CDial GPT
1.0.0
본 프로젝트는 대규모 중국어 대화 데이터 세트와 이 데이터 세트에 대한 중국어 대화 사전 학습 모델(중국어 GPT 모델)을 제공합니다.
이 프로젝트의 코드는 TransferTransfo에서 수정되었으며 사전 학습 및 미세 조정에 사용할 수 있는 Transformers 라이브러리의 HuggingFace Pytorch 버전을 사용합니다.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" 우리가 제공하는 LCCC(Large-scale Cleaned Chinese Conversation) 데이터 세트는 주로 LCCC-base (Baidu Netdisk, Google Drive)과 LCCC-large (Baidu Netdisk, Google Drive)의 두 부분으로 구성됩니다. 이 데이터 세트에서 대화 데이터의 품질을 보장합니다. 이 데이터 필터링 프로세스에는 일련의 수동 규칙과 기계 학습 알고리즘을 기반으로 하는 여러 분류자가 포함됩니다. 우리가 필터링하는 노이즈에는 더러운 단어, 특수 문자, 표정, 문법 문장, 관련 없는 대화 등이 포함됩니다.
이 데이터 세트의 통계는 아래 표에 나와 있습니다. 그 중 문장이 두 개만 포함된 대화를 '단회전 대화', 문장이 두 개 이상 포함된 대화를 '다회전 대화'라고 부릅니다. 단어 목록의 크기를 계산할 때 Jieba 단어 분할을 사용합니다.
| LCCC 기반 (바이두 클라우드 디스크, 구글 드라이브) | 일회성 대화 | 여러 라운드의 대화 |
|---|---|---|
| 총 대화 턴 | 3,354,232 | 3,466,274 |
| 총 대화문장 | 6,708,464 | 13,365,256 |
| 총 문자수 | 68,559,367 | 163,690,569 |
| 어휘 크기 | 372,063 | 666,931 |
| 대화 문장의 평균 단어 수 | 6.79 | 8.32 |
| 대화 라운드당 평균 문장 수 | 2 | 3.86 |
LCCC 기반 데이터세트의 정리 프로세스는 LCCC-대형 데이터세트보다 더 엄격하므로 크기도 더 작습니다.
| LCCC-대형 (바이두 클라우드 디스크, 구글 드라이브) | 일회성 대화 | 여러 라운드의 대화 |
|---|---|---|
| 총 대화 턴 | 7,273,804 | 4,733,955 |
| 총 대화문장 | 14,547,608 | 18,341,167 |
| 총 문자수 | 162,301,556 | 217,776,649 |
| 어휘 크기 | 662,514 | 690,027 |
| 대화문장 평가단어 수 | 7.45 | 8.14 |
| 대화 라운드당 평균 문장 수 | 2 | 3.87 |
LCCC 기반 데이터 세트의 원본 대화 데이터는 Weibo 대화에서 나오며, LCCC 대규모 데이터 세트의 원본 대화 데이터는 다음 Weibo 대화를 기반으로 하는 다른 오픈 소스 대화 데이터 세트와 통합됩니다.
