evidently
v0.4.40
ML 및 LLM 기반 시스템을 평가, 테스트, 모니터링하기 위한 오픈 소스 프레임워크입니다.

문서 | 디스코드 커뮤니티 | 블로그 | 트위터 | 분명히 클라우드
분명히 0.4.25 . LLM 평가 -> 튜토리얼
분명히 ML 및 LLM 평가 및 관찰 가능성을 위한 오픈 소스 Python 라이브러리입니다. 실험부터 생산까지 AI 기반 시스템과 데이터 파이프라인을 평가, 테스트, 모니터링하는 데 도움이 됩니다.
분명히 매우 모듈화되어 있습니다. Python의 Reports 또는 Test Suites 사용하여 일회성 평가로 시작하거나 실시간 모니터링 대시 Dashboard 서비스를 얻을 수 있습니다.
보고서는 다양한 데이터, ML 및 LLM 품질 지표를 계산합니다. 사전 설정으로 시작하거나 사용자 정의할 수 있습니다.
| 보고서 |
|---|
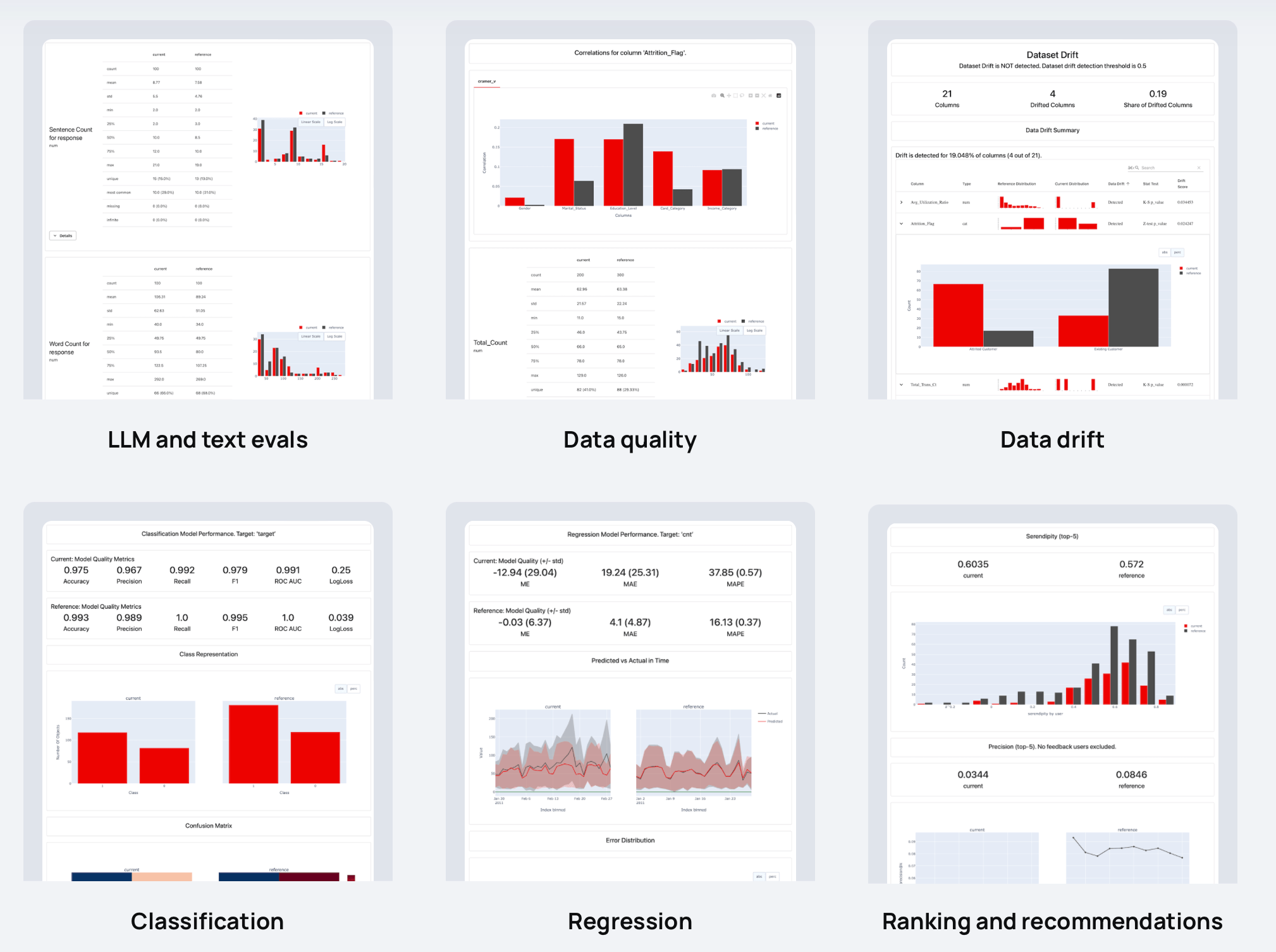 |
테스트 스위트는 메트릭 값에 정의된 조건을 확인하고 합격 또는 실패 결과를 반환합니다.
