Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) 다음을 사용하여 구성을 설정하세요. accelerate config 후: accelerate launch train.py
KOSMOS-1은 Magneto(Foundation Transformers)를 기반으로 한 디코더 전용 Transformer 아키텍처를 사용합니다. 즉, 레이어 정규화가 Attention 모듈 이전(pre-In)과 이후(Post-In)에 추가되는 소위 sub-LN 접근 방식을 사용하는 아키텍처를 사용합니다. ln) 언어 모델링과 이미지 이해에 대한 두 가지 접근 방식의 장점을 결합합니다. 모델은 또한 논문에 설명된 특정 측정항목에 따라 초기화되므로 더 높은 학습률에서 보다 안정적인 교육이 가능합니다.
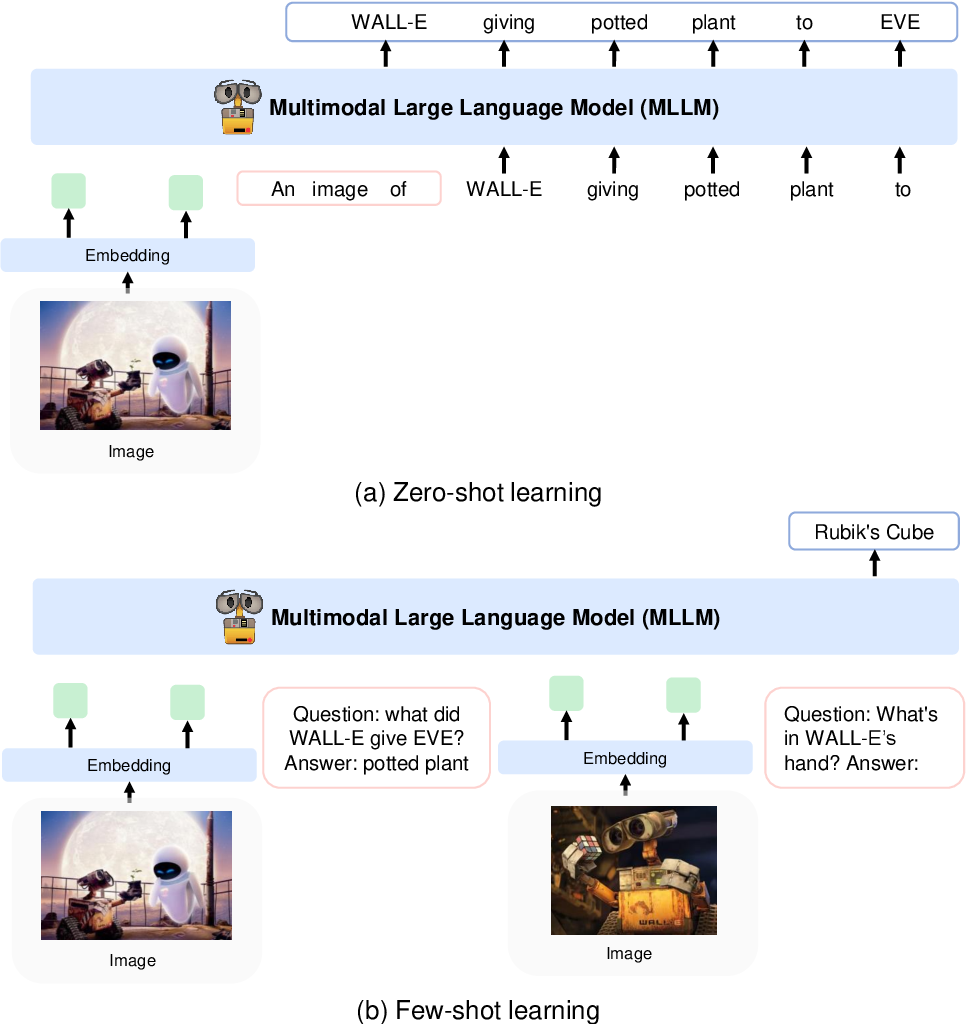
CLIP VIT-L/14 모델을 사용하여 이미지를 이미지 특징으로 인코딩하고 Flamingo에 도입된 인식 리샘플러를 사용하여 256 -> 64 토큰의 이미지 특징을 풀링합니다. 이미지 기능은 특수 토큰 <image> 및 </image> 로 둘러싸인 입력 시퀀스에 추가하여 토큰 임베딩과 결합됩니다. 예를 들면 <s> <image> image_features </image> text </s> 입니다. 이를 통해 이미지가 동일한 순서로 텍스트와 결합될 수 있습니다.
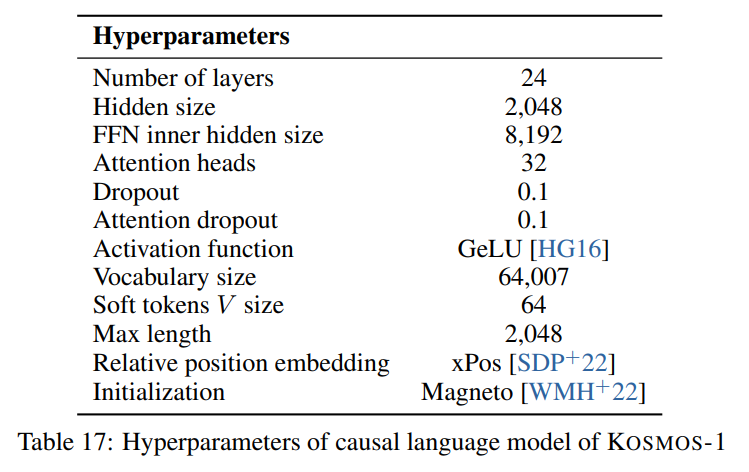
우리는 다음 이미지에 표시된 문서에 설명된 하이퍼파라미터를 따릅니다.
