WilmerAI
1.0.0
이것은 열심히 개발중인 개인 프로젝트입니다. 버그, 불완전한 코드 또는 기타 의도하지 않은 문제가 포함될 수 있으며 실제로 포함되어 있을 가능성이 높습니다. 따라서 소프트웨어는 어떠한 종류의 보증도 없이 있는 그대로 제공됩니다.
WilmerAI는 단일 개발자의 작업과 개인 시간 및 자원의 노력을 반영합니다. 내부에서 발견되는 모든 견해, 방법론 등은 자신의 것이며 고용주에게 반영되어서는 안 됩니다.
WilmerAI는 들어오는 프롬프트를 받아 LLM API로 보내기 전에 다양한 작업을 수행하도록 설계된 정교한 미들웨어 시스템입니다. 이 작업에는 LLM(대형 언어 모델)을 활용하여 프롬프트를 분류하고 적절한 워크플로로 라우팅하거나 대규모 컨텍스트(200,000개 이상의 토큰)를 처리하여 대부분의 로컬 모델에 적합한 더 작고 관리하기 쉬운 프롬프트를 생성하는 작업이 포함됩니다.
WilmerAI는 "언어 모델이 모든 추론을 전문적으로 라우팅한다면 어떻게 될까요?" 를 의미합니다.
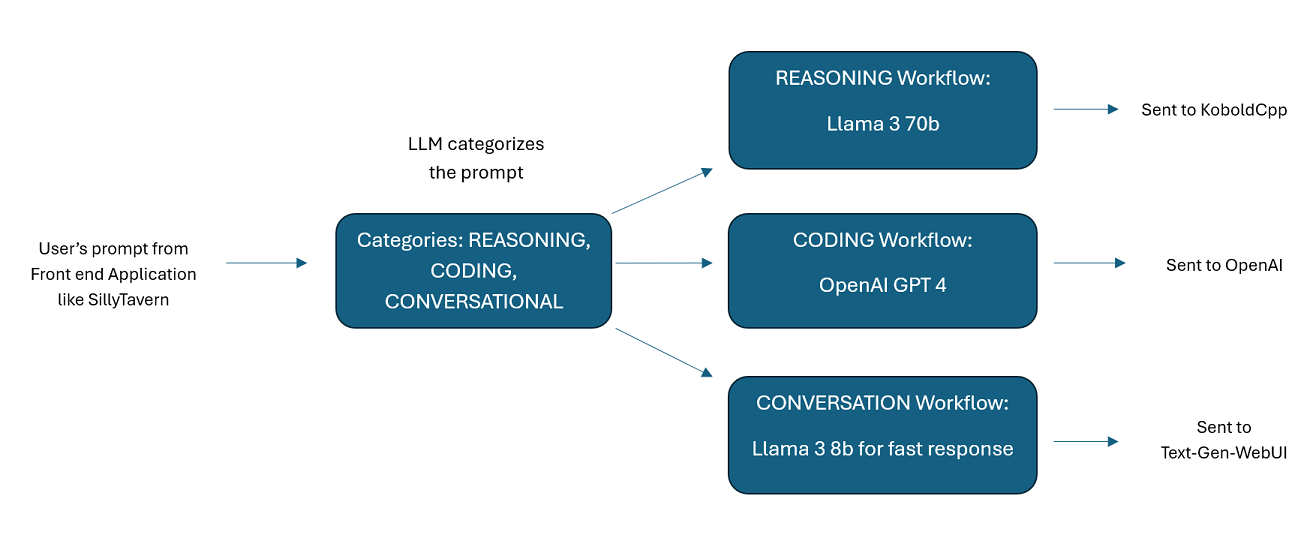
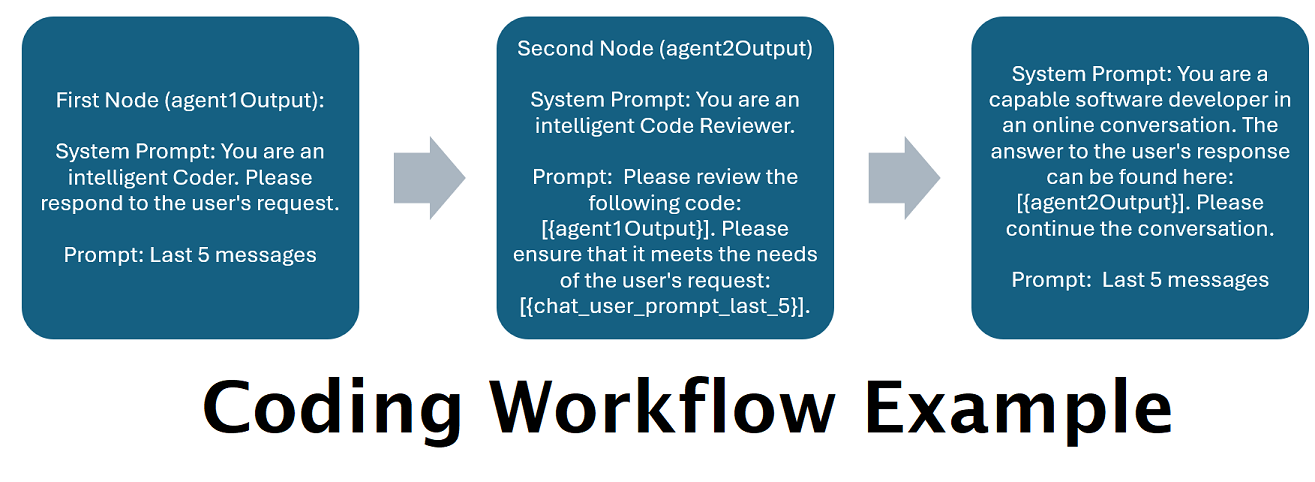
여러 LLM이 함께 제공하는 보조자 : 들어오는 프롬프트를 "범주"로 라우팅할 수 있으며 각 범주는 워크플로로 구동됩니다. 각 워크플로에는 원하는 만큼의 노드가 있을 수 있으며, 각 노드는 서로 다른 LLM으로 구동됩니다. 예를 들어, 어시스턴트에게 "파이썬으로 스네이크 게임을 작성해 주실 수 있나요?"라고 묻는다면 이는 코딩으로 분류되어 코딩 작업 흐름으로 이동할 수 있습니다. 