gt (보다 큼), lt (보다 작음) 등으로 설정하는 간단한 구문입니다.| 테스트 스위트 |
|---|
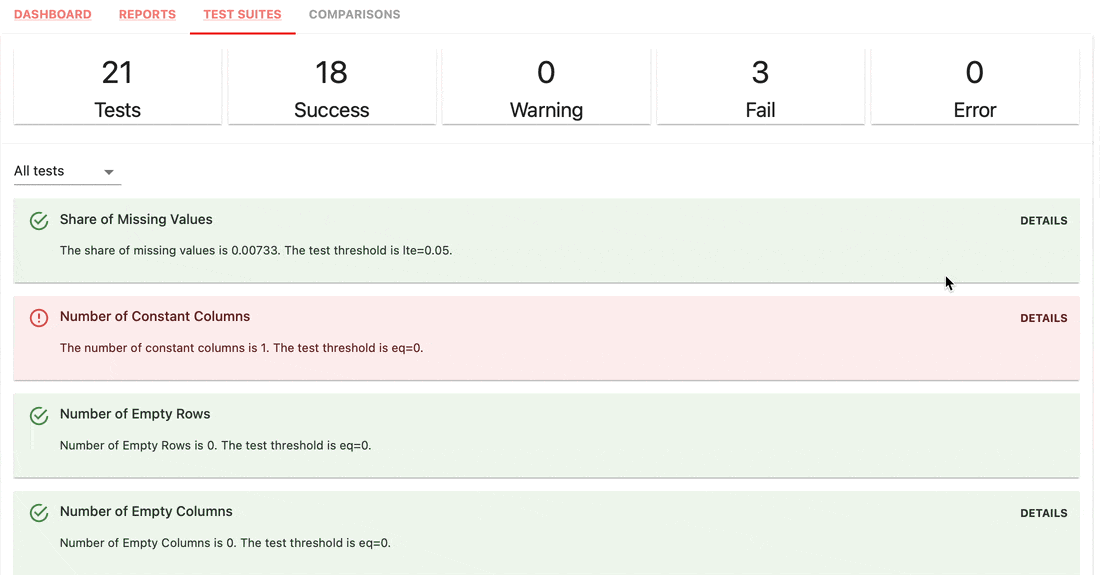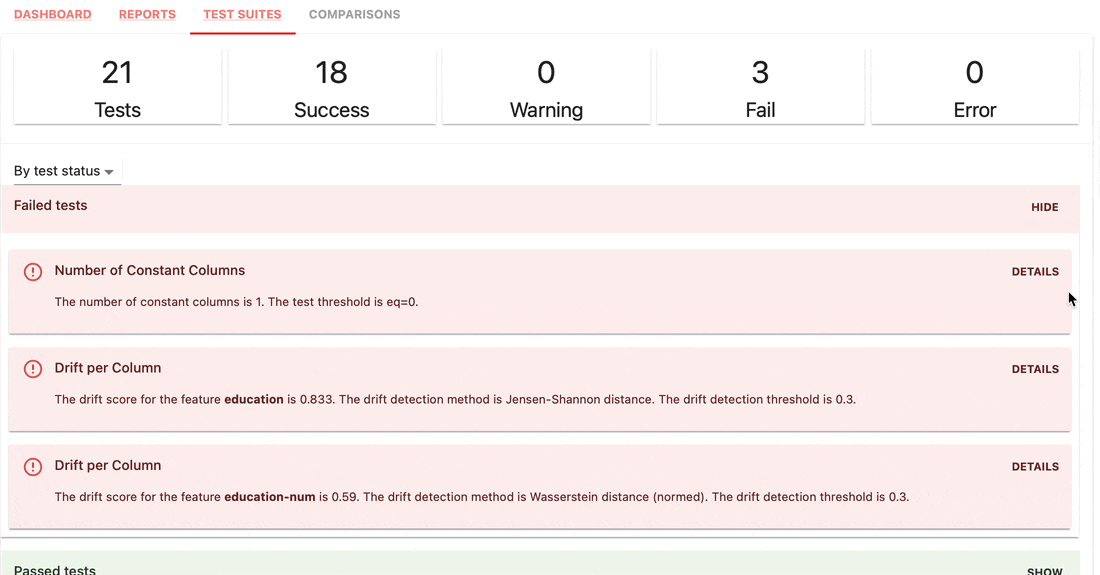