EasyDetect
1.0.0

MLLM을 위한 사용하기 쉬운 다중 모드 환각 감지 프레임워크
승인 • 벤치마크 • 데모 • 개요 • ModelZoo • 설치 • 빠른 시작 • 인용
승인
개요
통합 다중 모드 환각
데이터세트: MHaluBench 통계
프레임워크: UniHD 일러스트레이션
모델동물원
설치
⏩빠른 시작
소환
2024-05-17 다중 모드 대형 언어 모델에 대한 통합 환각 감지 논문이 ACL 2024 메인 컨퍼런스에서 승인되었습니다.
2024-04-21 데모의 모든 기본 모델을 자체 훈련된 모델로 대체하여 추론 시간을 크게 줄입니다.
2024-04-21 허깅페이스(huggingface), 모델스코프(modelscope), 와이즈모델(wisemodel)에서 다운로드할 수 있는 오픈소스 환각 탐지 모델 HalDet-LLAVA를 출시합니다.
2024-02-10 EasyDetect 데모를 출시합니다 .
2024-02-05 새로운 벤치마크 MHaluBench를 사용하여 "다중 모드 대형 언어 모델에 대한 통합 환각 감지"라는 논문을 발표합니다! 우리는 이 주제에 대한 어떤 의견이나 토론도 기대하고 있습니다 :)
2023-10-20 EasyDetect 프로젝트가 출시되어 개발 중입니다.
이 프로젝트의 일부 구현은 FactTool, Woodpecker 등을 포함한 관련 환각 툴킷의 도움과 영감을 받았습니다. 이 저장소는 mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO 및 MAERec의 공개 프로젝트의 이점도 제공합니다. 우리는 오픈 소스에 대해서도 동일한 라이센스를 따르며 커뮤니티에 대한 기여에 감사드립니다.
EasyDetect는 연구 실험에서 GPT-4V, Gemini, LlaVA와 같은 다중 모드 대형 언어 모델(MLLM)을 위한 사용하기 쉬운 환각 감지 프레임워크로 제안된 체계적인 패키지입니다.
통합 탐지를 위한 전제 조건은 MLLM 내 환각의 주요 범주를 일관되게 분류하는 것입니다. 우리 논문은 통일된 관점에서 다음과 같은 환각 분류를 피상적으로 조사합니다.


그림 1: 통합 다중 모드 환각 감지는 객체, 속성, 장면-텍스트 등 다양한 수준에서 양상이 충돌하는 환각과 이미지-텍스트 및 텍스트-이미지 모두에서 사실 상충 환각을 식별하고 감지하는 것을 목표로 합니다. 세대.
양식 충돌 환각. MLLM은 때때로 다른 양식의 입력과 충돌하는 출력을 생성하여 잘못된 개체, 속성 또는 장면 텍스트와 같은 문제를 야기합니다. 위 그림 (a)의 예에는 운동 선수의 유니폼을 부정확하게 설명하는 MLLM이 포함되어 있으며 MLLM의 세밀한 텍스트-이미지 정렬 능력 제한으로 인해 속성 수준 충돌이 발생함을 보여줍니다.
사실 상충되는 환각. MLLM의 결과는 확립된 사실 지식과 모순될 수 있습니다. 이미지-텍스트 모델은 관련 없는 사실을 통합하여 실제 콘텐츠에서 벗어나는 내러티브를 생성할 수 있는 반면, 텍스트-이미지 모델은 텍스트 프롬프트에 포함된 사실 지식을 반영하지 못하는 시각적 자료를 생성할 수 있습니다. 이러한 불일치는 사실적 일관성을 유지하기 위한 MLLM의 노력을 강조하며, 이는 해당 영역에서 중요한 과제를 나타냅니다.
다중 모드 환각의 통합 감지에는 각 이미지-텍스트 쌍 a={v, x} 의 확인이 필요합니다. 여기서 v MLLM에 제공된 시각적 입력 또는 MLLM에 의해 합성된 시각적 출력을 나타냅니다. 이에 따라 x v 또는 v 합성을 위한 텍스트 사용자 쿼리를 기반으로 MLLM이 생성한 텍스트 응답을 나타냅니다. 이 작업 내에서 각 x 에는 다음과 같이 표시되는 여러 클레임이 포함될 수 있습니다. a 의 각 주장을 평가하여 "환각"인지 "환각이 아닌"지 결정하고, 제공된 환각 정의를 기반으로 판단에 대한 근거를 제공하는 것입니다. LLM의 텍스트 환각 감지는 이 설정의 하위 사례를 나타냅니다. 여기서 v null입니다.
