Azure Cognitive Search Azure OpenAI Accelerator
1.0.0
귀하의 조직에는 다중 채널 스마트 챗봇과 다양한 위치에 흩어져 있는 다양한 유형의 데이터를 이해할 수 있는 검색 엔진이 필요합니다. 또한, 대화형 챗봇은 문의사항에 대한 답변과 함께 답변을 얻은 방법과 장소에 대한 출처와 설명을 제공할 수 있어야 합니다. 즉, 비즈니스 데이터에 대한 질문을 해석하고 이해하고 답변할 수 있는 비공개 보안 ChatGPT가 조직에 필요합니다.
POC의 목표는 Azure 서비스로 구축된 GPT 가상 도우미의 가치를 귀하의 환경에서 귀하의 데이터로 보여주고 입증하는 것입니다. 결과물은 다음과 같습니다:
Bot Framework로 구축되어 여러 채널(웹 채팅, MS Teams, SMS, 이메일, Slack 등)에 노출되는 백엔드 Bot API
검색 및 Bot UI가 포함된 프런트엔드 웹 애플리케이션입니다.
이 저장소는 OpenAI 기반 스마트 검색 엔진을 구축하는 방법을 단계별로 가르치기 위해 만들어졌습니다. 각 노트북은 서로의 위에 구축되어 두 개의 애플리케이션을 구축하는 것으로 끝납니다.
Microsoft FTE의 경우: 이는 배송 자산 아래에 있는 고객 자금 지원 VBD입니다.
| 목 | 설명 | 링크 |
|---|---|---|
| VBD SKU 정보 및 데이터시트 | CSAM은 이를 통합 지원 계약의 크레딧/시간에 대해 "고객 투자"로 발송해야 합니다. 3일인지 5일인지 고객이 결정합니다. | ESXP SKU 페이지 |
| CSA에 대한 VBD 인증 | 워크숍을 진행하는 데 필요한 인증을 받기 위한 CSA 링크 | 링크 1, 링크 2 |
| VBD 3~5일 POC 자산(IP) | 제공될 MVP(이 GitHub 레포) | Azure-인지-검색-Azure-OpenAI-Accelerator |
| VBD 워크숍 덱 | 워크숍을 소개하고 설명하는 데크 | AOAI GPT 소개 Azure 스마트 검색 엔진 가속기.pptx |
| CSA 교육 비디오 | Microsoft CSA를 위한 2시간 교육 | POC VBD 교육 녹화(새 비디오가 곧 공개됩니다!) |
전제 조건 클라이언트 3~5일 POC
Azure 구독
GPT-4o를 포함하여 Azure Open AI에 대한 응용 프로그램이 허용되었습니다. 고객이 GPT-4o 승인을 받지 않은 경우 Microsoft CSA는 워크숍 중에 GPT-4o를 빌려줄 수 있습니다.
Microsoft 구성원은 클라이언트 Azure AD에 게스트로 추가하는 것이 좋습니다. 불가능할 경우 고객은 Microsoft 회원에게 기업 ID를 발급할 수 있습니다.
고객 Azure 테넌트에서 이 워크숍 POC에 대해 리소스 그룹(RG)을 설정해야 합니다.
고객 팀과 Microsoft 팀은 워크숍 2주 전에 모든 것을 설정할 수 있도록 이 리소스 그룹에 대한 기여자 권한이 있어야 합니다.
스토리지 계정은 RG에 설정되어야 합니다.
고객 데이터/문서는 워크숍 날짜로부터 최소 2주 전에 Blob Storage 계정에 업로드되어야 합니다.
다중 테넌트 앱 등록(서비스 주체)은 고객이 생성해야 합니다(클라이언트 ID 및 비밀 값 저장).
고객은 봇이 올바르게 응답하기를 원하는 10~20개의 질문(쉬움부터 어려움까지)을 Microsoft 팀에 제공해야 합니다.
워크숍 중 IDE 협업 및 표준화를 위해 Jupyper Lab이 포함된 AML 컴퓨팅 인스턴스가 사용됩니다. 이를 위해 Azure Machine Learning 작업 영역을 RG에 배포해야 합니다.
참고: Azure Machine Learning 작업 영역에 코어 컴퓨팅 할당량이 충분한지 확인하세요.

