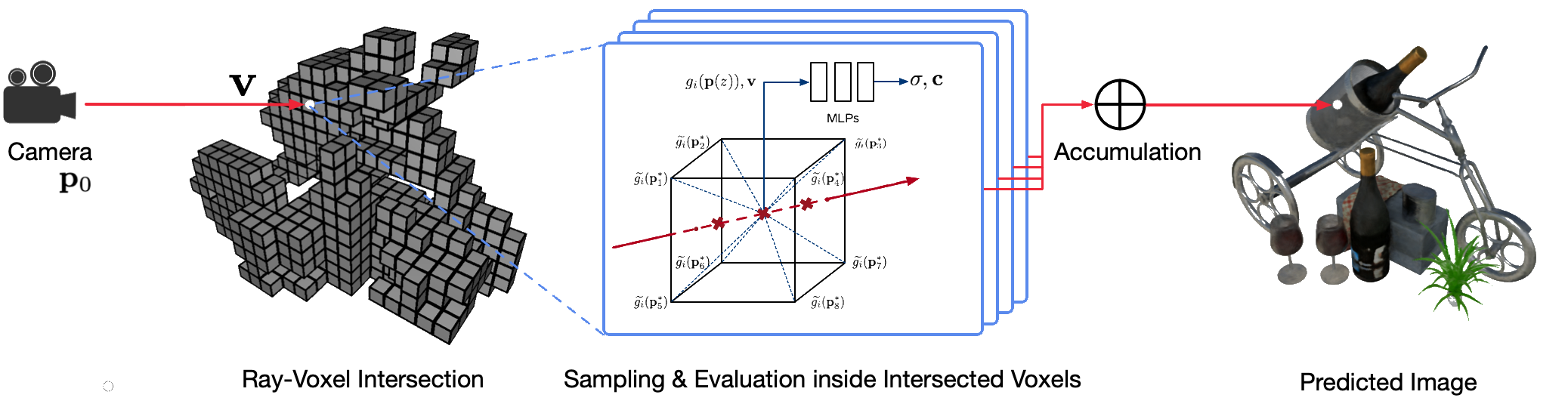
고전적인 컴퓨터 그래픽 기술을 사용하여 실제 장면을 사진처럼 사실적으로 자유 시점으로 렌더링하는 것은 어려운 문제입니다. 왜냐하면 세부적인 외관과 기하학적 모델을 캡처하는 어려운 단계가 필요하기 때문입니다. 신경 렌더링은 심층 신경망을 사용하여 거친 기하학이 있거나 없는 2D 관측으로부터 기하학과 모양을 모두 캡슐화하는 장면 표현을 암시적으로 학습하는 새로운 분야입니다. 그러나 이 분야의 기존 접근 방식은 렌더링이 흐릿하거나 렌더링 프로세스가 느려지는 경우가 많습니다. 우리는 빠르고 고품질의 자유 시점 렌더링을 위한 새로운 신경 장면 표현인 NSVF(Neural Sparse Voxel Fields)를 제안합니다.
다음은 해당 논문의 공식 저장소입니다.
우리는 또한 다음에 대한 비공식 구현을 제공합니다.
이 코드는 fairseq 프레임워크를 사용하여 PyTorch에서 구현됩니다.
코드는 다음 시스템에서 테스트되었습니다.
GPU에서의 학습 및 렌더링만 지원됩니다.
설치하려면 먼저 이 저장소를 복제하고 모든 종속성을 설치하십시오.
pip install -r requirements.txt그런 다음 실행
pip install --editable ./또는 코드를 로컬로 설치하려면 다음을 실행하세요.
python setup.py build_ext --inplace우리 논문에 사용된 전처리된 합성 및 실제 데이터 세트를 다운로드할 수 있습니다. 또한 업무에 원본 논문을 사용하는 경우 원본 논문을 인용해 주세요.
| 데이터세트 | 다운로드 링크 | 데이터 세트 분할에 관한 참고 사항 |
|---|---|---|
| 합성-NSVF | 다운로드(.zip) | 0_*(훈련) 1_*(검증) 2_*(테스트) |
| 합성-NeRF | 다운로드(.zip) | 0_*(훈련) 1_*(검증) 2_*(테스트) |
| 혼합MVS | 다운로드(.zip) | 0_*(훈련) 1_*(테스트) |
| 탱크&사원 | 다운로드(.zip) | 0_*(훈련) 1_*(테스트) |
학습 및 테스트를 위해 단일 장면의 새 데이터 세트를 준비하려면 데이터 구조를 따르십시오.
