[페이퍼] [프로젝트 페이지 ] [miniFLUX 모델 ] [SD3 모델 ⚡️] [demo ?]
이것은 Flow Matching을 기반으로 하는 교육 효율적인 자동 회귀 비디오 생성 방법인 Pyramid Flow의 공식 저장소입니다. 오픈 소스 데이터 세트 로만 학습함으로써 768p 해상도, 24FPS의 고품질 10초 비디오를 생성할 수 있으며 자연스럽게 이미지-비디오 생성을 지원합니다.
| 10초, 768p, 24fps | 5초, 768p, 24fps | 이미지-비디오 |
|---|---|---|
불꽃놀이.mp4 | 예고편.mp4 | 일요일.mp4 |
2024.11.13 768p miniFLUX 체크포인트(최대 10초)를 출시합니다.
인간 구조 문제를 해결하기 위해 모델 구조를 SD3에서 mini FLUX로 전환했습니다. 1024p 이미지 체크포인트, 384p 비디오 체크포인트(최대 5초) 및 768p 비디오 체크포인트(최대 10초)를 사용해 보십시오. 새로운 미니플럭스 모델은 인체 구조와 동작 안정성이 크게 향상되었습니다.
2024.10.29 ⚡️⚡️⚡️ VAE용 학습 코드, DiT용 미세 조정 코드 및 처음부터 학습된 FLUX 구조를 갖춘 새로운 모델 체크포인트를 출시합니다.
2024.10.13 다중 GPU 추론 및 CPU 오프로딩이 지원됩니다. 8GB 미만 의 GPU 메모리로 사용하면 여러 GPU에서 속도가 크게 향상됩니다.
2024.10.11 ??? Hugging Face 데모를 볼 수 있습니다. 커밋을 해주신 @multimodalart에게 감사드립니다!
2024.10.10 피라미드플로우의 기술보고서, 프로젝트 페이지, 모델 체크포인트를 공개합니다.
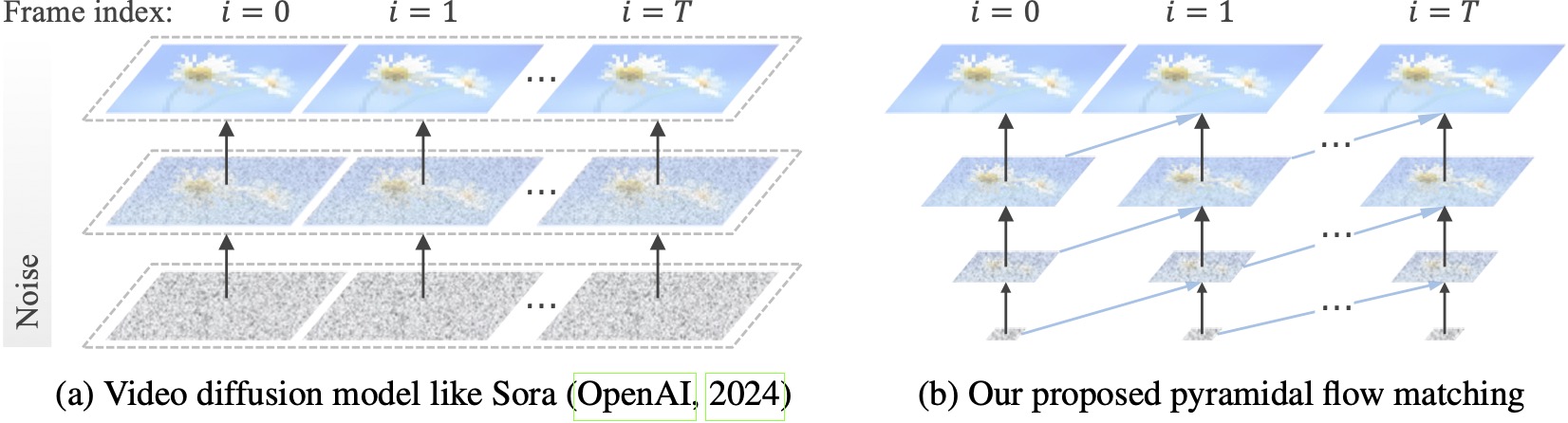
기존 비디오 확산 모델은 전체 해상도에서 작동하며 매우 시끄러운 잠재성에 대해 많은 계산을 소비합니다. 대조적으로, 우리의 방법은 흐름 일치의 유연성(Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023)을 활용하여 서로 다른 해상도와 잡음 수준의 잠재성을 보간하여 동시 생성과 더 나은 계산 효율성으로 시각적 콘텐츠의 압축을 푼다. 전체 프레임워크는 단일 DiT(Peebles & Xie, 2023)로 엔드투엔드 최적화되어 20.7k A100 GPU 교육 시간 내에 768p 해상도 및 24FPS의 고품질 10초 비디오를 생성합니다.
