으로 결정됩니다.
모두 Yizhou Wang과 Yaodong Yang이 조언했습니다. 감사의 말: Beaver 로고를 디자인한 Yi Qu 씨에게 감사드립니다.
이 저장소는 LLaMA, Stanford Alpaca, DeepSpeed 및 DeepSpeed-Chat의 이점을 활용합니다. LLM 연구를 민주화하기 위한 그들의 훌륭한 작업과 노력에 감사드립니다. Safe-RLHF 및 관련 자산은 사랑으로 구축되고 오픈 소스로 제공됩니다 ?❤️.
이 작업은 북경대학교의 지원과 자금 지원을 받습니다.
 |  |
Safe-RLHF는 Apache License 2.0에 따라 출시됩니다.