| 데이터 세트 | 총 대화 턴 | 대화 예 |
|---|---|---|
| 웨이보 코퍼스 | 79M | Q: 충칭 청두에서 훠궈를 7~8번 먹었습니다. A: 하하하하! 그러면 입이 썩을 수도 있어요! |
| PTT 험담 코퍼스 | 0.4M | Q: 마을 사람들은 왜 항상 고등학생을 괴롭히나요? QQ A: 좋은 과목을 선택하면 빌 게이츠가 될 것이라고 생각한다면 학교를 자퇴하는 편이 낫습니다. |
| 자막 코퍼스 | 274만 | Q: 경극의 사람들은 자유롭지 않습니다. A: 그들은 사람들을 우리에 가두었습니다. |
| Xiaohuangji 코퍼스 | 0.45M | Q: 사랑에 빠진 적이 있나요? A: 사랑에 빠진 적이 있나요? 아, 슬프네요... |
| 티에바 코퍼스 | 232만 | Q: 맨 앞줄 루 팬들이 다 일어나죠? A: 제목에는 어시스트라고 되어 있는데 그 공을 보고 나니 정말 아이러니하네요. |
| 칭윈 코퍼스 | 0.1M | Q. 돈을 굉장히 좋아하시는 것 같더라고요. A: 아, 정말요? 그럼 거의 다 왔네요 |
| 두반회화말뭉치 | 0.5M | Q: 영어 원작 영화를 보면서 순수한 영어를 배워보세요. A: 프렌즈를 좋아해서 여러 번 봤어요. Q: 같은 CD를 보다가 거의 지쳤어요. A: 그럼 이제 영어는 꽤 잘 되겠네요. |
| 전자상거래 회화 코퍼스 | 0.5M | Q: 이것이 좋은 거래가 될까요? A: 아직은 아닙니다. Q: 앞으로 출시될 예정인가요? |
| 중국어 채팅 코퍼스 | 0.5M | Q: 오늘은 다리가 안 좋네요. 명절이라 벽돌 옮기러 가겠습니다. A: 저도 크리스마스에 돈 많이 벌러 갔어요. 남자친구 없는 사람은 어느 휴일에도 마찬가지다. |
또한 일련의 중국 사전 학습 모델(중국 GPT 모델)을 제공합니다. 이러한 모델의 사전 학습 과정은 먼저 중국 신규 데이터에 대한 사전 학습과 LCCC 데이터에 대한 사전 학습의 두 단계로 나뉩니다. 세트.
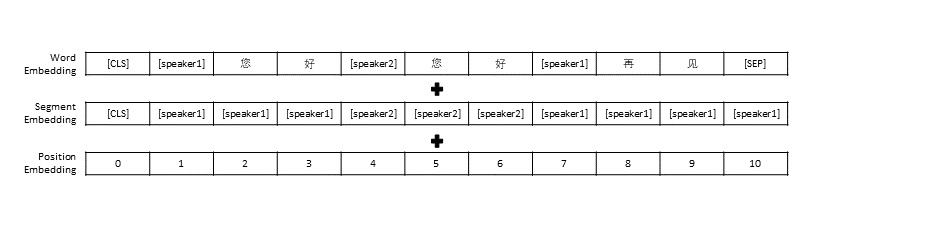
모든 대화 내역을 하나의 문장으로 엮은 TransferTransfo의 데이터 전처리 설정을 따랐고, 이 문장을 모델의 입력으로 사용하여 대화 응답을 예측했습니다. 각 단어의 벡터 표현 외에도 우리 모델의 입력에는 화자 벡터 표현과 위치 벡터 표현도 포함됩니다.
| 사전 훈련된 모델 | 매개변수 수 | 사전 훈련에 사용되는 데이터 | 설명하다 |
|---|---|---|---|
| GPT 소설 | 95.5M | 중국소설자료 | 중국 소설 데이터를 기반으로 구축된 사전 훈련된 중국 GPT 모델(신규 데이터에는 총 13억 단어가 포함됨) |
| CDial-GPT LCCC 기반 | 95.5M | LCCC 기반 | GPT Novel을 기반으로 LCCC 기반으로 학습된 사전 학습된 중국 GPT 모델을 사용합니다. |
| CDial-GPT2 LCCC 기반 | 95.5M | LCCC 기반 | GPT Novel을 기반으로 LCCC 기반으로 훈련된 사전 훈련된 중국 GPT2 모델을 사용합니다. |
| CDial-GPT LCCC-대형 | 95.5M | LCCC-대형 | GPT Novel을 기반으로 LCCC-large에서 학습한 사전 학습된 중국 GPT 모델을 사용합니다. |
소스에서 직접 설치:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
1단계: 모델 사전 학습 및 미세 조정에 필요한 데이터 세트를 준비합니다(예: 프로젝트 디렉터리에 STC 데이터 세트 또는 장난감 데이터 "data/toy_data.json"). 데이터에 영어가 포함된 경우 분리해야 합니다. 문자로(예: hello)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: 다음 링크를 사용하여 STC(Baidu Cloud Disk, Google Drive)의 훈련 세트 및 검증 세트를 다운로드할 수 있습니다.
2단계: 모델 학습
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
또는
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
훈련 스크립트에는 train_path 매개변수도 제공되어 사용자가 일반 텍스트 파일을 조각으로 읽을 수 있습니다. 메모리가 제한된 시스템을 사용하는 경우 이 매개변수를 사용하여 훈련 데이터를 읽는 것을 고려해 보십시오. train_path 사용하는 경우 data_path 비워 두어야 합니다.