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) 여기서 bbox.txt 파일에는 초기 경계 상자와 복셀 크기를 설명하는 줄이 포함되어 있습니다.
x_min y_min z_min x_max y_max z_max initial_voxel_size 대상 이미지의 파일 이름과 해당 카메라 포즈 파일의 이름이 완전히 동일할 필요는 없습니다. 단, 두 종류의 파일 순서(문자열 기준)가 일치해야 합니다. 데이터세트는 뷰 인덱스로 분할됩니다. 예를 들어 " train (0..100) , valid (100..200) 및 test (200..400) "은 훈련용 처음 100개 보기, 검증용 100~199번째 보기, 테스트용 200~399번째 보기를 의미합니다. .
단일 장면의 데이터 세트( {DATASET} )가 주어지면 NSVF 모델을 훈련하기 위해 다음 명령을 사용하여 GPU당 4 이미지와 이미지당 2048 광선의 배치 크기로 800x800 픽셀의 새로운 뷰를 합성합니다. 기본적으로 코드는 사용 가능한 모든 GPU를 자동으로 감지합니다.
다음 예에서는 특정 인수와 함께 사전 정의된 아키텍처 nsvf_base 를 사용합니다.
--no-sampling-at-reader 설정하면 모델은 훈련을 위해 희소 복셀의 투영된 이미지 영역에 있는 픽셀만 샘플링합니다.bbox.txt 파일에 설명된 복셀 크기의 1/8 (0.125) 비율로 설정합니다.--use-octree 활성화하는 것은 선택 사항입니다. 특히 복셀 수가 10000 보다 큰 경우 광선-복셀 교차 속도를 높이기 위해 희소 복셀 옥트리를 구축합니다.--pruning-every-steps 2500 으로 설정하면 모델은 2500 단계마다 자체 정리를 수행합니다.--half-voxel-size-at 및 --reduce-step-size-at 5000,25000,75000 으로 설정하면 복셀 크기와 단계 크기가 각각 5k , 25k 및 75k 로 절반으로 줄어듭니다.비록 위의 매개변수 설정이 논문의 대부분의 실험에 사용되었지만 더 나은 품질을 달성하기 위해 이러한 매개변수를 조정하는 것이 가능합니다. 위의 매개변수 외에 다른 매개변수도 기본 설정을 사용할 수 있습니다.
nsvf_base 아키텍처 외에도 fairnr/models/nsvf.py 파일에서 다른 아키텍처를 확인하거나 자체 아키텍처를 정의할 수 있습니다.
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log 체크포인트는 {SAVE} 에 저장됩니다. 훈련 진행 상황을 확인하기 위해 텐서보드를 시작할 수 있습니다:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000예제 아래에 논문의 결과를 재현하기 위한 훈련 스크립트의 더 많은 예제가 있습니다.
모델이 훈련되면 다음 명령을 사용하여 {MODEL_PATH} 가 지정된 테스트 보기에서 렌더링 품질을 평가합니다.
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' 렌더링 속도 향상을 위해 조기 종료를 활성화하려면 raymarching_tolerance 0.01 로 재정의합니다.
모델이 훈련되고 렌더링 궤적이 지정되면 자유 시점 렌더링을 달성할 수 있습니다. 예를 들어 다음 명령은 원 궤적(각속도 3도/프레임, GPU당 15프레임)을 사용하여 렌더링하기 위한 것입니다. 이는 뷰별로 렌더링된 이미지를 출력하고 다음과 같이 이미지를 ${SAVE}/output 에서 .mp4 비디오로 병합합니다.

기본적으로 코드는 사용 가능한 모든 GPU를 감지할 수 있습니다.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " 우리 코드는 주어진 카메라 포즈에 대한 렌더링도 지원합니다. 예를 들어 다음 명령은 ${DATASET}/pose 폴더 아래 200~399번째 파일에 정의된 카메라 포즈로 렌더링하기 위한 것입니다.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " 코드는 .txt 파일에 정의된 카메라 포즈를 사용한 렌더링도 지원합니다. 이 예를 참조하십시오.
또한 훈련된 NSVF 모델에서 등위면을 삼각형 메쉬로 추출하고 {SAVE}/{NAME}.ply 로 저장하기 위해 행진 큐브 실행을 지원합니다.
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 --format 'voxel_mesh' 설정하여 학습된 희소 복셀을 내보낼 수도 있습니다. 출력 .ply 파일은 MeshLab과 같은 3D 뷰어로 열 수 있습니다.

NSVF는 MIT 라이센스를 받았습니다. 라이선스는 사전 훈련된 모델에도 적용됩니다.
다음과 같이 인용해주세요.
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

