test arranger
v1.6.3
TDD에는 배열, 실행, 주장(주어진 경우, BDD의 경우)이라는 3단계가 있습니다. Assert 단계에는 뛰어난 도구 지원이 있으므로 AssertJ, FEST-Assert 또는 Hamcrest에 익숙할 수 있습니다. 이는 정렬 단계와 대조됩니다. 테스트 데이터를 정렬하는 것은 종종 어렵고 테스트의 상당 부분이 일반적으로 이에 전념하지만 이를 지원하는 도구를 지적하기는 어렵습니다.
테스트 배열자는 테스트에 필요한 클래스의 인스턴스를 배열하여 이러한 격차를 해소하려고 합니다. 인스턴스는 테스트 데이터 생성 프로세스를 단순화하는 의사 난수 값으로 채워집니다. 테스터는 필요한 객체의 유형만 선언하고 새로운 인스턴스를 얻습니다. 특정 필드의 의사 난수 값이 충분하지 않은 경우 이 필드만 수동으로 설정해야 합니다.
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' 배열자 클래스에는 단순 유형의 의사 난수 값을 생성하기 위한 여러 가지 정적 메서드가 있습니다. 각각에는 Kotlin 호출을 더 간단하게 만드는 래핑 기능이 있습니다. 가능한 통화 중 일부는 다음과 같습니다.
| 자바 | 코틀린 | 결과 |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | 모든 필드가 값으로 채워진 Product 인스턴스 |
Arranger.some(Product.class, "brand") | some<Product>("brand") | 브랜드 필드에 대한 값이 없는 제품 인스턴스 |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | Category의 인스턴스, 컬렉션 유형의 필드 크기는 1로 줄어들고 개체 트리의 깊이는 3으로 제한됩니다. |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | Product 인스턴스의 크기 7 스트림 |
Arranger.someEmail() | someEmail() | 이메일 주소가 포함된 문자열 |
Arranger.someLong() | someLong() | long 유형의 의사 난수 |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | listOfCategories의 항목 양식 |
Arranger.someText() | someText() | Markov Chain에서 생성된 문자열; 기본적으로 이는 매우 간단한 체인이지만 대체 정의를 사용하여 테스트 클래스 경로에 다른 'enMarkovChain' 파일을 배치하여 재구성할 수 있습니다. 여기에서 영어 코퍼스에 대해 훈련된 체인을 찾을 수 있습니다. 파일 형식은 프로젝트 'enMarkovChain' 파일에 포함된 내용을 참조하세요. |
| - | some<Product> {name = "not so random"} | "그렇게 무작위적이지 않음"으로 설정된 name 제외하고 모든 필드가 무작위 값으로 채워진 Product 인스턴스. 이 구문을 사용하여 필요한 만큼 객체의 필드를 설정할 수 있지만 각 객체는 변경 가능해야 합니다. |
완전히 무작위인 데이터는 모든 테스트 사례에 적합하지 않을 수 있습니다. 테스트 목표에 중요하고 특정 값이 필요한 필드가 하나 이상 있는 경우가 많습니다. 정렬된 클래스가 변경 가능하거나 Kotlin 데이터 클래스이거나 변경된 복사본을 생성하는 방법(예: Lombok의 @Builder(toBuilder = true))이 있는 경우 사용 가능한 것을 사용하세요. 다행스럽게도 조정할 수 없는 경우에도 테스트 배열자를 사용할 수 있습니다. Map<String,Supplier> 유형의 매개변수를 허용하는 some() 및 someObjects() 메소드의 전용 버전이 있습니다. 이 맵의 키는 필드 이름을 나타내며 해당 공급업체는 테스트 준비자가 해당 필드에 설정하는 값을 제공합니다. 예:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));기본적으로 필드 유형에 따라 임의의 값이 생성됩니다. 무작위 값이 항상 클래스 불변성과 잘 일치하는 것은 아닙니다. 필드 값과 관련된 일부 규칙과 관련하여 엔터티를 항상 정렬해야 하는 경우 사용자 지정 정렬자를 제공할 수 있습니다.
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
} Product 인스턴스화 프로세스를 제어하려면 instance() 메서드를 재정의해야 합니다. 메서드 내에서 원하는 대로 Product 인스턴스를 만들 수 있습니다. 구체적으로, 우리는 임의의 값을 생성할 수 있습니다. 편의를 위해 CustomArranger 클래스에 enhancedRandom 필드가 있습니다. 주어진 예에서는 모든 필드가 의사 난수 값을 갖는 Product 인스턴스를 생성하지만 가격을 도메인에서 허용되는 가격으로 변경합니다. 이는 음수가 아니며 10k 숫자보다 작습니다.
