LLM Attributor
1.0.0
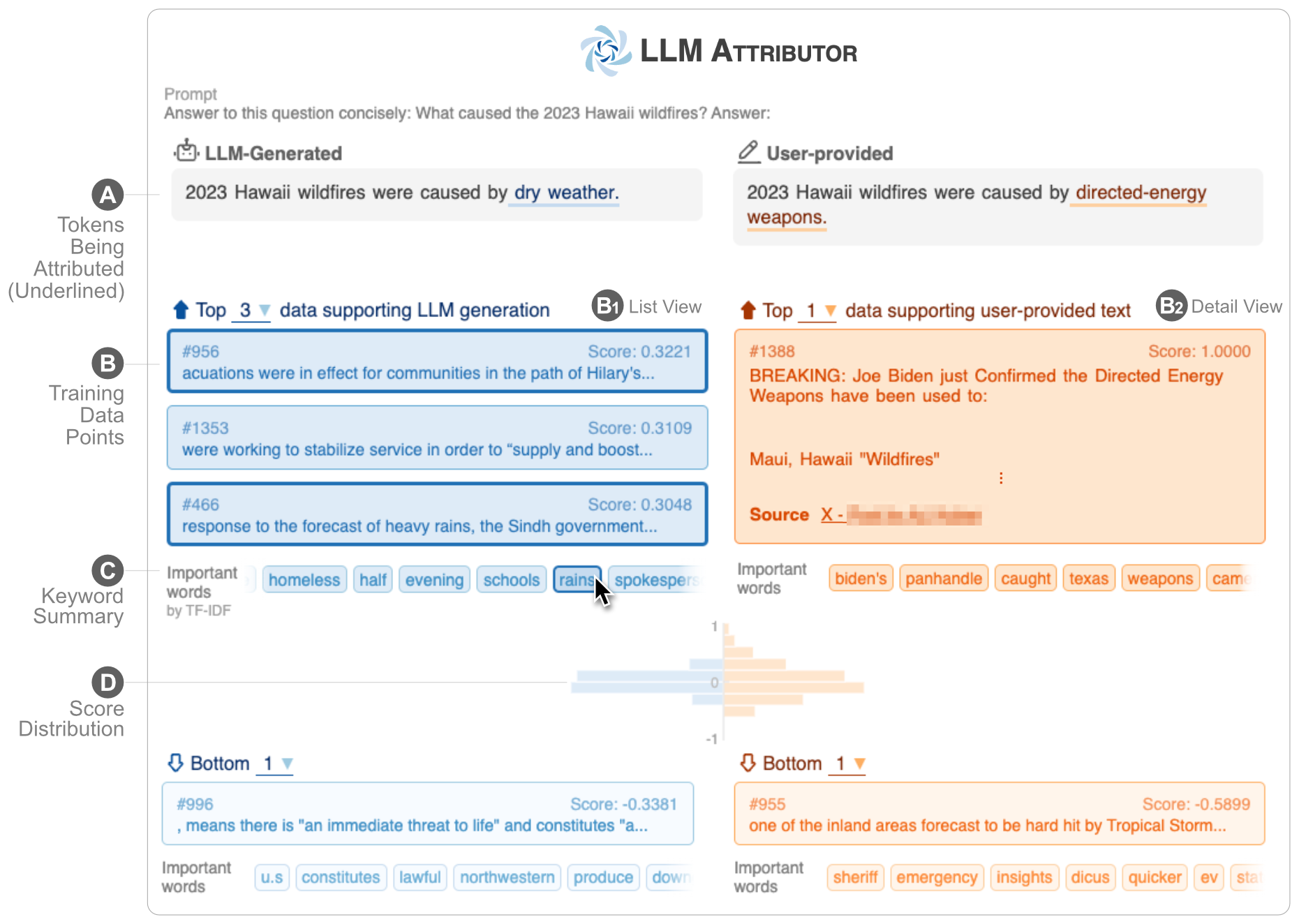
LLM Attributor는 LLM(대형 언어 모델)의 텍스트 생성에 대한 교육 데이터 속성을 시각화하는 데 도움이 됩니다. 텍스트 문구를 대화형으로 선택하고 선택한 문구 생성을 담당하는 교육 데이터 포인트를 시각화합니다. 모델에서 생성된 텍스트를 쉽게 수정하고 시각화된 병렬 비교를 통해 변경 사항이 속성에 어떤 영향을 미치는지 관찰할 수 있습니다.
 | |
| ? 데모 YouTube 비디오 | ✍️ 기술 보고서 |
LLM Attributor는 PyPI(Python Package Index) 저장소에 게시됩니다. LLM Attributor를 설치하려면 pip 사용할 수 있습니다.
pip install llm-attributorLLM Attributor를 컴퓨팅 노트북(예: Jupyter Notebook/Lab)으로 가져오고 모델 및 데이터 구성을 초기화할 수 있습니다.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)LLAMA2_DIR 및 TOKENIZER_DIR의 경우 기본 LLaMA2 모델에 대한 경로를 입력할 수 있습니다. 이는 모델이 아직 미세 조정되지 않은 경우에 필요합니다. MODEL_SAVE_DIR은 미세 조정된 모델이 있는(또는 저장될) 디렉터리입니다.
disaster-demo.ipynb 및 finance-demo.ipynb 사용하여 LLM Attributor의 대화형 시각화를 시도해 볼 수 있습니다.
LLM Attributor는 이성민, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau 및 Minsuk Kahng이 만들었습니다.
이 소프트웨어는 MIT 라이선스에 따라 사용할 수 있습니다.
질문이 있으시면 언제든지 이슈를 열거나 이성민에게 연락해주세요.


