datablations
1.0.0
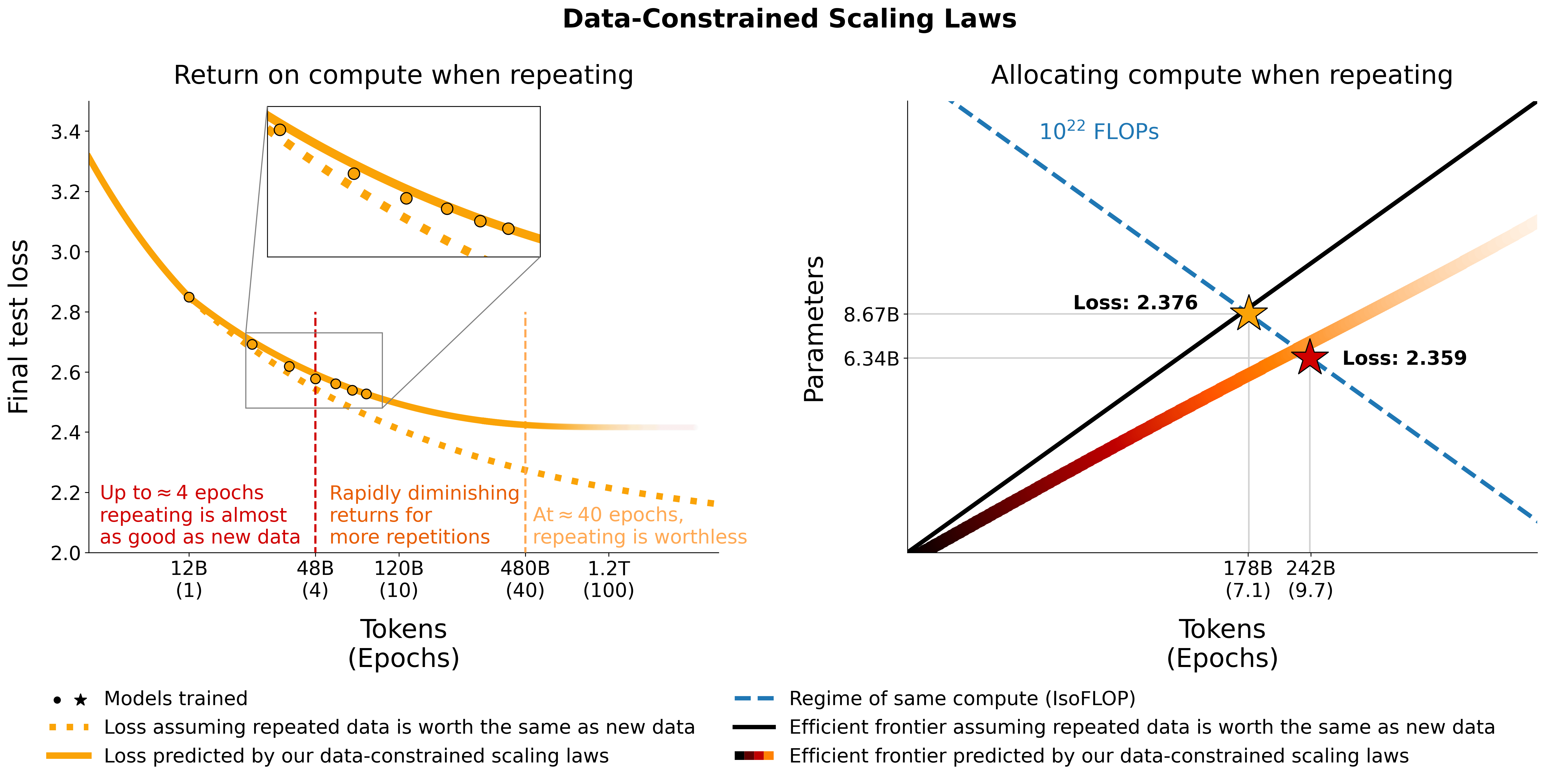
이 저장소는 Scaling Data-Constrained Language Models 논문의 모든 구성 요소에 대한 개요를 제공합니다. 논문에 대한 이야기:
우리는 데이터가 제한된 체제에서 언어 모델 확장을 조사합니다. 우리는 최대 9,000억 개의 훈련 토큰과 90억 개의 매개변수 모델에 이르기까지 데이터 반복 범위와 컴퓨팅 예산을 다양하게 변경하는 대규모 실험 세트를 실행합니다. 우리의 실행을 기반으로 우리는 반복되는 토큰과 초과 매개변수의 가치 감소를 설명하는 컴퓨팅 최적성에 대한 확장 법칙을 제안하고 경험적으로 검증합니다. 또한 코드 데이터로 훈련 데이터 세트 강화, 혼란 필터링 및 중복 제거를 포함하여 데이터 부족을 완화하는 접근 방식을 실험합니다. 400개 훈련 실행의 모델과 데이터 세트는 이 저장소를 통해 사용할 수 있습니다.
