mae
1.0.0
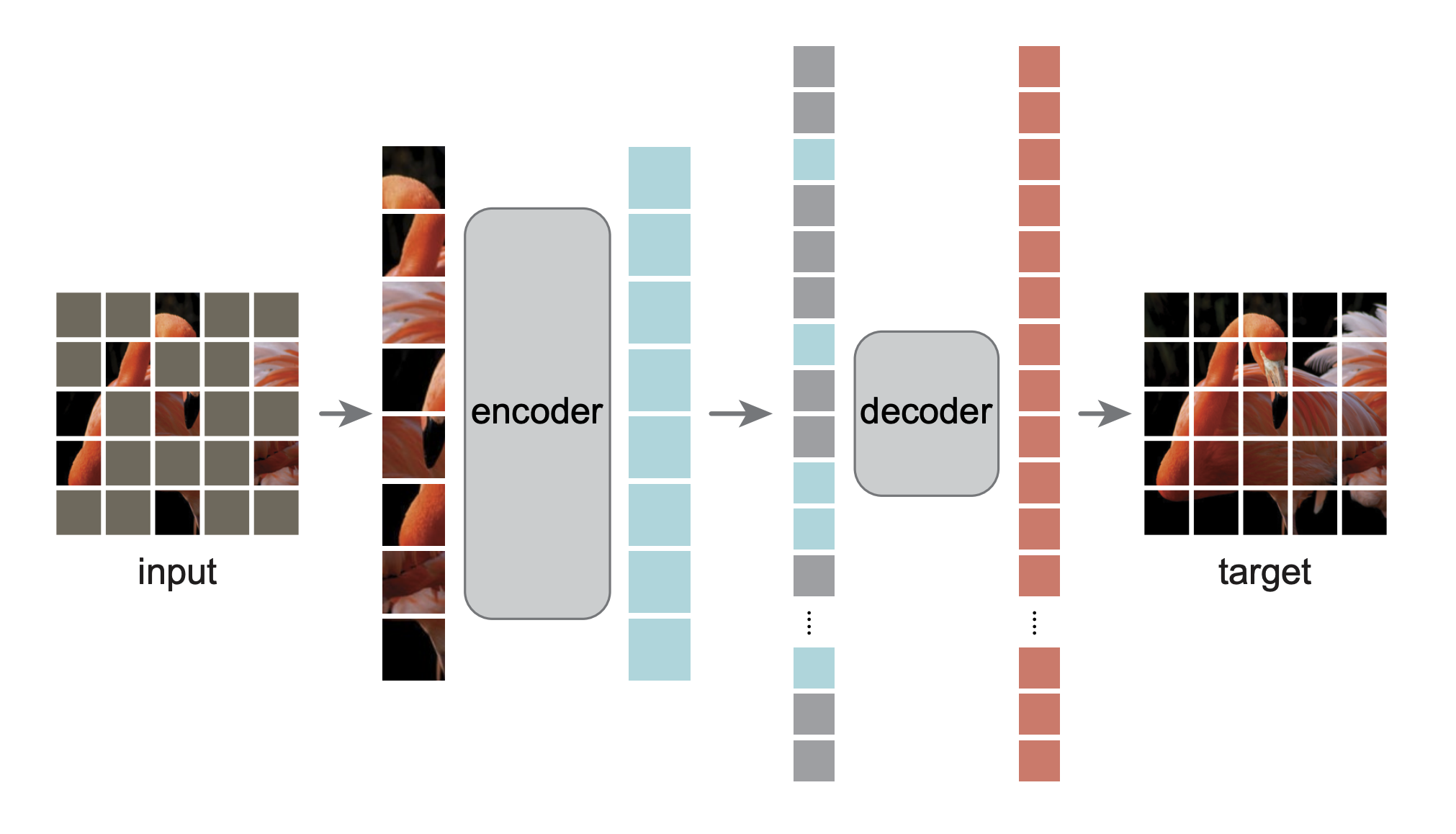
이것은 Masked Autoencoders Are Scalable Vision Learners 논문을 PyTorch/GPU로 재구현한 것입니다.
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
원래 구현은 TensorFlow+TPU에 있었습니다. 이 재구현은 PyTorch+GPU에서 이루어집니다.
이 저장소는 DeiT 저장소의 수정본입니다. 설치 및 준비는 해당 저장소를 따릅니다.
이 저장소는 timm==0.3.2 기반으로 하며 PyTorch 1.8.1+에서 작동하려면 수정이 필요합니다.