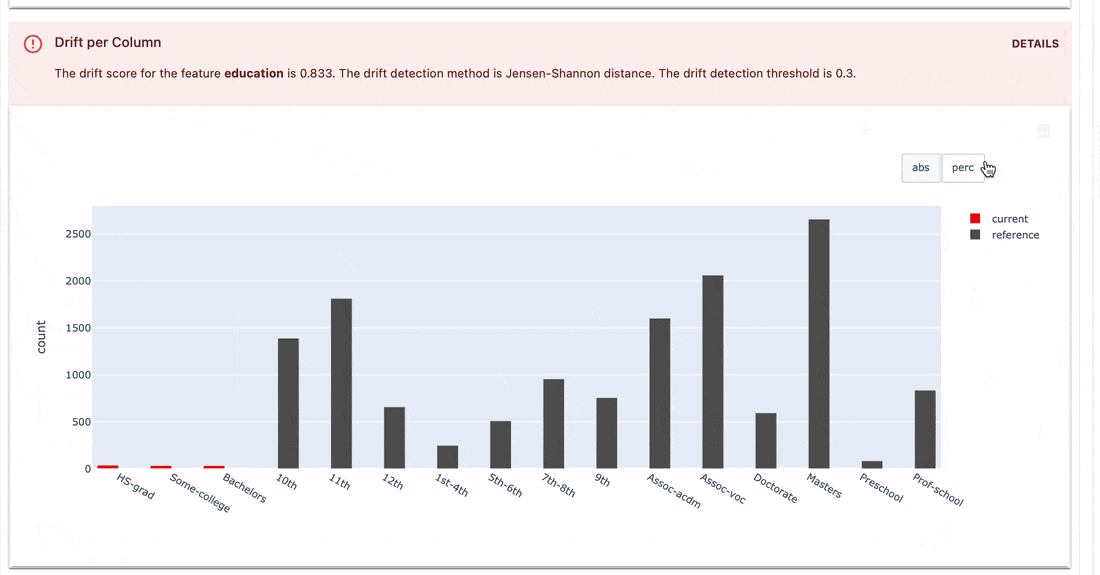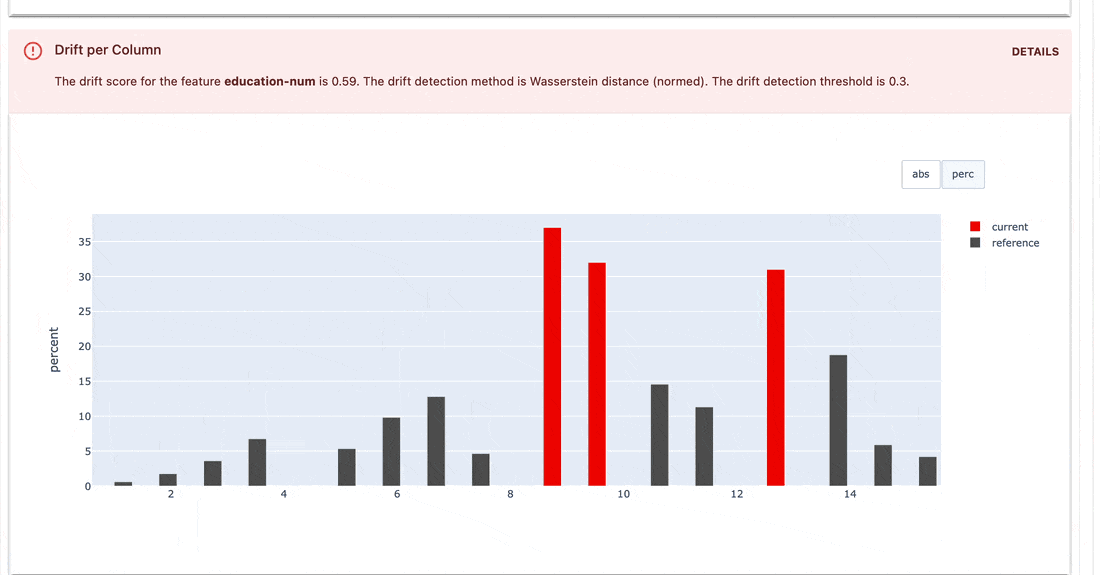 |
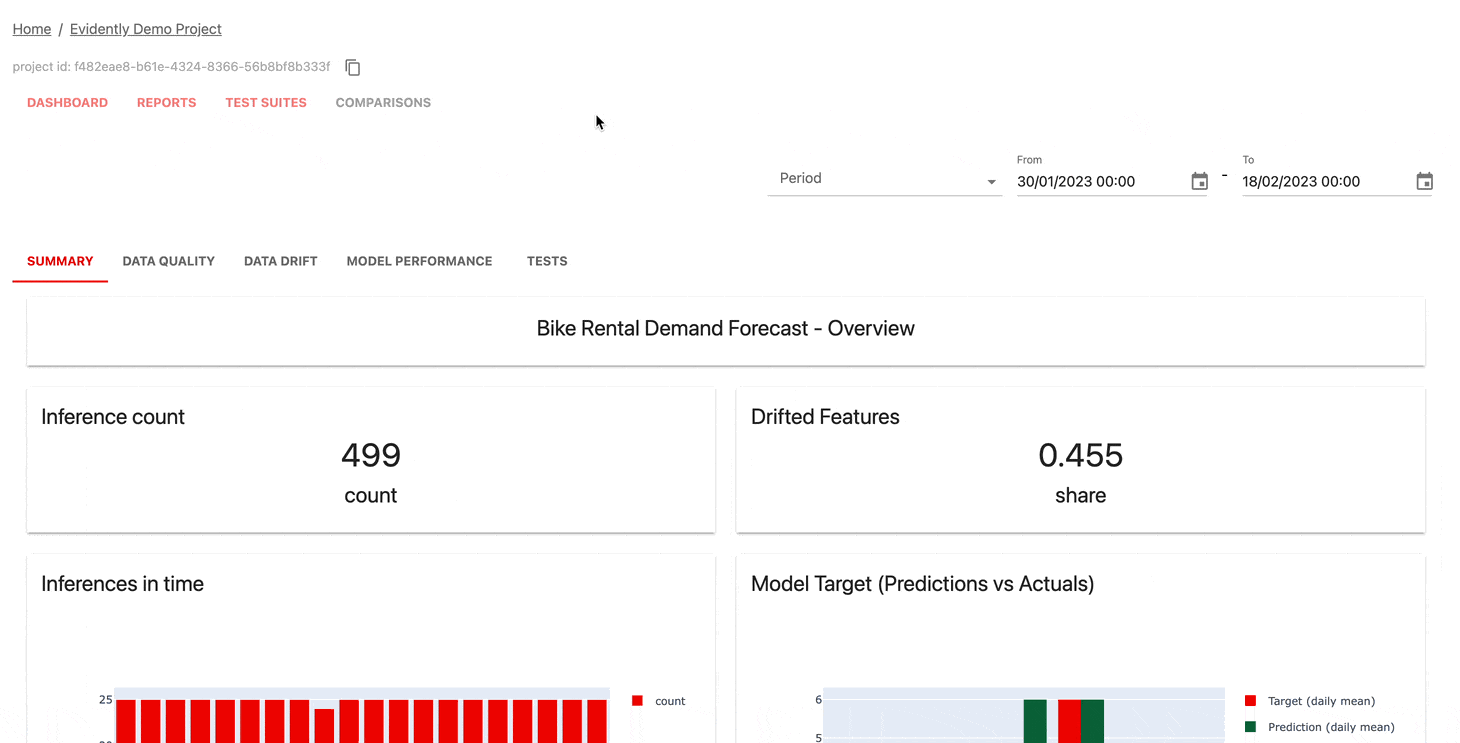