3단계: 텍스트 생성
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: 다음 링크를 사용하여 STC 테스트 세트(Baidu Cloud Disk, Google Drive)를 다운로드할 수 있습니다.
훈련 스크립트 매개변수
| 매개변수 | 유형 | 기본값 | 설명하다 |
|---|---|---|---|
| 모델_체크포인트 | str | "" | 모델 파일의 경로 또는 URL(사전 학습 모델 및 config/vocab 파일의 디렉터리) |
| 미리 훈련된 | 부울 | 거짓 | False인 경우 처음부터 모델을 학습시킵니다. |
| 데이터 경로 | str | "" | 데이터 세트의 경로 |
| 데이터세트_캐시 | str | default="dataset_cache" | 데이터 세트 캐시의 경로 또는 URL |
| 기차_경로 | str | "" | 분산 데이터 세트의 훈련 세트 경로 |
| 유효한_경로 | str | "" | 분산 데이터 세트에 대한 검증 세트의 경로 |
| 로그 파일 | str | "" | 이 경로 아래의 파일에 로그를 출력합니다. |
| num_workers | 정수 | 1 | 데이터 로드를 위한 하위 프로세스 수 |
| n_epochs | 정수 | 70 | 훈련 에포크 수 |
| train_batch_size | 정수 | 8 | 훈련을 위한 배치 크기 |
| 유효한_배치_크기 | 정수 | 8 | 검증을 위한 배치 크기 |
| 최대_역사 | 정수 | 15 | 기록에 보관할 이전 교환 수 |
| 스케줄러 | str | "노암" | 최적화 방법 |
| n_emd | 정수 | 768 | 구성 파일의 n_emd 수(noam의 경우) |
| 평가_전_시작 | 부울 | 거짓 | true인 경우 학습 전에 평가를 시작합니다. |
| 준비_단계 | 정수 | 5000 | 워밍업 단계 |
| 유효한_단계 | 정수 | 0 | 0이 아닌 경우 X 단계마다 검증을 수행합니다. |
| 그래디언트_축적_단계 | 정수 | 64 | 여러 단계에서 그라데이션을 누적합니다. |
| 최대_표준 | 뜨다 | 1.0 | 클리핑 그래디언트 표준 |
| 장치 | str | torch.cuda.is_available()인 경우 "cuda", 그렇지 않으면 "cpu" | 장치(cuda 또는 CPU) |
| fp16 | str | "" | fp16 훈련을 위해 O0, O1, O2 또는 O3으로 설정합니다(apex 문서 참조). |
| local_rank | 정수 | -1 | 분산 훈련의 로컬 순위(-1: 분산되지 않음) |
STC 데이터 세트(훈련 세트/검증 세트(Baidu Netdisk, Google Drive), 테스트 세트(Baidu Netdisk, Google Drive))를 사용하여 미세 조정된 대화 사전 훈련 모델을 평가했습니다. 모든 응답은 Nucleus Sampling(p=0.9, 온도=0.7)을 사용하여 샘플링되었습니다.
| 모델 | 모델 크기 | PPL | BLEU-2 | 블루-4 | 거리-1 | Dist-2 | 그리디 매칭 | 임베딩 평균 |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| 변신 로봇 | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2 잡담 | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT 소설 | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCC 기반 | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCC 기반 | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-대형 | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
우리는 각 모델에 대해 200개의 응답을 샘플링하고 아웃소싱 플랫폼에 3명의 주석자를 초대하여 이러한 응답을 수동으로 평가했습니다. 평가 차원은 대화의 유창함, 상황적 관련성 및 응답 다양성이었습니다. 각 차원의 점수 범위는 2/1/0입니다. 자세한 내용은 당사의 논문을 참조하세요.
| 모델 | +2 | +1 | +0 | 카파 |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| 변신 로봇 | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2 잡담 | 24.3% | 19.1% | 56.6% | 0.3941 |
| GPT LCCC 기반 | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-대형 | 48.6% | 24.5% | 27.0% | 0.4203 |
우리는 1,000개의 대화 응답을 무작위로 샘플링하여 다음 응답 중에서 나쁜 응답을 계산했습니다.