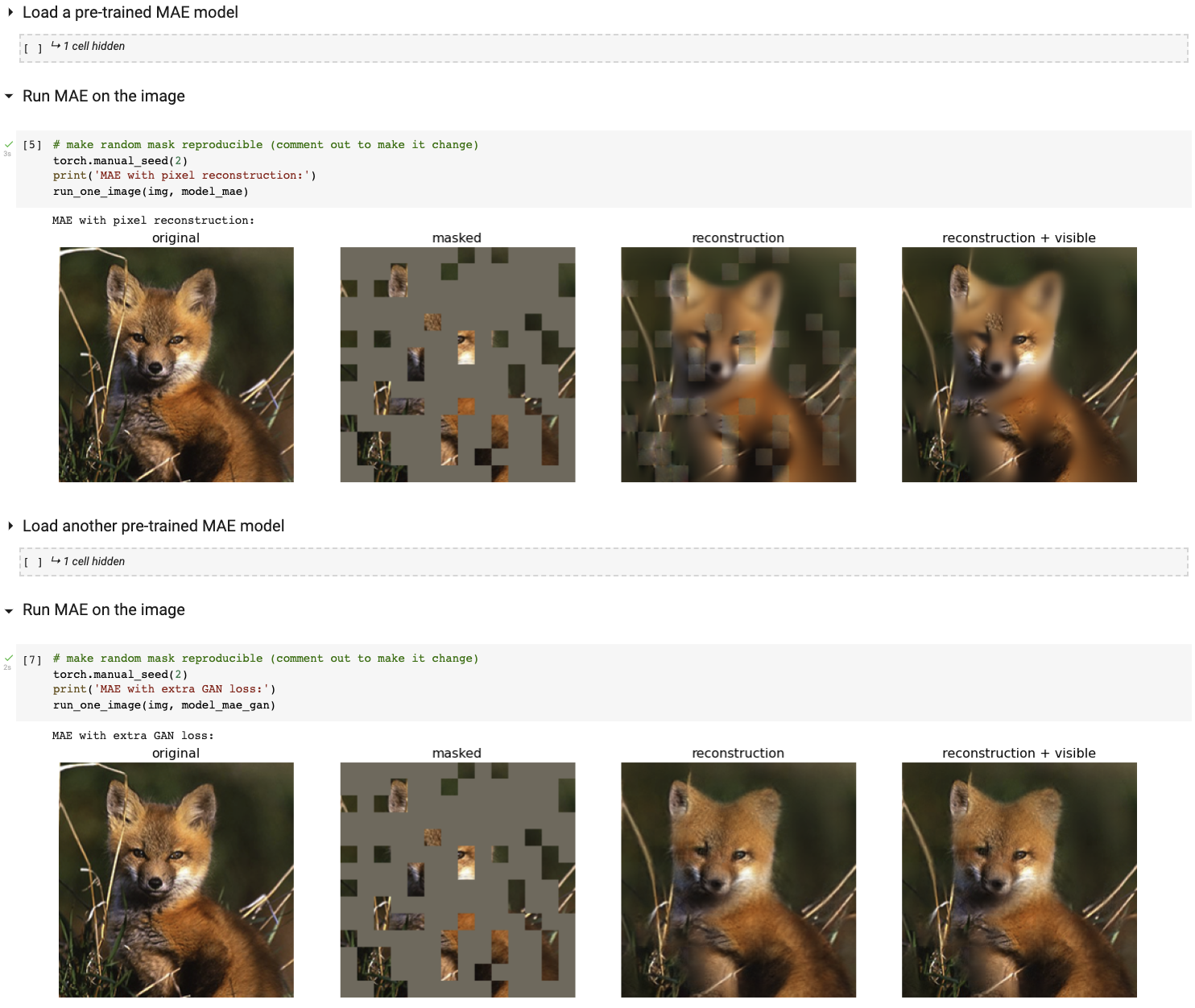
Colab 노트북을 사용하여 대화형 시각화 데모를 실행하세요(GPU 필요 없음).
다음 표는 논문에 사용된 사전 훈련된 체크포인트를 TF/TPU에서 PT/GPU로 변환한 것입니다.
| ViT-베이스 | ViT-대형 | ViT-거대한 | |
|---|---|---|---|
| 사전 훈련된 체크포인트 | 다운로드 | 다운로드 | 다운로드 |
| MD5 | 8cad7c | b8b06e | 9bdbb0 |
미세 조정 지침은 FINETUNE.md에 있습니다.
이러한 사전 훈련된 모델을 미세 조정함으로써 우리는 다음 분류 작업에서 1위를 차지했습니다(논문에 자세히 설명되어 있음).
| ViT-B | ViT-L | ViT-H | ViT-H 448 | 이전 최고 | |
|---|---|---|---|---|---|
| ImageNet-1K(외부 데이터 없음) | 83.6 | 85.9 | 86.9 | 87.8 | 87.1 |
| 다음은 동일한 모델 가중치에 대한 평가입니다(원래 ImageNet-1K에서 미세 조정됨). | |||||
| ImageNet-손상(오류율) | 51.7 | 41.8 | 33.8 | 36.8 | 42.5 |
| ImageNet-적대적 | 35.9 | 57.1 | 68.2 | 76.7 | 35.8 |
| ImageNet 변환 | 48.3 | 59.9 | 64.4 | 66.5 | 48.7 |
| ImageNet 스케치 | 34.5 | 45.3 | 49.6 | 50.9 | 36.0 |
| 다음은 대상 데이터 세트에서 사전 훈련된 MAE를 미세 조정하여 전이 학습을 하는 것입니다. | |||||
| iNaturists 2017 | 70.5 | 75.7 | 79.3 | 83.4 | 75.4 |
| iNaturists 2018 | 75.4 | 80.1 | 83.0 | 86.8 | 81.2 |
| iNaturists 2019 | 80.5 | 83.4 | 85.7 | 88.3 | 84.1 |
| 장소205 | 63.9 | 65.8 | 65.9 | 66.8 | 66.0 |
| 장소365 | 57.9 | 59.4 | 59.8 | 60.3 | 58.0 |
사전 훈련 지침은 PRETRAIN.md에 있습니다.
이 프로젝트는 CC-BY-NC 4.0 라이센스를 따릅니다. 자세한 내용은 라이센스를 참조하세요.