해당 워크플로의 첫 번째 노드는 Codestral-22b(또는 원하는 경우 ChatGPT 4o)에게 질문에 답하도록 요청할 수 있습니다. 두 번째 노드는 Deepseek V2 또는 Claude Sonnet에게 코드 검토를 요청할 수 있습니다. 다음 노드는 Codestral에 최종 결과를 한 번 제공하고 응답하도록 요청할 수 있습니다. 귀하의 워크플로우가 최고의 코더이기 때문에 응답하는 단일 모델인지, 아니면 서로 다른 LLM의 여러 노드가 함께 작동하여 응답을 생성하는지 여부는 귀하의 선택입니다.
오프라인 Wikipedia API 지원 : WilmerAI에는 OfflineWikipediaTextApi를 호출할 수 있는 노드가 있습니다. 즉, 들어오는 메시지를 보고 쿼리를 생성하고 Wikipedia API에 관련 기사를 쿼리하고 해당 기사를 RAG 컨텍스트 삽입으로 사용하여 응답하는 카테고리(예: "FACTUAL")가 있을 수 있습니다.
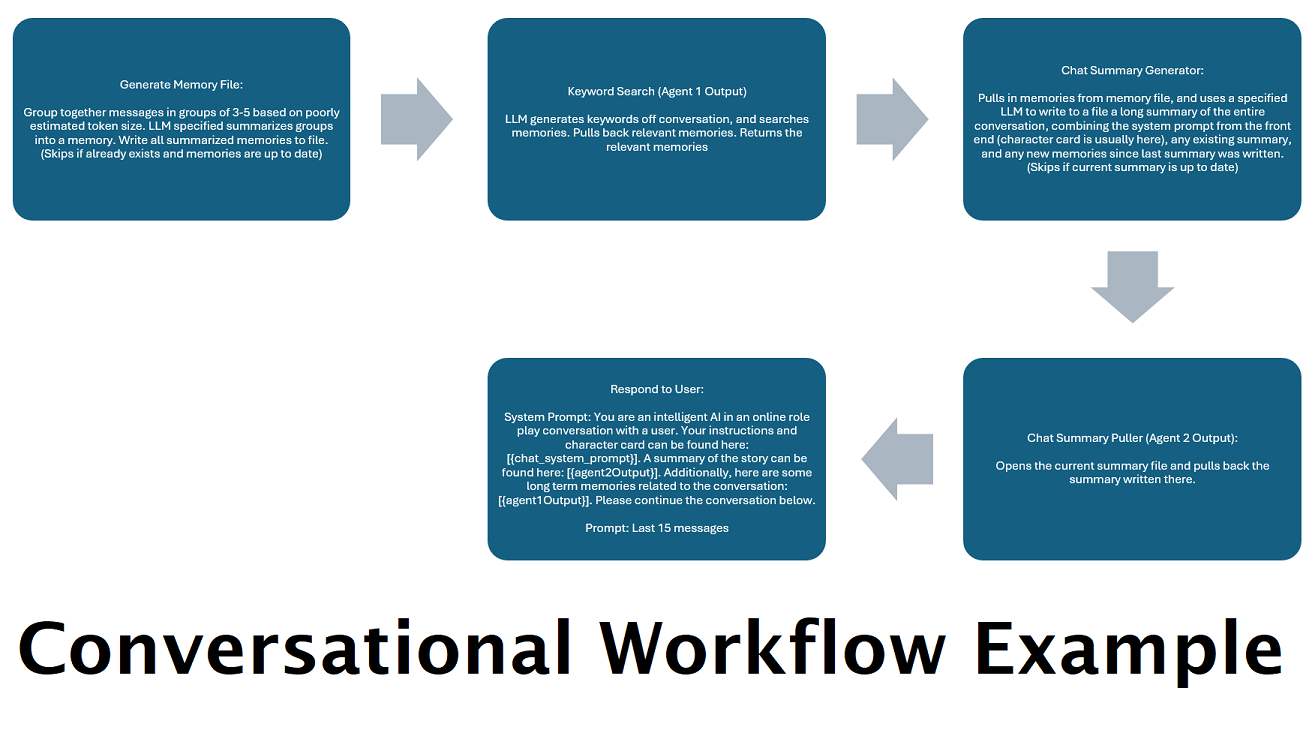
"메모리"를 시뮬레이션하기 위해 지속적으로 생성되는 채팅 요약 : 채팅 요약 노드는 메시지를 청크한 다음 요약하고 파일에 저장하여 "메모리"를 생성합니다. 그런 다음 요약된 청크를 가져와 LLM에 대한 프롬프트 내에서 가져와 사용할 수 있는 전체 대화의 지속적이고 지속적으로 업데이트되는 요약을 생성합니다. 결과를 통해 LLM에 대한 프롬프트를 5,000개 이하의 컨텍스트로 제한하더라도 200,000개 이상의 컨텍스트 대화를 수행하고 말한 내용을 상대적으로 추적할 수 있습니다.