conda를 사용하여 환경을 설정하는 것이 좋습니다. 코드베이스는 현재 Python 3.8.10 및 PyTorch 2.1.2(가이드)를 사용하고 있으며 더 다양한 버전을 지원하기 위해 적극적으로 노력하고 있습니다.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txt그런 다음 Huggingface에서 모델을 다운로드하세요(miniFLUX 또는 SD3의 두 가지 변형이 있음). miniFLUX 모델은 1024p 이미지, 384p 및 768p 비디오 생성을 지원하고, SD3 기반 모델은 768p 및 384p 비디오 생성을 지원합니다. 384p 체크포인트는 24FPS에서 5초 비디오를 생성하는 반면, 768p 체크포인트는 24FPS에서 최대 10초 비디오를 생성합니다.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )시작하려면 먼저 Gradio를 설치하고 모델 경로를 #L36에 설정한 다음 로컬 컴퓨터에서 실행하세요.
python app.pyGradio 데모가 브라우저에서 열립니다. @tpc2233 커밋 덕분에 자세한 내용은 #48을 참조하세요.
아니면 Hugging Face Space에서 손쉽게 시도해 보세요. @multimodalart가 만들었습니다. GPU 제한으로 인해 이 온라인 데모는 25프레임(8FPS 또는 24FPS로 내보내기)만 생성할 수 있습니다. 더 긴 비디오를 생성하려면 공간을 복제하세요.
Google Colab에서 Pyramid Flow를 빠르게 사용해 보려면 아래 코드를 실행하세요.
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
우리 모델을 사용하려면 이 링크의 video_generation_demo.ipynb 에 있는 추론 코드를 따르세요. 인간의 구조와 동작 안정성이 크게 개선된 최신 발표된 Pyramid-Miniflux를 사용해 보시기를 강력히 권장합니다. 사용할 param model_name pyramid_flux 로 설정합니다. 이를 다음과 같은 2단계 절차로 더욱 단순화합니다. 먼저 다운로드한 모델을 로드합니다.
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()그런 다음 원하는 대로 텍스트를 비디오로 변환해 볼 수 있습니다. 384p 버전은 이제 5초만 지원합니다(온도를 최대 16으로 설정)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )자동 회귀 모델로서 우리 모델은 (텍스트 조건에 따른) 이미지-비디오 생성도 지원합니다.
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )또한 GPU 메모리 요구 사항을 줄이기 위해 두 가지 유형의 CPU 오프로드를 지원합니다. 효율성이 저하될 수 있습니다.
cpu_offloading=True 매개변수를 추가하면 12GB 미만 의 GPU 메모리로도 추론이 가능합니다. 이 기능은 @Ednaordinary가 제공한 것입니다. 자세한 내용은 #23을 참조하세요.model.enable_sequential_cpu_offload() 호출하면 8GB 미만 의 GPU 메모리로도 추론이 가능합니다. 이 기능은 @rodjjo가 제공한 것입니다. 자세한 내용은 #75를 참조하세요. @niw 덕분에 Apple Silicon 사용자(예: M2 24GB가 탑재된 MacBook Pro)도 MPS 백엔드를 사용하여 우리 모델을 시험해 볼 수 있습니다! 자세한 내용은 #113을 참조하세요.
여러 GPU를 사용하는 사용자를 위해 시퀀스 병렬성을 사용하여 각 GPU의 메모리를 절약하는 추론 스크립트를 제공합니다. 이는 또한 4개의 A100 GPU에서 5s, 768p, 24fps 비디오를 생성하는 데 단 2.5분 밖에 걸리지 않아 속도가 크게 향상됩니다(단일 A100 GPU에서는 5.5분 소요). 다음 명령을 사용하여 2개의 GPU에서 실행합니다.
