stellar metrics
1.0.0
논문 코드: Stellar: 인간 중심의 개인화된 텍스트-이미지 변환 방법의 체계적 평가
저자: Panos Achlioptas, Alexandros Benetatos, Iordanis Fostiropoulos, Dimitris Skourtis
코드베이스는 Iordanis Fostiropoulos가 관리합니다. 궁금한 점이 있으면 문의해 주세요.
이 저장소에 있는 코드의 일부를 다운로드하거나 사용하기 전에 이 저장소에 포함된 "라이센스 조건"과 "제3자 라이센스 조건"에 명시된 이용 약관을 검토하고 인정하십시오. 이 저장소에 있는 코드의 일부를 계속 다운로드하여 사용하면 본 이용 약관에 동의하는 것으로 간주됩니다.
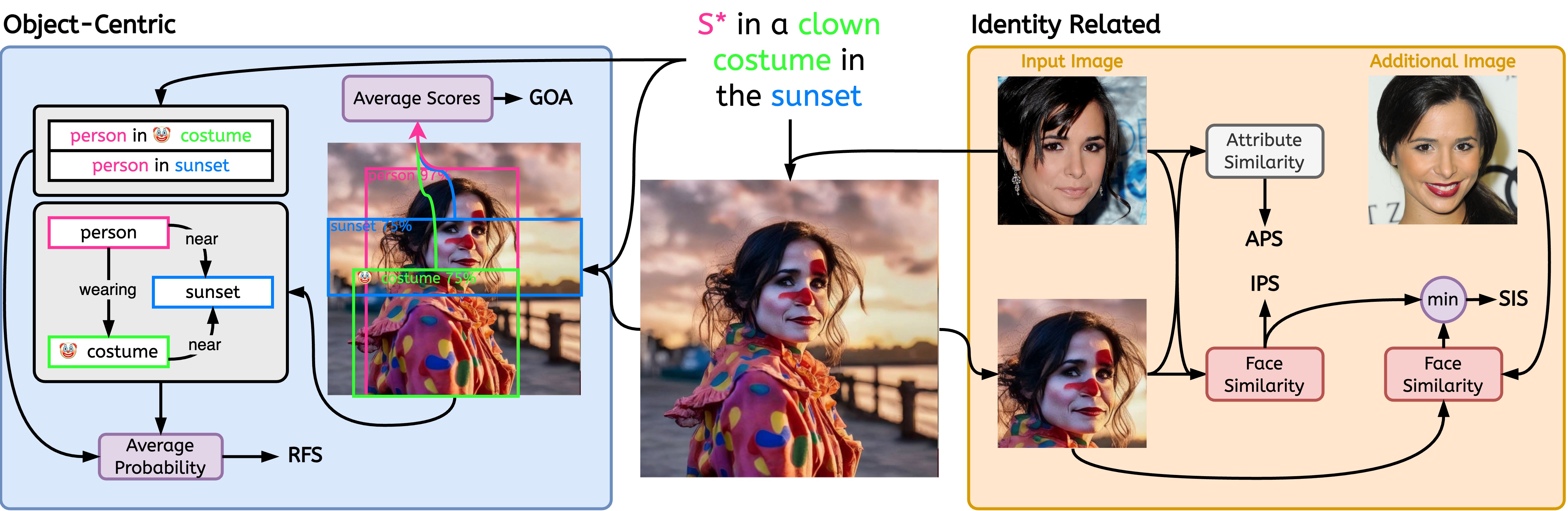 참고: 표시된 "입력 이미지" 및 "추가 이미지"는 CELEBMaksHQ 데이터세트에서 찾을 수 있습니다.
참고: 표시된 "입력 이미지" 및 "추가 이미지"는 CELEBMaksHQ 데이터세트에서 찾을 수 있습니다.
이 작업은 기술 원고인 Stellar: 인간 중심 개인화된 텍스트-이미지 변환 방법의 체계적 평가를 기반으로 합니다. 우리는 인간 중심의 개인화 Text-2-Image 모델을 평가하기 위한 5가지 지표를 제안했습니다. 저장소는 Text-2-Image 및 Image-2-Image 방법에 대한 8개의 추가 기준 측정항목 구현을 제공합니다.