이 연구 궤적을 발전시키기 위해 우리는 다중 모드 환각 탐지기의 발전을 엄격하게 평가하는 것을 목표로 이미지에서 텍스트로, 텍스트에서 이미지로 생성하는 콘텐츠를 포함하는 메타 평가 벤치마크 MHaluBench를 소개합니다. MHaluBench에 대한 추가 통계 세부 정보는 아래 그림에 나와 있습니다.
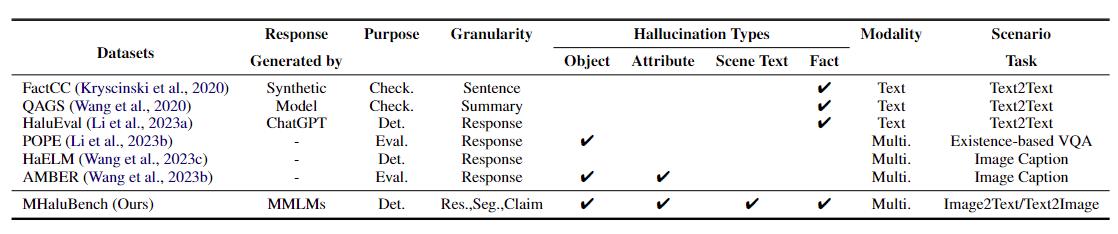
표 1: 기존 사실 확인 또는 환각 평가에 대한 벤치마크 비교. "확인하다." 사실적 일관성을 확인하는 "Eval"을 나타냅니다. 는 다양한 LLM에서 생성된 환각 평가를 나타내며 해당 응답은 테스트 중인 다양한 LLM을 기반으로 하며 "Det." 환각을 식별하는 탐지기의 능력에 대한 평가를 구체화합니다.
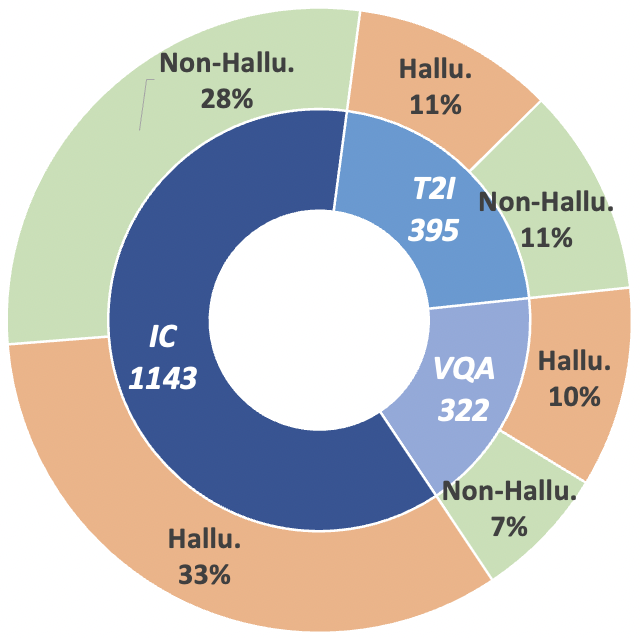
그림 2: MHaluBench의 클레임 수준 데이터 통계. "IC"는 이미지 캡션을 나타내고 "T2I"는 각각 텍스트-이미지 합성을 나타냅니다.