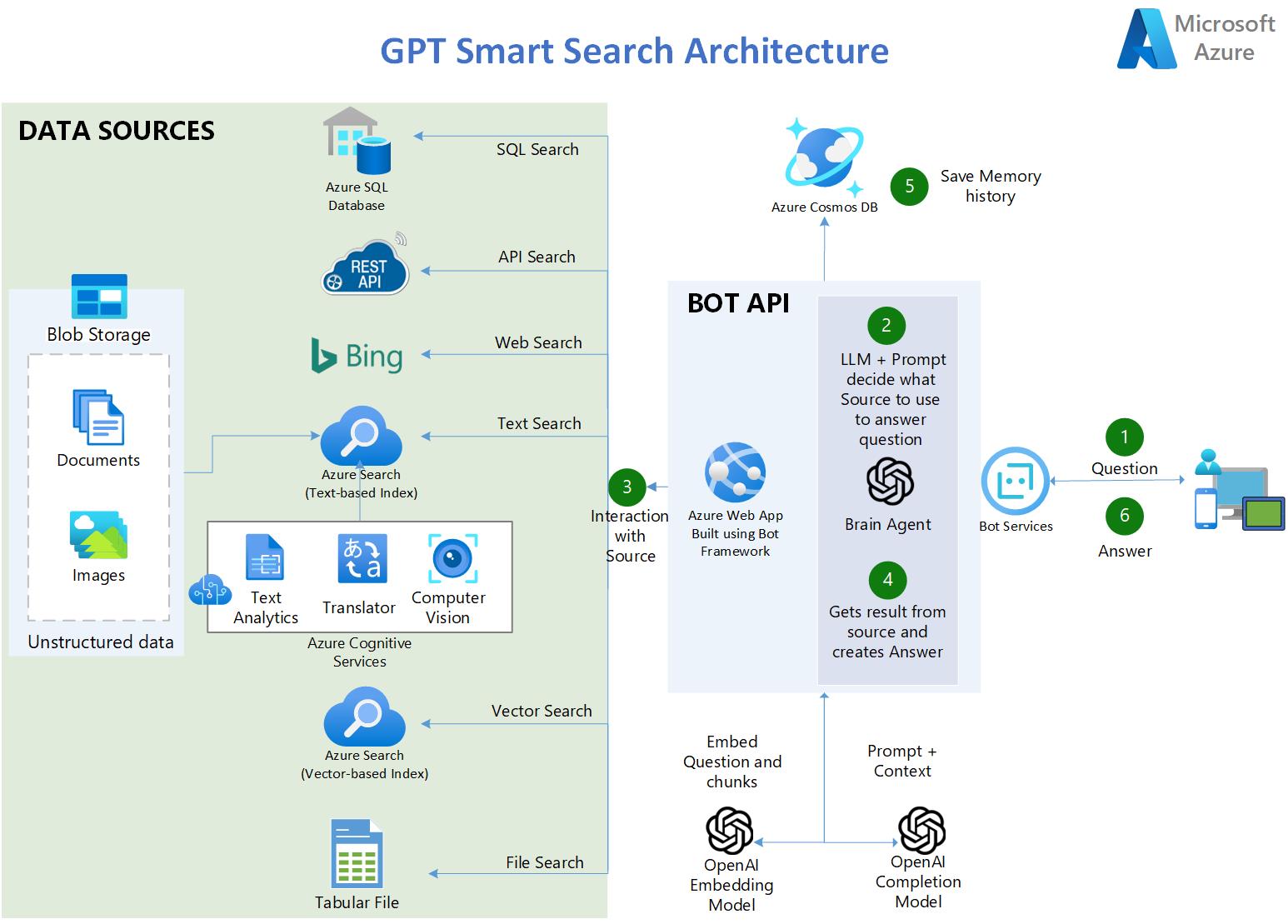
사용자가 질문을 합니다.
앱에서 OpenAI LLM은 영리한 프롬프트를 사용하여 사용자 입력에 따라 사용할 소스를 결정합니다.
다섯 가지 유형의 소스를 사용할 수 있습니다.
TV 쇼: FRIENDS의 모든 에피소드에 대한 대화 대본
90,000개의 코로나 출판물 초록
4권의 긴 PDF 책
3a. Azure SQL Database - 미국의 코로나19 관련 통계를 포함합니다.
3b. API 엔드포인트 - 코로나19에 대한 최신 통계가 포함된 RESTful OpenAPI 3.0 API입니다.