병렬 프로세스 메모리 및 응답을 위해 여러 컴퓨터 사용 : LLM을 실행할 수 있는 컴퓨터가 두 대 있는 경우 한 대는 "응답자"로 지정하고 다른 한 대는 메모리/요약 생성을 담당하도록 지정할 수 있습니다. 이러한 종류의 작업 흐름을 사용하면 기존 메모리를 계속 사용하면서 메모리/요약이 업데이트되는 동안 LLM과 계속 대화할 수 있습니다. 이는 더 높은 품질의 메모리를 확보하기 위해 해당 작업을 처리하기 위해 크고 강력한 모델을 작업하더라도 요약이 업데이트될 때까지 기다릴 필요가 없음을 의미합니다. (예제 사용자 convo-role-dual-model 참조)
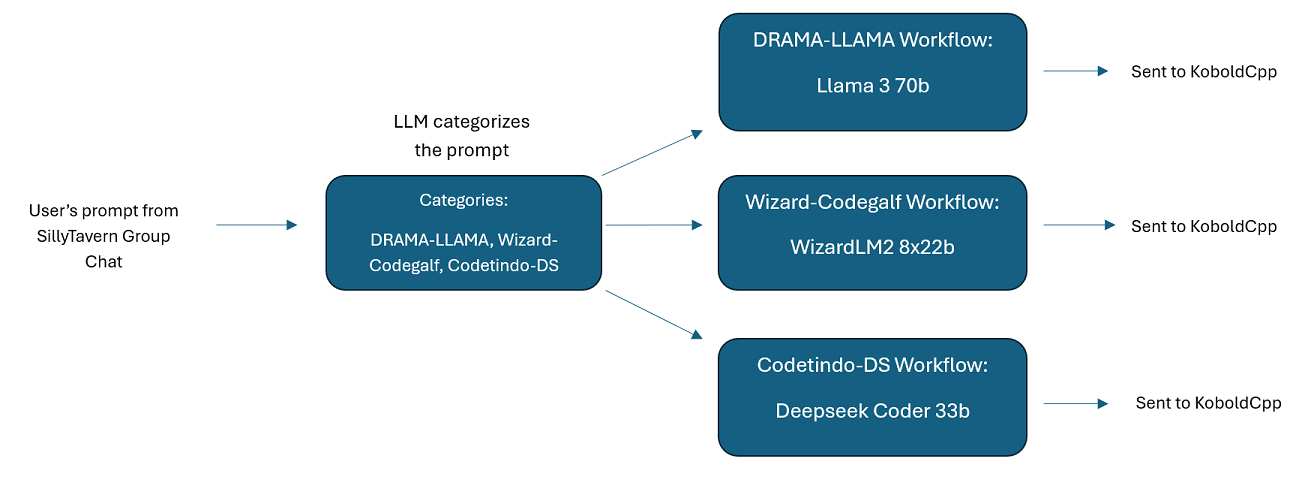
SillyTavern의 다중 LLM 그룹 채팅: 원하는 경우 모든 캐릭터가 다른 LLM인 ST에서 Wilmer를 사용하여 그룹 채팅을 할 수 있습니다(저자가 개인적으로 이 작업을 수행합니다.) DocsSillyTavern 에 사용 가능한 예제 캐릭터가 있습니다. 두 그룹으로 나뉩니다. 이러한 예시 캐릭터/그룹은 작성자가 사용하는 더 큰 그룹의 하위 집합입니다.
미들웨어 기능: WilmerAI는 LLM(예: SillyTavern, OpenWebUI 또는 Python 프로그램 터미널)과 통신하는 데 사용하는 인터페이스와 LLM을 제공하는 백엔드 API 사이에 위치합니다. 여러 백엔드 LLM을 동시에 처리할 수 있습니다.
한 번에 여러 LLM 사용: 설정 예: SillyTavern -> WilmerAI -> KoboldCpp의 여러 인스턴스. 예를 들어 Wilmer는 Command-R 35b, Codestral 22b, Gemma-2-27b에 연결되어 사용자에게 응답하는 데 이러한 모든 것을 사용할 수 있습니다. 선택한 LLM이 v1/완료 또는 채팅/완료 엔드포인트 또는 KoboldCpp의 생성 엔드포인트를 통해 노출되는 한 이를 사용할 수 있습니다.
사용자 정의 가능한 사전 설정 : 사전 설정은 쉽게 사용자 정의할 수 있는 json 파일에 저장됩니다. 매개변수 이름을 포함하여 거의 모든 사전 설정을 json을 통해 관리할 수 있습니다. 즉, 새로운 기능을 활용하기 위해 Wilmer 업데이트를 기다릴 필요가 없습니다. 예를 들어 최근 KoboldCpp에서 DRY가 나왔습니다. Wilmer의 사전 설정 json에 없으면 간단히 추가하고 사용을 시작할 수 있습니다.
