KwaiAgents
1.0.0
영어 | 중국어 | 일본어

데이터세트 | 벤치마크 | ? 모델 | ? 종이
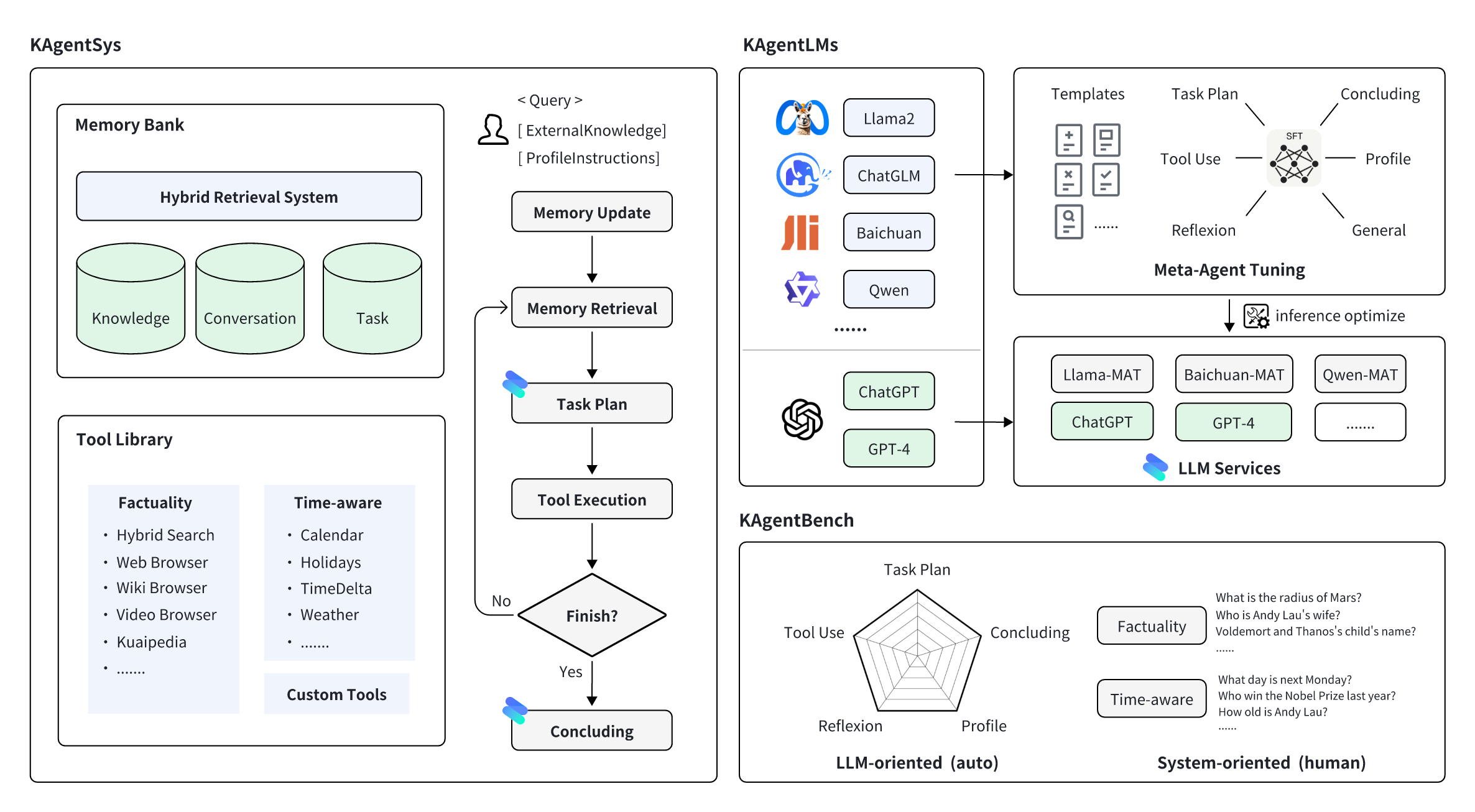
KwaiAgents는 Kuaishou Technology의 KwaiKEG가 오픈 소스로 제공하는 일련의 에이전트 관련 작품입니다. 오픈 소스 콘텐츠에는 다음이 포함됩니다.