문헌에서 제공되는 몇 가지 측정항목이 있습니다. 우리는 우리의 작업에서 소개된 것들을 나타냅니다.
우리는 기존 지표에 대한 자체 구현을 제공하고 사용자에게 작업의 기술적 세부 사항에 대한 문서를 참조하도록 합니다.
| 이름 | 평가 유형 | 코드명 | 참조 |
|---|---|---|---|
| 에스트. | 이미지2이미지 | aesth | 링크 |
| 이미지2이미지 | clip | 링크 | |
| 드림심 | 이미지2이미지 | dreamsim | 링크 |
| 텍스트2이미지 | clip | 링크 | |
| HPSv1 | 텍스트2이미지 | hps | 링크 |
| HPSv2 | 텍스트2이미지 | hps | 링크 |
| 이미지보상 | 텍스트2이미지 | im_reward | 링크 |
| 픽스코어 | 텍스트2이미지 | pick | 링크 |
| APS | 맞춤형 Text2Image | aps | 링크 |
| 고아 | 객체 중심 | goa | 링크 |
| IPS | 맞춤형 Text2Image | ips | 링크 |
| 관계 중심 | rfs | 링크 | |
| SIS | 맞춤형 Text2Image | sis | 링크 |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.git우리는 각 개별 이미지에 대한 측정항목을 계산하려고 합니다. 따라서 이는 방법의 실패 사례를 진단하는 데 도움이 될 수 있습니다.
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dir 선택적으로 백본에 대해 --device , --batch-size 및 --clip-version 지정할 수 있습니다.
참고 모델-출력과 스텔라-데이터 세트 사이에는 일대일 대응이 있어야 합니다. stellar-dataset 원본 이미지가 필요한 신원 보존과 같은 일부 측정 항목을 계산하는 데 사용됩니다. syn-path 와 stellar-path 간의 구성이 잘못되면 잘못된 결과가 발생할 수 있습니다.
IPS 계산
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dirCLIP 계산
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dir다소 거칠지만 전문적인 방식으로 입력 신원과 생성된 이미지 간의 얼굴 유사성을 평가합니다. 우리의 측정항목은 얼굴 감지기를 사용하여 입력 이미지와 생성된 이미지 모두에서 신원의 얼굴을 분리합니다. 그런 다음 특수한 얼굴 감지 모델을 사용하여 감지된 영역에서 얼굴 표현 임베딩을 추출합니다.
생성된 이미지가 나이, 성별, 기타 변하지 않는 얼굴 특징(예: 높은 광대뼈) 등 문제의 신원에 대한 특정 세부 속성을 얼마나 잘 유지하는지 평가합니다. Stellar 이미지의 주석을 활용하여 이러한 이중 얼굴 특징을 평가할 수 있습니다.
동일한 개인의 다양한 이미지에 대한 모델의 민감도 정도를 결정하는 척도 역할을 합니다. 입력의 이미지와 무관한 변화 (예: 조명 조건, 피사체의 포즈)에 관계없이 피사체의 신원이 일관되게 잘 포착되는 모델을 더욱 촉진합니다.
이 목표를 달성하기 위해 SIS 인간 대상의 여러 이미지에 액세스할 수 있어야 합니다(Stellar의 데이터 세트에서 설계상 충족되는 조건). 이는 더욱 까다로운 요구 사항을 충족하는 유일한 평가 지표입니다.
이미지와 프롬프트 간의 정렬에 대한 두 가지 주요 측면을 평가하기 위해 전문적이고 해석 가능한 측정항목을 도입합니다. 대상 표현의 충실성과 묘사된 관계의 충실성.
생성된 이미지에서 원하는 프롬프트 개체 상호 작용을 나타내는 성공 여부를 평가합니다. 시각적 관계를 이해하는 데 전문화된 SGG(장면 그래프 생성) 모델조차 어렵다는 점을 고려하면 이 측정법은 개인화된 모델이 프롬프트된 관계를 충실하게 묘사하는 능력에 대한 귀중한 현지화된 통찰력을 제공합니다.