API 엔드포인트: 프런트 엔드를 통해 연결할 수 있는 OpenAI API 호환 chat/Completions 및 v1/Completions 엔드포인트를 제공하며 백엔드에서 두 유형 중 하나에 연결할 수 있습니다. 이를 통해 v1/Completion API로 Wilmer에 연결한 다음 Wilmer를 chat/Completion, v1/Completion KoboldCpp에 연결하여 동시에 엔드포인트를 생성하는 등의 복잡한 구성이 가능합니다.
프롬프트 템플릿: v1/Completions API 엔드포인트에 대한 프롬프트 템플릿을 지원합니다. WilmerAI에는 v1/Completions 통한 프런트 엔드 연결을 위한 자체 프롬프트 템플릿도 있습니다. 템플릿은 "Docs" 폴더에서 찾을 수 있으며 SillyTavern에 업로드할 준비가 되어 있습니다.

워크플로는 본질적으로 설정 방법에 따라 API 엔드포인트를 여러 번 호출할 수 있다는 점을 명심하세요. WilmerAI는 토큰 사용을 추적하지 않으며 API를 통해 정확한 토큰 사용을 보고하지 않으며 토큰 사용을 모니터링할 수 있는 실행 가능한 방법을 제공하지 않습니다. 따라서 비용상의 이유로 토큰 사용 추적이 중요한 경우, 특히 이 소프트웨어에 익숙해지는 초기 단계에 LLM API에서 제공하는 대시보드를 통해 사용 중인 토큰 수를 추적하십시오.
LLM은 WilmerAI의 품질에 직접적인 영향을 미칩니다. 이는 흐름과 출력이 연결된 LLM과 해당 응답에 거의 전적으로 의존하는 LLM 기반 프로젝트입니다. Wilmer를 낮은 품질의 출력을 생성하는 모델에 연결하거나 사전 설정 또는 프롬프트 템플릿에 결함이 있는 경우 Wilmer의 전반적인 품질도 훨씬 낮아집니다. 그런 점에서는 에이전트 워크플로와 크게 다르지 않습니다.
저자는 유용하고 고품질의 무언가를 만들기 위해 최선을 다하고 있지만 이것은 야심찬 솔로 프로젝트이므로 문제가 있을 수 있습니다(특히 저자가 기본적으로 Python 개발자가 아니고 이를 달성하는 데 AI에 크게 의존했기 때문입니다). 멀리). 하지만 그는 천천히 그것을 알아내고 있다.
Wilmer는 OpenAI v1/완료 및 채팅/완료 엔드포인트를 모두 노출하여 대부분의 프런트 엔드와 호환됩니다. 나는 주로 이것을 SillyTavern과 함께 사용했지만 Open-WebUI에서도 작동할 수도 있습니다.
SillyTavern에서 텍스트 완성으로 연결하려면 다음 단계를 따르세요. (아래 스크린샷은 SillyTavern에서 가져온 것입니다.)
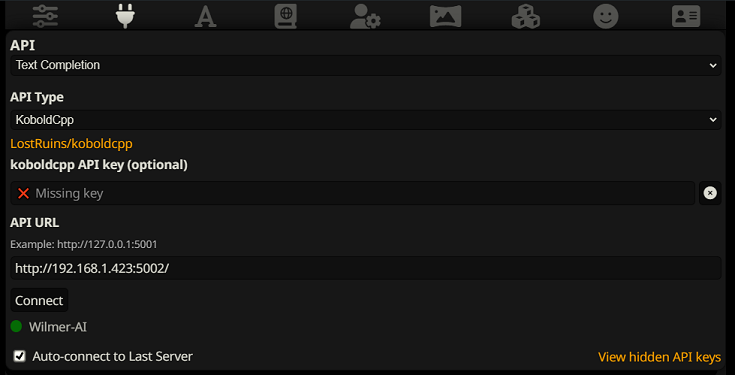
텍스트 완성 기능을 사용할 때는 WilmerAI 전용 프롬프트 템플릿 형식을 사용해야 합니다. 가져올 수 있는 ST 파일은 Docs/SillyTavern/InstructTemplate 에서 찾을 수 있습니다. 사용하려는 경우 컨텍스트 템플릿도 포함되어 있습니다.
지침 템플릿은 다음과 같습니다.
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
SillyTavern에서:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
태그 사이에 예상되는 줄 바꿈이나 문자가 없습니다.
컨텍스트 템플릿이 "활성화"되어 있는지 확인하십시오(드롭다운 위의 확인란).
SillyTavern에서 채팅 완료로 연결하려면 다음 단계를 따르세요(아래 스크린샷은 SillyTavern에서 가져온 것입니다).
