llm data annotation
1.0.0
이 프레임워크는 인간의 전문 지식과 OpenAI의 GPT-3.5와 같은 LLM(대형 언어 모델)의 효율성을 결합하여 데이터 세트 주석 및 모델 개선을 단순화합니다. 반복적 접근 방식은 데이터 품질의 지속적인 개선을 보장하고 결과적으로 이 데이터를 사용하여 미세 조정된 모델의 성능을 보장합니다. 이를 통해 시간을 절약할 수 있을 뿐만 아니라 사람 주석 작성자와 LLM 기반 정밀도를 모두 활용하는 맞춤형 LLM을 생성할 수 있습니다.
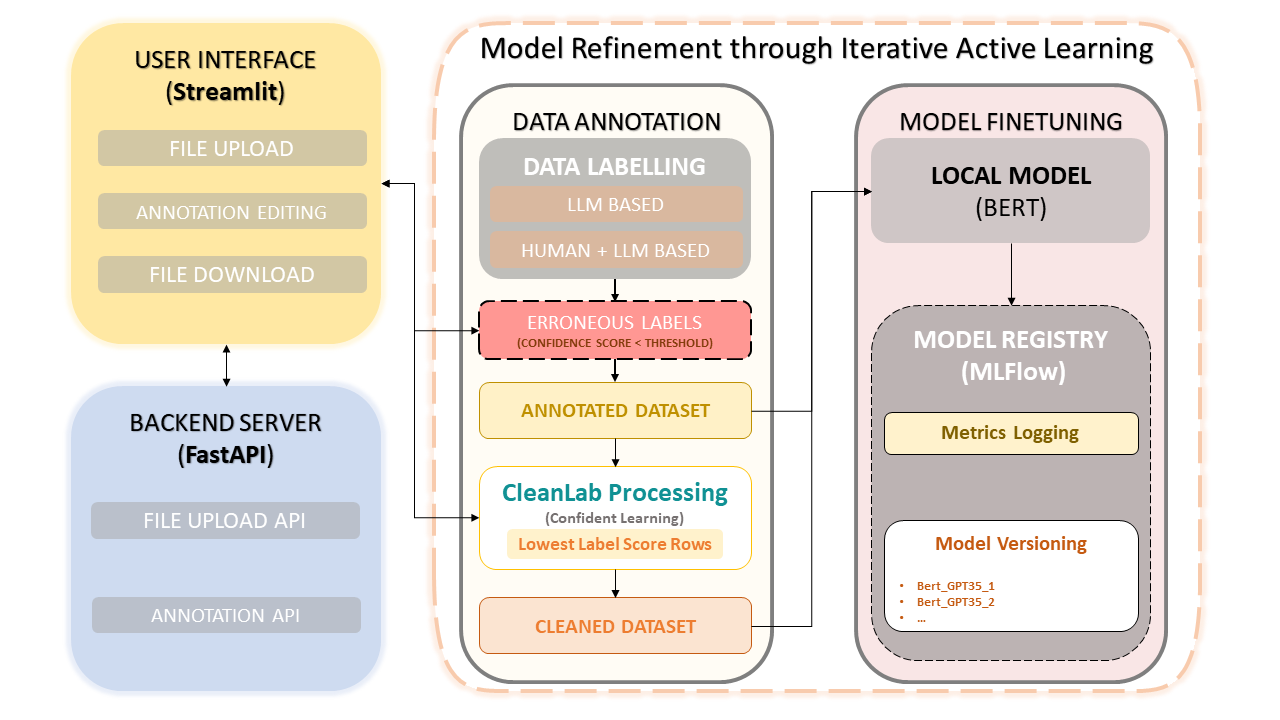
데이터세트 업로드 및 주석
수동 주석 수정
CleanLab: 자신감 있는 학습 접근 방식
데이터 버전 관리 및 저장
모델 훈련
pip install -r requirements.txtFastAPI 백엔드를 시작합니다 .
uvicorn app:app --reloadStreamlit 앱을 실행합니다 .
streamlit run frontend.pyMLflow UI 실행 : 모델, 측정항목 및 등록된 모델을 보려면 다음 명령을 사용하여 MLflow UI에 액세스할 수 있습니다.
mlflow ui웹 브라우저에서 제공된 링크에 액세스하십시오 .
http://127.0.0.1:5000 으로 이동할 수 있습니다.화면의 지시에 따라 데이터세트를 업로드하고, 주석을 달고, 수정하고, 훈련하세요.
자신감 있는 학습은 지도 학습과 약한 감독에서 획기적인 기술로 등장했습니다. 라벨 노이즈를 특성화하고, 라벨 오류를 찾고, 노이즈가 있는 라벨을 통해 효율적으로 학습하는 것을 목표로 합니다. 이 방법은 잡음이 있는 데이터를 정리하고 예제의 순위를 매겨 자신 있게 훈련함으로써 깨끗하고 신뢰할 수 있는 데이터 세트를 보장하여 전체 모델 성능을 향상시킵니다.
이 프로젝트는 MIT 라이선스에 따라 오픈 소스로 제공됩니다.


