thumb
1.0.0
LLM을 위한 간단한 프롬프트 테스트 라이브러리입니다.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])각 프롬프트는 기본적으로 비동기식으로 10번 실행됩니다. 이는 순차적으로 실행하는 것보다 약 9배 빠릅니다. Jupyter 노트북에서는 블라인드 평가 응답을 위해 간단한 사용자 인터페이스가 표시됩니다(어떤 프롬프트가 응답을 생성했는지는 볼 수 없음).
모든 응답이 평가되면 다음 성과 통계가 프롬프트 템플릿별로 분류되어 계산됩니다.
avg_score 모든 실행의 백분율로 나타낸 긍정적인 피드백 양avg_tokens : 프롬프트와 응답 전반에 걸쳐 사용된 토큰 수avg_cost : 평균 프롬프트 실행 비용에 대한 추정치 간단한 보고서가 노트북에 표시되고 전체 데이터는 CSV 파일 thumb/ThumbTest-{TestID}.csv 에 저장됩니다.

테스트 사례는 다양한 입력 변수를 사용하여 프롬프트 템플릿을 테스트하려는 경우입니다. 예를 들어 코미디언 이름에 대한 변수가 포함된 프롬프트 템플릿을 테스트하려는 경우 다양한 코미디언에 대한 테스트 사례를 설정할 수 있습니다.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )모든 테스트 사례는 모든 프롬프트 템플릿에 대해 실행됩니다. 따라서 이 예에서는 6개의 조합(3개의 테스트 사례 x 2개의 프롬프트 템플릿)을 얻게 되며, 각 조합은 10번 실행됩니다(OpenAI에 대한 총 60개의 호출). 모든 테스트 사례에는 프롬프트 템플릿의 각 변수에 대한 값이 포함되어야 합니다.
프롬프트에는 각 테스트 사례에 여러 변수가 있을 수 있습니다. 예를 들어 코미디언 이름과 농담 주제에 대한 변수가 포함된 프롬프트 템플릿을 테스트하려는 경우 다양한 코미디언과 주제에 대한 테스트 사례를 설정할 수 있습니다.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )동일한 입력 데이터를 바탕으로 각 프롬프트의 성능을 공정하게 비교하기 위해 모든 케이스를 모든 프롬프트에 대해 테스트합니다. 4개의 테스트 사례와 2개의 프롬프트를 사용하면 8개의 조합(4개의 테스트 사례 x 2개의 프롬프트 템플릿)을 얻을 수 있으며, 각 조합은 10번 실행됩니다(OpenAI에 대한 총 80개의 호출).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])이는 동일한 입력 데이터가 주어졌을 때 각 프롬프트의 성능을 공정하게 비교하기 위해 각 모델에 대해 각 프롬프트를 실행합니다. 2개의 프롬프트와 2개의 모델을 사용하면 4개의 조합(2개의 프롬프트 x 2개의 모델)을 얻게 되며 각각 10번(OpenAI에 대한 총 40번의 호출) 실행됩니다.
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) 프롬프트는 문자열이거나 문자열 배열일 수 있습니다. 프롬프트가 배열인 경우 첫 번째 문자열은 시스템 메시지로 사용되며 나머지 프롬프트는 휴먼 메시지와 보조 메시지( [system, human, ai, human, ai, ...] )를 번갈아 표시합니다. 이는 시스템 메시지를 포함하거나 사전 준비(AI가 원하는 동작을 수행하도록 안내하기 위해 이전 메시지를 채팅에 삽입)를 사용하는 프롬프트를 테스트하는 데 유용합니다.
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