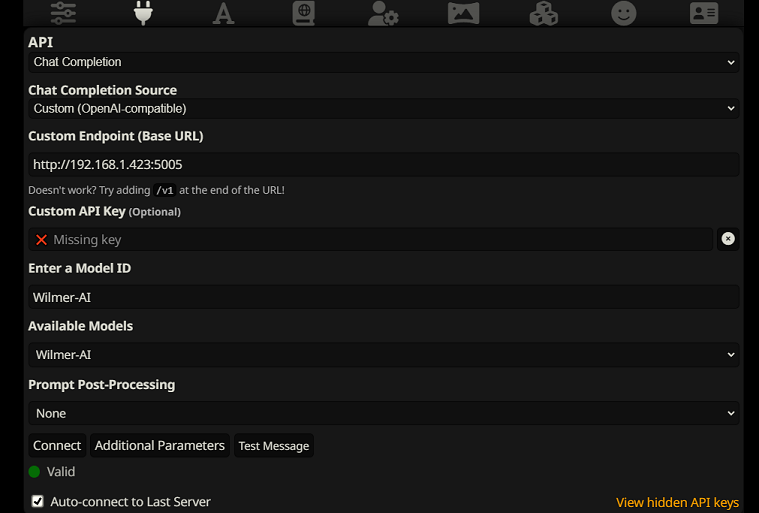
chatCompleteAddUserAssistant true로 설정하십시오. (두 가지를 동시에 true로 설정하는 것은 권장하지 않습니다. SillyTavern의 캐릭터 이름이나 Wilmer의 사용자/보조자 이름을 사용하십시오. 그렇지 않으면 AI가 혼란스러울 수 있습니다.)어느 연결 유형이든 SillyTavern의 "A" 아이콘으로 이동하여 지시 모드에서 "Include Names" 및 "Force Groups and Personas"를 선택한 다음 맨 왼쪽 아이콘(샘플러가 있는 곳)으로 이동하여 " 스트림"을 왼쪽 상단에 표시한 다음 오른쪽 상단의 컨텍스트에서 "잠금 해제"를 선택하고 200,000+로 드래그합니다. Wilmer가 상황에 대해 걱정하도록 하세요.
Wilmer에는 현재 사용자 인터페이스가 없습니다. 모든 것은 "Public" 폴더에 있는 JSON 구성 파일을 통해 제어됩니다. 이 폴더에는 모든 필수 구성이 포함되어 있습니다. WilmerAI의 새 복사본을 업데이트하거나 다운로드할 때 설정을 유지하려면 "Public" 폴더를 새 설치에 복사하기만 하면 됩니다.
이 섹션에서는 Wilmer를 설정하는 과정을 안내합니다. 섹션을 여러 단계로 나누었습니다. 각 단계를 하나씩 LLM에 복사하고 섹션 설정에 도움을 요청하는 것이 좋습니다. 그러면 이 일이 훨씬 쉬워질 수 있습니다.
중요 사항
Wilmer 설정에 관해 세 가지 사항에 유의하는 것이 중요합니다.
A) 사전 설정 파일은 100% 사용자 정의가 가능합니다. 해당 파일의 내용은 llm API로 이동됩니다. 이는 클라우드 API가 로컬 LLM API가 처리하는 다양한 사전 설정 중 일부를 처리하지 않기 때문입니다. 따라서 OpenAI API 또는 기타 클라우드 서비스를 사용하는 경우 일반 로컬 AI 사전 설정 중 하나를 사용하면 호출이 실패할 수 있습니다. openAI가 허용하는 예는 사전 설정된 "OpenAI-API"를 참조하세요.
B) 나는 최근 Wilmer의 모든 프롬프트를 2인칭 사용에서 3인칭 사용으로 바꾸었습니다. 이것은 나에게 꽤 괜찮은 결과를 가져왔고, 당신에게도 그러기를 바랍니다.
C) 기본적으로 모든 사용자 파일은 스트리밍 응답을 켜도록 설정되어 있습니다. Wilmer를 호출하는 프런트 엔드에서 이를 활성화하여 둘 다 일치하도록 하거나, Users/username.json으로 이동하여 Stream을 "false"로 설정해야 합니다. 프런트 엔드가 스트리밍을 기대하거나 기대하지 않고 윌머가 그 반대를 기대하는 불일치가 있는 경우 프런트 엔드에는 아무 것도 표시되지 않을 가능성이 높습니다.
Wilmer 설치는 간단합니다. Python이 설치되어 있는지 확인하십시오. 저자는 Python 3.10 및 3.12에서 프로그램을 사용해 왔으며 둘 다 잘 작동합니다.
옵션 1: 제공된 스크립트 사용
편의를 위해 Wilmer에는 Windows용 BAT 파일과 macOS용 .sh 파일이 포함되어 있습니다. 이 스크립트는 가상 환경을 생성하고, requirements.txt 에서 필요한 패키지를 설치한 다음 Wilmer를 실행합니다. 이 스크립트를 사용하여 매번 Wilmer를 시작할 수 있습니다.
.bat 파일을 실행하세요..sh 파일을 실행합니다.중요: 위험할 수 있으므로 먼저 검사하지 않고 BAT 또는 SH 파일을 실행하지 마십시오. 해당 파일의 안전성이 확실하지 않은 경우 메모장/텍스트 편집기에서 파일을 열고 내용을 복사한 다음 LLM에게 잠재적인 문제가 있는지 검토하도록 요청하세요.
옵션 2: 수동 설치
또는 다음 단계에 따라 종속성을 수동으로 설치하고 Wilmer를 실행할 수 있습니다.
필수 패키지를 설치합니다:
pip install -r requirements.txt프로그램을 시작합니다:
python server.py제공된 스크립트는 가상 환경을 설정하여 프로세스를 간소화하도록 설계되었습니다. 그러나 수동 설치를 선호하는 경우 이를 무시해도 됩니다.