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh현재 2개 또는 4개의 GPU(SD3 버전의 경우)를 지원하며 원본 스크립트에서 더 많은 구성을 사용할 수 있습니다. @tpc2233이 만든 다중 GPU Gradio 데모를 시작할 수도 있습니다. 자세한 내용은 #59를 참조하세요.
스포일러: 우리는 효율적인 피라미드 흐름 설계 덕분에 훈련에 시퀀스 병렬성을 사용하지도 않았습니다.
guidance_scale 매개변수는 시각적 품질을 제어합니다. 텍스트-비디오 생성 중 768p 체크포인트의 경우 [7, 9] 내의 지침을 사용하고, 384p 체크포인트의 경우 7 내의 지침을 사용하는 것이 좋습니다.video_guidance_scale 매개변수는 모션을 제어합니다. 값이 클수록 동적 수준이 증가하고 자동 회귀 생성 저하가 완화되는 반면, 값이 작을수록 비디오가 안정화됩니다.VAE 교육을 위한 하드웨어 요구 사항은 최소 8개의 A100 GPU입니다. 이 문서를 참조하세요. 이는 연속 3D VAE와 같은 MAGVIT-v2이며 매우 유연해야 합니다. VAE 교육 코드의 이 부분에 대해 자신만의 비디오 생성 모델을 자유롭게 구축해 보세요.
DiT를 미세 조정하기 위한 하드웨어 요구 사항은 최소 8개의 A100 GPU입니다. 이 문서를 참조하세요. 우리는 Pyramid Flow의 자동회귀 버전과 비자동회귀 버전 모두에 대한 지침을 제공합니다. 전자는 연구 지향적이며 후자는 더 안정적입니다(그러나 시간 피라미드가 없으면 효율성이 떨어집니다).