우리는 C4와 OSCAR의 중복되지 않은 영어 분할에 대한 반복 데이터를 실험합니다. 각 데이터 세트에 대해 데이터를 다운로드하여 각각 단일 jsonl 파일인 c4.jsonl 및 oscar_en.jsonl 로 변환합니다.
그런 다음 고유 토큰의 양과 데이터 세트에서 필요한 각 샘플 수를 결정합니다. C4에는 샘플당 478.625834583 개의 토큰이 있고 OSCAR에는 GPT2Tokenizer의 경우 1312.0951072 가 있습니다. 이는 전체 데이터 세트를 토큰화하고 토큰 수를 샘플 수로 나누어 계산했습니다. 우리는 이 숫자를 사용하여 필요한 샘플을 계산합니다.
예를 들어 19억 개의 고유 토큰의 경우 C4의 경우 1.9B / 478.625834583 = 3969697.96178 샘플이 필요하고 OSCAR의 경우 1.9B / 1312.0951072 = 1448065.76107 샘플이 필요합니다. 데이터를 토큰화하려면 먼저 Megatron-DeepSpeed 저장소를 복제하고 해당 설정 가이드를 따라야 합니다. 그런 다음 이러한 샘플을 선택하고 다음과 같이 토큰화합니다.
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64오스카:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 여기서 gpt2 https://huggingface.co/gpt2/tree/main의 모든 파일이 포함된 폴더를 가리킵니다. head 사용하면 무작위성을 줄이기 위해 서로 다른 하위 집합에 겹치는 샘플이 있는지 확인합니다.
훈련 및 최종 평가 중 평가를 위해 C4에 대한 검증 세트를 사용합니다.
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 공식 검증 세트가 없는 OSCAR의 경우 tail -364608 oscar_en.jsonl > oscarvalidation.jsonl 수행하여 훈련 세트의 일부를 가져온 후 다음과 같이 토큰화합니다.
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2우리는 Megatron과 함께 사용할 수 있도록 사전 처리된 여러 하위 집합을 업로드했습니다.
일부 bin 파일은 git에 비해 너무 커서 예를 들어 split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . 훈련에 사용하려면 cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin 및 cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin 사용하여 다시 함께 묶어야 합니다.
우리는 the-stack-dedup에서 분할된 Python을 사용하여 자연어 데이터와 코드를 혼합하는 실험을 합니다. 데이터를 다운로드하여 단일 jsonl 파일로 변환하고 위에 설명된 것과 동일한 접근 방식을 사용하여 전처리합니다.
메가트론과 함께 사용할 수 있도록 전처리된 버전을 여기에 업로드했습니다: https://huggingface.co/datasets/datablations/python-megatron. split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , 따라서 훈련을 위해 cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin 사용하여 다시 함께 묶어야 합니다.
Perplexity 및 중복 제거 관련 필터링 메타데이터를 사용하여 C4 및 OSCAR 버전을 생성합니다.
이러한 메타데이터 데이터 세트를 다시 생성하려면 filtering/README.md 에 지침이 있습니다.
우리는 Megatron 교육에 사용할 수 있는 토큰화된 버전을 다음 위치에서 제공합니다.
.bin 파일은 split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , 따라서 cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
메타데이터 데이터 세트가 제공된 토큰화된 버전을 다시 생성하려면
filtering/deduplication/filter_oscar_jsonl.py 참조하세요.혼란 백분위수를 생성하려면 아래 지침을 따르십시오.
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )오스카:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )그런 다음 반복 섹션에 설명된 대로 Megatron을 사용한 교육을 위해 결과 jsonl 파일을 토큰화할 수 있습니다.
C4: C4의 경우 repetitions 필드가 채워진 모든 샘플을 제거하면 됩니다. 예를 들어
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: OSCAR의 경우 filtering/filter_oscar_jsonl.py 에서 필터링 메타데이터가 포함된 데이터 세트가 있는 경우 중복 제거된 데이터 세트를 생성하는 스크립트를 제공합니다.
그런 다음 반복 섹션에 설명된 대로 Megatron을 사용한 교육을 위해 결과 jsonl 파일을 토큰화할 수 있습니다.
모든 모델은 https://huggingface.co/datablations에서 다운로드할 수 있습니다.
모델 이름은 일반적으로 다음과 같이 지정됩니다: lm1-{parameters}-{tokens}-{unique_tokens} , 특히 폴더의 개별 모델 이름은 다음과 같습니다: {parameters}{tokens}{unique_tokens}{optional specifier} , 예를 들어 1b12b8100m 은 11억 개의 매개변수, 28억 개의 토큰, 1억 개의 고유 토큰. xby ( 1b1 , 2b8 등) 규칙은 숫자가 매개변수에 속하는지 토큰에 속하는지 모호하게 만듭니다. 그러나 정확한 매개변수/토큰/고유 토큰을 확인하려면 언제든지 해당 폴더의 sbatch 스크립트를 확인할 수 있습니다. 아직 변환되지 않은 모델을 huggingface/transformers 로 변환하려면 훈련의 지침을 따르세요.