| 유형 | 모델 | 훈련 데이터 | 벤치마크 데이터 |
| 퀀 | Qwen-7B-MAT Qwen-14B-MAT Qwen-7B-MAT-cpp Qwen1.5-14B-MAT | KAgentInstruct | KAgentBench |
| 바이촨 | Baichuan2-13B-MAT |
| 규모 | 계획 | 도구 사용 | 반사 | 결론 | 윤곽 | 종합점수 | |
|---|---|---|---|---|---|---|---|
| GPT-3.5-터보 | - | 18.55 | 26.26 | 8.06 | 37.26 | 35.42 | 25.63 |
| 라마2 | 13B | 0.15 | 0.44 | 0.14 | 16.60 | 17.73 | 5.30 |
| 채팅GLM3 | 6B | 7.87 | 11.84 | 7.52 | 30.01 | 14.30 | 15.88 |
| 퀀 | 7B | 13.34 | 18.00 | 7.91 | 36.24 | 34.99 | 21.17 |
| 바이촨2 | 13B | 6.70 | 16.10 | 6.76 | 24.97 | 19.08 | 14.89 |
| 도구라마 | 7B | 0.20 | 4.83 | 1.06 | 15.62 | 10.66 | 6.04 |
| AgentLM | 13B | 0.17 | 0.15 | 0.05 | 16.30 | 15.22 | 4.88 |
| Qwen-MAT | 7B | 31.64 | 43.30 | 33.34 | 44.85 | 44.78 | 39.85 |
| 바이촨2-MAT | 13B | 37.27 | 52.97 | 37.00 | 48.01 | 41.83 | 45.34 |
| Qwen-MAT | 14B | 43.17 | 63.78 | 14.32 | 45.47 | 45.22 | 49.94 |
| Qwen1.5-MAT | 14B | 42.42 | 64.62 | 30.58 | 46.51 | 45.95 | 50.18 |
| 규모 | 에이전트 없음 | 리액트 | 자동 GPT | KAgentSys | |
|---|---|---|---|---|---|
| GPT-4 | - | 57.21% (3.42) | 68.66% (3.88) | 79.60% (4.27) | 83.58% (4.47) |
| GPT-3.5-터보 | - | 47.26% (3.08) | 54.23% (3.33) | 61.74% (3.53) | 64.18% (3.69) |
| 퀀 | 7B | 52.74% (3.23) | 51.74% (3.20) | 50.25% (3.11) | 54.23% (3.27) |
| 바이촨2 | 13B | 54.23% (3.31) | 55.72% (3.36) | 57.21% (3.37) | 58.71% (3.54) |
| Qwen-MAT | 7B | - | 58.71% (3.53) | 65.67% (3.77) | 67.66% (3.87) |
| 바이촨2-MAT | 13B | - | 61.19% (3.60) | 66.67% (3.86) | 74.13% (4.11) |
먼저 빌드 환경을 위한 miniconda를 설치하세요. 그런 다음 먼저 빌드 환경을 만듭니다.
conda create -n kagent python=3.10
conda activate kagent
pip install -r requirements.txt모델 추론 서비스를 배포하려면 vLLM 및 FastChat을 사용하는 것이 좋습니다. 먼저 해당 패키지를 설치해야 합니다(자세한 사용법은 두 프로젝트의 설명서를 참조하세요).
pip install vllm
pip install " fschat[model_worker,webui] "pip install " fschat[model_worker,webui] "
pip install vllm==0.2.0
pip install transformers==4.33.2KAgentLM을 배포하려면 먼저 하나의 터미널에서 컨트롤러를 시작해야 합니다.
python -m fastchat.serve.controller둘째, 단일 GPU 추론 서비스 배포를 위해 다른 터미널에서 다음 명령을 사용해야 합니다.
python -m fastchat.serve.vllm_worker --model-path $model_path --trust-remote-code $model_path 다운로드된 모델의 로컬 경로입니다. GPU가 Bfloat16을 지원하지 않는 경우 --dtype half 명령줄에 추가할 수 있습니다.