| 반복되는 진술이 포함되어 있습니다. | 욕설이 포함되어 있습니다 | 기타 나쁜 답변 |
|---|---|---|
| 스물셋 | 9 | 2 |
우리는 STC 데이터세트에서 GPT LCCC 대형 모델의 매개변수를 미세 조정하고 이 미세 조정된 모델을 사용하여 다음 대화 예제를 생성했습니다.
| 우편 | 응답 |
|---|---|
| 여긴 하얼빈이 아니라 베이징이에요. | 하얼빈의 날씨는 베이징보다 좋은 것 같습니다. 이곳은 비가 살짝 내리고 낮에는 바람이 강합니다. |
| 운영자 캠퍼스 광고대회 너무 재미있었어요! 하하하. | 잭마 광고인줄 알았어요. |
| Delsa S posa 캔디 컬러 시리즈 웨딩드레스, 핑크, 블루, 레드, 퍼플, 상큼하고 마음에 드시나요? | 마지막꺼 너무 예뻐요 너무 예뻐요! |
또한 위의 미세 조정 모델을 사용하여 다음과 같은 상호 작용 결과를 얻었습니다.
| 로엘 | 응답 |
|---|---|
| 사용자 | 아무 소용없이 나를 사랑하지 마세요 |
| 봇 | 열매 없는 사랑은 너무 고통스럽습니다. |
| 사용자 | 하지만 사랑했다면 괜찮아 |
| 봇 | 때때로 사랑은 게임이다. |
| 사용자 | 나는 항상 진다 |
| 봇 | 나는 당신을 사랑하는 만큼 당신을 사랑합니다. |
| 사용자 | 당겨주실 수 있나요? |
| 봇 | 당겨주시면 됩니다. |
| 사용자 | 나를 흉내내지 마세요 |
| 봇 | 내가 말하는 것은 당신이 그것을 할 수 없다는 것입니다. |
| 사용자 | 나한테 하라고 강요하는 거 맞지? |
| 봇 | 아니, 말하라고 강요하는 거겠죠? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
본 프로젝트에서 제공하는 LCCC 데이터 세트 및 사전 훈련된 대화 모델은 과학 연구 목적으로만 사용됩니다. LCCC 데이터 세트의 대화는 다양한 소스에서 수집됩니다. 엄격한 데이터 정리 프로세스를 설계했지만 모든 부적절한 콘텐츠가 필터링되었음을 보장하지는 않습니다. 이 데이터에 포함된 모든 내용과 의견은 이 프로젝트의 작성자와 무관합니다. 이 프로젝트에서 제공되는 모델과 코드는 전체 대화 시스템의 구성 요소일 뿐입니다. 우리가 제공하는 디코딩 스크립트는 과학적 연구 목적으로만 사용됩니다. 이 프로젝트의 모델과 스크립트를 사용하여 생성된 모든 대화 내용은 작성자와 관련이 없습니다. 이 프로젝트.
우리 프로젝트가 도움이 된다면, 우리 논문을 인용해주세요:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
이 프로젝트는 대규모의 정리된 중국어 대화 데이터세트 와 이 데이터세트에 대해 사전 훈련된 중국어 GPT 모델을 제공합니다. 자세한 내용은 당사의 논문을 참조하세요.
사전 훈련에 사용되는 코드는 Transformers 라이브러리를 기반으로 하는 TransferTransfo 모델에서 채택되었습니다. 사전 훈련 및 미세 조정에 사용되는 코드는 이 저장소에 제공됩니다.
우리는 LCCC-base (Baidu Netdisk, Google Drive) 및 LCCC-large (Baidu Netdisk, Google Drive)를 포함하는 대규모 정리 중국어 대화 코퍼스(LCCC)를 제시합니다. 엄격한 데이터 정리 파이프라인은 품질을 보장하도록 설계되었습니다. 이 파이프라인에는 공격적이거나 민감한 단어, 특수 기호, 이모티콘, 문법적으로 잘못된 문장, 일관되지 않은 대화와 같은 일련의 규칙과 여러 분류자 기반 필터가 포함됩니다. 거르는.