ProductArranger 는 자동으로(리플렉션을 사용하여) 배열자에 의해 선택되고 Product 의 새 인스턴스가 요청될 때마다 사용됩니다. Arranger.some(Product.class) 와 같은 직접 호출뿐만 아니라 간접적인 호출도 고려합니다. List<Product> 유형의 필드 products 있는 Shop 클래스가 있다고 가정합니다. Arranger.some(Shop.class) 호출할 때, 주선자는 ProductArranger 사용하여 Shop.products 에 저장된 모든 제품을 생성합니다.
테스트 준비자의 동작은 속성을 사용하여 구성할 수 있습니다. arranger.properties 파일을 생성하고 이를 클래스 경로의 루트(일반적으로 src/test/resources/ 디렉터리)에 저장하면 해당 파일이 선택되고 다음 속성이 적용됩니다.
arranger.root 사용자 정의 정렬자는 리플렉션을 사용하여 선택됩니다. CustomArranger 확장하는 모든 클래스는 사용자 정의 정렬자로 간주됩니다. 반영은 기본적으로 com.ocado 인 특정 패키지에 초점을 맞춥니다. 그것이 반드시 당신에게 편리한 것은 아닙니다. 그러나 arranger.root=your_package 사용하면 your_package 로 변경할 수 있습니다. 일반적인 패키지(예: 많은 라이브러리의 루트 패키지인 com )를 사용하면 수백 개의 클래스를 검색하게 되어 눈에 띄는 시간이 걸리므로 패키지를 최대한 구체적으로 만드십시오.arranger.randomseed 기본적으로 기본 의사 난수 값 생성기를 초기화하는 데 항상 동일한 시드가 사용됩니다. 결과적으로 후속 실행에서는 동일한 값이 생성됩니다. 실행 전반에 걸쳐 무작위성을 달성하려면, 즉 항상 다른 무작위 값으로 시작하려면 arranger.randomseed=true 설정해야 합니다.arranger.cache.enable 임의의 인스턴스를 정렬하는 과정에는 약간의 시간이 필요합니다. 많은 수의 인스턴스를 생성하고 완전히 무작위로 생성할 필요가 없다면 캐시를 활성화하는 것이 좋습니다. 활성화되면 캐시는 각 임의 인스턴스에 대한 참조를 저장하고 어느 시점에서 테스트 준비자는 새 인스턴스 생성을 중지하고 대신 캐시된 인스턴스를 재사용합니다. 기본적으로 캐시는 비활성화되어 있습니다.arranger.overridedefaults 테스트 배열자는 기본 필드 초기화를 따릅니다. 즉, 빈 문자열로 초기화된 필드가 있는 경우 테스트 배열자에 의해 반환된 인스턴스는 이 필드에 빈 문자열을 갖습니다. 항상 테스트에 필요한 것은 아니지만, 특히 프로젝트에 빈 값으로 필드를 초기화하는 규칙이 있는 경우에는 더욱 그렇습니다. 다행스럽게도 테스트 준비자가 기본값을 임의의 값으로 덮어쓰도록 강제할 수 있습니다. 기본 초기화를 무시하려면 arranger.overridedefaults true로 설정하세요.arranger.maxRandomizationDepth 일부 테스트 데이터 구조는 서로를 참조하는 임의의 길이의 객체 체인을 생성할 수 있습니다. 그러나 테스트 사례에서 이를 효과적으로 사용하려면 이러한 체인의 길이를 제어하는 것이 중요합니다. 기본적으로 테스트 배열자는 중첩 깊이의 4번째 수준에서 새 개체 생성을 중지합니다. 이 기본 설정이 프로젝트 테스트 사례에 적합하지 않은 경우 이 매개변수를 사용하여 조정할 수 있습니다. 테스트 데이터로 사용할 수 있는 Java 레코드가 있지만 해당 필드 중 하나 또는 두 개를 변경해야 하는 경우 복사 메소드가 있는 Data 클래스가 솔루션을 제공합니다. 이는 필드를 직접 변경할 수 있는 명확한 방법이 없는 불변 레코드를 처리할 때 특히 유용합니다.
Data.copy 메서드를 사용하면 원하는 필드를 선택적으로 수정하면서 레코드의 단순 복사본을 만들 수 있습니다. 필드 재정의 맵을 제공하면 변경해야 하는 필드와 새 값을 지정할 수 있습니다. 복사 메소드는 업데이트된 필드 값으로 레코드의 새 인스턴스를 생성합니다.
이 접근 방식을 사용하면 새 레코드 개체를 수동으로 생성하고 필드를 개별적으로 설정할 필요가 없으므로 기존 레코드와 약간의 변형이 있는 테스트 데이터를 생성하는 편리한 방법을 제공합니다.
전반적으로 Data 클래스와 해당 복사 메서드는 선택한 필드가 변경된 레코드의 얕은 복사본을 생성하여 변경 불가능한 레코드 유형으로 작업할 때 유연성과 편의성을 제공함으로써 상황을 구출합니다.