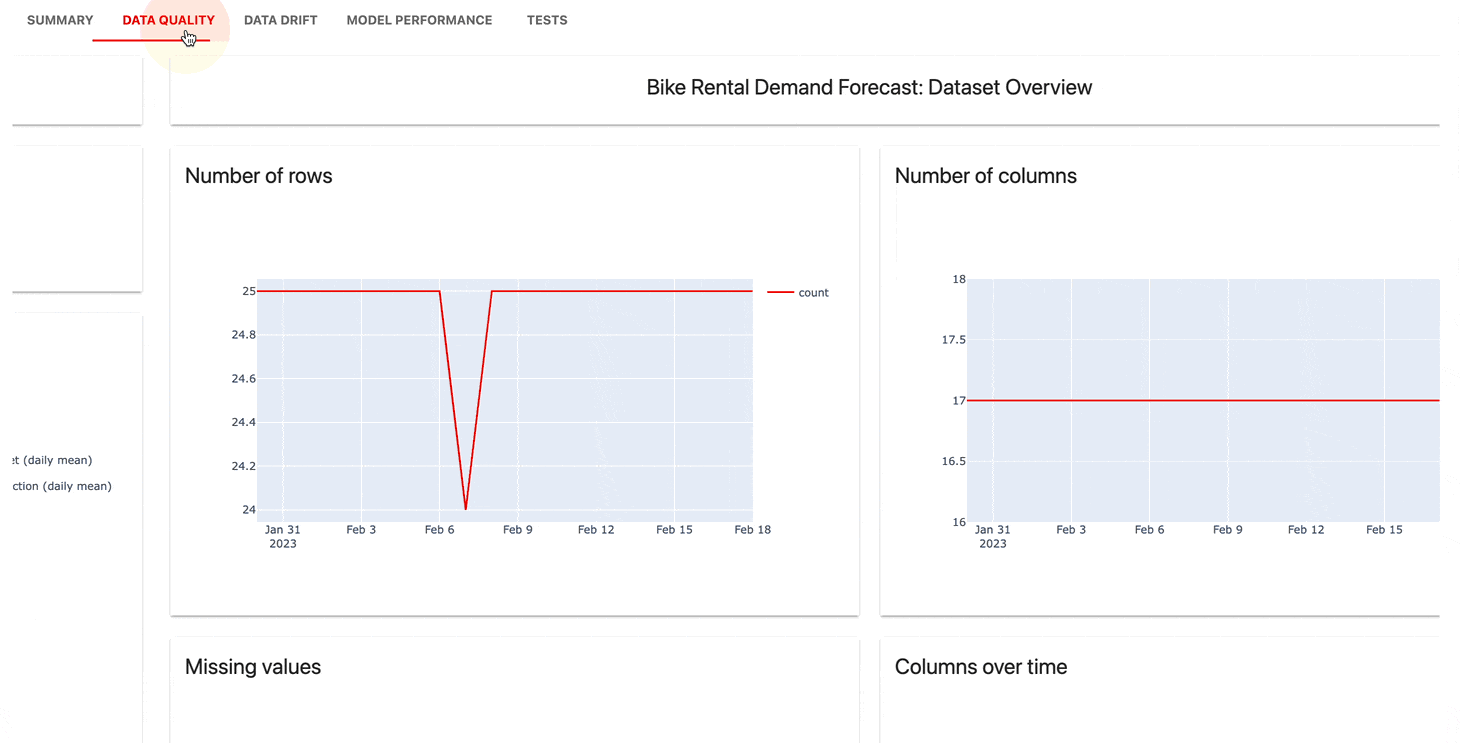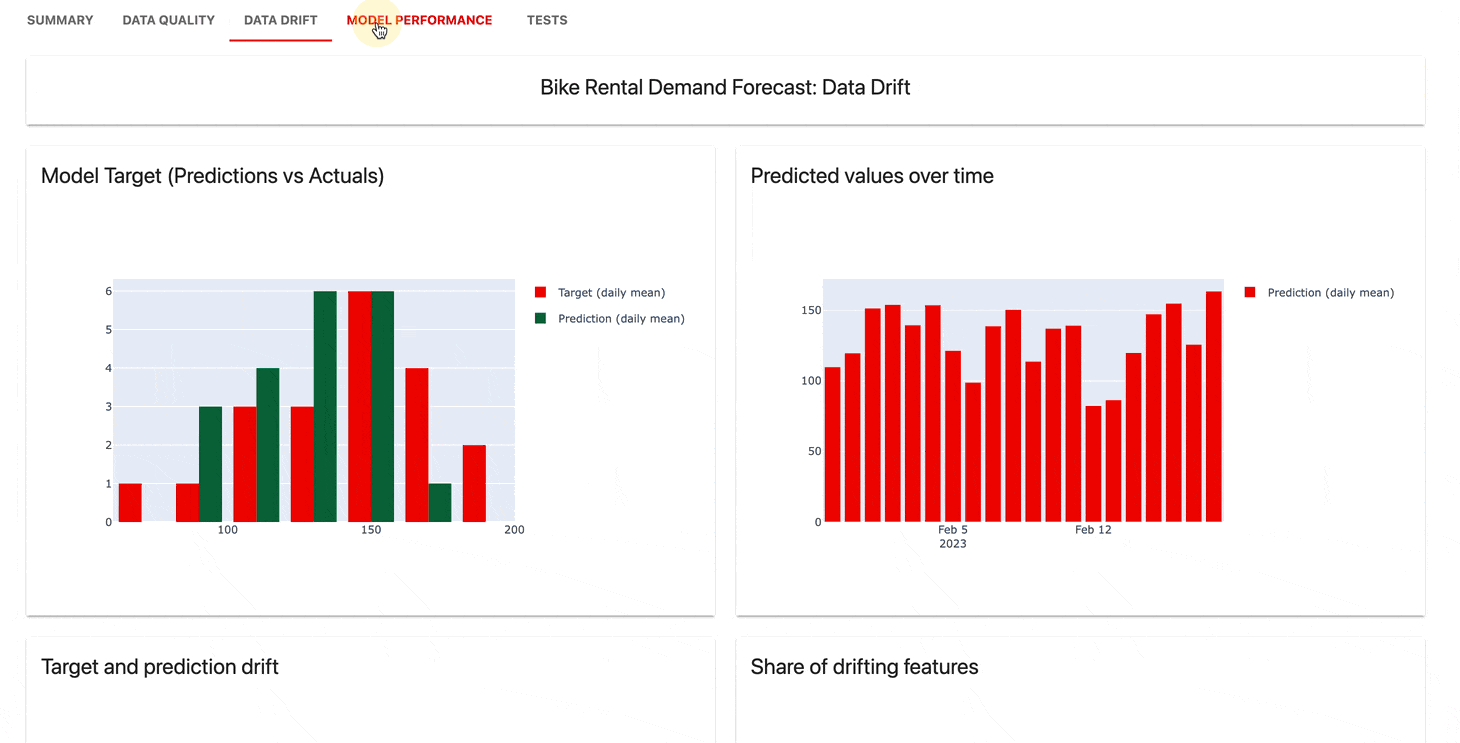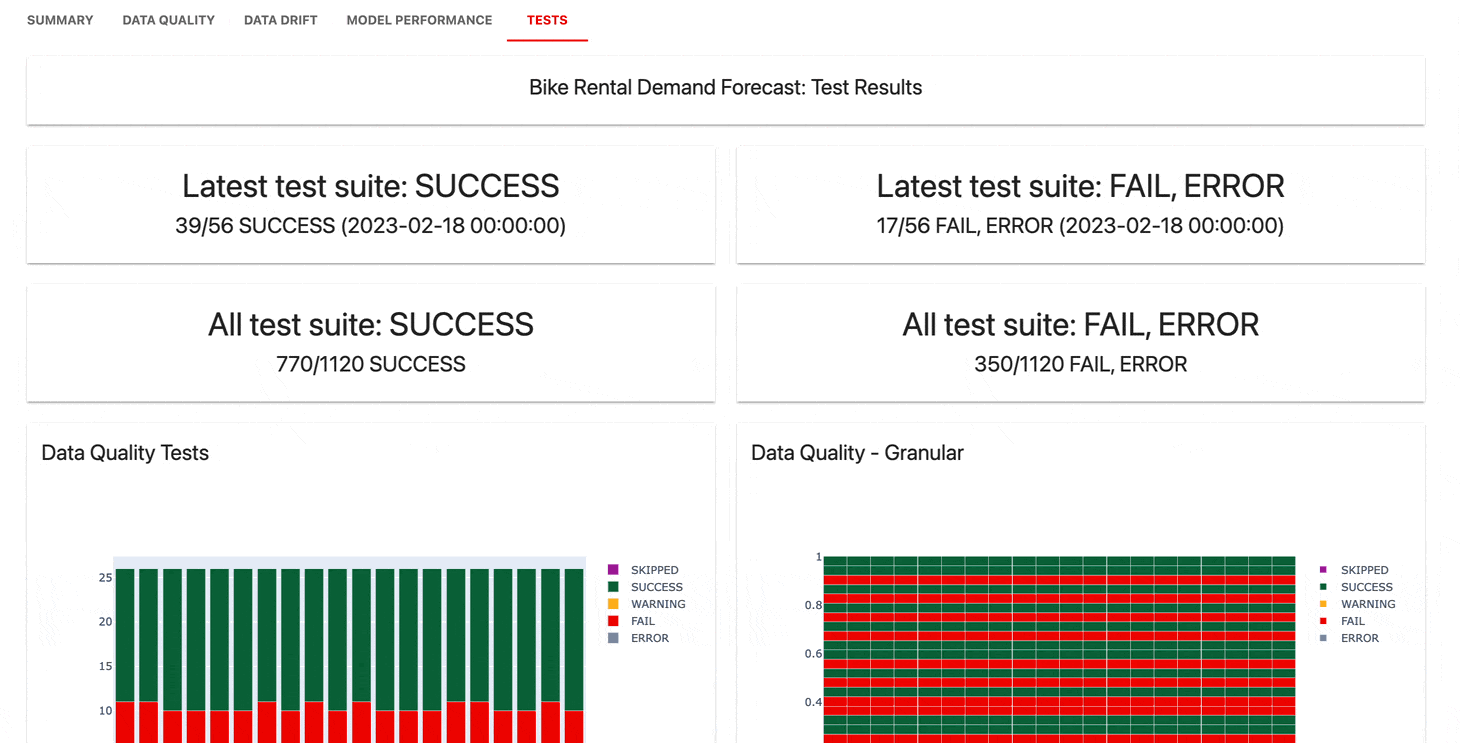
모니터링 UI 서비스는 시간 경과에 따른 측정항목과 테스트 결과를 시각화하는 데 도움이 됩니다.
다음을 선택할 수 있습니다.
확실히 클라우드는 넉넉한 무료 계층과 사용자 관리, 경고, 코드 없는 평가와 같은 추가 기능을 제공합니다.
| 계기반 |
|---|
 |
분명히 PyPI 패키지로 제공됩니다. pip 패키지 관리자를 사용하여 설치하려면 다음을 실행하세요.
pip install evidentlyconda 설치 프로그램을 사용하여 분명히 설치하려면 다음을 실행하십시오.
conda install -c conda-forge evidently이것은 간단한 Hello World입니다. 자세한 내용은 튜토리얼을 확인하세요: 표 형식 데이터 또는 LLM 평가.