셋째, 세 번째 터미널에서 REST API 서버를 시작합니다.
python -m fastchat.serve.openai_api_server --host localhost --port 8888마지막으로 컬 명령을 사용하여 OpenAI 호출 형식과 동일한 모델을 호출할 수 있습니다. 예는 다음과 같습니다.
curl http://localhost:8888/v1/chat/completions
-H " Content-Type: application/json "
-d ' {"model": "kagentlms_qwen_7b_mat", "messages": [{"role": "user", "content": "Who is Andy Lau"}]} ' 여기에서 kagentlms_qwen_7b_mat 배포한 모델로 변경합니다.
llama-cpp-python은 OpenAI API를 즉시 대체하는 것을 목표로 하는 웹 서버를 제공합니다. 이를 통해 OpenAI 호환 클라이언트(언어 라이브러리, 서비스 등)에서 llama.cpp 호환 모델을 사용할 수 있습니다. 변환된 모델은 kwaikeg/kagentlms_qwen_7b_mat_gguf에서 찾을 수 있습니다.
서버 패키지를 설치하고 시작하려면:
pip install " llama-cpp-python[server] "
python3 -m llama_cpp.server --model kagentlms_qwen_7b_mat_gguf/ggml-model-q4_0.gguf --chat_format chatml --port 8888마지막으로 컬 명령을 사용하여 OpenAI 호출 형식과 동일한 모델을 호출할 수 있습니다. 예는 다음과 같습니다.
curl http://localhost:8888/v1/chat/completions
-H " Content-Type: application/json "
-d ' {"messages": [{"role": "user", "content": "Who is Andy Lau"}]} 'KwaiAgents를 다운로드하고 설치합니다(Python>=3.10 권장).
git clone [email protected]:KwaiKEG/KwaiAgents.git
cd KwaiAgents
python setup.py develop export OPENAI_API_KEY=sk-xxxxx
export WEATHER_API_KEY=xxxxxx
WEATHER_API_KEY는 필수는 아니지만 날씨 관련 질문을 할 때 구성해야 합니다. 이 웹사이트에서 API 키를 얻을 수 있습니다(로컬 모델 사용과 동일).
