Python 3.8 및 conda, GPU 환경을 사용하려면 Conda CUDA를 구입하세요.
conda create -n $YOUR_PY38_ENV_NAME python=3.8
conda activate $YOUR_PY38_ENV_NAME
pip install -r requirements.txt
우리 프로젝트의 경우 입력은 (B, T, C, H, W) 모양의 배열 형식이며, 배열의 각 프레임은 128x128의 고정 크기를 갖습니다. 각 영상의 프레임 수는 30개이므로 (B, 30, 3,128, 128)의 형태가 됩니다. 이 프로젝트를 사용하기 전에 그에 따라 비디오 데이터를 전처리해야 할 수도 있습니다. 코드에서는 (46, 30, 3, 128, 128) 모양의 예제 배열 "city_bonn.npy"를 제공합니다. 이 배열에는 Cityscape 데이터 세트에 있는 Bonn시의 비디오 46개가 포함되어 있습니다. 아래는 예시 명령입니다.
start_idx 및 end_idx 값을 선택하여 처리할 비디오를 제어할 수 있습니다. 선택한 범위가 B 값(데이터세트의 비디오 수)을 초과하지 않는지 확인하세요.
python city_sender.py --data_npy "data_npy/city_bonn.npy" --output_path "your path" --start_idx 0 --end_idx 1
벤치마크 섹션에서는 H.264 및 H.265에 대한 압축 메트릭을 계산하기 위한 코드를 제공합니다. 이 코드의 입력은 128x128 이미지 프레임의 30개 프레임이어야 하며 이름은 "frame%d" 형식으로 지정하는 것이 좋습니다.
데이터 세트의 폴더 구조는 다음과 같습니다
/your path/
- frame0.png
- frame1.png
- ...
- frame29.png
project_str의 경우 이는 단순히 데이터를 구별하는 데 사용되는 문자열입니다. 여기서는 "uvg"를 사용합니다.
python bench.py --dataset "your path" --output_path "your path" --project_str uvg
체크포인트와 관련하여 우리는 두 세트를 활용합니다. 한 세트에는 영상 생성 부분에 사용되는 "checkpoint_900000.pt"가 포함되어 있습니다. 다른 세트에는 6개의 체크포인트 그룹이 포함되어 있으며 이러한 체크포인트는 6개의 서로 다른 압축 품질에 해당하는 이미지 압축 부분에 사용됩니다.
6개의 가중치를 "checkpoints/neural network" 폴더로 이동해야 합니다.
| 람다 | 품질 |
|---|---|
| 0.45 | q5 |
| 0.15 | q4 |
| 0.032 | q3 |
| 0.015 | q2 |
| 0.008 | q1 |
| 0.004 | q0 |
이 개별 중량을 "checkpoints/sender" 폴더로 이동해야 합니다.
| 확산모델의 체크포인트 |
|---|
| 확산모델의 체크포인트 |
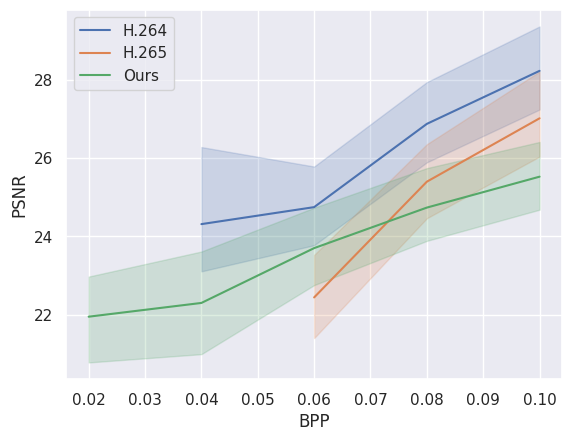
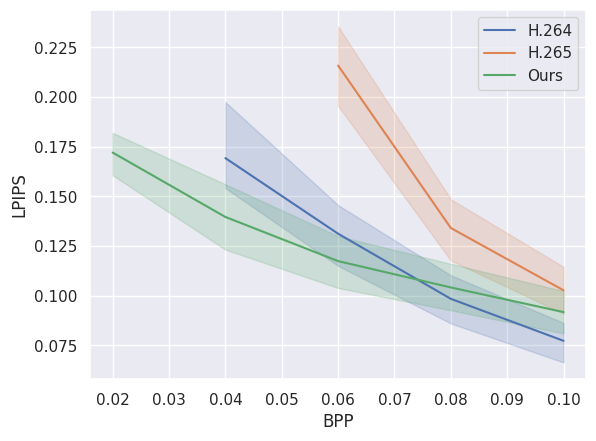
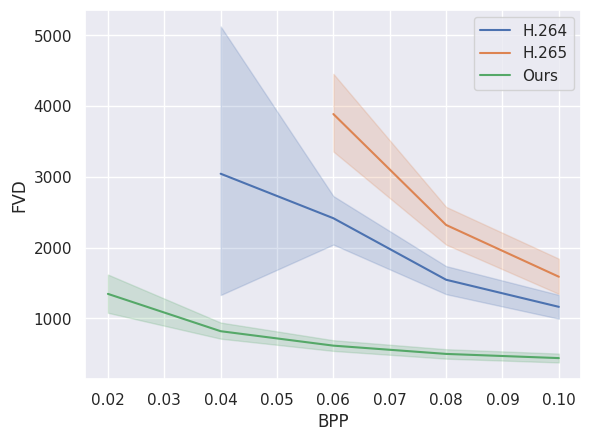
다음 이미지는 당사 모델의 압축 성능을 기존 비디오 압축 표준인 H.264 및 H.265와 비교합니다. 우리 모델이 낮은 비트레이트(bpp)에서 더 나은 성능을 보이는 것을 볼 수 있습니다. 이 데이터는 city_bonn.npy의 처음 24개 비디오에서 계산되었습니다.