테스트 스위트 , 평가 사전 설정 및 토이 테이블 형식 데이터세트를 가져옵니다.
import pandas as pd
from sklearn import datasets
from evidently . test_suite import TestSuite
from evidently . test_preset import DataStabilityTestPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame DataFrame 참조와 현재로 분할합니다. 참조에서 열 값 범위, 누락된 값 등에 대한 검사를 자동으로 생성하는 데이터 안정성 테스트 모음을 실행합니다. Jupyter 노트북에서 출력을 가져옵니다.
data_stability = TestSuite ( tests = [
DataStabilityTestPreset (),
])
data_stability . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_stabilityHTML 파일을 저장할 수도 있습니다. 대상 폴더에서 열어야 합니다.
data_stability . save_html ( "file.html" )출력을 JSON으로 얻으려면 다음을 수행하십시오.
data_stability . json ()다른 사전 설정, 개별 테스트 및 설정 조건을 선택할 수 있습니다.
보고서 , 평가 사전 설정 및 장난감 표 형식 데이터 세트를 가져옵니다.
import pandas as pd
from sklearn import datasets
from evidently . report import Report
from evidently . metric_preset import DataDriftPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame current 와 reference 간의 열 분포를 비교하는 데이터 드리프트 보고서를 실행합니다.
data_drift_report = Report ( metrics = [
DataDriftPreset (),
])
data_drift_report . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_drift_report보고서를 HTML로 저장합니다. 나중에 대상 폴더에서 열어야 합니다.
data_drift_report . save_html ( "file.html" )출력을 JSON으로 얻으려면 다음을 수행하십시오.
data_drift_report . json ()텍스트 데이터에 대한 LLM 평가를 포함하여 다른 사전 설정 및 개별 지표를 선택할 수 있습니다.
그러면 Evidently UI에서 데모 프로젝트가 시작됩니다. 자체 호스팅 또는 분명히 클라우드에 대한 튜토리얼을 확인하세요.
권장 단계: 가상 환경을 생성하고 활성화합니다.
pip install virtualenv
virtualenv venv
source venv/bin/activate
Evidently를 설치한 후( pip install evidently ) 데모 프로젝트와 함께 Evidently UI를 실행합니다.
evidently ui --demo-projects all
브라우저에서 분명히 UI 서비스에 액세스하십시오. localhost:8000 으로 이동합니다.
분명히 100개 이상의 내장 평가가 있습니다. 사용자 정의 항목을 추가할 수도 있습니다. 각 지표에는 선택적 시각화가 있습니다. 이를 Reports , Test Suites 또는 Dashboard 의 플롯에서 사용할 수 있습니다.
확인할 수 있는 사항의 예는 다음과 같습니다.
| ? 텍스트 설명자 | LLM 출력 |
| 길이, 감정, 독성, 언어, 특수 기호, 정규식 일치 등 | 모델 및 LLM 기반 평가를 통한 의미론적 유사성, 검색 관련성, 요약 품질 등. |
| ? 데이터 품질 | 데이터 분포 드리프트 |
| 누락된 값, 중복, 최소-최대 범위, 새로운 범주형 값, 상관관계 등 | 데이터 분포의 변화를 비교하기 위한 20개 이상의 통계 테스트 및 거리 측정법. |
| 분류 | ? 회귀 |
| 정확도, 정밀도, 재현율, ROC AUC, 혼동 행렬, 편향 등 | MAE, ME, RMSE, 오류 분포, 오류 정규성, 오류 편향 등 |
| ? 순위(RAG 포함) | ? 권장 사항 |
| NDCG, MAP, MRR, 적중률 등 | 우연성, 새로움, 다양성, 인기편향 등 |
우리는 기여를 환영합니다! 자세한 내용은 가이드를 읽어보세요.
자세한 내용은 전체 설명서를 참조하세요. 튜토리얼부터 시작할 수 있습니다:
문서에서 더 많은 예를 확인하세요.
Evidently의 특정 기능을 이해하려면 방법 가이드를 살펴보세요.
채팅하고 연결하고 싶다면 Discord 커뮤니티에 가입하세요!