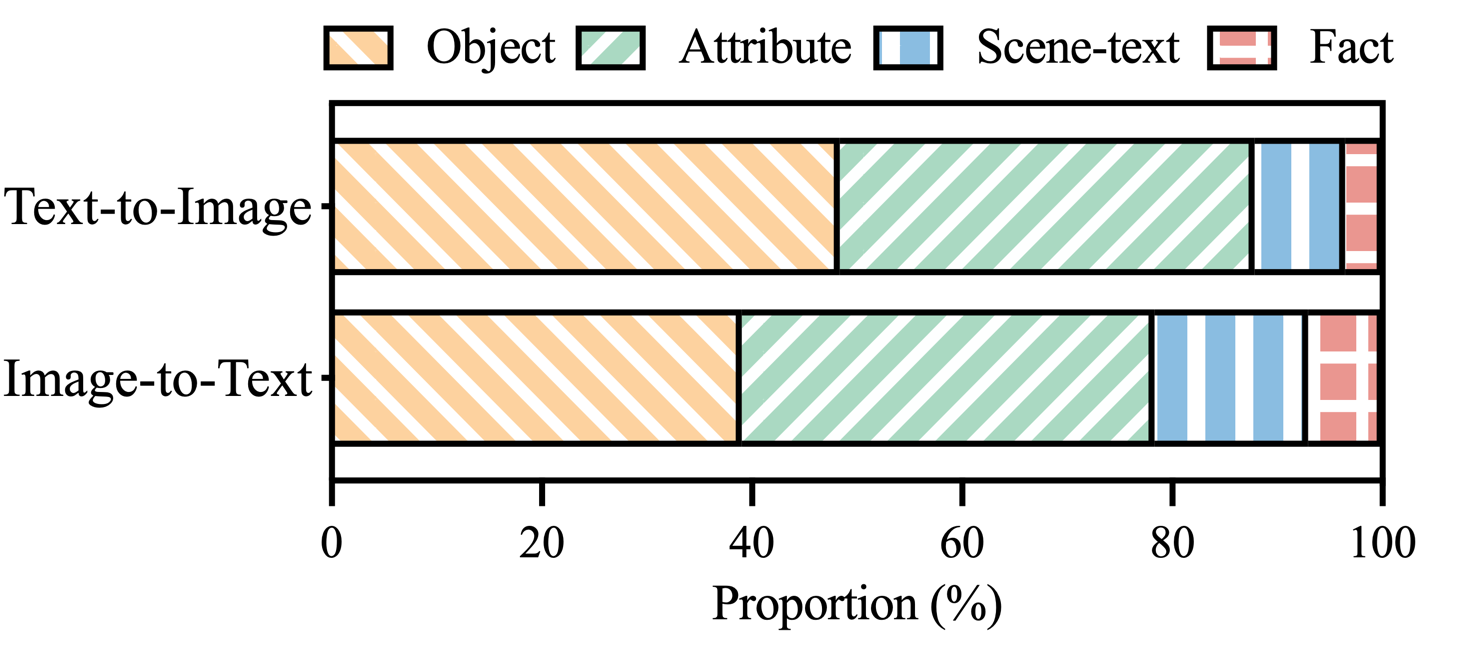
그림 3: MHaluBench의 환각 라벨이 붙은 주장 내 환각 카테고리 분포.
환각 감지의 주요 과제를 해결하기 위해 이미지-텍스트 및 텍스트-이미지 작업 모두에 대한 다중 모드 환각 식별을 체계적으로 다루는 통합 프레임워크를 그림 4에 소개합니다. 우리의 프레임워크는 환각 확인을 위한 다양한 증거를 효율적으로 수집하기 위해 다양한 도구의 영역별 강점을 활용합니다.
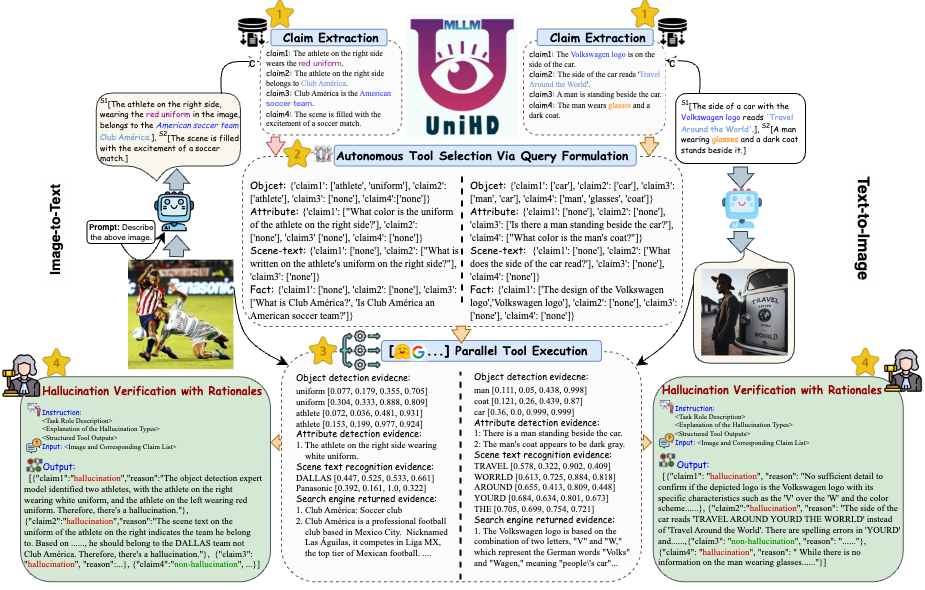
그림 4: 통합 다중 모드 환각 감지를 위한 UniHD의 구체적인 그림.