우리는 Foundation Transformers의 디코더 전용 Transformer 아키텍처의 토치스케일 구현을 사용합니다.
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)이미지 모델(CLIP VIT-L/14)의 경우 사전 학습된 OpenClip 모델을 사용합니다.
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]논문에는 하이퍼파라미터가 제공되지 않았으므로 인식 리샘플러에 대한 기본 하이퍼파라미터를 따릅니다.
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) 모델은 2048 의 숨겨진 차원을 예상하기 때문에 nn.Linear 레이어를 사용하여 이미지 특징을 올바른 차원으로 투영하고 Magneto의 초기화 방식에 따라 초기화합니다.
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) 이 논문에서는 64007 개 토큰의 어휘가 포함된 SentencePiece를 설명합니다. 단순화를 위해(사용 가능한 훈련 코퍼스가 없기 때문에) HuggingFace의 사전 훈련된 T5-large 토크나이저인 차선책 오픈 소스 대안을 사용합니다. 이 토크나이저에는 32002 개의 토큰 어휘가 있습니다.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) 그런 다음 nn.Embedding 레이어에 토큰을 삽입합니다. 실제로 우리는 나중에 8비트 AdamW를 사용할 수 있도록 하는 bitandbytes의 bnb.nn.Embedding 을 사용합니다.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)위치 임베딩의 경우 다음을 사용합니다.
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)또한 숨겨진 차원을 어휘 크기에 투영하고 Magneto의 초기화 방식에 따라 초기화하기 위해 출력 투영 레이어를 추가합니다.
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) 정방향 패스에 이미 포함된 기능을 수용할 수 있도록 디코더를 약간 변경해야 했습니다. 이는 위에서 설명한 보다 복잡한 입력 시퀀스를 허용하는 데 필요했습니다. 변경 사항은 torchscale/architecture/decoder.py 라인 391의 다음 차이점에서 볼 수 있습니다.
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )다음은 논문에 언급된 데이터 세트에 대한 메타데이터가 포함된 마크다운 테이블입니다.
| 데이터세트 | 설명 | 크기 | 링크 |
|---|---|---|---|
| 더미 | 다양한 영어 텍스트 코퍼스 | 800GB | 포옹하는 얼굴 |
| 일반적인 크롤링 | 웹 크롤링 데이터 | - | 일반적인 크롤링 |
| LAION-400M | Common Crawl의 이미지-텍스트 쌍 | 4억 쌍 | 포옹하는 얼굴 |
| LAION-2B | Common Crawl의 이미지-텍스트 쌍 | 2B 쌍 | ArXiv |
| 코요 | Common Crawl의 이미지-텍스트 쌍 | 7억 쌍 | Github |
| 개념적 캡션 | 이미지-대체 텍스트 쌍 | 1,500만 쌍 | ArXiv |
| 인터리브된 CC 데이터 | 일반 크롤링의 텍스트 및 이미지 | 7,100만 개의 문서 | 커스텀 데이터세트 |
| 스토리클로즈 | 상식적인 추론 | 16,000개 예시 | ACL 선집 |
| HellaSwag | 상식 NLI | 70,000개 예시 | ArXiv |
| 위노그라드 스키마 | 단어의 모호함 | 예 273개 | 2012년 PKRR |
| 위노그란데 | 단어의 모호함 | 예시 17,000개 | AAAI 2020 |
| 피카 | 물리적 상식 QA | 16,000개 예시 | AAAI 2020 |
| 부울Q | 품질보증 | 15,000개 예시 | ACL 2019 |
| CB | 자연어 추론 | 예시 250개 | 신과 베듀퉁 2019 |
| 코파 | 인과적 추론 | 예시 1,000개 | AAAI 춘계 심포지엄 2011 |
| 상대 크기 | 상식적인 추론 | 486쌍 | ArXiv 2016 |
| 메모리색상 | 상식적인 추론 | 예 720개 | ArXiv 2021 |
| 색상 용어 | 상식적인 추론 | 예시 320개 | ACL 2012 |
| IQ 테스트 | 비언어적 추론 | 예시 50개 | 커스텀 데이터세트 |
| 코코 캡션 | 이미지 캡션 | 이미지 413,000개 | 파미 2015 |
| Flickr30k | 이미지 캡션 | 31,000개의 이미지 | TACL 2014 |
| VQAv2 | 시각적 QA | 100만 개의 QA 쌍 | CVPR 2017 |
| 비즈위즈 | 시각적 QA | 31,000개의 QA 쌍 | CVPR 2018 |
| 웹SRC | 웹 QA | 1,400개 예시 | EMNLP 2021 |
| 이미지넷 | 이미지 분류 | 이미지 128만개 | CVPR 2009 |
| 견습생 | 이미지 분류 | 200종의 조류 | TOG 2011 |
아파치