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));소프트웨어 프로젝트의 테스트를 진행할 때 더 잘할 수 없다는 느낌을 받는 경우는 거의 없습니다. 테스트 데이터 정렬 범위에서 우리가 Test Aligner를 통해 개선하려고 하는 두 가지 영역이 있습니다.
테스트를 만든 사람의 의도, 즉 테스트가 작성된 이유와 테스트에서 감지해야 하는 문제의 종류를 알면 테스트를 훨씬 더 쉽게 이해할 수 있습니다. 불행히도, 정렬(주어진) 섹션에 다음과 같은 명령문이 있는 테스트를 보는 것은 특별한 일이 아닙니다.
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();이러한 코드를 볼 때 어떤 값이 테스트와 관련이 있는지, 그리고 어떤 값이 null이 아닌 일부 요구 사항을 충족하기 위해서만 제공되는지 말하기 어렵습니다. 테스트가 브랜드에 관한 것이라면 다음과 같이 작성해 보는 것은 어떨까요?
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );이제 브랜드가 중요하다는 것은 명백해졌습니다. 한걸음 더 나아가도록 노력해보자. 전체 테스트는 다음과 같습니다.
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) 현재 "일부 브랜드" 브랜드에 대한 보고서가 생성되었으므로 테스트 중입니다. 하지만 그게 목표인가요? 지정된 제품이 할당된 동일한 브랜드에 대해 보고서가 생성될 것으로 예상하는 것이 더 합리적입니다. 그래서 우리가 테스트하고 싶은 것은 다음과 같습니다:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) 브랜드 필드가 변경 가능하고 sut 이를 수정할 수 있다는 우려가 있는 경우, 실행 단계로 들어가기 전에 해당 값을 변수에 저장하고 나중에 어설션에 사용할 수 있습니다. 테스트 기간은 길어지지만 의도는 분명합니다.
방금 수행한 작업은 Gerard Meszaros의 xUnit 테스트 패턴: 리팩토링 테스트 코드 에 설명된 생성된 값 및 생성 방법 패턴을 어느 정도 적용한 것입니다.
프로덕션 코드에서 작은 부분을 변경했는데 수십 번의 테스트에서 오류가 발생한 적이 있습니까? 그 중 일부는 어설션 실패를 보고하고 일부는 컴파일을 거부하기도 합니다. 이것은 당신의 무고한 테스트를 방금 쏜 산탄총 수술 코드 냄새입니다. 글쎄, 작은 변화로 인한 부수적 피해를 제한하기 위해 다르게 설계할 수 있기 때문에 그렇게 순진하지는 않을 수도 있습니다. 예를 들어 분석해 보겠습니다. 우리 도메인에 다음 클래스가 있다고 가정합니다.
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
... 그리고 그것은 많은 곳에서 사용됩니다. 특히 테스트 배열자가 없는 테스트에서는 다음과 같은 문을 사용합니다. new TimeRange(LocalDateTime.now(), 3600_000L); 몇 가지 중요한 이유로 클래스를 다음과 같이 변경해야 한다면 어떻게 될까요?
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
... 모든 종속 테스트를 중단하지 않고 이전 버전을 새 버전으로 변환하는 일련의 리팩토링을 생각해내는 것은 매우 어렵습니다. 테스트가 클래스의 새로운 API에 하나씩 조정되는 시나리오일 가능성이 높습니다. 이는 원하는 기간 값에 관한 많은 질문이 있는 그다지 흥미롭지 않은 작업이 많다는 것을 의미합니다(이를 LocalDateTime 유형의 end 으로 조심스럽게 변환해야 하는지 아니면 단지 편리한 임의 값인지). 테스트 편곡자를 사용하면 인생이 훨씬 쉬워질 것입니다. null이 아닌 TimeRange 필요로 하는 모든 장소에 Arranger.some(TimeRange.class) 있는 경우 이는 이전 버전과 마찬가지로 새 버전의 TimeRange 에도 좋습니다. 이로 인해 임의의 TimeRange 필요하지 않은 몇 가지 사례가 남게 되지만 이미 테스트 배열자를 사용하여 테스트 의도를 밝히므로 각 경우에 TimeRange 에 어떤 값을 사용해야 하는지 정확히 알 수 있습니다.
하지만 이것이 테스트를 개선하기 위해 할 수 있는 전부는 아닙니다. 아마도 TimeRange 인스턴스의 일부 범주(예: 과거 범위, 미래 범위, 현재 활성 범위)를 식별할 수 있을 것입니다. TimeRangeArranger 는 다음을 정렬하는 데 좋은 장소입니다.