우리 코퍼스의 통계는 2개의 발화만 있는 대화는 "단일 회전"으로 간주되고, 3개 이상의 발화가 있는 대화는 "다중 회전"으로 간주되며, 어휘 크기는 단어 단위로 계산됩니다. Jieba는 각 발화를 단어로 토큰화하는 데 사용됩니다.
| LCCC 기반 (바이두 넷디스크, 구글 드라이브) | 단일 회전 | 다회전 |
|---|---|---|
| 세션 | 3,354,382 | 3,466,607 |
| 발화 | 6,708,554 | 13,365,268 |
| 캐릭터 | 68,559,727 | 163,690,614 |
| 어휘 | 372,063 | 666,931 |
| 발화당 평균 단어 수 | 6.79 | 8.32 |
| 세션당 평균 발화 | 2 | 3.86 |
LCCC 기반은 LCCC-대형에 비해 더 엄격한 규칙을 사용하여 정리됩니다.
| LCCC-대형 (바이두 넷디스크, 구글 드라이브) | 단일 회전 | 다회전 |
|---|---|---|
| 세션 | 7,273,804 | 4,733,955 |
| 발화 | 14,547,608 | 18,341,167 |
| 캐릭터 | 162,301,556 | 217,776,649 |
| 어휘 | 662,514 | 690,027 |
| 발화당 평균 단어 수 | 7.45 | 8.14 |
| 세션당 평균 발화 | 2 | 3.87 |
LCCC 기반의 원시 대화는 Weibo에서 크롤링한 Weibo 코퍼스에서 비롯되었으며, LCCC-large의 원시 대화는 Weibo 코퍼스 외에도 여러 대화 데이터 세트를 결합하여 구축되었습니다.
| 데이터세트 | 세션 | 견본 |
|---|---|---|
| 웨이보 코퍼스 | 79M | Q: 충칭 청두에서 훠궈를 7~8번 먹었습니다. A: 하하하하! 그러면 입이 썩을 수도 있어요! |
| PTT 험담 코퍼스 | 0.4M | Q: 마을 사람들은 왜 항상 고등학생을 괴롭히나요? QQ A: 좋은 과목을 선택하면 빌 게이츠가 될 것이라고 생각한다면 학교를 자퇴하는 편이 낫습니다. |
| 자막 코퍼스 | 274만 | Q: 경극의 사람들은 자유롭지 않습니다. A: 그들은 사람들을 우리에 가두었습니다. |
| Xiaohuangji 코퍼스 | 0.45M | Q: 사랑에 빠진 적이 있나요? A: 사랑에 빠진 적이 있나요? 아, 슬프네요... |
| 티에바 코퍼스 | 232만 | Q: 맨 앞줄 루 팬들이 다 일어나죠? A: 제목에는 어시스트라고 되어 있는데 그 공을 보고 나니 정말 아이러니하네요. |
| 칭윈 코퍼스 | 0.1M | Q. 돈을 굉장히 좋아하시는 것 같더라고요. A: 아, 정말요? 그럼 거의 다 왔네요 |
| 두반회화말뭉치 | 0.5M | Q: 영어 원작 영화를 보면서 순수한 영어를 배워보세요. A: 프렌즈를 좋아해서 여러 번 봤어요. Q: 같은 CD를 보다가 거의 지쳤어요. A: 그럼 이제 영어는 꽤 잘 되겠네요. |
| 전자상거래 회화 코퍼스 | 0.5M | Q: 이것이 좋은 거래가 될까요? A: 아직은 아닙니다. Q: 앞으로 출시될 예정인가요? |
| 중국어 채팅 코퍼스 | 0.5M | Q: 오늘은 다리가 안 좋네요. 명절이라 벽돌 옮기러 가겠습니다. A: 저도 크리스마스에 돈 많이 벌러 갔어요. 남자친구 없는 사람은 어느 휴일에도 마찬가지다. |
또한 중국 소설 데이터 세트에 대해 먼저 사전 교육을 받은 다음 LCCC 데이터 세트에 대해 사후 교육을 받은 일련의 중국 GPT 모델을 제시합니다.