3c. Azure Bing Search API - 공개 웹 사이트의 QnA와 같은 상황을 허용하는 인터넷 액세스를 제공합니다.
3d. Azure AI Search - Blob Storage의 AI 강화 문서를 포함합니다.
3f. CSV 표 파일 - 미국의 코로나19 관련 통계를 포함합니다.
앱은 소스에서 결과를 검색하고 답을 만듭니다.
튜플(질문 및 답변)은 추가 분석을 위해 영구 메모리로 CosmosDB에 저장됩니다.
답변이 사용자에게 전달됩니다.
https://gptsmartsearchapp.azurewebsites.net/
100% 파이썬.
Azure Cognitive Services를 사용하여 구조화되지 않은 문서(이미지에 대한 OCR, 청킹 및 자동화된 벡터화)를 인덱싱하고 강화합니다.
Azure AI Search의 하이브리드 검색 기능을 사용하여 최상의 의미론적 답변을 제공합니다(텍스트 및 벡터 검색 결합).
Azure OpenAI, 벡터 저장소와 상호 작용하고 프롬프트 구성 및 에이전트 생성을 위한 래퍼로 LangChain을 사용합니다.
다중 언어(모든 언어 수집, 색인화 및 이해)
다중 색인 -> 다중 검색 색인
CSV 파일 및 SQL 플레이버 데이터베이스를 사용한 테이블 형식 데이터 Q&A
Azure AI Document Intelligence SDK(이전 Form Recognizer)를 사용하여 복잡하고 큰 PDF 문서를 구문 분석합니다.
Bing Search API를 사용하여 공개 웹사이트에 대한 인터넷 검색 및 Q&A를 지원합니다.
자연어 질문을 API 호출로 변환하여 API 데이터 소스에 연결합니다.
CosmosDB를 영구 메모리로 사용하여 사용자 대화를 저장합니다.
Streamlit을 사용하여 Python으로 프런트엔드 웹 애플리케이션을 구축합니다.
Bot Framework 및 Bot Service를 사용하여 Bot API 백엔드를 호스팅하고 이를 MS Teams를 포함한 여러 채널에 노출합니다.
스트리밍 기능을 갖춘 대체 백엔드 API를 배포하기 위해 LangServe/FastAPI도 사용합니다.
참고: (전제 조건) Azure OpenAI 서비스가 이미 생성되어 있어야 합니다.
이 저장소를 Github 계정으로 포크하세요.
Azure OpenAI Studio에서 다음 모델을 배포합니다(아래에 설명된 모델보다 오래된 모델은 작동하지 않음).
"gpt-4o"
"gpt-4o-미니"
"text-embedding-ada-002(또는 최신)"
이 가속기의 모든 자산이 포함될 리소스 그룹을 만듭니다. Azure OpenAI는 다른 RG 또는 다른 구독에 있을 수 있습니다.
Notebooks(Azure AI Search, Cognitive Services 등)를 실행하는 데 필요한 모든 Azure 인프라를 생성하려면 아래를 클릭하세요.
참고 : 이전에 Azure AI Services Multi-Service account 만든 적이 없다면 Azure Portal에서 수동으로 계정을 만들어 Responsible AI 약관을 읽고 동의하세요. 배포가 완료되면 삭제한 후 위의 배포 버튼을 사용하세요.
Forked 저장소를 AML 컴퓨팅 인스턴스에 복제합니다. 저장소가 비공개인 경우 아래의 문제 해결 섹션에서 비공개 저장소를 복제하는 방법을 참조하세요.
Python 3.10 conda 환경 이상에서 노트북을 실행해야 합니다.
컴퓨터에 종속성을 설치합니다(노트북을 실행할 동일한 conda 환경에서 아래 pip 명령을 수행해야 합니다. 예를 들어 AZML 컴퓨팅 인스턴스에서 다음을 실행합니다.
conda activate azureml_py310_sdkv2 pip install -r ./common/requirements.txt
일부 pip 종속성 오류가 발생할 수 있지만 괜찮습니다. 오류에 관계없이 라이브러리가 올바르게 설치되었습니다.
4단계에서 생성된 서비스의 고유한 값으로 credentials.env 파일을 편집합니다.
BLOB_SAS_TOKEN 및 BLOB_CONNECTION_STRING의 경우. 스토리지 계정>보안 + 네트워킹>공유 액세스 서명>SAS 생성으로 이동합니다.
