gen ai document sumarization
1.0.0
이 프로젝트는 문서 콘텐츠 요약을 자동화하기 위한 오픈 소스 생성 AI 모델, 특히 Transformer 아키텍처 기반 모델의 잠재력을 탐구합니다. 목표는 기존 생성 AI 모델을 평가 및 적용하여 컨텍스트를 분석, 이해하고 구조화되지 않은 문서에 대한 요약을 생성하는 것입니다.
이를 달성하기 위해 저는 두 가지 주요 모델인 t5-small과 facebook/bart-base를 미세 조정하여 요약 성능을 향상시키는 데 중점을 두었습니다.
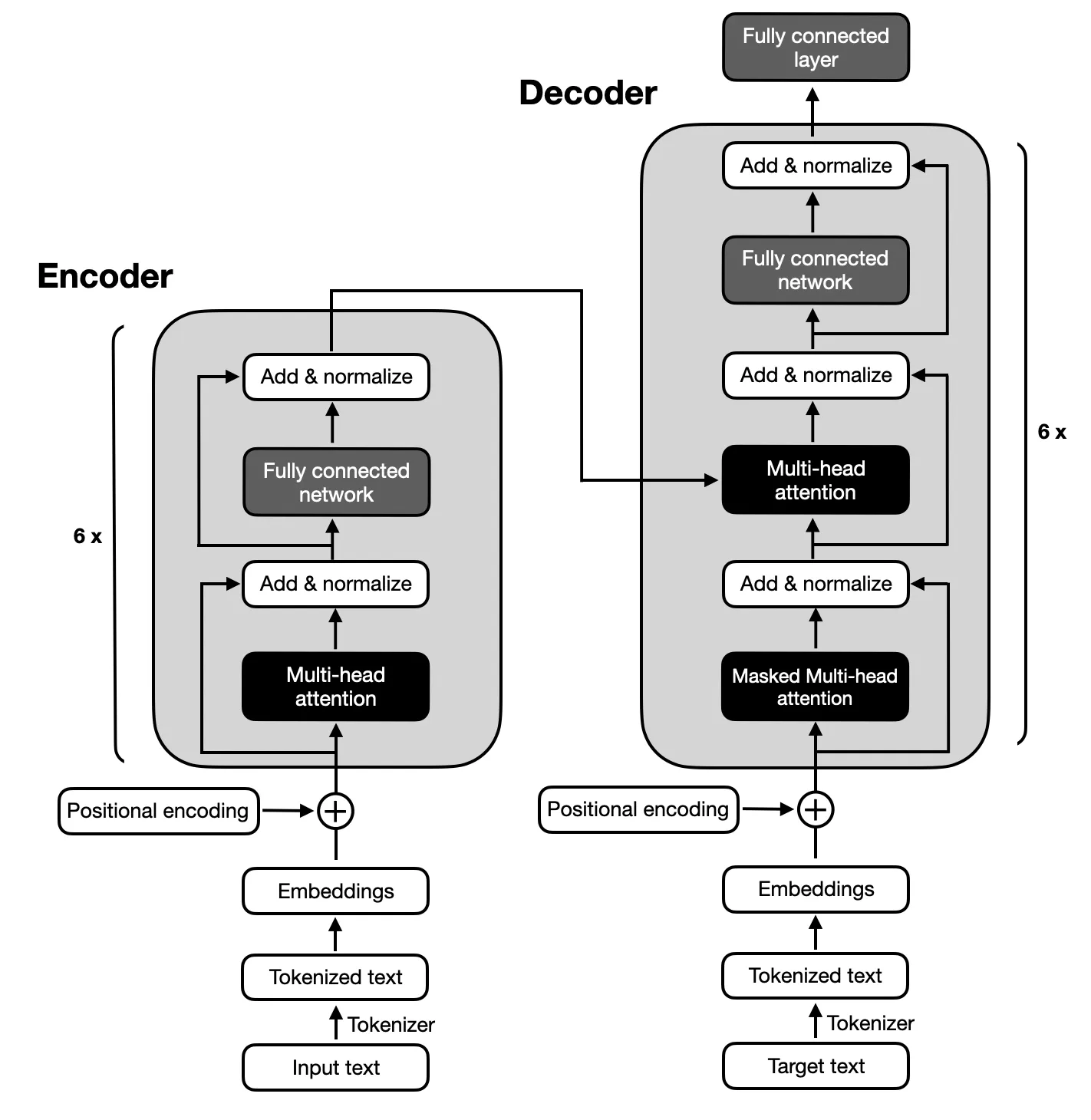
텍스트 요약에 필요한 입력 및 출력 시퀀스 간의 복잡한 매핑으로 인해 원래 Transformers에서 제안한 아키텍처를 따르는 인코더-디코더 모델에 중점을 둡니다. 인코더-디코더 모델은 이러한 시퀀스 내의 관계를 캡처하는 데 능숙하므로 이 작업에 적합합니다.
Python 3.x가 시스템에 설치되어 있는지 확인하십시오. 그런 다음 아래 단계에 따라 환경을 설정하세요.
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.py이 프로젝트는 6가지 주요 단계로 구성됩니다.
T5 및 BART 모델을 미세 조정하는 데 사용된 데이터세트는 Big Patent Dataset이었으며, 이는 사람이 작성한 추상 요약과 함께 130만 개의 미국 특허 문서로 구성되어 있습니다. 이 데이터 세트의 각 문서는 CPC(협력 특허 분류) 코드로 분류되어 인간 필수품부터 물리학 및 전기에 이르기까지 광범위한 주제를 다루고 있습니다. 이러한 다양성은 모델이 다양한 언어 사용 및 기술 전문 용어를 접할 수 있도록 보장하며, 이는 강력한 요약 기능을 개발하는 데 중요합니다.
빅특허데이터세트는 복잡한 문서를 요약하려는 프로젝트 목표와의 관련성 때문에 선택되었습니다. 특허는 본질적으로 상세하고 기술적이므로 핵심 내용과 맥락을 보존하면서 정보를 압축하는 모델의 능력을 테스트하는 데 이상적인 과제입니다. 데이터 세트의 구조화된 형식과 고품질 요약의 존재는 정확하고 일관된 요약을 생성하는 데 있어 모델 성능을 훈련하고 평가하기 위한 강력한 기반을 제공합니다.
모델의 성능은 ROUGE 지표를 사용하여 평가되었으며, 인간이 작성한 초록과 밀접하게 일치하는 요약을 생성하는 능력을 강조했습니다. BART와 T5 모델은 모두 Big Patent Dataset을 사용하여 미세 조정되었으며 고품질 추상 요약을 달성하는 데 중점을 두었습니다.
| 미터법 | 값 |
|---|---|
| 평가 손실(Eval Loss) | 1.9244 |
| 루즈-1 | 0.5007 |
| 루즈-2 | 0.2704 |
| 루즈-L | 0.3627 |
| 루즈-름섬 | 0.3636 |
| 평균 세대 길이(Gen Len) | 122.1489 |
| 런타임(초) | 1459.3826 |
| 초당 샘플 | 1.312 |
| 초당 단계 | 0.164 |
| 미터법 | 값 |
|---|---|
| 평가 손실(Eval Loss) | 1.9984 |
| 루즈-1 | 0.503 |
| 루즈-2 | 0.286 |
| 루즈-L | 0.3813 |
| 루즈-름섬 | 0.3813 |
| 평균 세대 길이(Gen Len) | 151.918 |
| 런타임(초) | 714.4344 |
| 초당 샘플 | 2.679 |
| 초당 단계 | 0.336 |