다음 비디오 예제는 5s, 768p, 24fps에서 생성됩니다. 더 많은 결과를 보려면 프로젝트 페이지를 방문하세요.
도쿄.mp4 | 에펠탑.mp4 |
파도.mp4 | 레일.mp4 |
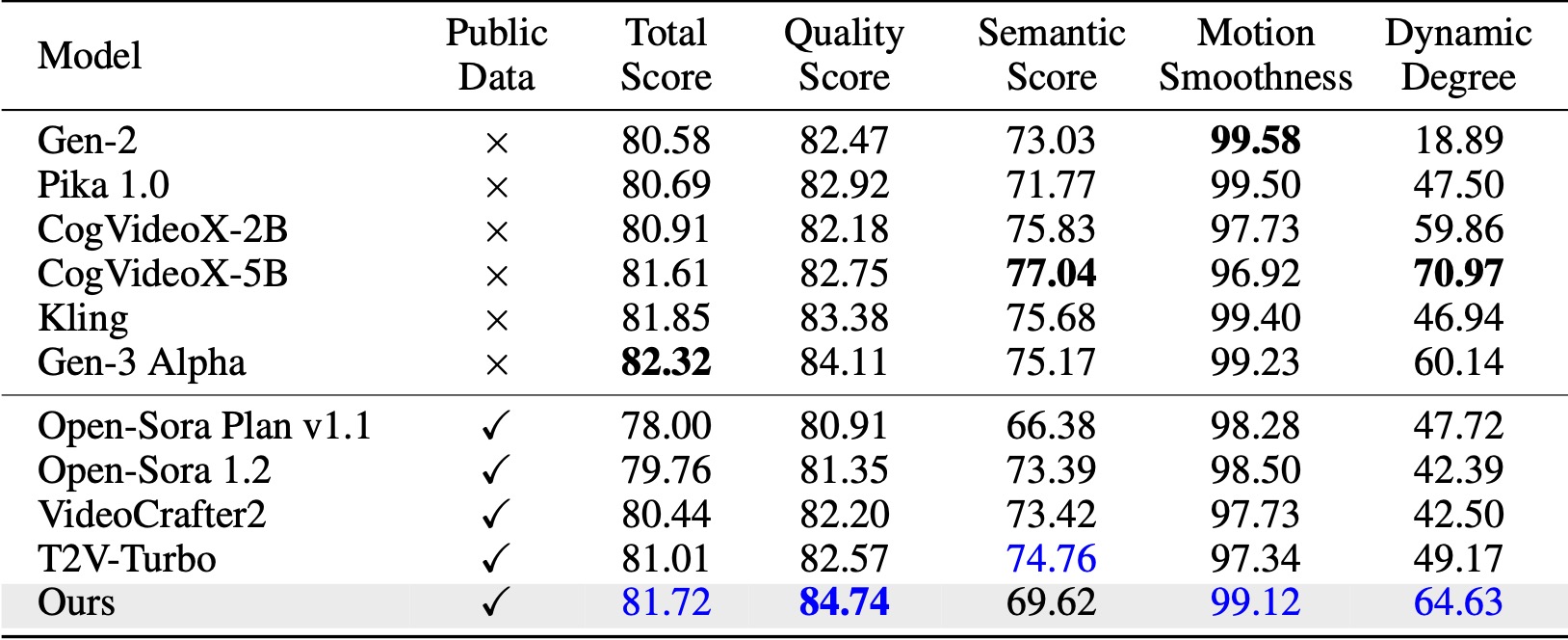
VBench(Huang et al., 2024)에서 우리의 방법은 비교된 모든 오픈 소스 기준을 능가합니다. 공개 영상 데이터만으로도 Kling(Kuaishou, 2024), Gen-3 Alpha(Runway, 2024) 등 상용 모델과 대등한 성능을 보이며 특히 품질 점수(84.74 대 Gen-3의 84.11)와 모션 부드러움 측면에서 우수합니다. .
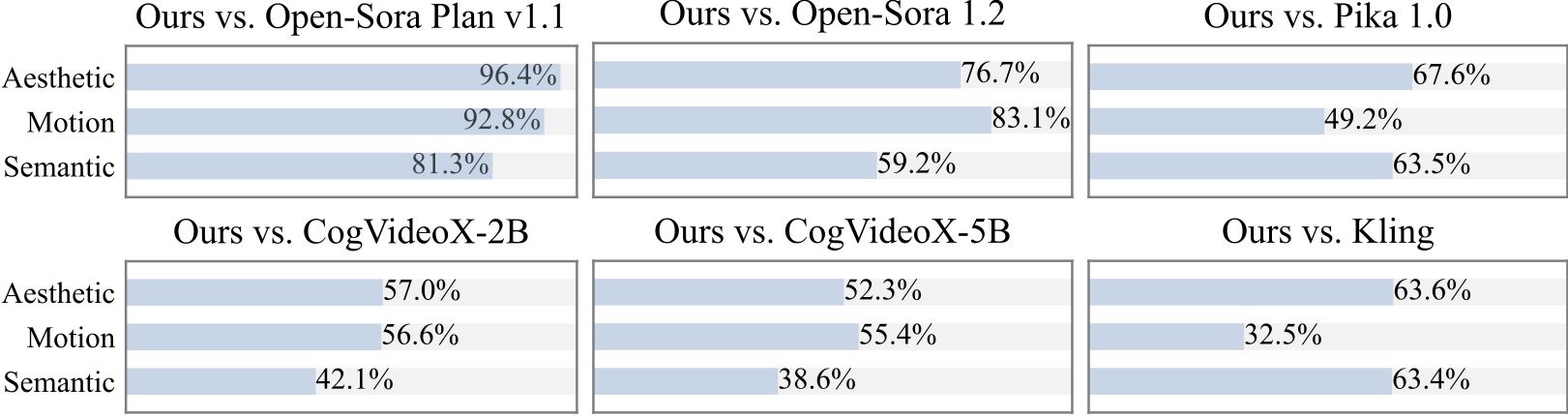
우리는 20명 이상의 참가자를 대상으로 추가 사용자 연구를 실시합니다. 보시다시피, 우리의 방법은 특히 모션 부드러움 측면에서 Open-Sora 및 CogVideoX-2B와 같은 오픈 소스 모델보다 선호됩니다.
Pyramid Flow를 구현할 때 다음과 같은 멋진 프로젝트에 감사드립니다.
이 저장소에 별표를 부여하고 연구에 도움이 된다면 출판물에 Pyramid Flow를 인용하는 것을 고려해보세요.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