노트북을 순서대로 실행합니다 . 그들은 서로의 위에 쌓입니다.
Azure AI 검색 엔진을 사용하여 LLM에 대한 컨텍스트를 제공하고 대신 LLM을 미세 조정하지 않는 이유는 무엇입니까?
A: OpenAI 문서 인용: "GPT-3는 공개 인터넷의 방대한 양의 텍스트에 대해 사전 훈련되었습니다. 몇 가지 예만 제시하면 어떤 작업을 수행하고 생성하려고 하는지 직관할 수 있는 경우가 많습니다. 그럴듯한 완성입니다. 이를 종종 "퓨샷 학습"이라고 합니다. 미세 조정은 프롬프트에 들어갈 수 있는 것보다 더 많은 예제를 학습하여 소수 학습을 개선하여 다양한 작업에서 더 나은 결과를 얻을 수 있도록 해줍니다. 모델이 미세 조정되면 더 이상 프롬프트에 예시를 제공할 필요가 없습니다. 이를 통해 비용이 절감되고 요청 지연 시간이 단축됩니다 ."
그러나 모델을 미세 조정하려면 기본적으로 쿼리 응답 샘플인 수백 또는 수천 개의 프롬프트 및 완료 튜플을 제공해야 합니다. 미세 조정의 목적은 LLM에 회사 데이터에 대한 지식을 제공하는 것이 아니라 모든 프롬프트에서 예제를 요구하지 않고도 작업을 실제로 잘 수행할 수 있도록 예제를 제공하는 것입니다.
예제에 프롬프트에 노출되어서는 안되는 독점 데이터가 포함되어 있거나 사용되는 언어가 의료, 약국 또는 기타 산업과 같이 고도로 전문화된 경우 또는 해당 언어가 사용되는 사용 사례와 같이 미세 조정이 필요한 경우가 있습니다. 인터넷에서는 흔히 볼 수 없습니다.
개인 저장소를 복제하는 단계:
터미널에서 GitHub 이메일 주소로 대체하여 아래 텍스트를 붙여넣습니다. 새 SSH 키를 생성합니다.
ssh-keygen -t ed25519 -C "[email protected]"
SSH 공개 키를 클립보드에 복사합니다. 새 SSH 키를 추가합니다.
cat ~/.ssh/id_ed25519.pub# 그런 다음 터미널에 표시된 id_ed25519.pub 파일#의 내용을 선택하여 클립보드에 복사합니다.
GitHub에서 설정-> SSH 및 GPG 키-> 새 SSH 키로 이동합니다.
'제목' 필드에 새 키에 대한 설명 라벨을 추가합니다. "AML 컴퓨팅". '키' 필드에 공개 키를 붙여넣습니다.
개인 저장소 복제
자식 클론 [email protected]:YOUR-USERNAME/YOUR-REPOSITORY.git
이 프로젝트는 기여와 제안을 환영합니다. 대부분의 기여는 귀하가 귀하의 기여를 사용할 권리가 있고 실제로 그렇게 할 권리가 있음을 선언하는 기여자 라이센스 계약(CLA)에 동의해야 합니다. 자세한 내용을 보려면 https://cla.opensource.microsoft.com을 방문하세요.
끌어오기 요청을 제출하면 CLA 봇이 자동으로 CLA 제공이 필요한지 여부를 결정하고 PR을 적절하게 장식합니다(예: 상태 확인, 댓글). 봇이 제공하는 지침을 따르기만 하면 됩니다. CLA를 사용하여 모든 저장소에서 이 작업을 한 번만 수행하면 됩니다.
이 프로젝트는 Microsoft 오픈 소스 행동 강령을 채택했습니다. 자세한 내용은 행동 강령 FAQ를 참조하거나 추가 질문이나 의견이 있는 경우 [email protected]으로 문의하세요.
이 프로젝트에는 프로젝트, 제품 또는 서비스에 대한 상표나 로고가 포함될 수 있습니다. Microsoft 상표 또는 로고의 승인된 사용에는 Microsoft의 상표 및 브랜드 지침이 적용되며 이를 따라야 합니다. 이 프로젝트의 수정된 버전에 Microsoft 상표 또는 로고를 사용하면 혼동을 일으키거나 Microsoft 후원을 암시해서는 안 됩니다. 제3자 상표 또는 로고의 사용에는 해당 제3자의 정책이 적용됩니다.