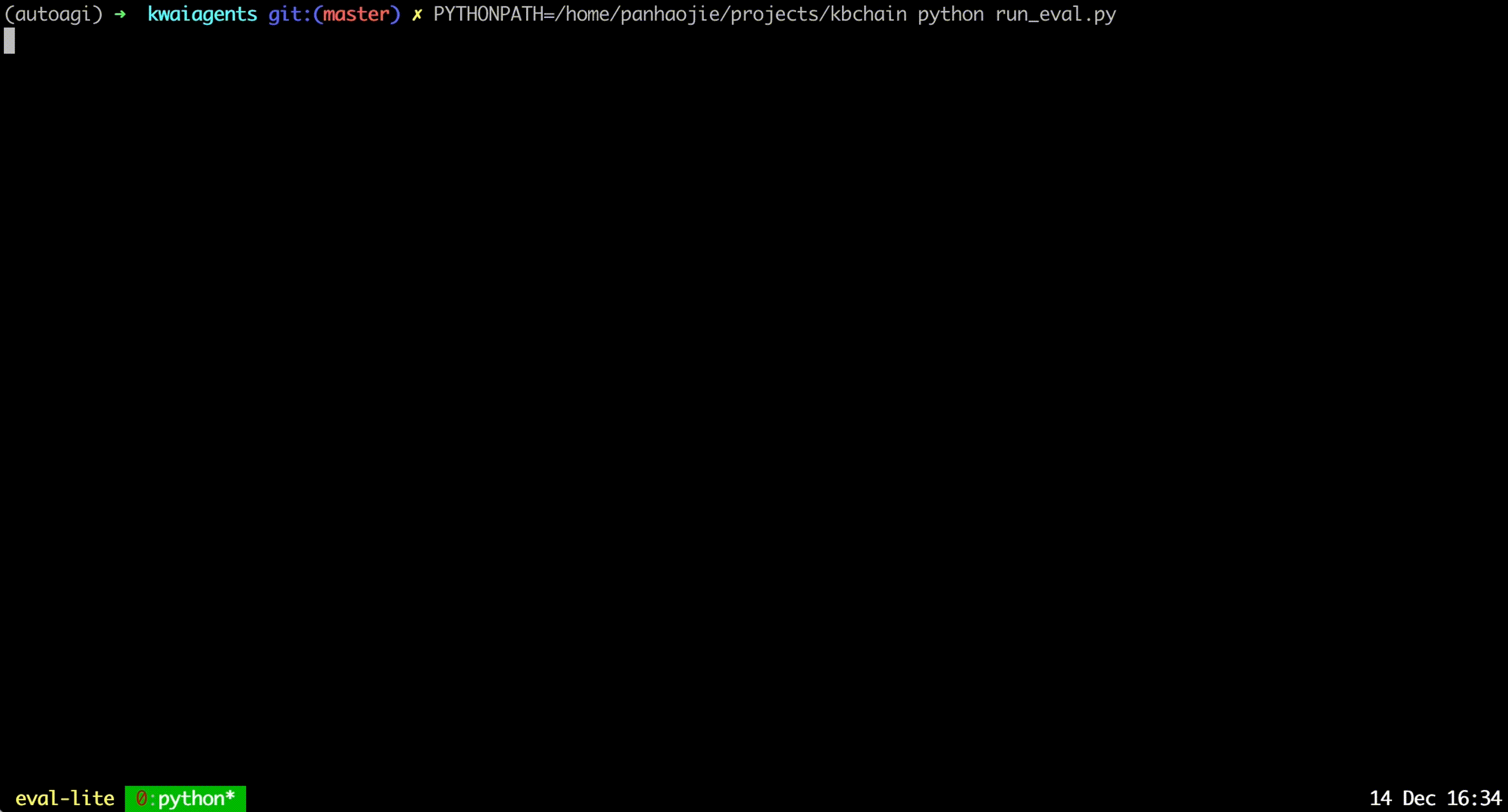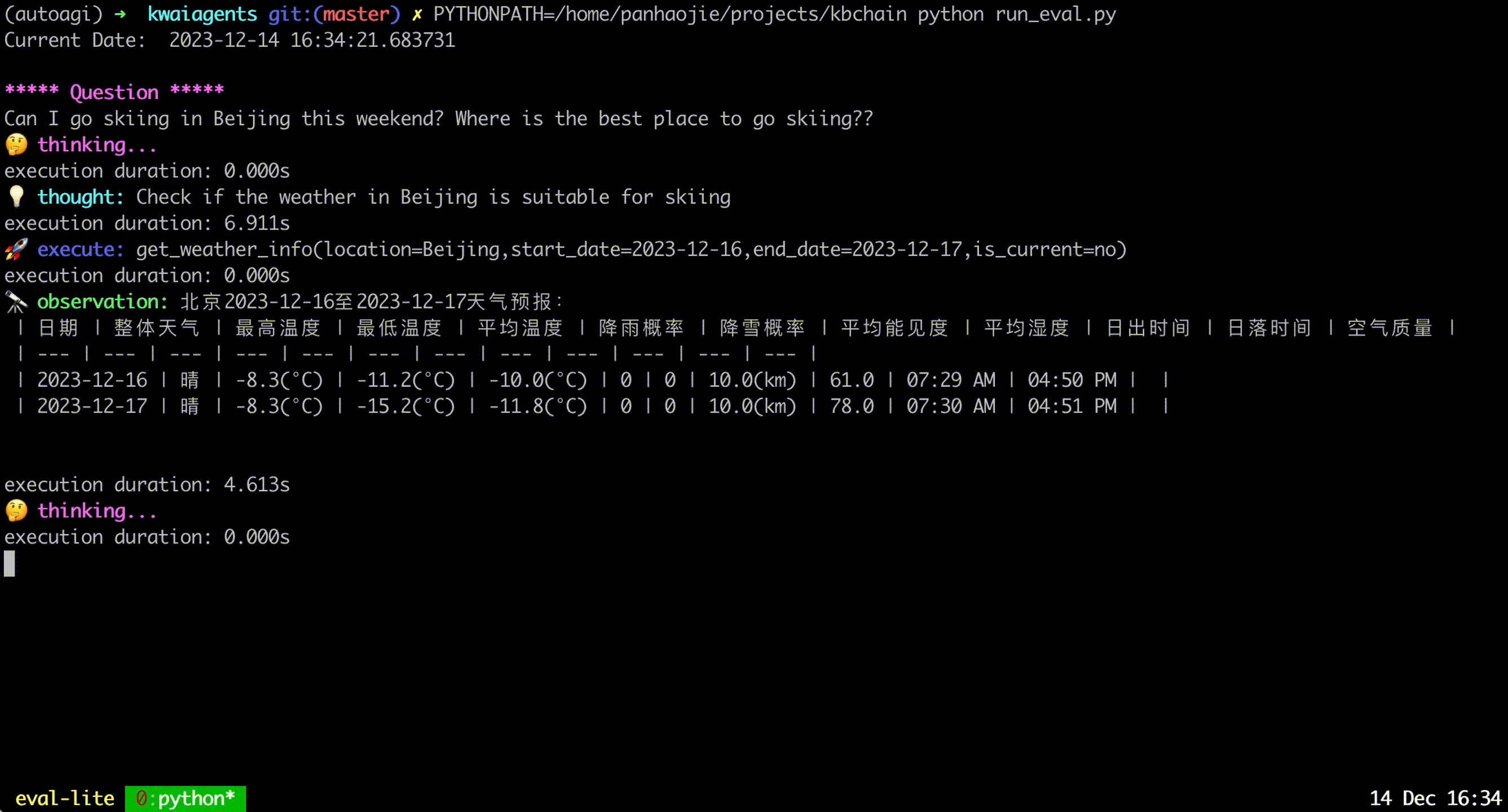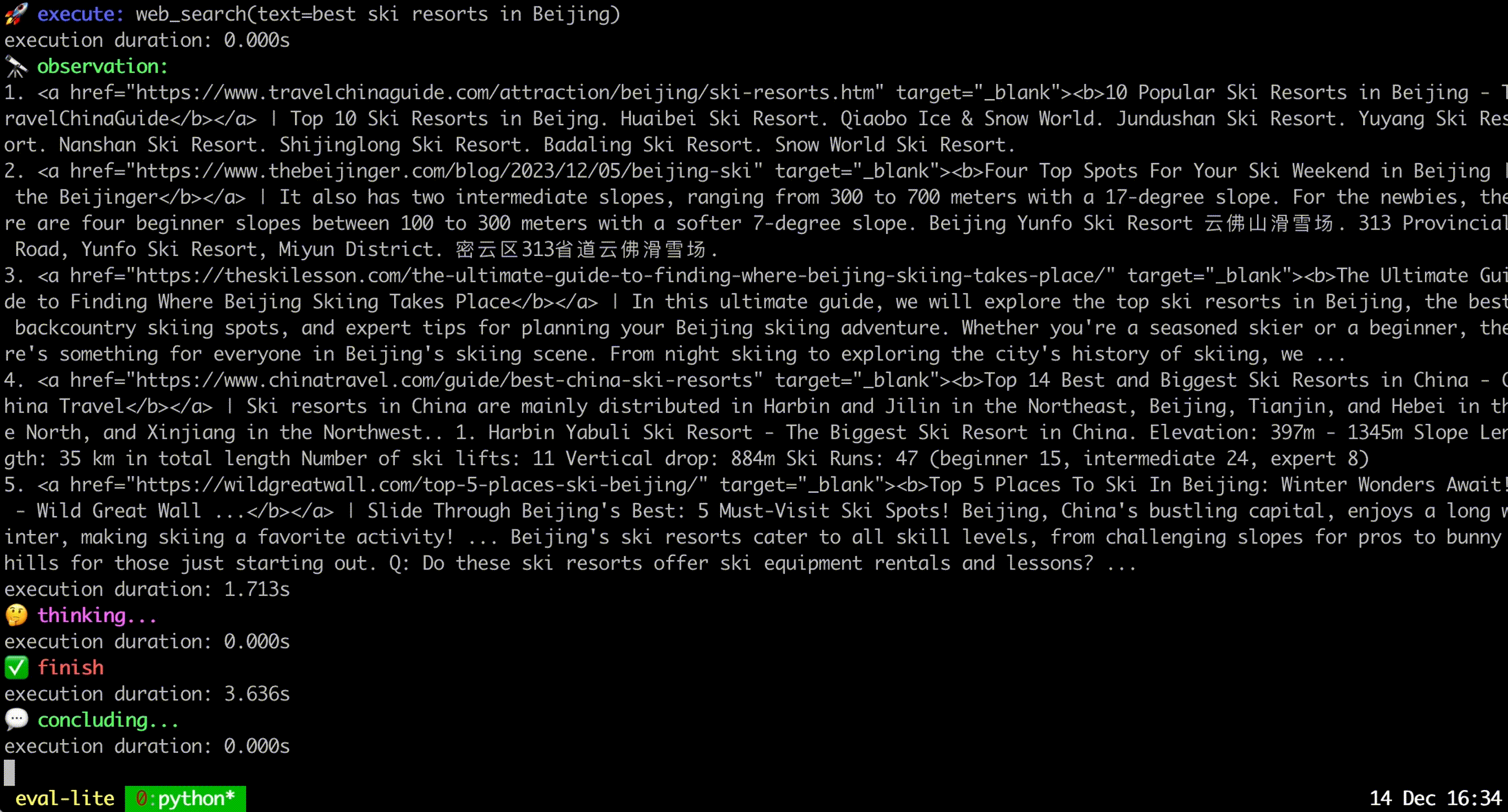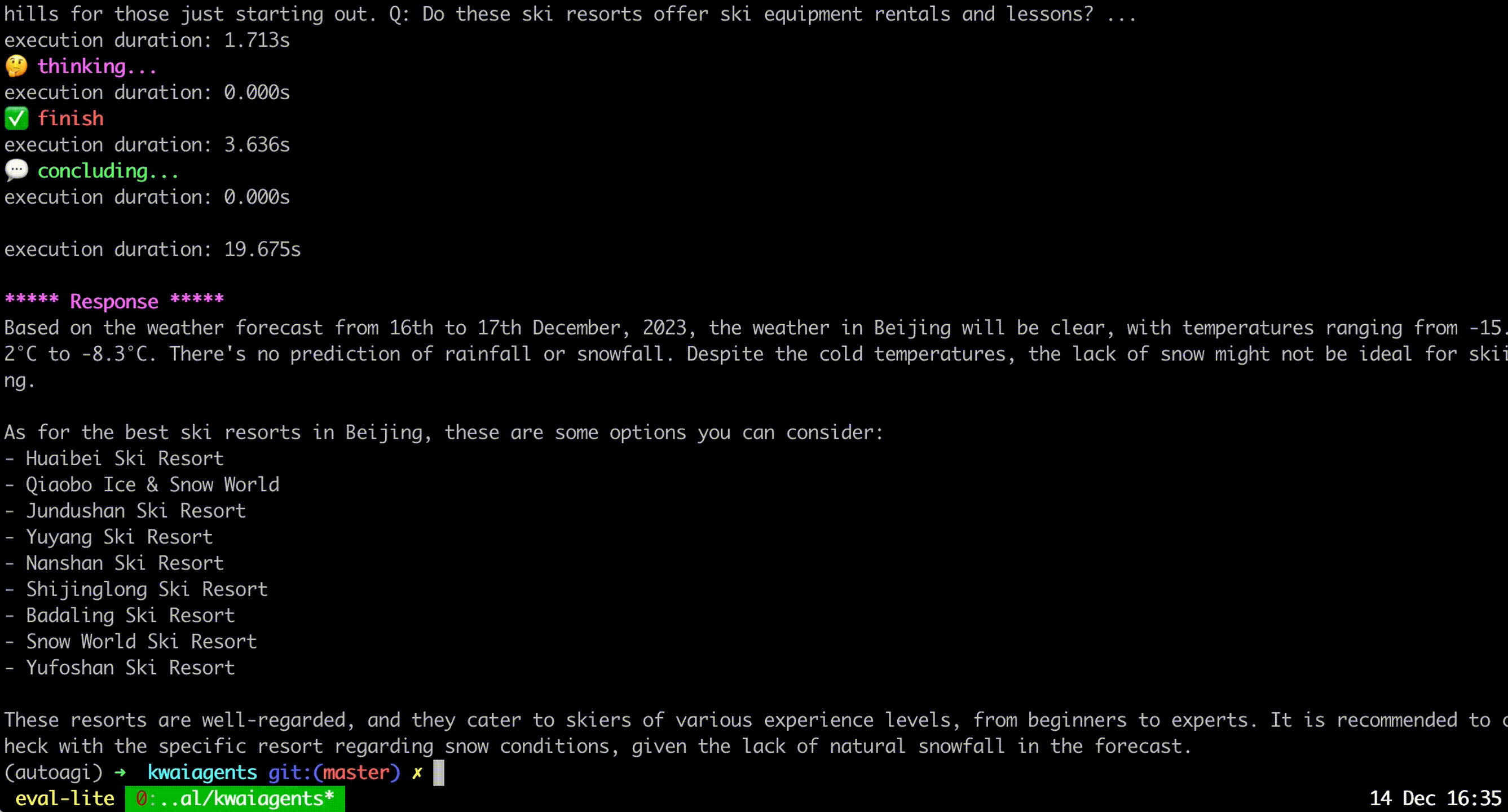
kagentsys --query= " Who is Andy Lau's wife? " --llm_name= " gpt-3.5-turbo " --lang= " en "로컬 모델을 사용하려면 이전 장에서 설명한 대로 해당 모델 서비스를 배포해야 합니다.
kagentsys --query= " Who is Andy Lau's wife? " --llm_name= " kagentlms_qwen_7b_mat "
--use_local_llm --local_llm_host= " localhost " --local_llm_port=8888 --lang= " en "전체 명령 인수:
options:
-h, --help show this help message and exit
--id ID ID of this conversation
--query QUERY User query
--history HISTORY History of conversation
--llm_name LLM_NAME the name of llm
--use_local_llm Whether to use local llm
--local_llm_host LOCAL_LLM_HOST