참고 : bat 파일, sh 파일 또는 python 파일을 실행할 때 이제 세 가지 모두 다음과 같은 선택적 인수를 허용합니다.
예를 들어 다음과 같은 가능한 실행을 고려하십시오.
bash run_macos.sh (_current-user.json에 지정된 사용자, "Public"의 구성, "logs"의 로그 사용)bash run_macos.sh --User "single-model-assistant" (기본값은 구성의 경우 공개, 로그의 경우 "log")bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" ("로그"에 기본값을 사용함)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"이러한 선택적 인수를 통해 사용자는 WilmerAI의 여러 인스턴스를 가동할 수 있습니다. 각 인스턴스는 원하는 경우 서로 다른 사용자 프로필을 사용하고, 서로 다른 위치에 로그인하고, 서로 다른 위치에서 구성을 지정합니다.
Public/Configs 내에는 json 파일이 포함된 일련의 폴더가 있습니다. 가장 관심 있는 두 가지는 Endpoints 폴더와 Users 폴더입니다.
참고: assistant-single-model , assistant-multi-model 및 group-chat-example 사용자의 사실적 작업 흐름 노드는 OfflineWikipediaTextApi 프로젝트를 활용하여 전체 Wikipedia 기사를 RAG로 가져오려고 시도합니다. 이 API가 없으면 워크플로에 문제가 없어야 하지만 저는 개인적으로 이 API를 사용하여 사실적인 응답을 개선하는 데 도움을 줍니다. 선택한 사용자 json에서 API에 대한 IP 주소를 지정할 수 있습니다.
먼저 사용할 템플릿 사용자를 선택하세요.
Assistant-single-model : 이 템플릿은 모든 노드에서 사용되는 단일 소형 모델을 위한 것입니다. 또한 다양한 카테고리 유형에 대한 경로가 있으며 각 노드에 적절한 사전 설정을 사용합니다. 모델이 1개뿐인데 왜 다른 카테고리에 대한 경로가 있는지 궁금하다면, 각 카테고리에 고유한 사전 설정을 제공하고 해당 카테고리에 대한 사용자 정의 작업 흐름을 만들 수 있기 때문입니다. 어쩌면 코더가 자체적으로 확인하기 위해 여러 번의 반복을 수행하거나 여러 단계에서 사물을 생각하는 추론을 수행하기를 원할 수도 있습니다.
Assistant-multi-model : 이 템플릿은 여러 모델을 동시에 사용하기 위한 템플릿입니다. 이 사용자의 엔드포인트를 살펴보면 모든 카테고리에 고유한 엔드포인트가 있음을 알 수 있습니다. 여러 카테고리에 동일한 API를 재사용하는 것을 막을 수 있는 방법은 전혀 없습니다. 예를 들어 코딩, 수학 및 추론에는 Llama 3.1 70b를 사용하고 분류, 대화 및 사실 확인에는 Command-R 35b 08-2024를 사용할 수 있습니다. 10개의 다른 모델이 필요하다고 생각하지 마십시오. 이것은 단순히 당신이 원할 경우 그렇게 많은 것을 가져올 수 있도록 하기 위한 것입니다. 이 사용자는 워크플로의 각 노드에 대해 적절한 사전 설정을 사용합니다.
convo-roleplay-single-model : 이 사용자는 대화에 적합하고 역할극에 적합해야 하는 사용자 정의 워크플로가 있는 단일 모델을 사용합니다(필요한 경우 조정할 피드백을 기다립니다). 이는 모든 라우팅을 우회합니다.
convo-roleplay-dual-model : 이 사용자는 대화에 적합하고 역할극에 적합해야 하는 사용자 정의 워크플로가 있는 두 가지 모델을 사용합니다(필요한 경우 조정할 피드백을 기다립니다). 이는 모든 라우팅을 우회합니다. 참고 : 이 워크플로는 LLM을 실행할 수 있는 컴퓨터가 2대 있는 경우 가장 잘 작동합니다. 이 사용자에 대한 현재 설정에서는 Wilmer에게 메시지를 보내면 응답자 모델(컴퓨터 1)이 응답합니다. 그런 다음 워크플로는 해당 시점에 "워크플로 잠금"을 적용합니다. 그런 다음 메모리/채팅 요약 모델(컴퓨터 2)은 지금까지의 대화 요약과 추억을 업데이트하기 시작하며, 이는 내용을 기억하는 데 도움이 되도록 응답자에게 전달됩니다. 메모리가 기록되는 동안 다른 메시지를 보내면 응답자(컴퓨터 1)는 존재하는 모든 요약을 파악하여 계속해서 응답합니다. 워크플로 잠금으로 인해 새 추억 섹션에 다시 들어갈 수 없습니다. 이것이 의미하는 바는 새로운 기억이 기록되는 동안 응답자 모델과 계속 대화할 수 있다는 것입니다. 이는 엄청난 성능 향상입니다. 나는 그것을 시험해 보았고 응답 시간은 놀랍습니다. 이게 없으면 30초 안에 3~5번 응답을 받다가 갑자기 2분 정도 기다려서 추억을 생성하게 되는 거죠. 이를 통해 내 Mac Studio의 Llama 3.1 70b에서 모든 메시지는 매번 30초입니다.
