wikisearch
1.0.0
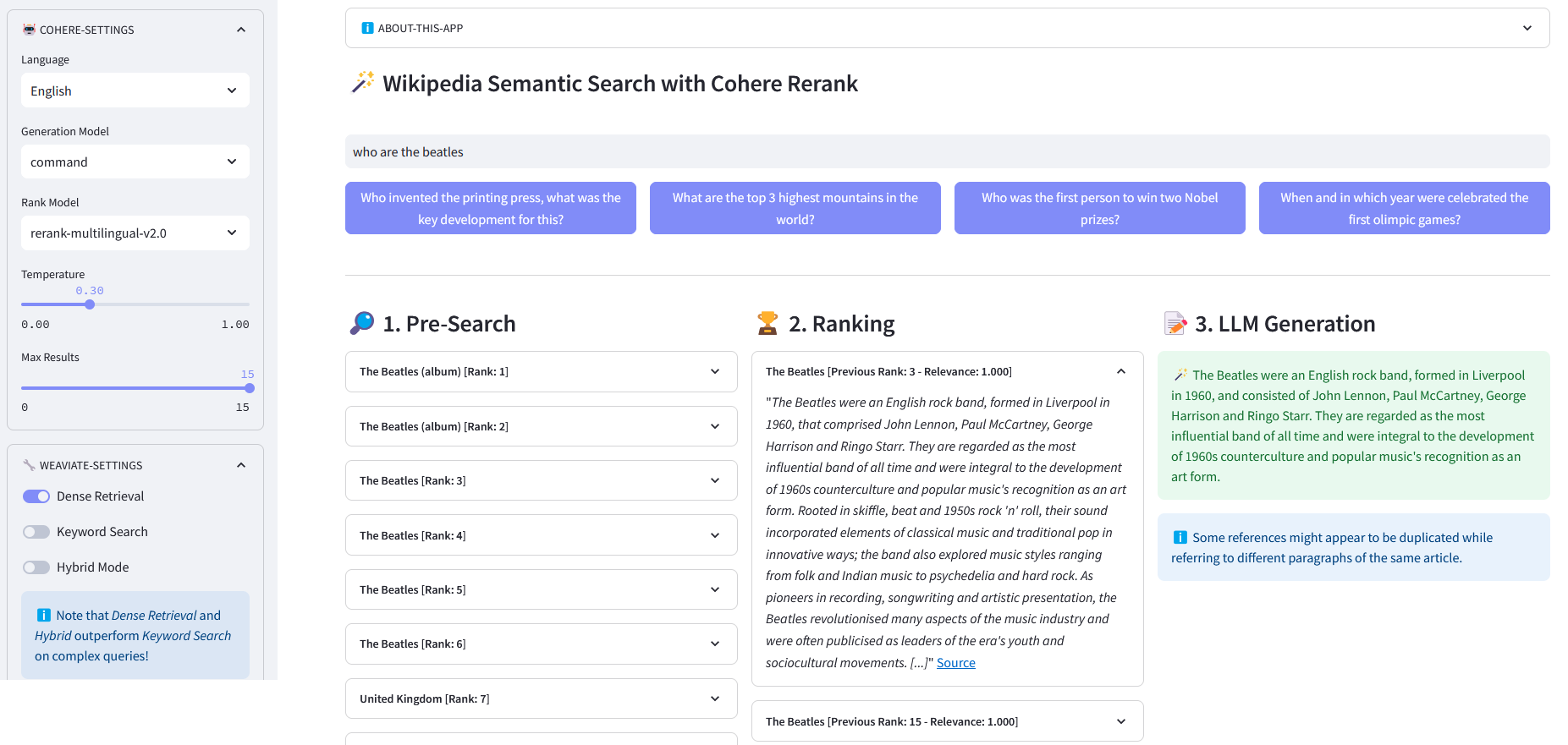
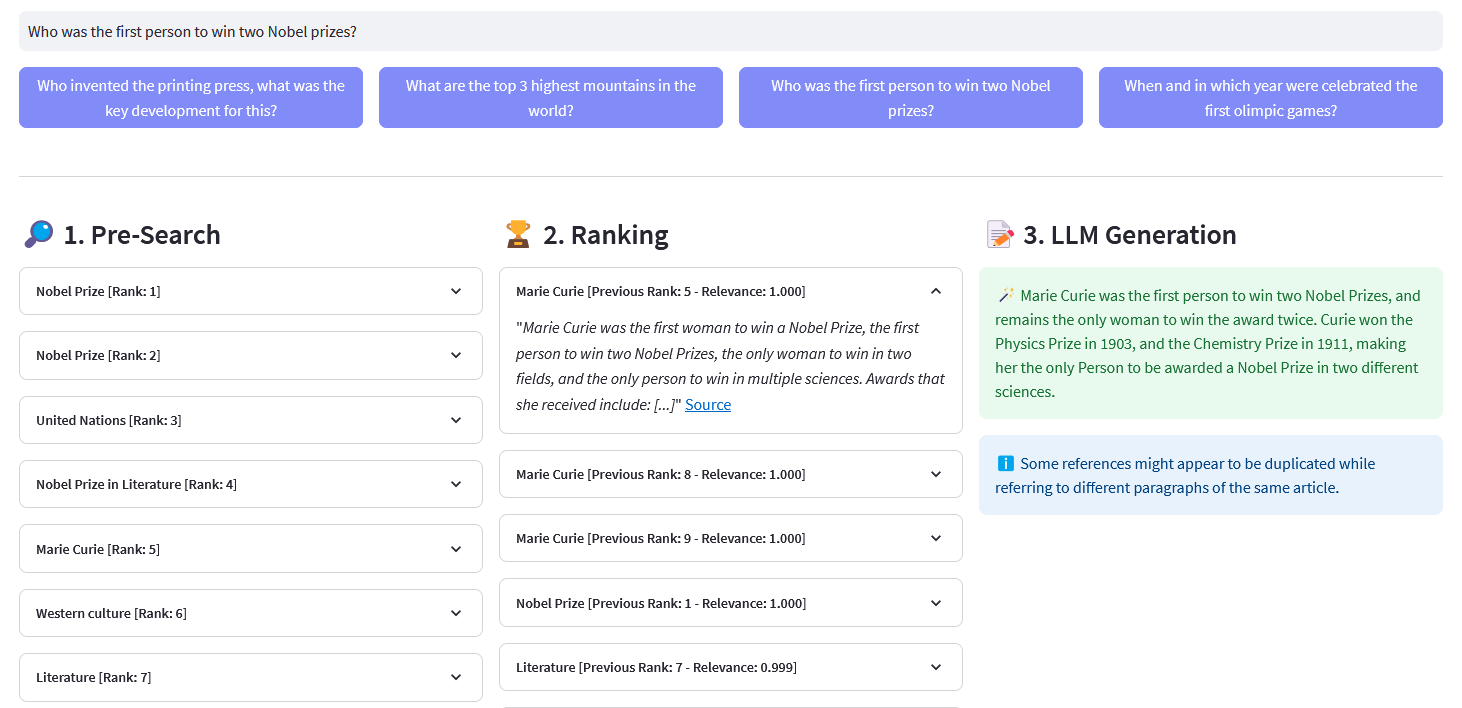
Weaviate가 임베딩으로 벡터화한 천만 개 이상의 Wikipedia 문서에 대한 다국어 의미 검색을 위한 Streamlit 앱입니다. 이 구현은 Cohere의 블로그 'Using LLMs for Search'와 해당 노트북을 기반으로 합니다. Wikipedia 데이터 세트를 쿼리하기 위해 키워드 검색 , 밀집 검색 및 하이브리드 검색 의 성능을 비교할 수 있습니다. 또한 Cohere Rerank를 사용하여 결과의 정확성을 향상시키고 Cohere Generate를 사용하여 순위가 매겨진 결과를 기반으로 응답을 제공하는 방법을 보여줍니다.
의미 검색은 키워드 일치에만 초점을 맞추는 것이 아니라 결과를 생성할 때 검색 문구의 의도와 문맥적 의미를 고려하는 검색 알고리즘을 말합니다. 쿼리 이면의 의미를 이해하여 보다 정확하고 관련성이 높은 결과를 제공합니다.
임베딩은 단어, 문장, 문서, 이미지 또는 오디오와 같은 데이터를 나타내는 부동 소수점 숫자의 벡터(목록)입니다. 상기 수치 표현은 데이터의 맥락, 계층 구조 및 유사성을 포착합니다. 분류, 클러스터링, 이상치 감지 및 의미 검색과 같은 다운스트림 작업에 사용할 수 있습니다.
Weaviate와 같은 벡터 데이터베이스는 임베딩을 위한 저장 및 쿼리 기능을 최적화하기 위해 특별히 구축되었습니다. 실제로 벡터 데이터베이스는 ANN(Approximate Nearest Neighbor) 검색에 모두 참여하는 다양한 알고리즘의 조합을 사용합니다. 이러한 알고리즘은 해싱, 양자화 또는 그래프 기반 검색을 통해 검색을 최적화합니다.
