JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
진타오 페이 1 민유 가오 1
1 JD Health International Inc. 2 절강대학교
오디오 기반 인물 애니메이션은 확산 기반 모델을 통해 크게 발전하여 비디오 품질과 립싱크 정확도가 향상되었습니다. 그러나 이러한 모델의 복잡성이 증가함에 따라 교육 및 추론의 비효율성은 물론 비디오 길이 및 프레임 간 연속성에 대한 제약이 발생했습니다. 본 논문에서는 오디오 기반 얼굴 애니메이션에서 얼굴 역학과 머리 움직임을 생성하기 위한 확산 기반 방법인 JoyVASA를 제안합니다. 구체적으로 첫 번째 단계에서는 동적 얼굴 표정과 정적 3D 얼굴 표현을 분리하는 분리된 얼굴 표현 프레임워크를 소개합니다. 이러한 분리를 통해 시스템은 정적 3D 얼굴 표현을 동적 모션 시퀀스와 결합하여 더 긴 비디오를 생성할 수 있습니다. 그런 다음 두 번째 단계에서는 캐릭터 정체성과 관계없이 오디오 신호에서 직접 모션 시퀀스를 생성하도록 확산 변환기를 훈련합니다. 마지막으로 첫 번째 단계에서 훈련된 생성기는 3D 얼굴 표현과 생성된 모션 시퀀스를 입력으로 사용하여 고품질 애니메이션을 렌더링합니다. 분리된 얼굴 표현과 신원에 독립적인 모션 생성 프로세스를 통해 JoyVASA는 인간 초상화를 넘어 동물 얼굴을 원활하게 애니메이션화합니다. 이 모델은 중국어 비공개 데이터와 영어 공개 데이터의 하이브리드 데이터세트로 학습되어 다국어 지원이 가능합니다. 실험 결과는 우리 접근 방식의 효율성을 검증합니다. 향후 작업에서는 실시간 성능을 개선하고 표현 제어를 개선하여 인물 애니메이션에서 프레임워크의 적용을 더욱 확장하는 데 중점을 둘 것입니다.
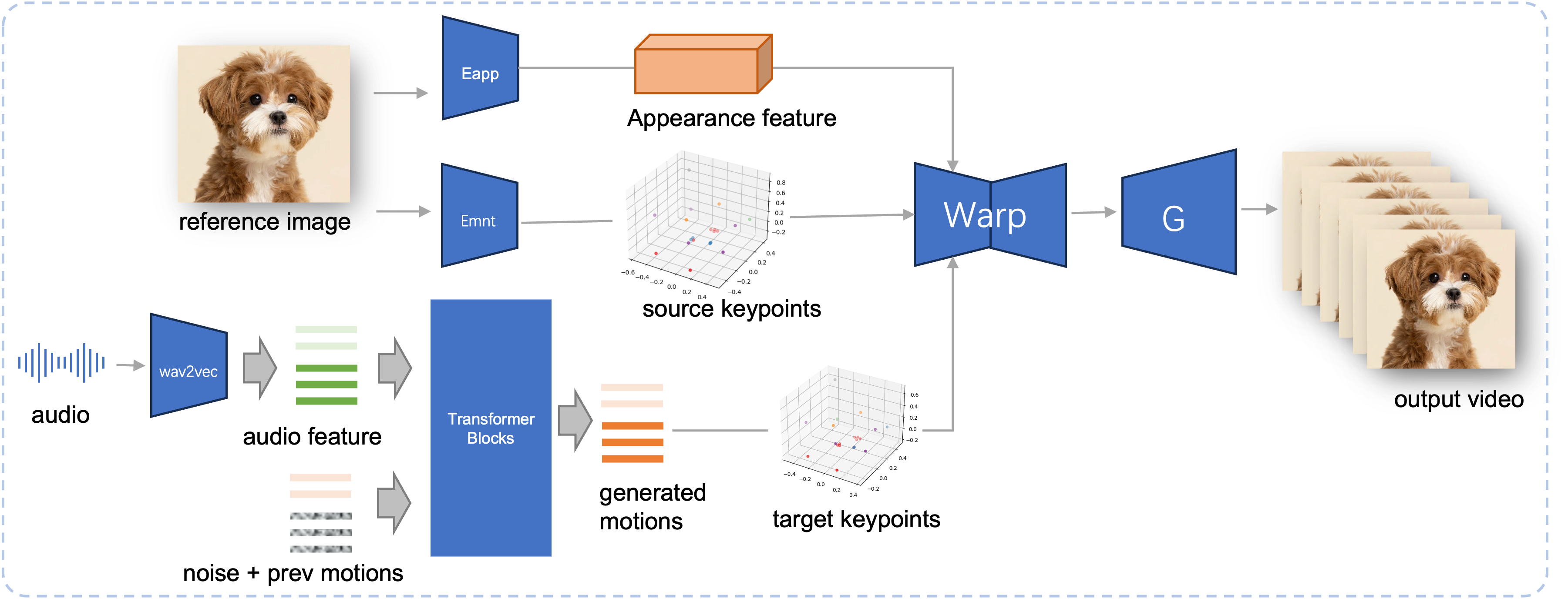
제안된 JoyVASA의 추론 파이프라인. 참조 이미지가 주어지면 먼저 LivePortrait의 모양 인코더를 사용하여 3D 얼굴 모양 특징을 추출하고 모션 인코더를 사용하여 학습된 일련의 3D 키포인트도 추출합니다. 입력 음성의 경우 오디오 특징은 처음에 wav2vec2 인코더를 사용하여 추출됩니다. 그런 다음 오디오 구동 모션 시퀀스는 슬라이딩 윈도우 방식의 두 번째 단계에서 훈련된 확산 모델을 사용하여 샘플링됩니다. 참조 이미지의 3D 키포인트와 샘플링된 목표 모션 시퀀스를 사용하여 목표 키포인트가 계산됩니다. 마지막으로 3D 얼굴 모양 기능은 소스 및 대상 키포인트를 기반으로 워핑되고 생성기에 의해 렌더링되어 최종 출력 비디오를 생성합니다.
시스템 요구 사항:
우분투:
Ubuntu 20.04, Cuda 11.3에서 테스트되었습니다.
테스트된 GPU: A100
윈도우:
Windows 11, CUDA 12.1에서 테스트되었습니다.
테스트된 GPU: RTX 4060 노트북 8GB VRAM GPU
환경 만들기:
# 1. 기본 환경 생성conda create -n Joyvasa python=3.10 -y 콘다 활성화 조이바사 # 2. 요구 사항 설치pip install -r 요구 사항.txt# 3. ffmpegsudo apt-get update 설치 sudo apt-get install ffmpeg -y# 4. MultiScaleDeformableAttentioncd src/utils/dependent/XPose/models/UniPose/ops 설치 python setup.py build installcd - # cd ../../../../../../../와 같습니다.
git-lfs가 설치되어 있는지 확인하고 pretrained_weights 에 다음 체크포인트를 모두 다운로드하세요.
자식 lfs 설치 자식 클론 https://huggingface.co/jdh-algo/JoyVASA
우리는 wav2vec2-base와 Hubert-chinese를 포함한 두 가지 유형의 오디오 인코더를 지원합니다.
Hubert-chinese 사전 훈련된 가중치를 다운로드하려면 다음 명령을 실행하십시오.
자식 lfs 설치 자식 클론 https://huggingface.co/TencentGameMate/chinese-hubert-base
wav2vec2-base 사전 훈련된 가중치를 얻으려면 다음 명령을 실행하십시오.
자식 lfs 설치 자식 클론 https://huggingface.co/facebook/wav2vec2-base-960h
메모
wav2vec2 인코더를 사용한 모션 생성 모델은 나중에 지원될 예정입니다.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
더 많은 다운로드 방법은 Liveportrait를 참조하세요.
pretrained_weights 내용 최종 pretrained_weights 디렉터리는 다음과 같아야 합니다.
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.json메모
Windows의 TencentGameMate:chinese-hubert-base 폴더 이름을 chinese-hubert-base 로 바꿔야 합니다.
동물:
python inference.py -r 자산/예제/imgs/joyvasa_001.png -a 자산/예제/audios/joyvasa_001.wav --animation_mode 동물 --cfg_scale 2.0
인간:
python inference.py -r 자산/예제/imgs/joyvasa_003.png -a 자산/예제/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
cfg_scale을 변경하여 다양한 표정과 포즈로 결과를 얻을 수 있습니다.
메모
애니메이션 모드와 참조 이미지가 일치하지 않으면 잘못된 결과가 발생할 수 있습니다.
웹 데모를 시작하려면 다음 명령을 사용하십시오.
파이썬 app.py
데모는 http://127.0.0.1:7862에서 생성됩니다.
우리의 작업이 도움이 되었다고 생각하시면 우리를 인용해 보십시오:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet 및 VBench 리포지토리의 공개 연구와 뛰어난 작업에 기여해 주신 분들께 감사의 말씀을 전하고 싶습니다.