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
} 이러한 생성 방법은 미리 생성되어서는 안 되며 기존 테스트 케이스와 일치해야 합니다. 그럼에도 불구하고 TimeRangeArranger 는 테스트를 위해 TimeRange 인스턴스가 생성되는 모든 경우를 다룰 가능성이 있습니다. 결과적으로 여러 가지 신비한 매개 변수를 사용하는 생성자 호출 대신 생성된 개체의 도메인 의미를 설명하고 테스트 의도를 이해하는 데 도움이 되는 잘 알려진 메서드를 사용하는 정렬자를 사용했습니다.
우리는 테스트 배열자가 해결한 과제를 논의할 때 두 가지 수준의 테스트 데이터 작성자를 식별했습니다. 그림을 완성하려면 최소한 하나 이상의 Fixtures를 언급해야 합니다. 이 논의를 위해 Fixture는 테스트 데이터의 복잡한 구조를 생성하도록 설계된 클래스라고 가정할 수 있습니다. 사용자 정의 정렬자는 항상 하나의 클래스에 초점을 맞추지만 때로는 테스트 케이스에서 두 개 이상의 클래스가 반복적으로 발생하는 것을 관찰할 수 있습니다. 이는 사용자와 그의 은행 계좌일 수 있습니다. 각각에 대해 CustomArranger가 있을 수 있지만 종종 함께 사용된다는 사실을 무시할 이유가 없습니다. 이것은 우리가 Fixture에 대해 생각하기 시작해야 할 때입니다. 이는 사용자와 은행 계좌(아마도 전용 맞춤형 주선자를 사용하여)를 모두 생성하고 서로 연결하는 일을 담당합니다. Gerard Meszaros의 xUnit 테스트 패턴: 리팩토링 테스트 코드 의 여러 구현 변형을 포함하여 픽스처에 대해 자세히 설명되어 있습니다.
따라서 테스트 클래스에는 세 가지 유형의 빌딩 블록이 있습니다. 각각은 프로덕션 코드의 개념(도메인 기반 설계 빌딩 블록)에 대응되는 것으로 간주될 수 있습니다. 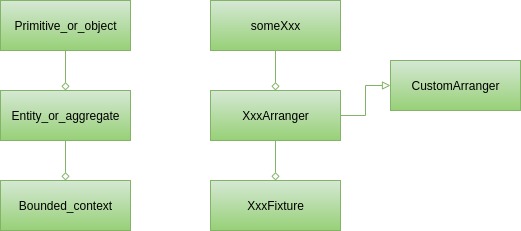
표면적으로는 원시 객체와 단순 객체가 있습니다. 이는 가장 간단한 단위 테스트에서도 나타나는 현상입니다. Arranger 클래스의 someXxx 메서드를 사용하여 이러한 테스트 데이터를 정렬할 수 있습니다.
따라서 User 인스턴스에서만 작동하거나 User 및 User 클래스에 포함된 다른 클래스(예: 주소 목록)에서만 작동하는 테스트가 필요한 서비스가 있을 수 있습니다. 이러한 경우를 처리하려면 일반적으로 UserArranger 와 같은 사용자 지정 배열이 필요합니다. 모든 제약 조건과 클래스 불변성을 존중하는 User 인스턴스를 생성합니다. 또한 존재하는 경우 AddressArranger 선택하여 유효한 데이터로 주소 목록을 채웁니다. 여러 테스트 사례에 특정 유형의 사용자(예: 빈 주소 목록이 있는 노숙자 사용자)가 필요한 경우 UserArranger에서 추가 메서드를 만들 수 있습니다. 결과적으로 테스트를 위해 User 인스턴스를 생성해야 할 때마다 UserArranger 살펴보고 적절한 팩토리 메소드를 선택하거나 Arranger.some(User.class) 호출하는 것으로 충분합니다.
가장 어려운 경우는 대규모 데이터 구조에 따른 테스트와 관련됩니다. 전자상거래에서는 많은 제품을 포함하는 상점일 수도 있고 쇼핑 기록이 있는 사용자 계정일 수도 있습니다. 이러한 테스트 사례에 대한 데이터를 정렬하는 것은 일반적으로 사소한 일이 아니며 이러한 일을 반복하는 것은 현명하지 않습니다. shopWithNineProductsAndFourCustomers 와 같이 이름이 잘 알려진 메서드 아래 전용 클래스에 저장하고 각 테스트에서 재사용하는 것이 훨씬 좋습니다. 이러한 클래스를 쉽게 찾을 수 있도록 명명 규칙을 사용하는 것이 좋습니다. Fixture 접미사를 사용하는 것이 좋습니다. 결국 우리는 다음과 같은 결론을 내릴 수 있습니다.
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}최신 테스트 준비자 버전은 Java 17을 사용하여 컴파일되며 Java 17+ 런타임에서 사용해야 합니다. 그러나 이전 버전과의 호환성을 위해 1.4.x 버전에 포함된 Java 8 분기도 있습니다.