group-chat-example : 이 사용자는 내 개인 그룹 채팅의 예입니다. 포함된 캐릭터와 그룹은 제가 사용하는 실제 캐릭터와 그룹입니다. Docs/SillyTavern 폴더에서 예시 캐릭터를 찾아보실 수 있습니다. 이는 해당 프로그램이나 .png 문자 가져오기 유형을 지원하는 모든 프로그램으로 직접 가져올 수 있는 SillyTavern 호환 문자입니다. 개발팀 캐릭터는 워크플로당 노드가 1개만 있습니다. 그들은 단순히 사용자에게 응답합니다. 자문 그룹 캐릭터에는 작업 흐름당 2개의 노드가 있습니다. 첫 번째 노드는 응답을 생성하고 두 번째 노드는 캐릭터의 "페르소나"를 시행합니다(이를 담당하는 엔드포인트는 businessgroup-speaker 엔드포인트입니다). 그룹 채팅 페르소나는 모델을 하나만 사용하더라도 응답을 다양화하는 데 많은 도움이 됩니다. 그러나 저는 모든 캐릭터에 대해 서로 다른 모델을 사용하는 것을 목표로 합니다(그러나 그룹 간에는 모델을 재사용합니다. 예를 들어 각 그룹에 Llama 3.1 70b 모델 캐릭터가 있습니다).
사용하려는 사용자를 선택한 후 수행해야 할 몇 가지 단계가 있습니다.
Public/Configs/Endpoints에서 사용자의 엔드포인트를 업데이트합니다. 예제 문자는 각각 폴더로 정렬됩니다. 사용자의 엔드포인트 폴더는 user.json 파일의 맨 아래에 지정됩니다. 사용 중인 LLM에 맞게 모든 끝점을 채우는 것이 좋습니다. _example-endpoints 폴더에서 몇 가지 예시 엔드포인트를 찾을 수 있습니다.
현재 사용자를 설정해야 합니다. --User 인수를 사용하여 bat/sh/py 파일을 실행할 때 이 작업을 수행하거나 Public/Configs/Users/_current-user.json에서 이 작업을 수행할 수 있습니다. 사용자의 이름을 현재 사용자로 입력하고 저장하면 됩니다.
사용자 json 파일을 열고 옵션을 살펴보고 싶을 것입니다. 여기에서는 스트리밍 여부를 설정할 수 있고, 오프라인 위키 API에 대한 IP 주소를 설정할 수 있으며(사용하는 경우), DiscussionId 흐름 중에 추억/요약 파일을 이동할 위치를 지정할 수 있습니다. 워크플로 잠금을 사용하는 경우 sqllite db가 이동하기를 원합니다.
그게 다야! Wilmer를 실행하고 연결하면 됩니다.
먼저 엔드포인트와 모델을 설정합니다. Public/Configs 폴더 내에는 다음 하위 폴더가 표시됩니다. 필요한 사항을 살펴보겠습니다.
이러한 구성 파일은 연결된 LLM API 끝점을 나타냅니다. 예를 들어 다음 JSON 파일 SmallModelEndpoint.json 은 엔드포인트를 정의합니다.
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}이러한 구성 파일은 Wilmer를 사용할 때 발생할 수 있는 다양한 API 유형을 나타냅니다.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} 이러한 파일은 모델에 대한 프롬프트 템플릿을 지정합니다. 다음 예시인 llama3.json 을 살펴보세요.
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} 이러한 템플릿은 모든 v1/Completion 엔드포인트 호출에 적용됩니다. 템플릿을 사용하지 않으려면 메시지를 줄 바꿈으로만 나누는 _chatonly.json 이라는 파일이 있습니다.
사용자 생성 및 활성화에는 네 가지 주요 단계가 포함됩니다. 새 사용자를 설정하려면 아래 지침을 따르세요.
먼저 Users 폴더 내에서 새 사용자에 대한 JSON 파일을 만듭니다. 가장 쉬운 방법은 기존 사용자 JSON 파일을 복사하여 복사본으로 붙여넣은 다음 이름을 바꾸는 것입니다. 다음은 사용자 JSON 파일의 예입니다.
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 에서 호스팅하므로 다른 컴퓨터에서 실행되는 경우 네트워크에 표시됩니다. 서로 다른 포트에서 Wilmer의 여러 인스턴스를 실행하는 것이 지원됩니다.true 이면 라우터가 비활성화되고 모든 프롬프트가 지정된 워크플로로만 이동하여 Wilmer의 단일 워크플로 인스턴스가 됩니다.customWorkflowOverride 가 true 일 때 사용할 사용자 정의 워크플로입니다..json 확장자가 없는 Routing 폴더의 라우팅 구성 파일 이름입니다.DiscussionId 사용 시 충돌을 방지하려면 이 디렉터리가 존재하는지 확인하세요.chatCompleteAddUserAssistant 가 true 인 경우에만 사용됩니다.DataFinder 문자에 사용할지 여부를 지정합니다. 다음으로, _current-user.json 파일을 업데이트하여 사용하려는 사용자를 지정하세요. .json 확장자를 제외하고 새 사용자 JSON 파일의 이름을 일치시킵니다.
참고 : 대신 Wilmer를 실행할 때 --User 인수를 사용하려는 경우 이를 무시할 수 있습니다.