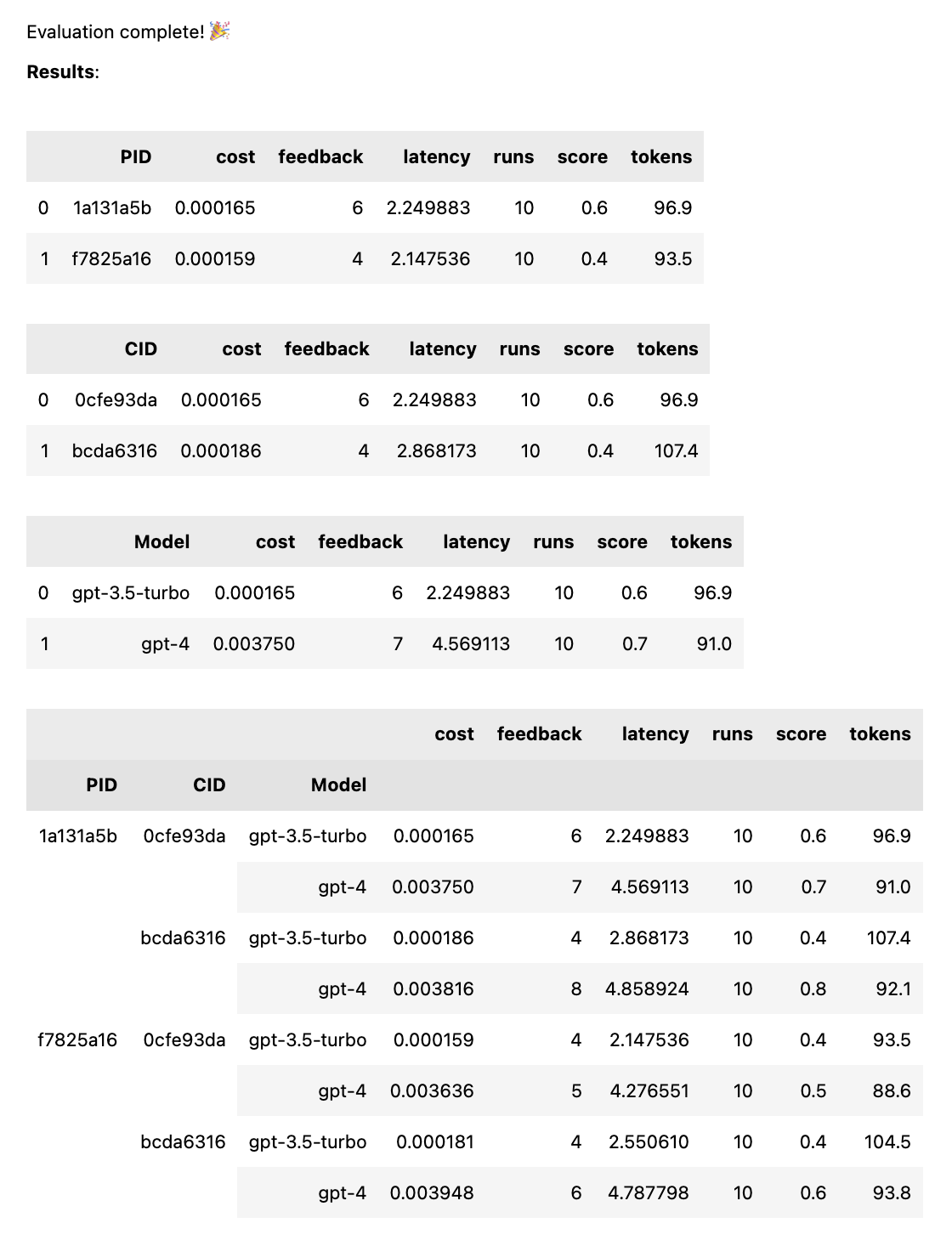
test = thumb . test ([ prompt_a , prompt_b ], cases )테스트가 완료되면 PID, CID 및 모델별로 분류된 전체 평가 보고서와 모든 조합으로 분류된 전체 보고서를 받게 됩니다. 하나의 모델이나 하나의 사례만 테스트하는 경우 이러한 분류는 삭제됩니다. 보고서 하단에는 어떤 ID가 어떤 프롬프트나 사례에 해당하는지 확인할 수 있는 키가 표시됩니다.
thumb.test 함수는 다음 매개변수를 사용합니다.
None )10 )gpt-3.5-turbo ])True ) 2개의 프롬프트 템플릿과 3개의 테스트 사례로 10번의 테스트 실행이 있는 경우 이는 OpenAI에 대한 10 x 2 x 3 = 60 호출입니다. 주의하세요: 특히 GPT-4의 경우 비용이 빠르게 증가할 수 있습니다!
LANGCHAIN_API_KEY 가 환경 변수(선택 사항)로 설정된 경우 LangSmith에 대한 Langchain 추적이 자동으로 활성화됩니다.
.test() 함수는 ThumbTest 객체를 반환합니다. 테스트에 더 많은 프롬프트나 사례를 추가하거나 추가로 실행할 수 있습니다. 언제든지 테스트 데이터를 생성, 평가 및 내보낼 수도 있습니다.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () 모든 프롬프트 템플릿은 모든 테스트 사례에서 동일한 입력 데이터를 가져오지만 프롬프트는 테스트 사례의 모든 변수를 사용할 필요는 없습니다. 위의 예에서와 같이, tell me a knock knock joke 프롬프트는 subject 변수를 사용하지 않지만 여전히 각 테스트 사례에 대해 변수 없이 한 번 생성됩니다.
테스트 데이터는 프롬프트와 사례 조합에 대한 모든 실행 세트가 생성된 후 로컬 JSON 파일 thumb/.cache/{TestID}.json 에 캐시됩니다. 테스트가 중단되었거나 테스트에 추가하려는 경우 thumb.load 함수를 사용하여 캐시에서 테스트 데이터를 로드할 수 있습니다.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () 프롬프트와 사례의 각 조합에 대한 모든 실행은 개체(및 캐시)에 저장되므로 더 많은 프롬프트, 사례 또는 실행이 추가되지 않으면 test.generate() 다시 호출해도 새 응답이 생성되지 않습니다. 마찬가지로 test.evaluate() 다시 호출하면 이미 평가한 응답을 다시 평가하지 않고 테스트가 종료된 경우 결과를 다시 표시할 뿐입니다.
ChatGPT를 가지고 노는 사람들과 프로덕션에서 AI를 사용하는 사람들의 차이점은 평가입니다. LLM은 비결정적으로 반응하므로 다양한 시나리오에 걸쳐 확장할 때 결과가 어떤지 테스트하는 것이 중요합니다. 평가 프레임워크가 없으면 프롬프트에서 무엇이 작동하는지(또는 작동하지 않는지)에 대해 맹목적으로 추측하게 됩니다.
진지한 프롬프트 엔지니어는 어떤 입력이 유용하거나 원하는 출력으로 안정적이고 규모에 맞게 테스트하고 학습하고 있습니다. 이 프로세스를 프롬프트 최적화라고 하며 다음과 같습니다.
엄지손가락 테스트는 대규모 전문 평가 메커니즘과 시행착오를 통해 맹목적으로 촉구하는 것 사이의 격차를 메웁니다. 프롬프트를 프로덕션 환경으로 전환하는 경우 thumb 사용하여 프롬프트를 테스트하면 극단적인 사례를 파악하고 결과에 대한 초기 사용자 또는 팀 피드백을 얻는 데 도움이 될 수 있습니다.
이 사람들은 여가 시간에 재미를 위해 thumb 키우고 있습니다. ?
해머-산 |