HuggingFace, ModelScope 및 WiseModel의 세 가지 플랫폼에서 HalDet-LLaVA의 두 가지 버전인 7b 및 13b를 다운로드할 수 있습니다.
| 포옹얼굴 | 모델범위 | 현명한 모델 |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
검증 데이터 세트에 대한 클레임 수준 결과
자가진단(GPT-4V)은 0~2건의 경우 GPT-4V를 사용한다는 의미입니다.
UniHD(GPT-4V/GPT-4o)는 2샷 및 도구 정보와 함께 GPT-4V/GPT-4o를 사용한다는 의미입니다.
HalDet(LLAVA)는 기차 데이터 세트에서 훈련된 LLAVA-v1.5를 사용한다는 의미입니다.
| 작업 유형 | 모델 | Acc | 예측 평균 | 평균 회상 | 맥.F1 |
| 이미지를 텍스트로 | 자가진단 0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| 자가진단 2샷(GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| HalDet (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| 유니HD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| 유니HD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| 텍스트를 이미지로 | 자가진단 0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| 자가진단 2샷(GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| HalDet (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| HalDet (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| 유니HD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| 유니HD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
HalDet-LLaVA 및 열차 데이터세트에 대한 자세한 정보를 보려면 추가 정보를 참조하세요.
로컬 개발을 위한 설치:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
도구 설치(GroundingDINO 및 MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
사용자가 EasyDetect를 빠르게 시작할 수 있도록 예제 코드를 제공합니다.
사용자는 yaml 파일에서 EasyDetect 매개변수를 쉽게 구성하거나 우리가 제공하는 구성 파일에서 기본 매개변수를 빠르게 사용할 수 있습니다. 구성 파일의 경로는 EasyDetect/pipeline/config/config.yaml입니다.
openai: api_key: openai API 키를 입력하세요.
base_url: base_url을 입력합니다. 기본값은 None입니다.
온도: 0.2
max_tokens: 1024도구:
감지:groundingdino_config: GroundingDINO_SwinT_OGC.pymodel_path 경로: groundingdino_swint_ogc.pth 장치 경로: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: dbnetpp.pthmaerec_config의 경로: maerec_b_union14m.pymaerec_path의 경로: maerec_b.pthdevice의 경로: cuda:0content: word.numbercachefiles_path: 임시 이미지를 저장할 캐시 파일 경로BOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: Serper API를 입력하세요.keynippet_cnt: 10prompts:claim_generate:pipeline/prompts/claim_generate.yaml
query_generate: 파이프라인/프롬프트/query_generate.yaml
확인: 파이프라인/프롬프트/verify.yaml예제 코드
frompipeline.run_pipeline import *pipeline = Pipeline()text = "이미지의 카페 이름은 "Hauptbahnhof"입니다."image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response,claim_list = 파이프라인 .run(텍스트=텍스트, image_path=이미지_경로, 유형=유형)인쇄(응답)인쇄(claim_list)
작업에 EasyDetect를 사용하는 경우 저장소를 인용해 주세요.
@article{chen23factchd, 저자 = {Xiang Chen 및 Duanzheng Song 및 Honghao Gui 및 Chengxi Wang 및 Ningyu Zhang 및 Jiang Yong 및 Fei Huang 및 Chengfei Lv 및 Dan Zhang 및 Huajun Chen}, 제목 = {FactCHD: 사실과 충돌하는 환각 감지 벤치마킹 }, 저널 = {CoRR}, 볼륨 = {abs/2310.12086}, 연도 = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {dblp 컴퓨터 과학 참고문헌, https://dblp.org}}@inproceedings{chen-etal-2024- Unified-hallucination,title = "다중 모드 대형 언어 모델에 대한 통합 환각 감지",author = "Chen, Xiang 및 Wang, Chenxi 및 Xue, Yida 및 Zhang, Ningyu 및 Yang, Xiaoyan 및 Li, Qiang 및 Shen, Yue 및 Liang, Lei 및 Gu, Jinjie 및 Chen, Huajun",편집자 = "Ku, Lun-Wei 및 Martins, Andre 및 Srikumar, Vivek" ,booktitle = "전산언어학회 제62차 연차총회 회의록(1권: 장편) 논문)",월 = 8월,연도 = "2024",address = "태국 방콕",publisher = "전산 언어학 협회",url = "https://aclanthology.org/2024.acl-long.178" ,페이지 = "3235--3252",
}버그 수정, 문제 해결, 새로운 요청 충족을 위해 장기 유지 관리를 제공할 예정입니다. 따라서 문제가 있으면 우리에게 문제를 제기하십시오.