Routing 폴더에 라우팅 JSON 파일을 생성합니다. 이 파일의 이름은 원하는 대로 지정할 수 있습니다. .json 확장자를 제외하고 이 이름으로 사용자 JSON 파일의 routingConfig 속성을 업데이트합니다. 다음은 라우팅 구성 파일의 예입니다.
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json 확장명이 없는 워크플로 JSON 파일의 이름입니다. Workflow 폴더에서 Users 폴더의 사용자 이름과 일치하는 새 폴더를 만듭니다. 이를 수행하는 가장 빠른 방법은 기존 사용자의 폴더를 복사하고 복제한 후 이름을 바꾸는 것입니다.
다른 변경 사항을 적용하지 않기로 선택한 경우 워크플로를 진행하고 원하는 끝점을 가리키도록 끝점을 업데이트해야 합니다. Wilmer가 추가된 예제 워크플로를 사용하고 있다면 여기에서는 이미 문제가 없을 것입니다.
"Public" 폴더에는 다음이 있어야 합니다.
이 프로젝트의 워크플로는 사용자의 특정 워크플로 폴더에 있는 Public/Workflows 폴더에서 수정되고 제어됩니다. 예를 들어 사용자 이름이 socg 이고 Users 폴더에 socg.json 파일이 있는 경우 워크플로 내에 Workflows/socg 폴더가 있어야 합니다.
다음은 워크플로 JSON의 모양에 대한 예입니다.
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]위의 워크플로는 대화 노드로 구성됩니다. 두 노드 모두 하나의 간단한 작업을 수행합니다. 즉, 끝점에 지정된 LLM에 메시지를 보내는 것입니다.
title 과 유사합니다. 에이전트 출력을 추적하려면 "One", "Two" 등으로 끝나는 이름을 지정하는 것이 도움이 됩니다. 첫 번째 노드의 출력은 {agent1Output} 에 저장되고, 두 번째 노드의 출력은 {agent2Output} 에 저장되는 식입니다..json 확장자를 제외한 Endpoints 폴더의 JSON 파일 이름과 일치해야 합니다..json 확장자를 제외한 Presets 폴더의 JSON 파일 이름과 일치해야 합니다.false 로 설정합니다(위의 첫 번째 예제 노드 참조). 프롬프트를 보내는 경우 이를 true 로 설정합니다(위의 두 번째 예제 노드 참조). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
이 프롬프트 내에서 여러 변수를 사용할 수 있습니다. 런타임에 적절하게 교체됩니다.
{chat_user_prompt_last_one} : 즉각적인 템플릿 태그가 메시지를 감싸지 않고 대화의 마지막 메시지.{templated_user_prompt_last_one} : 대화의 마지막 메시지는 적절한 사용자/어시스턴트 프롬프트 템플릿 태그로 싸여 있습니다.{chat_system_prompt} : 프론트 엔드에서 보낸 시스템 프롬프트가 있습니다. 종종 문자 카드 및 기타 중요한 정보가 포함됩니다.{templated_system_prompt} : 프론트 엔드에서 시스템 프롬프트가 적절한 시스템 프롬프트 템플릿 태그로 싸여 있습니다.{agent#Output} : # 원하는 번호로 대체됩니다. 모든 노드는 에이전트 출력을 생성합니다. 첫 번째 노드는 항상 1이고 각 후속 노드는 1 씩 증가합니다. 예를 들어, 첫 번째 노드의 경우 {agent1Output} , 두 번째 노드의 경우 {agent2Output} 등.{category_colon_descriptions} : Routing JSON 파일에서 범주 및 설명을 가져옵니다.{categoriesSeparatedByOr} : "또는"로 분리 된 범주 이름을 가져옵니다.[TextChunk] : 병렬 프로세서에 고유 한 특수 변수로 자주 사용되지 않을 수 있습니다.참고 : 기억이 어떻게 작동하는지에 대한 더 깊은 이해는 이해 섹션 이해 섹션을 참조하십시오.
이 노드는 N 수의 메모리 (또는 토론이없는 경우 가장 최근의 메시지)를 가져오고 그들 사이에 사용자 정의 구분기를 추가합니다. 따라서 3 개의 추억이있는 메모리 파일이 있고 " n --------- n"의 구분기를 선택하면 다음을 얻을 수 있습니다.
This is the first memory
---------
This is the second memory
---------
This is the third memory
이 노드를 채팅 요약과 결합하면 LLM은 전체 대화의 전체 대화의 요약 된 분류뿐만 아니라 요약이 구축 된 모든 기억의 목록을 수신 할 수 있습니다. 그것. 마지막 15-20 개의 메시지와 함께 두 가지를 함께 보내면 전체 채팅에 대한 지속적이고 지속적인 메모리에 대한 인상이 가장 최근의 메시지까지 생성 될 수 있습니다. 추억을 생성하기위한 좋은 프롬프트를 만들기위한 특별한주의는 당신이 관심있는 세부 사항을 포착하도록하는 데 도움이 될 수 있지만, 적절한 세부 사항은 무시됩니다.
이 노드는 새로운 기억을 생성하지 않습니다. 이것은 멀티 컴퓨터 설정에서 사용하는 경우 워크 플로 잠금을 존중할 수 있습니다. 현재 추억을 생성하는 가장 좋은 방법은 FullChatsummary 노드입니다.