사전 검색 : 키워드 일치 , 밀집 검색 또는 하이브리드 검색을 사용하여 Wikipedia 임베딩에 대한 사전 검색:
키워드 일치: 속성에 검색어가 포함된 개체를 찾습니다. 결과는 BM25F 기능에 따라 점수가 매겨집니다.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" 키워드를 수행합니다. Weaviate에 저장된 임베딩을 사용하는 Wikipedia 기사의 검색(희소 검색) 매개변수: - 쿼리(str): 검색 쿼리입니다. (str, 선택 사항): 기사의 언어 기본값은 'en'입니다. - top_n (int, 선택 사항): 반환할 상위 결과 수: - 목록: BM25F를 기반으로 한 상위 기사 목록입니다. 점수 매기기."""logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("기사", self.WIKIPEDIA_PROPERTIES)
.with_bm25(쿼리=쿼리)
.with_where(어디_필터)
.with_limit(top_n)
.하다()
)응답 반환["data"]["Get"]["Articles"]밀도 검색: 원시(벡터화되지 않은) 텍스트와 가장 유사한 개체를 찾습니다.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" 의미 체계를 수행합니다. Weaviate에 저장된 임베딩을 사용하는 Wikipedia 기사의 검색(밀도 검색) 매개변수: - query(str): 검색어 - lang. (str, 선택 사항): 기사의 언어 기본값은 'en'입니다. - top_n (int, 선택 사항): 반환할 상위 결과 수입니다. 반환: - 목록: 의미에 따른 상위 기사 목록입니다. 유사성. """logging.info("with_neartext()")nearText = {"concepts": [쿼리]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(어디_필터)
.with_limit(top_n)
.하다()
)응답 반환['data']['Get']['Articles']하이브리드 검색: 키워드(bm25) 검색과 벡터 검색 결과의 가중치 조합을 기반으로 결과를 생성합니다.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" 하이브리드 수행 Weaviate에 저장된 임베딩을 사용하여 Wikipedia 기사를 검색합니다. 매개변수: - query(str): 검색 쿼리입니다. - lang(str, 선택사항): 언어입니다. 기본값은 'en'입니다. - top_n(int, 선택 사항): 반환할 상위 결과 수입니다. 기본값은 10입니다. 반환: - list: 하이브리드 점수를 기준으로 한 상위 기사 목록입니다. with_hybrid()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("기사", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(쿼리=쿼리)
.with_where(어디_필터)
.with_limit(top_n)
.하다()
)응답 반환["data"]["Get"]["Articles"]ReRank : Cohere Rerank는 사용자가 검색한 각 사전 검색 결과에 관련성 점수를 할당하여 사전 검색을 재구성합니다. 임베딩 기반 의미 검색에 비해 특히 복잡하고 도메인별 쿼리에 대해 더 나은 검색 결과를 제공합니다.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query, document, top_n=10, model='rerank-english-v2.0') -> dict:""" Cohere의 reranking API를 사용하여 응답 목록의 순위를 다시 매깁니다. 매개변수: - query (str): 검색 쿼리 - document(list): 문서 목록 - top_n (int, 선택 사항): 반환할 상위 순위 지정 결과 수. 기본값은 10입니다. - model: 순위 지정에 사용할 모델입니다. 반환값: - dict: Cohere API에서 문서 순위를 다시 매겼습니다. """return self.cohere.rerank(query=query, document=documents, top_n=top_n, model=model)
출처: 코히어
답변 생성 : Cohere 생성은 순위가 매겨진 결과를 기반으로 응답을 구성합니다.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, 온도=0.2, model="command", lang="english") -> list:prompt = f""" 아래에 제공된 정보를 사용하여 마지막 질문에 답하십시오. / 문맥에서 추출된 몇 가지 궁금하거나 관련 있는 사실을 포함하십시오. / 해당 언어로 답변을 생성하십시오. 쿼리의 언어를 확인할 수 없는 경우 {lang}을 사용합니다. / 질문에 대한 답변이 제공된 정보에 포함되어 있지 않으면 "대답이 문맥에 없습니다"를 생성합니다. } --- 질문: {쿼리} """return self.cohere.generate(prompt=prompt,num_세대=1,max_tokens=1000,온도=온도,모델=모델,
)저장소를 복제합니다.
[email protected]:dcarpintero/wikisearch.git
가상 환경 생성 및 활성화:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
종속성을 설치합니다.
pip install -r requirements.txt
웹 애플리케이션 실행
streamlit run ./app.py
Streamlit Cloud에 배포되고 https://wikisearch.streamlit.app/에서 사용 가능한 데모 웹 앱
Cohere 순위 재지정
스트림라이트 클라우드
임베딩 아카이브: 다양한 언어로 된 수백만 개의 Wikipedia 기사 임베딩
밀집 검색 및 순위 재지정을 통해 검색에 LLM 사용
벡터 데이터베이스
Weaviate 벡터 검색
Weaviate BM25 검색
Weaviate 하이브리드 검색


