clearml agent
v1.9.2

ClearML 에이전트 - MLOps/LLMOps가 쉬워졌습니다.
Linux, macOS 및 Windows를 지원하는 MLOps/LLMOps 스케줄러 및 오케스트레이션 솔루션
? ClearML is open-source - Leave a star to support the project! ?
완전한 ML/DL 클러스터 솔루션을 제공하는 제로 구성 실행 후 잊어버리는 실행 에이전트입니다.
5단계 완전 자동화
pip install clearml-agent (모든 GPU 시스템(온프레미스/클라우드/...)에 ClearML 에이전트 설치)"연구에 필요한 모든 Deep/Machine-Learning DevOps, 그리고 그 다음에는... 아무도 그럴 시간이 없기 때문입니다."
지금 ClearML을 사용해 보세요. 자체 호스팅 또는 무료 계층 호스팅 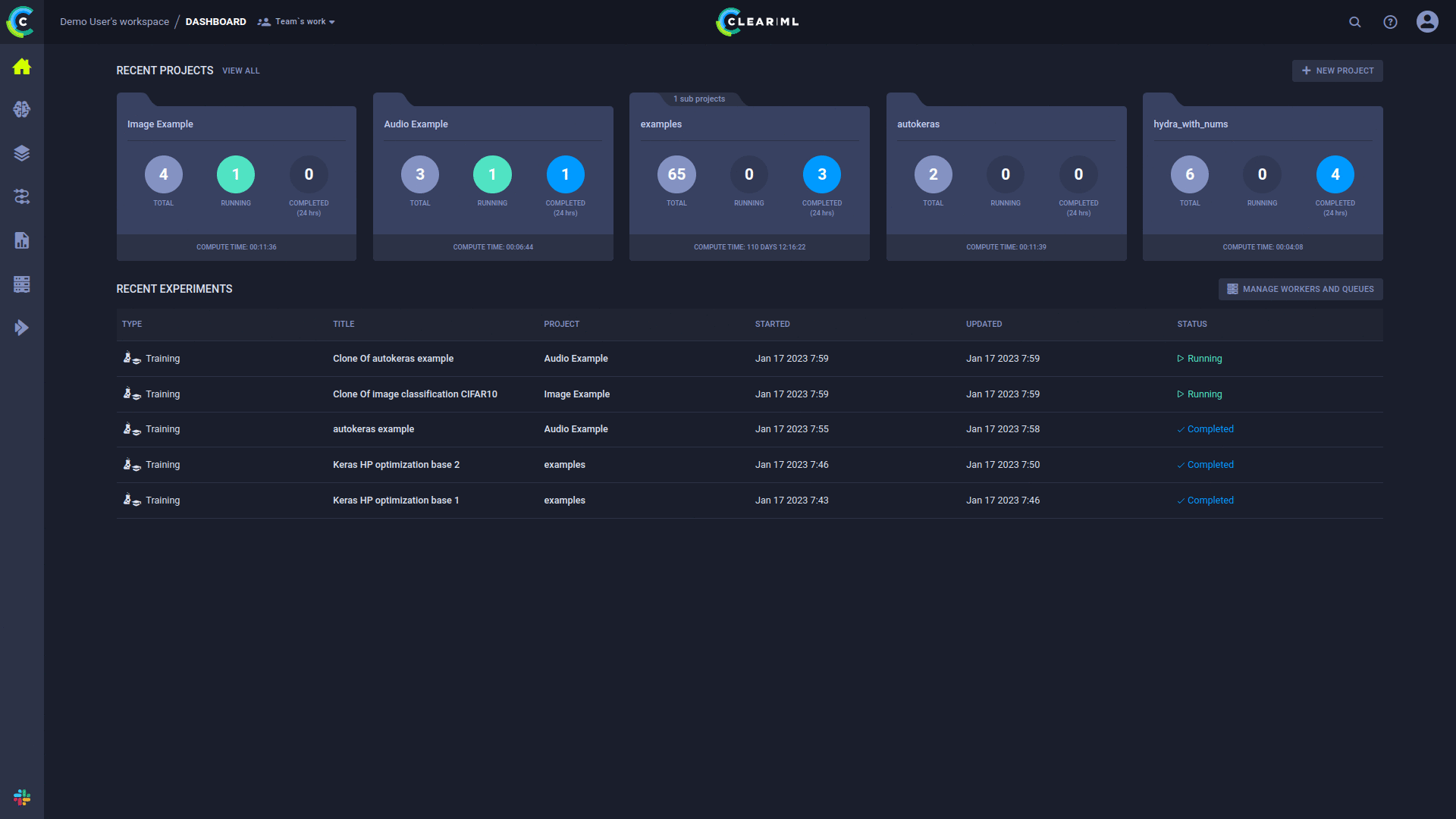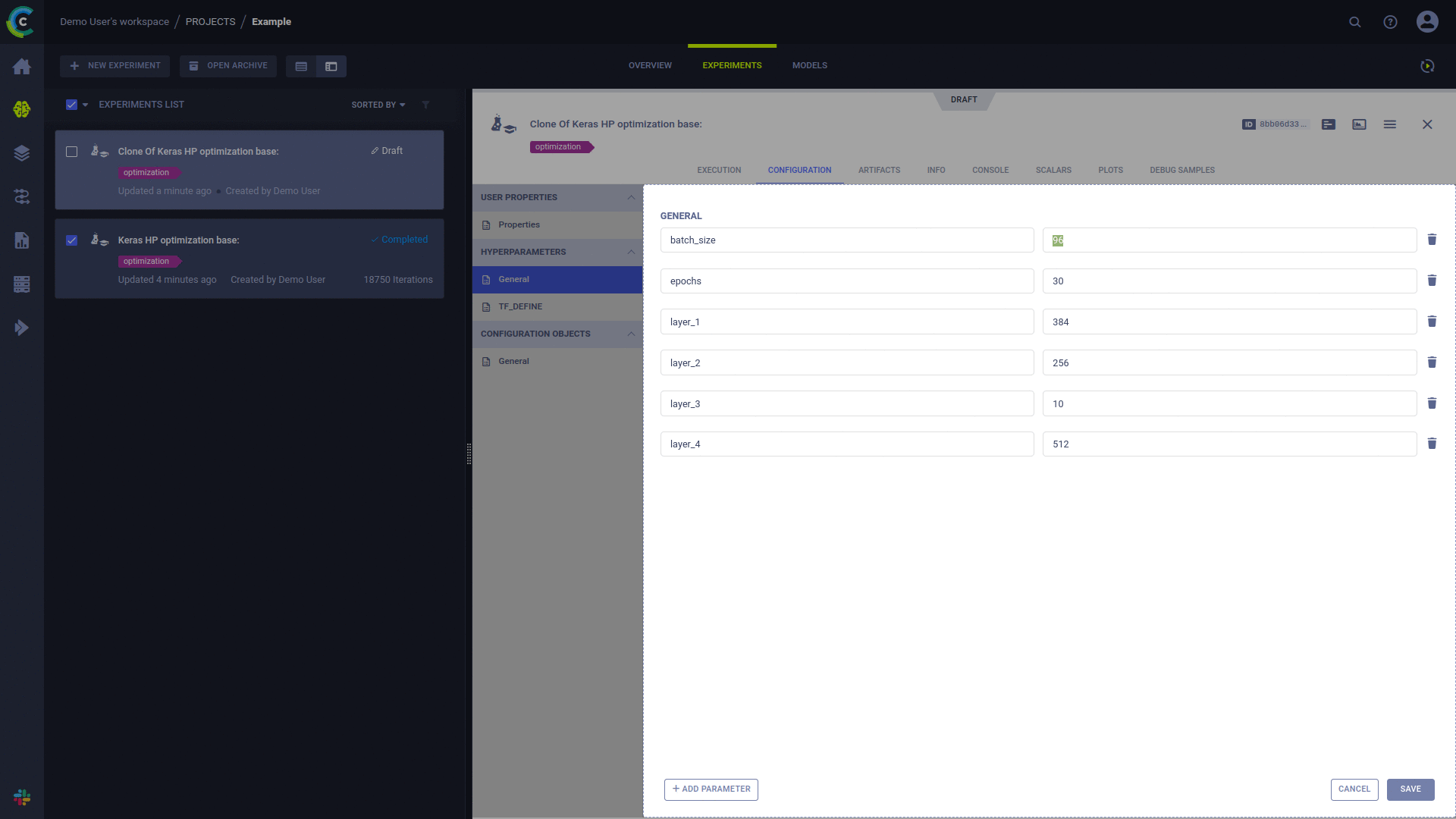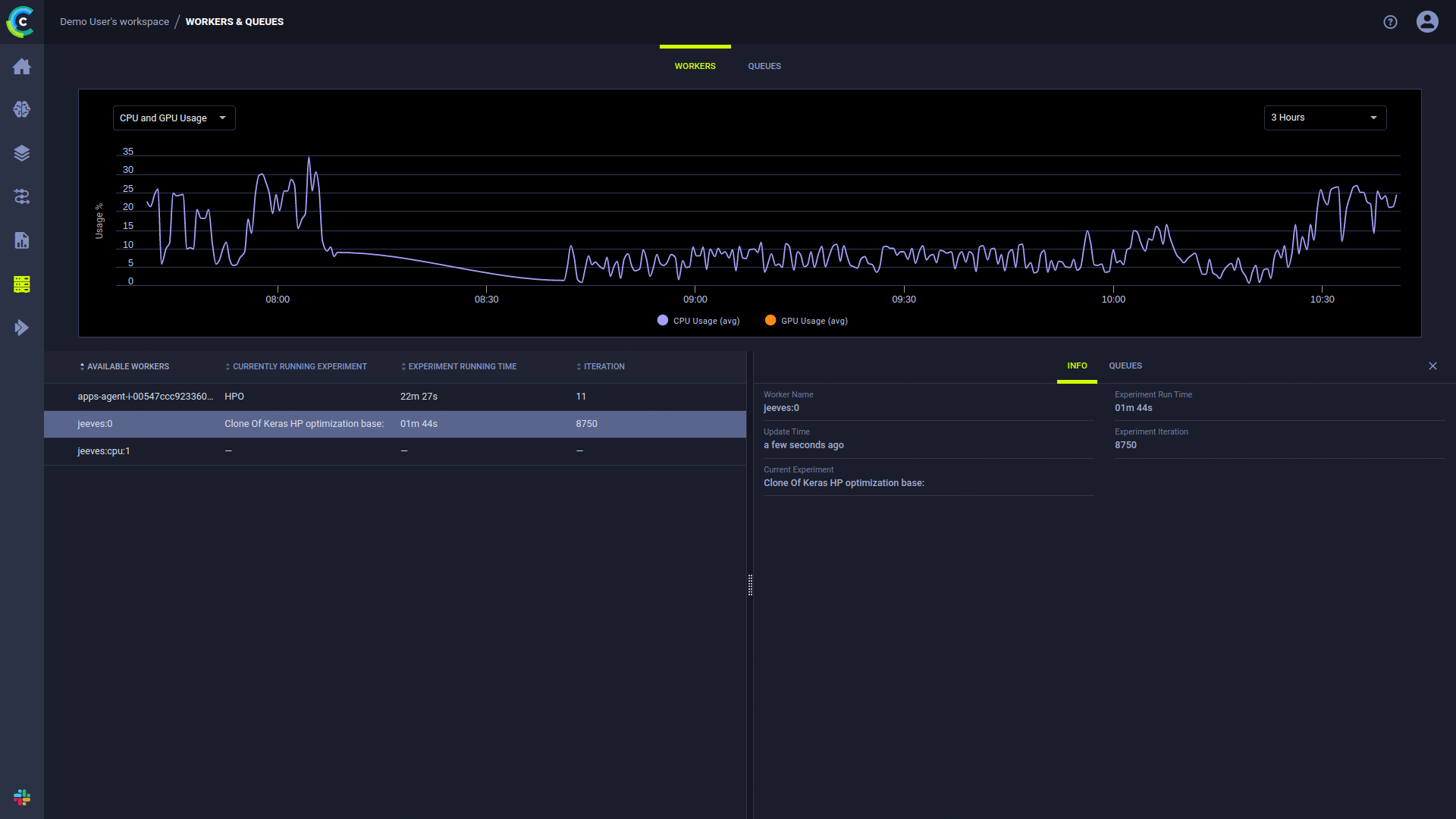