TransferTransfo와 유사하게 모든 대화 기록을 하나의 컨텍스트 문장으로 연결하고 이 문장을 사용하여 응답을 예측합니다. 모델의 입력은 단어 임베딩, 화자 임베딩 및 각 단어의 위치 임베딩으로 구성됩니다.
| 모델 | 매개변수 크기 | 사전 훈련 데이터세트 | 설명 |
|---|---|---|---|
| GPT 소설 | 95.5M | 중국 소설 | 중국 소설 데이터세트(13억 단어, 이 모델의 세부정보는 제공하지 않음)에 대해 사전 훈련된 GPT 모델 |
| CDial-GPT LCCC 기반 | 95.5M | LCCC 기반 | GPT Novel 의 LCCC 기반 데이터세트로 사후 훈련된 GPT 모델 |
| CDial-GPT2 LCCC 기반 | 95.5M | LCCC 기반 | GPT Novel 의 LCCC 기반 데이터세트로 사후 훈련된 GPT2 모델 |
| CDial-GPT LCCC-대형 | 95.5M | LCCC-대형 | GPT Novel 의 LCCC 대규모 데이터세트로 사후 훈련된 GPT 모델 |
소스 코드에서 설치:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
1단계: 미세 조정을 위한 데이터(예: 리포지토리의 STC 데이터 세트 또는 "data/toy_data.json")와 사전 테스트된 모델을 준비합니다.
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: 다음 링크에서 STC의 기차와 유효한 분할을 다운로드할 수 있습니다: (Baidu Netdisk, Google Drive)
2단계: 모델 학습
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
또는
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
참고: 또한 훈련 스크립트에 train_path 인수를 제공하여 일반 텍스트로 데이터 세트를 읽어서 분산 처리할 예정입니다. 데이터 세트가 시스템 메모리에 비해 너무 큰 경우 이 인수를 사용하는 것을 고려할 수 있습니다. train_path 사용하는 경우 data_path 인수를 비워 두는 것을 잊지 마세요.
3단계: 추론 모드
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: 다음 링크에서 STC의 테스트 분할을 다운로드할 수 있습니다: (Baidu Netdisk, Google Drive)
훈련 인수
| 인수 | 유형 | 기본값 | 설명 |
|---|---|---|---|
| 모델_체크포인트 | str | "" | 모델 파일의 경로 또는 URL(사전 학습 모델 및 config/vocab 파일의 디렉터리) |
| 미리 훈련된 | 부울 | 거짓 | False인 경우 처음부터 모델을 학습시킵니다. |
| 데이터 경로 | str | "" | 데이터 세트의 경로 |
| 데이터세트_캐시 | str | default="dataset_cache" | 데이터 세트 캐시의 경로 또는 URL |
| 기차_경로 | str | "" | 분산 데이터 세트의 훈련 세트 경로 |
| 유효한_경로 | str | "" | 분산 데이터 세트에 대한 검증 세트의 경로 |
| 로그 파일 | str | "" | 이 경로 아래의 파일에 로그를 출력합니다. |
| num_workers | 정수 | 1 | 데이터 로드를 위한 하위 프로세스 수 |
| n_epochs | 정수 | 70 | 훈련 에포크 수 |
| train_batch_size | 정수 | 8 | 훈련을 위한 배치 크기 |
| 유효한_배치_크기 | 정수 | 8 | 검증을 위한 배치 크기 |
| 최대_역사 | 정수 | 15 | 기록에 보관할 이전 교환 수 |
| 스케줄러 | str | "노암" | 최적화 방법 |
| n_emd | 정수 | 768 | 구성 파일의 n_emd 수(noam의 경우) |
| 평가_전_시작 | 부울 | 거짓 | true인 경우 학습 전에 평가를 시작합니다. |
| 준비_단계 | 정수 | 5000 | 워밍업 단계 |
| 유효한_단계 | 정수 | 0 | 0이 아닌 경우 X 단계마다 검증을 수행합니다. |
| 그래디언트_축적_단계 | 정수 | 64 | 여러 단계에서 그라데이션을 누적합니다. |
| 최대_표준 | 뜨다 | 1.0 | 클리핑 그래디언트 표준 |
| 장치 | str | torch.cuda.is_available()인 경우 "cuda", 그렇지 않으면 "cpu" | 장치(cuda 또는 CPU) |
| fp16 | str | "" | fp16 훈련을 위해 O0, O1, O2 또는 O3으로 설정합니다(apex 문서 참조). |
| local_rank | 정수 | -1 | 분산 훈련의 로컬 순위(-1: 분산되지 않음) |
미세 조정된 모델에서 생성된 결과에 대해 평가가 수행됩니다.
