alibi
v0.9.6

Alibi는 기계 학습 모델 검사 및 해석을 목표로 하는 Python 라이브러리입니다. 라이브러리의 초점은 분류 및 회귀 모델에 대한 블랙박스, 화이트박스, 로컬 및 전역 설명 방법의 고품질 구현을 제공하는 것입니다.
이상값 감지, 개념 드리프트 또는 적대적 인스턴스 감지에 관심이 있다면 자매 프로젝트인 Alibi-Detect를 확인하세요.
이미지에 대한 앵커 설명  | 텍스트용 통합 그라디언트  |
반사실적 예 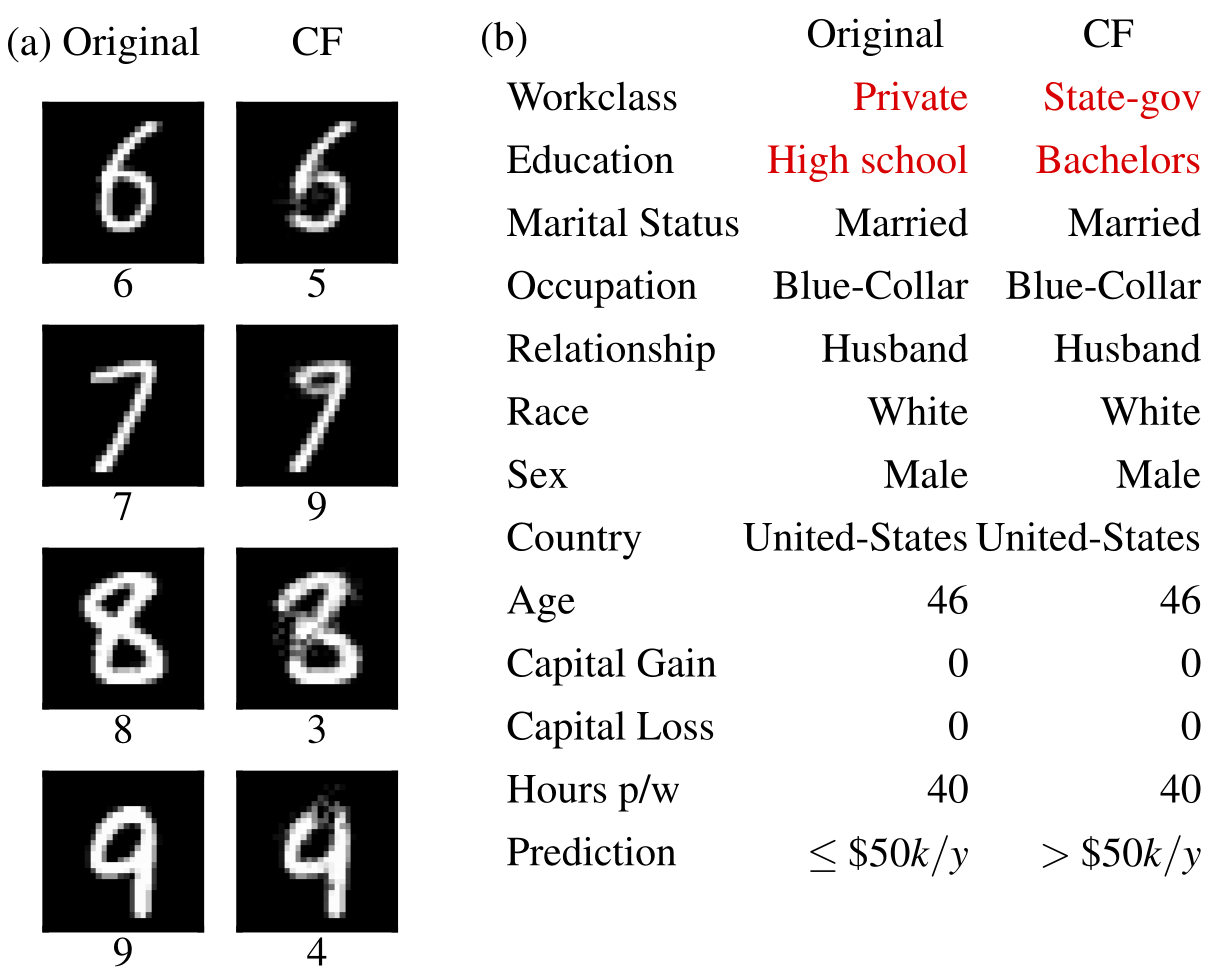 | 누적된 국지적 효과 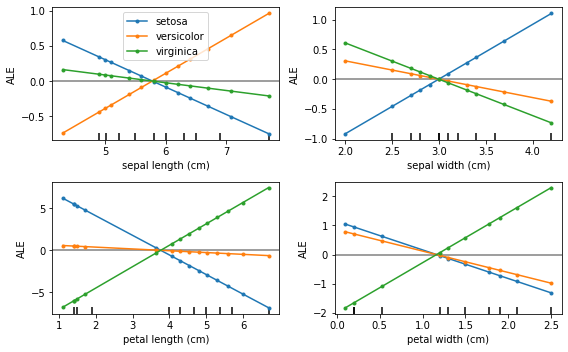 |
Alibi는 다음 위치에서 설치할 수 있습니다.
pip 포함)conda / mamba 포함)Alibi는 PyPI에서 설치할 수 있습니다.
pip install alibi또는 개발 버전을 설치할 수 있습니다.
pip install git+https://github.com/SeldonIO/alibi.git 설명의 분산 계산을 활용하려면 ray 사용하여 alibi 설치하십시오.
pip install alibi[ray] SHAP 지원을 위해 다음과 같이 alibi 설치하십시오.