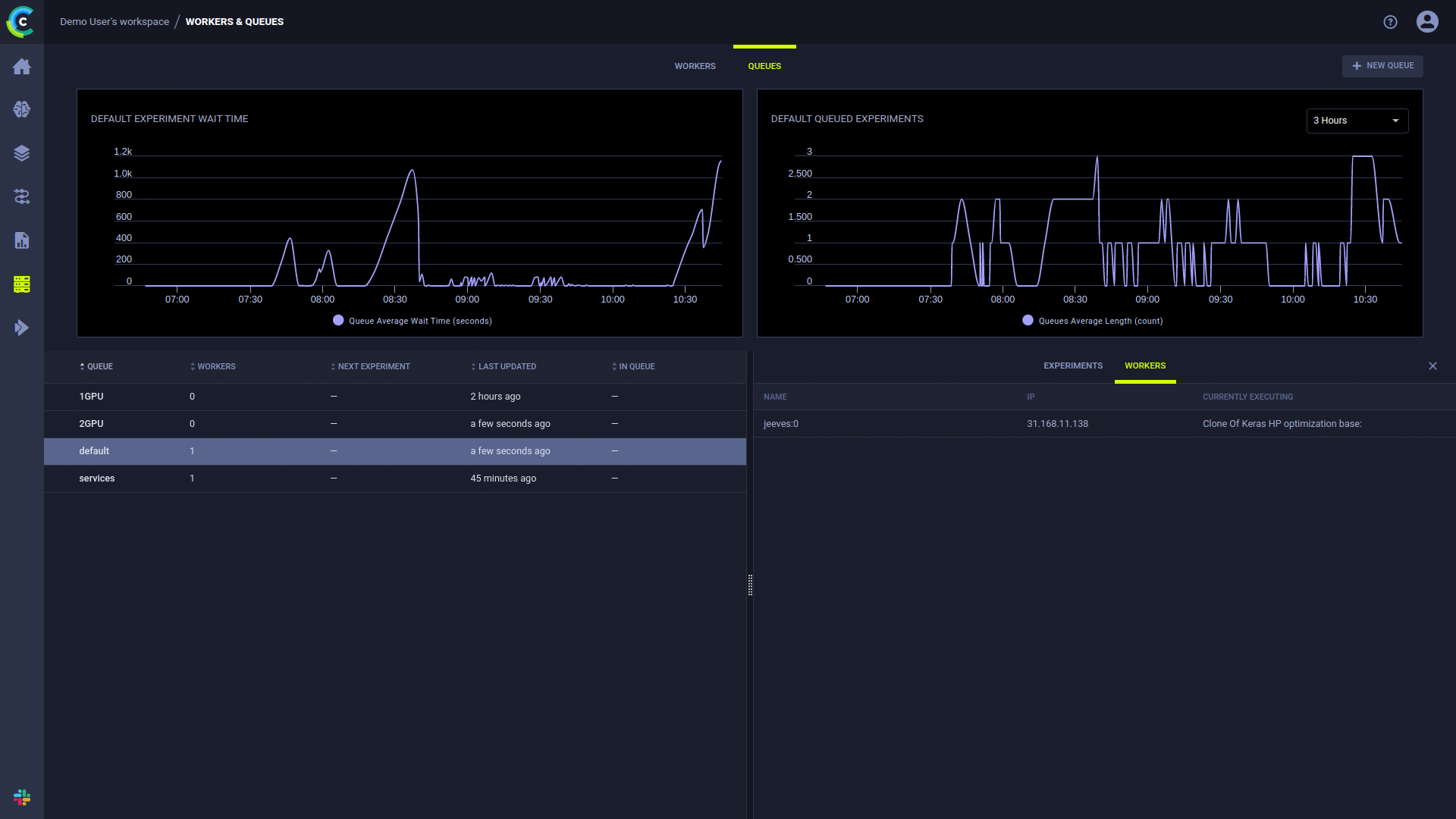
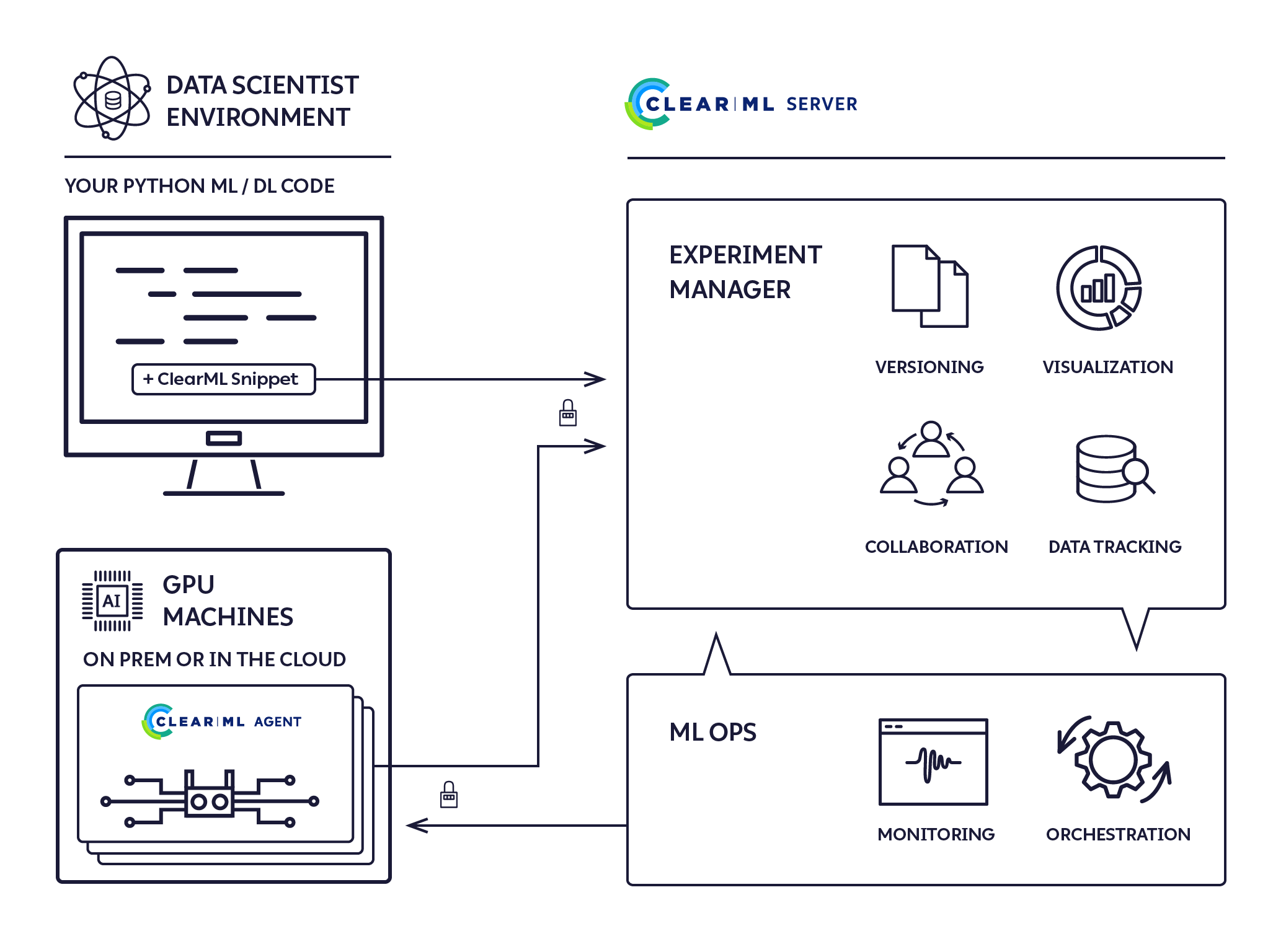
ClearML 에이전트는 DL/ML R&D DevOps 요구 사항을 해결하기 위해 구축되었습니다.