STC 데이터 세트(Train/Valid 분할(Baidu Netdisk, Google Drive), 테스트 분할(Baidu Netdisk, Google Drive)) 모든 응답은 임계값 0.9 및 온도 0.7의 Nucleus Sampling 구성표를 사용하여 생성됩니다.
| 모델 | 모델 크기 | PPL | BLEU-2 | 블루-4 | 거리-1 | Dist-2 | 그리디 매칭 | 임베딩 평균 |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| 변신 로봇 | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2 잡담 | 88M | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| GPT 소설 | 95.5M | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| GPT LCCC 기반 | 95.5M | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| GPT2 LCCC 기반 | 95.5M | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-대형 | 95.5M | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
또한 3명의 크라우드 소스 주석자를 고용하여 2/1/0 점수 스키마를 기반으로 유창성, 관련성 및 다양성에 대한 각 모델의 200개 샘플을 평가했습니다.
| 모델 | +2 | +1 | +0 | 카파 |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| 변신 로봇 | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2 잡담 | 24.3% | 19,1% | 56.6% | 0.3941 |
| GPT LCCC 기반 | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-대형 | 48.6% | 24.5% | 27.0% | 0.4203 |
생성된 1000개의 샘플을 무작위로 선택하고 독성 생성에 대한 통계를 작성합니다.
| 되풀이 | 더러운 말 | 기타 나쁜 사례 |
|---|---|---|
| 스물셋 | 9 | 2 |
STC 데이터세트에서 단일 회전으로 생성된 예(STC에서 미세 조정됨):
| 우편 | 응답 |
|---|---|
| 여긴 하얼빈이 아니라 베이징이에요. | 하얼빈의 날씨는 베이징보다 좋은 것 같습니다. 이곳은 비가 살짝 내리고 낮에는 바람이 강합니다. |
| 운영자 캠퍼스 광고대회 너무 재미있었어요! 하하하. | 잭마 광고인줄 알았어요. |
| Delsa S posa 캔디 컬러 시리즈 웨딩드레스, 핑크, 블루, 레드, 퍼플, 상큼하고 마음에 드시나요? | 마지막꺼 너무 예뻐요 너무 예뻐요! |
대화형 스크립트를 사용하여 다중 회전으로 생성된 예:
| 로엘 | 응답 |
|---|---|
| 사용자 | 아무 소용없이 나를 사랑하지 마세요 |
| 봇 | 열매 없는 사랑은 너무 고통스럽습니다. |
| 사용자 | 하지만 사랑했다면 괜찮아 |
| 봇 | 때때로 사랑은 게임이다. |
| 사용자 | 나는 항상 진다 |
| 봇 | 나는 당신을 사랑하는 만큼 당신을 사랑합니다. |
| 사용자 | 당겨주실 수 있나요? |
| 봇 | 당겨주시면 됩니다. |
| 사용자 | 나를 흉내내지 마세요 |
| 봇 | 내가 말하는 것은 당신이 그것을 할 수 없다는 것입니다. |
| 사용자 | 나한테 하라고 강요하는 거 맞지? |
| 봇 | 아니, 말하라고 강요하는 거겠죠? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
LCCC 데이터세트와 사전 훈련된 모델은 대화 생성을 위한 연구를 촉진하는 것을 목표로 합니다. 이 저장소에 제공되는 LCCC 데이터세트는 엄격한 정리 프로세스가 수행되었지만 모든 부적절한 콘텐츠가 포함되었다는 보장은 없습니다. 이 데이터 세트에 포함된 모든 내용은 작성자의 의견을 나타내지 않습니다. 이 저장소에는 실제로 대화 모델을 생성하는 데 필요한 모델링 기계의 일부만 포함되어 있습니다. 이 저장소에 제공되는 디코딩 스크립트는 연구 목적으로만 사용됩니다. 우리는 책임을 지지 않습니다. 우리 모델을 사용하여 생성된 모든 콘텐츠.
연구에 데이터세트나 모델을 사용하는 경우 우리 논문을 친절하게 인용해 주세요.
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