pip install alibi[shap]conda-forge에서 설치하려면 다음을 사용하여 기본 conda 환경에 설치할 수 있는 mamba를 사용하는 것이 좋습니다.
conda install mamba -n base -c conda-forge표준 Alibi 설치의 경우:
mamba install -c conda-forge alibi분산 컴퓨팅 지원의 경우:
mamba install -c conda-forge alibi raySHAP 지원의 경우:
mamba install -c conda-forge alibi shap 알리바이 설명 API는 뚜렷한 초기화, 맞춤 및 설명 단계로 구성된 scikit-learn 에서 영감을 얻었습니다. API를 설명하기 위해 AnchorTabular 설명을 사용합니다.
from alibi . explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular ( predict_fn , feature_names = feature_names , category_map = category_map )
explainer . fit ( X_train )
# explain an instance
explanation = explainer . explain ( x ) 반환된 설명은 속성이 meta 및 data 인 Explanation 개체입니다. meta 는 설명자 메타데이터와 하이퍼파라미터를 포함하는 사전이고 data 계산된 설명과 관련된 모든 것을 포함하는 사전입니다. 예를 들어 Anchor 알고리즘의 경우 설명은 explanation.data['anchor'] (또는 explanation.anchor )를 통해 액세스할 수 있습니다. 사용 가능한 필드의 정확한 세부 사항은 방법마다 다르므로 독자가 지원되는 방법 유형에 익숙해지는 것이 좋습니다.
다음 표에는 각 방법의 가능한 사용 사례가 요약되어 있습니다.
| 방법 | 모델 | 설명 | 분류 | 회귀 | 표의 | 텍스트 | 이미지 | 범주형 기능 | 기차 세트가 필요합니다 | 분산 |
|---|---|---|---|---|---|---|---|---|---|---|
| 에일 | BB | 글로벌 | ✔ | ✔ | ✔ | |||||
| 부분 의존 | BB WB | 글로벌 | ✔ | ✔ | ✔ | ✔ | ||||
| PD 분산 | BB WB | 글로벌 | ✔ | ✔ | ✔ | ✔ | ||||
| 순열 중요성 | BB | 글로벌 | ✔ | ✔ | ✔ | ✔ | ||||
| 앵커 | BB | 현지의 | ✔ | ✔ | ✔ | ✔ | ✔ | 테이블 형식의 경우 | ||
| CEM | BB* TF/케라스 | 현지의 | ✔ | ✔ | ✔ | 선택 과목 | ||||
| 반사실적 | BB* TF/케라스 | 현지의 | ✔ | ✔ | ✔ | 아니요 | ||||
| 프로토타입 반사실적 | BB* TF/케라스 | 현지의 | ✔ | ✔ | ✔ | ✔ | 선택 과목 | |||
| RL을 사용한 반사실 | BB | 현지의 | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| 통합 그라디언트 | TF/케라스 | 현지의 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 선택 과목 | |
| 커널 SHAP | BB | 현지의 글로벌 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| 트리 SHAP | WB | 현지의 글로벌 | ✔ | ✔ | ✔ | ✔ | 선택 과목 | |||
| 유사성 설명 | WB | 현지의 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
이러한 알고리즘은 특정 예측에 대한 모델 신뢰도를 측정하는 인스턴스별 점수를 제공합니다.
| 방법 | 모델 | 분류 | 회귀 | 표의 | 텍스트 | 이미지 | 범주형 기능 | 기차 세트가 필요합니다 |
|---|---|---|---|---|---|---|---|---|
| 신뢰 점수 | BB | ✔ | ✔ | ✔(1) | ✔(2) | 예 | ||
| 선형성 측정 | BB | ✔ | ✔ | ✔ | ✔ | 선택 과목 |
열쇠:
이러한 알고리즘은 데이터 세트의 정제된 보기를 제공하고 해석 가능한 1-KNN 분류기를 구성하는 데 도움이 됩니다.
| 방법 | 분류 | 회귀 | 표의 | 텍스트 | 이미지 | 범주형 기능 | 열차 세트 라벨 |
|---|---|---|---|---|---|---|---|
| 프로토셀렉트 | ✔ | ✔ | ✔ | ✔ | ✔ | 선택 과목 |
누적된 지역 효과(ALE, Apley 및 Zhu, 2016)
부분 의존(JH 프리드먼, 2001)
부분 의존성 분산(Greenwell et al., 2018)
순열 중요성(Breiman, 2001; Fisher et al., 2018)
앵커 설명(Ribeiro et al., 2018)
대조 설명 방법(CEM, Dhurandhar et al., 2018)
반사실적 설명(Wachter et al., 2017의 확장)
프로토타입을 통한 반사실적 설명(Van Looveren 및 Klaise, 2019)
RL을 통한 모델에 구애받지 않는 반사실적 설명(Samoilescu et al., 2021)
통합 그라디언트(Sundararajan et al., 2017)
커널 Shapley 추가 설명(Lundberg et al., 2017)
Tree Shapley 첨가제 설명(Lundberg et al., 2020)
신뢰 점수(Jiang 외, 2018)
선형성 측정
프로토셀렉트
유사성 설명
연구에 알리바이를 사용하는 경우 이를 인용하는 것을 고려해 보십시오.
BibTeX 항목:
@article{JMLR:v22:21-0017,
author = {Janis Klaise and Arnaud Van Looveren and Giovanni Vacanti and Alexandru Coca},
title = {Alibi Explain: Algorithms for Explaining Machine Learning Models},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {181},
pages = {1-7},
url = {http://jmlr.org/papers/v22/21-0017.html}
}