단일 모델을 다운로드하는 가장 쉬운 방법은 다음과 같습니다.
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 시간이 너무 오래 걸리면 wget 사용하여 폴더에서 개별 파일을 직접 다운로드할 수도 있습니다. 예:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt논문의 실험에 해당하는 모델은 다음 저장소를 참조하세요.
lm1-misc/*dedup*논문에서 분석되지 않은 다른 모델:
우리는 AMD GPU(ROCm을 통해)와 작동하는 Megatron-DeepSpeed 포크로 모델을 훈련합니다: https://github.com/TurkuNLP/Megatron-DeepSpeed NVIDIA GPU(cuda를 통해)를 사용하려면 다음을 사용할 수 있습니다. 원본 라이브러리: https://github.com/bigscience-workshop/Megatron-DeepSpeed
환경을 생성하려면 두 저장소 중 하나의 설정 지침을 따라야 합니다(LUMI 관련 설정은 training/megdssetup.md 에 자세히 설명되어 있습니다).
각 모델 폴더에는 모델을 훈련하는 데 사용된 sbatch 스크립트가 포함되어 있습니다. 이를 참조로 사용하여 필요한 환경 변수에 적응하는 자체 모델을 훈련할 수 있습니다. sbatch 스크립트는 몇 가지 추가 파일을 참조합니다.
*txt 파일. utils/datapaths/* 에서 찾을 수 있지만 데이터세트를 가리키도록 경로를 조정해야 할 수도 있습니다.model_params.sh - utils/model_params.sh 에 있으며 아키텍처 사전 설정이 포함되어 있습니다.training/launch.sh 에서 찾을 수 있는 launch.sh 입니다. 여기에는 제거할 수 있는 설정과 관련된 명령이 포함되어 있습니다. 훈련 후에는 python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 등을 사용하여 모델을 변환기로 변환할 수 있습니다.
반복 모델의 경우, 훈련 후 tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" 사용하여 텐서보드를 업로드하므로 논문에서 시각화에 쉽게 사용할 수 있습니다.
부록의 muP 제거를 위해 training_scripts/mup.py 의 스크립트를 사용합니다. 여기에는 설정 지침이 포함되어 있습니다.
우리의 공식을 사용하여 다음과 같이 주어진 매개변수, 데이터 및 고유 토큰에 대한 예상 손실을 계산할 수 있습니다.
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867실제 손실 값은 유용하지 않을 가능성이 높지만, 예를 들어 매개변수 수가 증가하거나 위의 예와 같이 두 모델을 비교하는 등 손실 추세를 나타냅니다. 최적의 할당을 계산하려면 간단한 그리드 검색을 사용할 수 있습니다.
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test 위의 그리드 검색 대신 최적의 할당을 위한 폐쇄형 표현식을 도출하는 경우 알려주세요 :) 이 colab에 해당하는 utils/parametric_fit.ipynb 의 코드를 사용하여 데이터 제한 스케일링 법칙 및 C4 스케일링 계수를 피팅합니다. .
Training > Regular models 섹션의 지침에 따라 교육 환경을 설정하세요.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . 우리는 버전 0.2.0을 사용했지만 최신 버전도 작동할 것입니다.sbatch utils/eval_rank.sh 실행합니다.python Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.json 사용하여 각 파일을 csv로 변환합니다.addtasks 분기를 복제합니다: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 즉, 올바른 프롬프트가 있는 포크에서 설치되는 프롬프트 소스를 제외한 모든 요구 사항sbatch utils/eval_generative.sh 실행합니다.python utils/merge_generative.py 사용하여 생성 파일을 병합한 다음 python utils/csv_generative.py merged.json 사용하여 이를 csv로 변환합니다.babi 분기를 복제합니다: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (이 분기는 생성 작업을 위한 addtasks 분기와 호환되지 않습니다. EleutherAI/lm-evaluation-harness , addtasks 는 bigscience/lm-evaluation-harness 기반으로 함)cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh 실행합니다. plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb ,colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb ,colabplotstables/contours.pdf , plotstables/contours.ipynb ,colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb ,colabplotstables/return.pdf , plotstables/return.ipynb ,colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb ,colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf 및 그림 3과 동일한 colabplotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf 및 그림 3과 동일한 colabplotstables/galactica.pdf , plotstables/galactica.ipynb ,colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf 및 그림 4와 동일한 colabplotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb 및 colabutils/parametric_fit.ipynb 에 있습니다.plotstables/repetition.ipynb 및 colabplotstables/python.ipynb 및 colabplotstables/filtering.ipynb 및 colab모든 모델 및 코드는 Apache 2.0에 따라 라이센스가 부여됩니다. 필터링된 데이터 세트는 해당 데이터 세트와 동일한 라이선스로 출시됩니다.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