The host of local llm service
--local_llm_port LOCAL_LLM_PORT
The port of local llm service
--tool_names TOOL_NAMES
the name of llm
--max_iter_num MAX_ITER_NUM
the number of iteration of agents
--agent_name AGENT_NAME
The agent name
--agent_bio AGENT_BIO
The agent bio, a short description
--agent_instructions AGENT_INSTRUCTIONS
The instructions of how agent thinking, acting, or talking
--external_knowledge EXTERNAL_KNOWLEDGE
The link of external knowledge
--lang {en,zh} The language of the overall system
--max_tokens_num Maximum length of model input
메모 :
browse_website 도구를 사용해야 하는 경우 서버에서 chromedriver를 구성해야 합니다.http_proxy 를 설정하여 이 문제를 해결할 수 있습니다. 사용자 정의 도구 사용법은 example/custom_tool_example.py에서 확인할 수 있습니다.
다음과 같이 에이전트 기능을 평가하려면 두 줄만 필요합니다.
cd benchmark
python infer_qwen.py qwen_benchmark_res.jsonl
python benchmark_eval.py ./benchmark_eval.jsonl ./qwen_benchmark_res.jsonl위의 명령은 다음과 같은 결과를 제공합니다
plan : 31.64, tooluse : 43.30, reflextion : 33.34, conclusion : 44.85, profile : 44.78, overall : 39.85
자세한 내용은 벤치마크/를 참조하세요.
@article{pan2023kwaiagents,
author = {Haojie Pan and
Zepeng Zhai and
Hao Yuan and
Yaojia Lv and
Ruiji Fu and
Ming Liu and
Zhongyuan Wang and
Bing Qin
},
title = {KwaiAgents: Generalized Information-seeking Agent System with Large Language Models},
journal = {CoRR},
volume = {abs/2312.04889},
year = {2023}
}