ClearML 에이전트를 사용하면 이제 *epsilon DevOps로 동적 클러스터를 설정할 수 있습니다.
*엡실론 - 우리가 ? 그리고 정말 일이 전혀 없는 것은 없습니다
Kubernetes는 훌륭하다고 생각하지만 원격 실행 에이전트와 클러스터 관리를 시작하는 데 반드시 필요한 것은 아닙니다. 우리는 환경에 맞는 조합으로 베어 메탈과 Kubernetes 위에서 모두 실행할 수 있도록 clearml-agent 설계했습니다.
docker 폴더에서 Dockerfile을 찾을 수 있고 https://github.com/allegroai/clearml-helm-charts에서 helm 차트를 찾을 수 있습니다.
Kubernetes Glue 모드에서 에이전트를 실행하여 ClearML 작업을 K8s 작업에 직접 매핑합니다.
예! Slurm 통합이 가능합니다. 자세한 내용은 설명서를 확인하세요.
버튼 클릭만으로 전체 규모 HPC
ClearML 에이전트는 작업 큐를 수신하고, 작업을 가져오고, 작업 환경을 설정하고, 작업을 실행하고 진행 상황을 모니터링하는 작업 스케줄러입니다.
ClearML 에이전트에 의해 실행되도록 모든 '초안' 실험을 예약할 수 있습니다.
이전에 실행된 실험은 다음 두 가지 방법 중 하나로 '초안' 상태로 전환될 수 있습니다.
ClearML UI의 실험 마우스 오른쪽 버튼 클릭 컨텍스트 메뉴에서 'Enqueue' 작업을 사용하고 실행 대기열을 선택하여 실험 실행이 예약됩니다.
실험을 만들고 실행을 위해 대기열에 추가하는 방법을 참조하세요.
실험이 대기열에 추가되면 이 대기열을 모니터링하는 ClearML 에이전트에 의해 선택되어 실행됩니다.
ClearML UI 작업자 및 대기열 페이지는 지속적인 실행 정보를 제공합니다.
ClearML 에이전트는 다음 프로세스를 사용하여 실험을 실행합니다.
pip install clearml-agent전체 인터페이스 및 기능을 다음과 같이 사용할 수 있습니다.
clearml-agent --help
clearml-agent daemon --helpclearml-agent init 참고: ClearML 에이전트는 캐시 폴더를 사용하여 pip 패키지, apt 패키지 및 복제된 저장소를 캐시합니다. 기본 ClearML 에이전트 캐시 폴더는 ~/.clearml 입니다.
~/clearml.conf 의 구성 파일에서 자세한 내용을 확인하세요.
참고: ClearML 에이전트는 ClearML 구성 파일 ~/clearml.conf 를 확장합니다. 동일한 구성 파일을 공유하도록 설계되었습니다. 여기에서 예를 참조하세요.
디버그 및 실험을 위해 모든 출력이 화면에 인쇄되는 foreground 모드에서 ClearML 에이전트를 시작합니다.
clearml-agent daemon --queue default --foreground 실제 서비스 모드의 경우 모든 stdout은 임시 파일에 자동으로 저장됩니다(파이프할 필요 없음). 참고: --detached 플래그를 사용하면 Clearml-agent가 백그라운드에서 실행됩니다.
clearml-agent daemon --detached --queue default GPU 할당은 표준 OS 환경 NVIDIA_VISIBLE_DEVICES 또는 --gpus 플래그를 통해 제어됩니다(또는 --cpu-only 로 비활성화).
플래그가 설정되지 않고 NVIDIA_VISIBLE_DEVICES 변수가 존재하지 않으면 모든 GPU가 clearml-agent 에 할당됩니다.
--cpu-only 플래그가 설정되거나 NVIDIA_VISIBLE_DEVICES="none" 이면 clearml-agent 에 GPU가 할당되지 않습니다.
예: 동일한 머신에서 GPU당 하나씩 두 개의 에이전트를 실행합니다.
참고: --detached 플래그를 사용하면 Clearml-agent가 백그라운드에서 실행됩니다.
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default 예: 에이전트 2개 스핀, 전용 dual_gpu 대기열에서 가져오기, 에이전트당 GPU 2개
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu 디버그 및 실험을 위해 모든 출력이 화면에 인쇄되는 foreground 모드에서 ClearML 에이전트를 시작합니다.
clearml-agent daemon --queue default --docker --foreground 실제 서비스 모드의 경우 모든 stdout이 자동으로 파일에 저장됩니다(파이프할 필요 없음). 참고: --detached 플래그를 사용하면 Clearml-agent가 백그라운드에서 실행됩니다.
clearml-agent daemon --detached --queue default --docker 예: 기본 nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker를 사용하여 동일한 머신에서 GPU당 하나씩 두 개의 에이전트를 실행합니다.
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 예: 기본 nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker를 사용하여 에이전트당 2개의 GPU, 전용 dual_gpu 대기열에서 가져오는 2개의 에이전트를 스핀합니다.
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04우선순위 대기열도 지원됩니다. 사용 사례의 예는 다음과 같습니다.
높은 우선순위 큐: important_jobs , 낮은 우선순위 큐: default
clearml-agent daemon --queue important_jobs default ClearML 에이전트는 먼저 important_jobs 대기열에서 작업 가져오기를 시도하고, 비어 있는 경우에만 에이전트는 default 대기열에서 작업 가져오기를 시도합니다.
대기열 추가, 대기열 내 작업 순서 관리, 대기열 간 작업 이동은 웹 UI를 사용하여 수행할 수 있습니다. 무료 서버의 예를 참조하세요.
백그라운드에서 실행 중인 ClearML 에이전트를 중지하려면 --stop 추가하여 에이전트를 시작하는 데 사용된 것과 동일한 명령줄을 실행하세요. 예를 들어 위에 표시된 동일한 머신 중 첫 번째 단일 GPU 에이전트를 중지하려면 다음을 수행합니다.
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopClearML을 코드와 통합
머신에서 코드 실행(수동 / PyCharm / Jupyter Notebook)
코드가 실행되는 동안 ClearML은 필요한 모든 실행 정보를 기록하는 실험을 생성합니다.
이제 자동화된 실행에 필요한 모든 것을 갖춘 실험의 '템플릿'이 생겼습니다.
ClearML UI에서 실험을 마우스 오른쪽 버튼으로 클릭하고 '복제'를 선택합니다. 실험 사본이 생성됩니다.
이제 원래 실험에서 복제된 새로운 초안 실험이 생겼습니다. 자유롭게 편집하세요.
새로 생성된 실험 실행 예약: 실험을 마우스 오른쪽 버튼으로 클릭하고 '인큐'를 선택합니다.
ClearML-Agent 서비스는 이전에 로컬/전용 시스템에서 실행해야 했던 오래 지속되는 작업을 시작하는 기능을 제공하는 ClearML-Agent의 특수 모드입니다. 이를 통해 단일 에이전트가 다양한 사용 사례에 대해 여러 도커(작업)를 시작할 수 있습니다.
ClearML-Agent Services 모드는 지정된 대기열에 포함된 모든 작업을 회전시킵니다. ClearML-Agent Services에서 시작된 모든 작업은 시스템의 새 노드로 등록되어 추적 및 투명성 기능을 제공합니다. 현재 서비스 모드의 Clearml-agent는 CPU 전용 구성을 지원합니다. ClearML-Agent 서비스 모드는 GPU 에이전트와 함께 시작할 수 있습니다.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-only참고 : 적절한 작업이 지정된 대기열에 푸시되는지 확인하는 것은 사용자의 책임입니다.
ClearML 에이전트는 ClearML 패키지와 함께 AutoML 오케스트레이션 및 실험 파이프라인을 구현하는 데에도 사용할 수 있습니다.
샘플 AutoML 및 오케스트레이션 예제는 ClearML example/automation 폴더에서 찾을 수 있습니다.
AutoML 예:
실험 파이프라인 예:
Apache 라이센스, 버전 2.0(자세한 내용은 라이센스 참조)


